今天,我们深入探讨 MySQL 性能优化的核心思路。当线上服务报警,CPU 满载、数据库连接池爆满时,你脑海中闪过的“慢查询”往往是问题的关键。
别慌,性能优化的核心心法在于:化 I/O 于无形,锁争用于无声。下面这套从表结构到 SQL 调优的组合拳,请你接好。
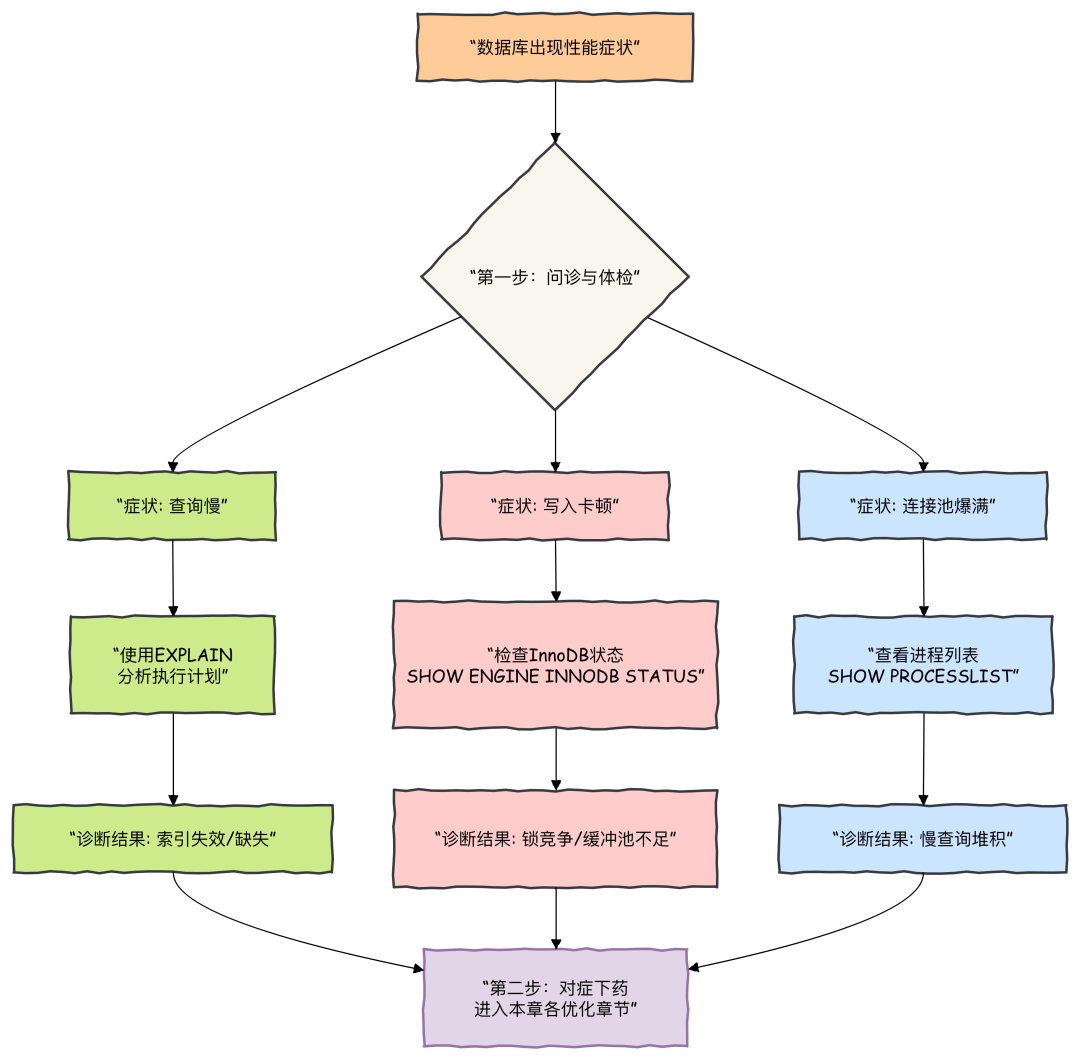
数据库性能取决于软件层面的设计(如表结构、查询语句和配置),这些最终会转化为硬件层面的 CPU 和 I/O 操作。优化的目标是尽可能减少并提升这些操作的效率。
表结构设计
如果把数据比作住客,那么表结构就是它的家。设计得当,数据“住”得舒坦,查询速度自然起飞。
数据类型:能小就别大,能瘦就别胖
TINYINT 是你的好朋友:存储状态码(0/1)时用 TINYINT,而不是 INT。省下的每一个字节,都是在为未来的磁盘 I/O 节省资源。- 用 DATE 代替 DATETIME:如果你不关心时分秒,就用
DATE 类型,避免无用的字段占用空间。
- 避免“NULL 的诅咒”:
NULL 会让索引和计算变得更复杂。尽量为列设置默认值(如空字符串或 0)。
- 字符串类型优化:IP地址可存为无符号整数;UUID 可存为
