最近体验了GLM的API,因其宣称对Claude Code有不错的兼容性。实际效果如何,这里不做过多评价。如果你对当前国内各大LLM API在支持Claude Code方面的具体表现有所了解,欢迎分享你的经验。

按照官方教程完成接入后,无论是在命令行中使用Claude Code,还是将其集成到VSCode中,整体流程都非常顺畅,基本实现了开箱即用。
但一个更深层次的问题浮出水面:Claude Code的系统提示词究竟是如何设计的?
对于许多AI工具而言,决定体验上限的往往不是模型本身,而是其背后的工程化设计,主要包括三个方面:
- 系统提示词结构
- 工具调用策略
- 上下文管理方式
想要真正理解这些设计,最直接有效的方法只有一个:
抓包,分析真实请求。
因此,我们接下来将详细探讨如何捕获Claude Code的实时网络请求日志,这是进行任何深入的逆向工程分析的第一步。
一、整体思路
核心思路非常清晰:
- 使用 mitmproxy 作为反向代理服务器。
- 将Claude Code的API请求地址指向本地运行的代理服务。
- 在mitmproxy提供的Web界面中,查看每一次请求的详细内容,包括请求体(request body)和响应体(response body)。
- 最终,分析捕获到的数据,重点研究其中的系统提示词(system prompt)。
整个数据流的结构如下:
Claude Code
↓
本地 mitmproxy(监听8125端口)
↓
真实模型 API(例如 GLM / Anthropic 等)
二、安装 mitmproxy
官方安装文档地址:
https://docs.mitmproxy.org/stable/overview/installation/
macOS(推荐使用Homebrew)
使用brew命令进行安装:
brew install --cask mitmproxy
当然,你也可以根据自身环境选择使用 uv 或 pip 进行安装。
三、启动反向代理
这里以代理GLM的API地址为例,执行以下命令:
mitmweb --mode reverse:https://open.bigmodel.cn --listen-port 8125
命令执行后:
- mitmproxy会自动在浏览器中打开一个Web控制台界面。
- 默认的访问地址通常是:
http://127.0.0.1:8081
在这个控制台页面中,你可以清晰地看到每一个经过代理的请求详情,包括:
- 请求头(request headers)
- 请求体(request body)
- 响应体(response body)
四、修改 Claude Code 的 API 地址
Claude Code的配置文件默认位于以下路径(macOS系统):
~/claude/settings.json
修改逻辑
原本,Claude Code会直接请求目标API服务器,例如:
https://open.bigmodel.cn
现在,我们需要修改配置,让所有请求先经过我们本地启动的代理服务器:
http://127.0.0.1:8125
配置示例
以下是修改后的 settings.json 文件示例:
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "xxxx.yyyy",
"ANTHROPIC_BASE_URL": "http://127.0.0.1:8125/api/anthropic",
"API_TIMEOUT_MS": "3000000",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": 1,
"ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air",
"ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.7",
"ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.7"
}
}
其中,最关键的一处修改就是:
"ANTHROPIC_BASE_URL": "http://127.0.0.1:8125/api/anthropic"
五、启动 Claude Code 并抓包
完成上述配置后,在终端启动Claude Code:
claude code
然后,打开之前提到的mitmweb控制台地址:http://127.0.0.1:8081。
现在,你就能在控制台中实时观察到:
- Claude Code发出的每一次API请求。
- 完整的对话Prompt结构。
- 工具调用(Tools)的细节。
- 最核心的——系统提示词的结构。
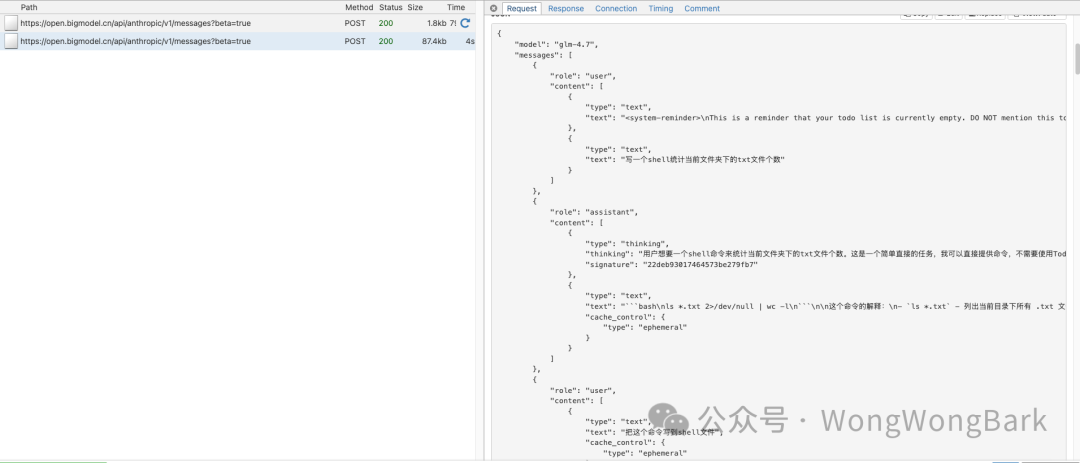
这一步至关重要,因为你所看到的并非官方文档中简化的“示例Prompt”,而是真实生产环境中使用的、工程化级别的提示词。
六、接下来要分析什么?
成功捕获到数据之后,真正有趣的分析才刚刚开始。我们可以深入探究:
- Claude Code的系统提示词究竟有多长?结构如何?
- 它是如何组织并约束工具调用规则的?
- 模型的行为被哪些规则所限制?
- 代码上下文是如何被有效管理和嵌入的?
- 其多轮对话的交互策略是如何设计的?
这些设计,才是一个工程级AI编程助手区别于普通对话模型的真正核心。
在下篇文章中,我们将对抓取到的具体系统提示词进行拆解。这里先展示一个简单的对话响应(response body)片段,让大家有一个直观感受:
{
"model": "glm-4.5-air",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "把这个命令写到shell文件"
}
]
},
{
"role": "assistant",
"content": [
{
"type": "text",
"text": "{"
}
]
}
],
"system": [
{
"type": "text",
"text": "You are Claude Code, Anthropic's official CLI for Claude."
},
{
"type": "text",
"text": "Analyze if this message indicates a new conversation topic. If it does, extract a 2-3 word title that captures the new topic. Format your response as a JSON object with two fields: 'isNewTopic' (boolean) and 'title' (string, or null if isNewTopic is false). Only include these fields, no other text. ONLY generate the JSON object, no other text (eg. no markdown)."
}
],
"tools": [],
"metadata": {
"user_id": "user_ee020b4626dc49055a0c53279bbe0acc9cd2fc3086ab3ac72d9cc91367b27520_account__session_ac0ef032-3c7d-4ce7-8e4a-01fd03124886"
},
"max_tokens": 32000,
"stream": true
}
通过这种方法,我们不仅能了解Claude Code,更能举一反三,为构建或优化自己的人工智能应用提供宝贵的工程参考。这种开源实战精神驱动的探索,正是技术不断前进的动力。如果你对这类深度技术拆解感兴趣,欢迎到云栈社区交流讨论。
 发表于 2026-2-9 09:50:50
|
查看: 233|
回复: 0
发表于 2026-2-9 09:50:50
|
查看: 233|
回复: 0