BINARY(16);固定长度字符串用 CHAR;可变长度字符串用 VARCHAR 并设置合适长度。
- 时间类型优化:只需要日期时用
DATE;需要自动更新时间戳时用 TIMESTAMP。
核心逻辑:更小的数据类型 → 更少的磁盘空间 → 更多数据能缓存进内存 → 更少的 I/O → 飞一样的速度。
范式与反范式
数据库设计的核心之一是平衡范式化与反范式化。
- 范式化(高范式):数据冗余最小化,更新灵活(写操作快),适合写多读少的场景。
- 反范式化(低范式):适度冗余数据,读取方便(避免 JOIN,读操作快),适合读多写少的场景。
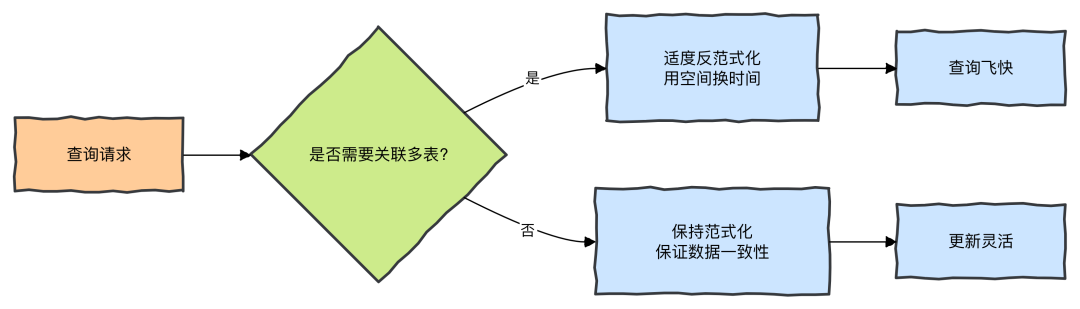
没有绝对的好坏,只有适不适合。在需要极致查询速度时,适度冗余是智慧的体现。
以下是一个范式化设计的示例:
-- 范式化设计示例
CREATE TABLE users (
user_id INT PRIMARY KEY,
username VARCHAR(50),
email VARCHAR(100)
);
CREATE TABLE orders (
order_id INT PRIMARY KEY,
user_id INT,
order_date DATE,
FOREIGN KEY (user_id) REFERENCES users(user_id)
);
CREATE TABLE order_items (
item_id INT PRIMARY KEY,
order_id INT,
product_id INT,
quantity INT,
FOREIGN KEY (order_id) REFERENCES orders(order_id)
);
当读操作远多于写操作时,可以采用反范式化设计来提升查询性能:
-- 反范式化设计示例:订单表包含用户信息
CREATE TABLE orders_denormalized (
order_id INT PRIMARY KEY,
user_id INT,
username VARCHAR(50), -- 反范式化字段
email VARCHAR(100), -- 反范式化字段
order_date DATE,
total_amount DECIMAL(10, 2)
);
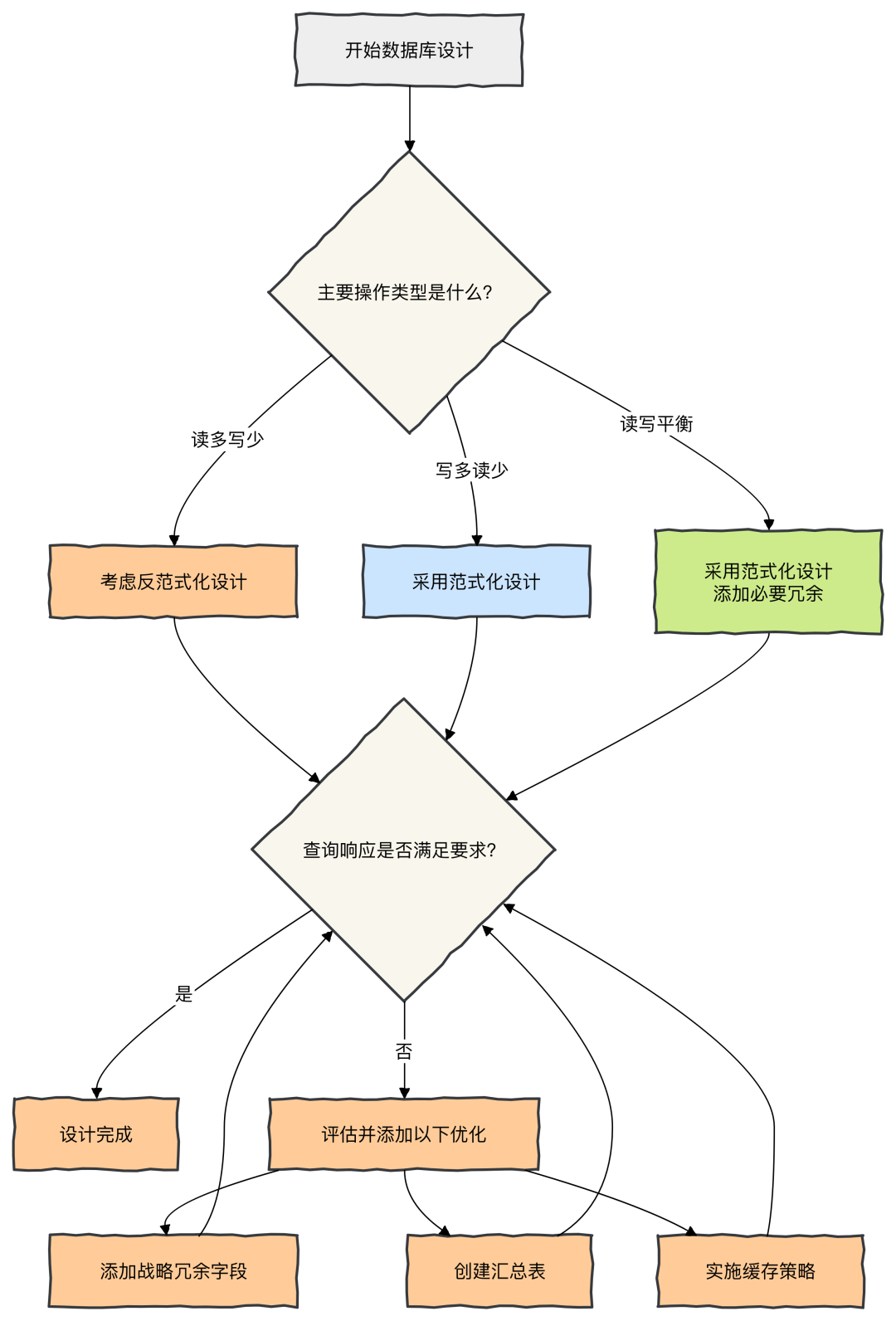
以下流程图展示了数据库设计时,如何根据读写比例决策是否采用反范式化:
索引:数据库的超级目录
没有索引的查询,就像在图书馆里找一本没编号的书——只能“全表扫描”。索引就是书的目录,而且是智能的 B+Tree 目录。索引用得好,下班回家早。
索引设计实战
MySQL 支持多种索引类型,以下是一些创建示例:
-- 1. B-Tree索引(默认):适用于全值匹配、范围查询、排序
CREATE INDEX idx_order_date ON orders(order_date);
-- 2. 多列索引(复合索引)
CREATE INDEX idx_user_status_date ON orders(user_id, status, order_date);
-- 3. 前缀索引:为字符串列前N个字符创建索引
CREATE INDEX idx_email_prefix ON users(email(20));
-- 4. 函数索引(MySQL 8.0+):为表达式结果创建索引
CREATE INDEX idx_lower_username ON users((LOWER(username)));
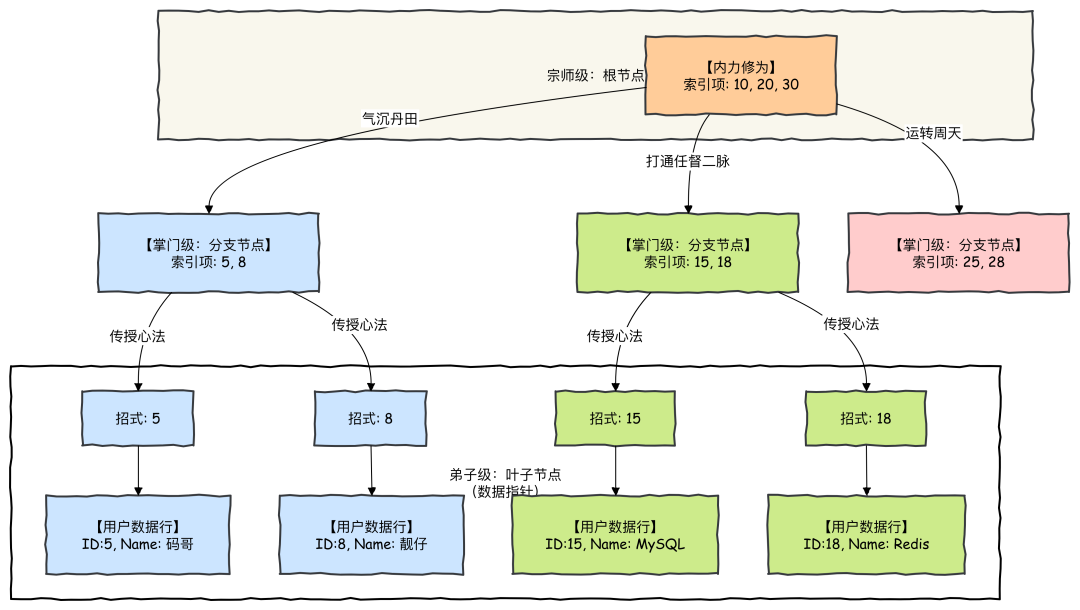
B+Tree 索引是如何工作的?
下图以武侠风格生动展示了 B+Tree 索引的结构和工作原理:
索引设计最佳实践
-- 1. 选择性高的列放在索引前面
-- user_id的选择性高于status,因此user_id在前
CREATE INDEX idx_user_status ON orders(user_id, status);
-- 2. 考虑覆盖索引
-- 索引包含查询所需的所有列,避免回表
CREATE INDEX idx_covering ON orders(order_id, user_id, order_date, total_amount);
-- 查询可以使用覆盖索引
SELECT order_id, user_id, order_date
FROM orders
WHERE user_id = 100 AND order_date > '2024-01-01';
-- 3. 避免重复索引
-- 以下索引是冗余的,因为idx_a_b可以用于a列的查询
CREATE INDEX idx_a ON table1(a); -- 冗余索引
CREATE INDEX idx_a_b ON table1(a, b);
-- 4. 定期分析并删除未使用的索引
-- 使用sys schema查看索引使用统计
SELECT * FROM sys.schema_unused_indexes;
索引使用关键点总结:
- 最左前缀原则。如果建立复合索引
(last_name, first_name),那么:
WHERE last_name = '张' 索引有效WHERE last_name = '张' AND first_name = '三' 索引有效WHERE first_name = '三' 索引失效!
- 别在索引列上“搞计算”。
WHERE YEAR(create_time) = 2023 (❌ 索引列被函数包裹,索引失效)。- 应写成
WHERE create_time BETWEEN '2023-01-01' AND '2023-12-31' (✅)。
- 高选择性原则:避免在“性别”这种区分度低的列上建索引。应在“身份证号”这种高区分度的列上建。
线上索引管理安全技巧:
当你怀疑某个索引多余却不敢删除时,在 MySQL 8.0+ 中可以使其“隐身”:
ALTER TABLE user ADD INDEX idx_email (email); -- 创建
ALTER TABLE user ALTER INDEX idx_email INVISIBLE; -- 隐身!
索引依然存在,但优化器会无视它。观察一段时间业务无恙后,即可放心 DROP INDEX。这是线上索引管理的安全气囊。
查询优化核心技巧
JOIN 优化
JOIN 操作是常见的性能瓶颈,优化关键在于索引和驱动表的选择。
-- 1. 确保JOIN列上有索引
-- 优化前:没有索引的JOIN(性能差)
SELECT * FROM orders o JOIN users u ON o.user_id = u.user_id;
-- 优化后:为JOIN列添加索引
CREATE INDEX idx_user_id ON orders(user_id);
CREATE INDEX idx_user_id ON users(user_id);
-- 2. 小表驱动大表
-- 通过STRAIGHT_JOIN提示优化器
SELECT STRAIGHT_JOIN s.*, l.*
FROM small_table s
JOIN large_table l ON s.key = l.key;
排序和分组优化
你是否遇到过 ORDER BY create_time DESC 明明有索引却依然慢的情况?这是因为传统索引是升序的,反向扫描效率低。从 MySQL 8.0 开始,可以创建真正的降序索引:
CREATE INDEX idx_time_desc ON article (create_time DESC);
这对于新闻流、朋友圈时间线这类需要频繁查询最新数据的场景特别有效。
其他常见优化技巧:
-- 1. 使用索引避免排序
CREATE INDEX idx_order_date_desc ON orders(order_date DESC);
-- 2. 优化GROUP BY查询,为分组列添加索引
CREATE INDEX idx_user_id ON orders(user_id);
SELECT user_id, COUNT(*) FROM orders GROUP BY user_id;
-- 3. 使用派生表(CTE)优化复杂分组,分阶段处理
WITH order_summary AS (
SELECT o.order_id, o.user_id, SUM(oi.quantity) as order_quantity
FROM orders o JOIN order_items oi ON o.order_id = oi.order_id
GROUP BY o.order_id, o.user_id
)
SELECT user_id, COUNT(*) as order_count, SUM(order_quantity) as total_quantity
FROM order_summary
GROUP BY user_id;
分页优化
大数据量下的传统 LIMIT offset, size 分页性能极差,因为偏移量越大,需要扫描并丢弃的行越多。
推荐使用基于游标(Keyset)的分页:
-- 记住最后一条记录的值,而不是使用偏移量
SELECT * FROM orders
WHERE order_date > '2024-01-01'
ORDER BY order_date
LIMIT 20;
-- 获取下一页时,使用上一页最后一条的order_date
SELECT * FROM orders
WHERE order_date > '上一页最后一条的order_date'
ORDER BY order_date
LIMIT 20;
也可以使用覆盖索引优化大偏移量分页:
SELECT o.*
FROM orders o
JOIN (
SELECT order_id
FROM orders
WHERE order_date > '2024-01-01'
ORDER BY order_date
LIMIT 100000, 20
) tmp ON o.order_id = tmp.order_id;
警惕索引失效的常见场景
- 使用 SELECT *:无法使用覆盖索引,必须回表,增加I/O。
- 索引列使用函数 / 运算:如
WHERE DATE(create_time) = '2025-01-01',索引失效。
- 隐式类型转换:如索引字段是
INT,查询用 WHERE age='20',MySQL 会做转换导致索引失效。
- 使用
LIKE '%xxx'(左模糊):WHERE name like '%张三' 索引失效,右模糊 '张三%' 则有效。
- 违反最左前缀原则:使用联合索引时跳过了左侧字段。
查询分析与 EXPLAIN
任何优化都必须以分析为前提。EXPLAIN 命令就是 SQL 语句的“体检报告”。
EXPLAIN FORMAT=JSON
SELECT o.order_id, o.order_date, u.username
FROM orders o
JOIN users u ON o.user_id = u.user_id
WHERE o.order_date >= '2024-01-01'
ORDER BY o.order_date DESC
LIMIT 10;
解读 EXPLAIN 结果,要重点关注以下几列:
- type 列:访问类型。从优到劣大致是:
system > const > eq_ref > ref > range > index > ALL。见到 ALL(全表扫描)就要警惕。
- key 列:实际使用的索引。如果为
NULL,说明未使用索引。
- rows 列:MySQL 预估需要扫描的行数。值越大,查询成本越高。
- Extra 列:包含重要附加信息。出现
Using filesort(文件排序)或 Using temporary(使用临时表)通常是性能瓶颈的信号。
使用 EXPLAIN FORMAT=JSON 可以获得更详尽的成本分析报告。
MySQL 系统级优化
缓冲池(InnoDB Buffer Pool)
这是 InnoDB 的性能灵魂。innodb_buffer_pool_size 应设置为系统总内存的 70%-80%。一个足够大的缓冲池能让热数据常驻内存,极大减少磁盘 I/O。
如何判断缓冲池是否够用?
SHOW STATUS LIKE 'innodb_buffer_pool_read%';
如果 Innodb_buffer_pool_reads(从磁盘读取的页数)远大于 Innodb_buffer_pool_read_requests(总的读请求数),说明缓冲池太小,命中率低。
日志系统(Redo Log)
Redo Log 是保证事务持久性的关键。innodb_flush_log_at_trx_commit 参数平衡了性能与安全性:
- =1(默认):每次事务提交都刷盘。最安全,但最慢。适用于金融交易等强一致性场景。
- =2:每次提交只写操作系统缓存,每秒刷一次盘。性能好,崩溃可能丢失近1秒数据。适用于大多数业务场景。
- =0:每秒写和刷盘。性能最好,但崩溃可能丢失最多1秒数据。适用于可容忍少量数据丢失的场景(如日志收集)。
对于非强一致性要求的业务,尝试设置为 2 可以获得显著的性能提升。
监控与度量
优化不能靠猜,必须有数据支撑。MySQL 提供了强大的监控工具。
1. 慢查询日志: 记录执行时间超过 long_query_time(如 0.1 秒)的 SQL,是定位问题 SQL 的“病历本”。
2. Performance Schema: 深度监控服务器运行时的所有细节,如语句执行阶段、锁等待、I/O。
3. sys Schema: 基于 Performance Schema 的友好视图,提供人类可读的报告,例如直接查询全表扫描的语句:
SELECT * FROM sys.statements_with_full_table_scans;
下图展示了在数据库性能优化中,各项工作的精力分配建议:
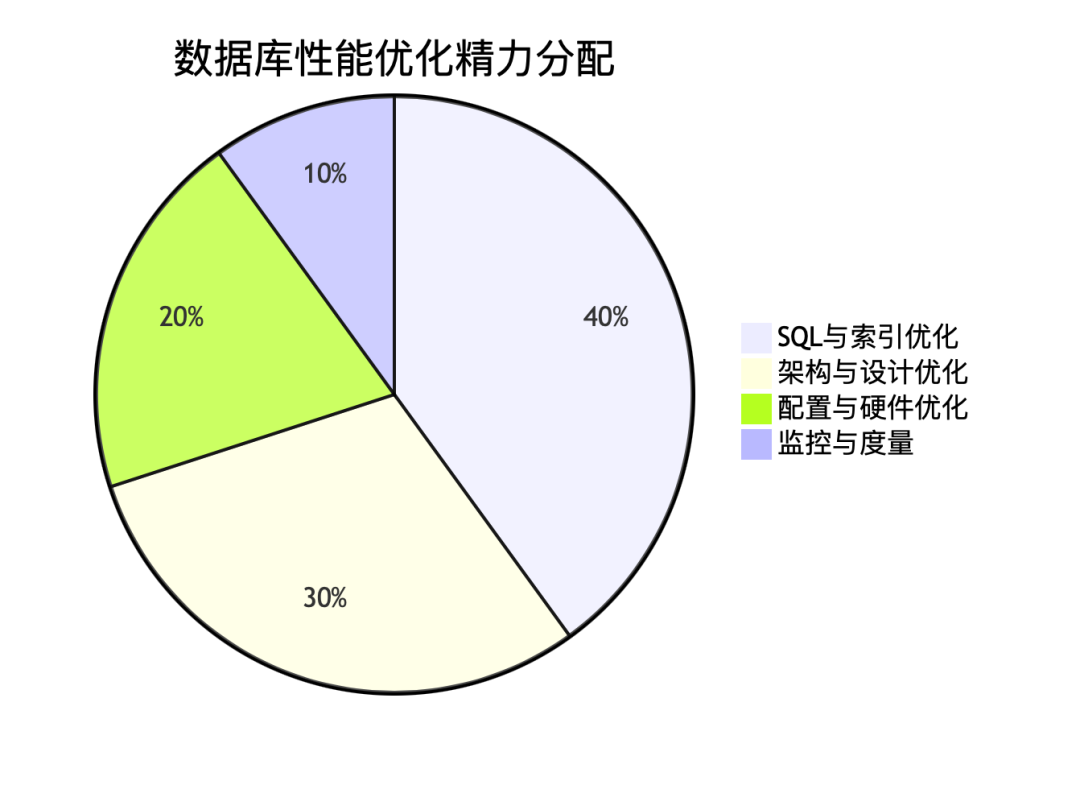
总结:MySQL 优化核心心法
- 先诊断,后开药:善用
EXPLAIN、慢查询日志和 Performance Schema 等工具定位问题。
- SQL 与索引为王:绝大多数性能问题都能通过优化 SQL 语句和索引设计来解决或缓解。
- 理解存储引擎:掌握 InnoDB 缓冲池和 Redo Log 的配置,就握住了性能的关键命脉。
- 善用新特性:如不可见索引、降序索引等,它们是安全运维和性能提升的利器。
- 数据驱动决策:建立性能监控基线,任何优化前后都要进行量化对比,确保改变确实有效。
性能优化是一条持续的道路,需要不断学习和实践。希望这份从实战出发的指南,能帮助你在处理高并发场景下的数据库性能问题时,思路更加清晰。如果你有更多心得或疑问,欢迎到云栈社区与广大开发者交流探讨。
 发表于 2026-2-10 03:21:48
|
查看: 129|
回复: 0
发表于 2026-2-10 03:21:48
|
查看: 129|
回复: 0
