今天想聊一个实际的问题:我们如何把 Claude Code 这样的 AI 编程工具,从个人玩具变成团队稳定交付的引擎?核心不是“写得快”,而是“交付稳”。
我自己曾踩过一个坑:把一个“看起来不复杂”的需求直接丢给 AI,让它一次性生成接口、实现和测试。第二天 Review 时才发现,它漏掉了最关键的权限边界。改起来不难,难的是得重新梳理一遍上下文。
从那以后,我的目标就变了:不追求 AI 一次写对,而是追求它能每次都沿着正确的流程,将问题收敛到可验证的状态。
下面这 6 个抓手,是我在实际项目中反复踩坑、迭代出来的方法。它们结合了 Claude Code 的 Hooks、Skill、Subagent、权限体系等机制层能力,提炼成了可以直接落地的实践。你可以把它看作一份“团队 Playbook 的骨架”。
TL;DR(太长不看版)
- 第一抓手是验收:先写怎么证明对,再谈怎么实现。
- 提示词不要写成愿望,要写成任务单:范围、证据、约束、验收。
- 复杂任务别一口吞,先用 Plan 做 WBS:拆模块、标依赖、定顺序、列交付物。
- 护栏要写进配置:
CLAUDE.md + .claude/settings.json 的 permissions + sandbox + hooks。
- Skill 是团队记忆:把一次成功变成可复用组件,别靠口口相传。
- 要规模化,靠两件事:MCP 把外部系统接进来,Subagents 把高输出/高噪音隔离出去。
抓手 1:先写“怎么验收”,再写“怎么实现”
AI 编程里最贵的成本不是 Token,也不是生成速度,而是返工。
返工通常不是“写错了语法”,而是:
- 你没写清楚“什么叫做对”
- 你没定义“对到什么边界”
- 你没给它一个自证正确的路径
我现在会把任何任务都改写成一句验收标准:
“你改完以后,我要能用哪些命令/截图/对比证明它是对的?”
我把这个思路变成了团队流程的第零步:无论用不用 Claude Code,先明确一个可执行的验收方式,后续所有步骤才有落点。 这跟传统 TDD 里“先写失败测试”是一回事,但适用范围更广:
- 单测:
npm test / pnpm test / go test ./...
- 构建:
npm run build / cargo build
- 代码规范:
<lint-command>(或格式化)
- 端到端:
npx playwright test(关键用户旅程 + 截图/trace 作为证据)
- 回归点:3 条“最容易出事”的业务路径
- 回滚:一句话说清楚“出了问题怎么退回去”
把验收写出来之后,你会发现很多需求会自动变清晰。例如“要更安全”这种话没意义,验收可以直接落成:
- 未登录访问应该返回 401
- 权限不足应该返回 403,且有审计日志
- 敏感字段必须脱敏,且单测覆盖
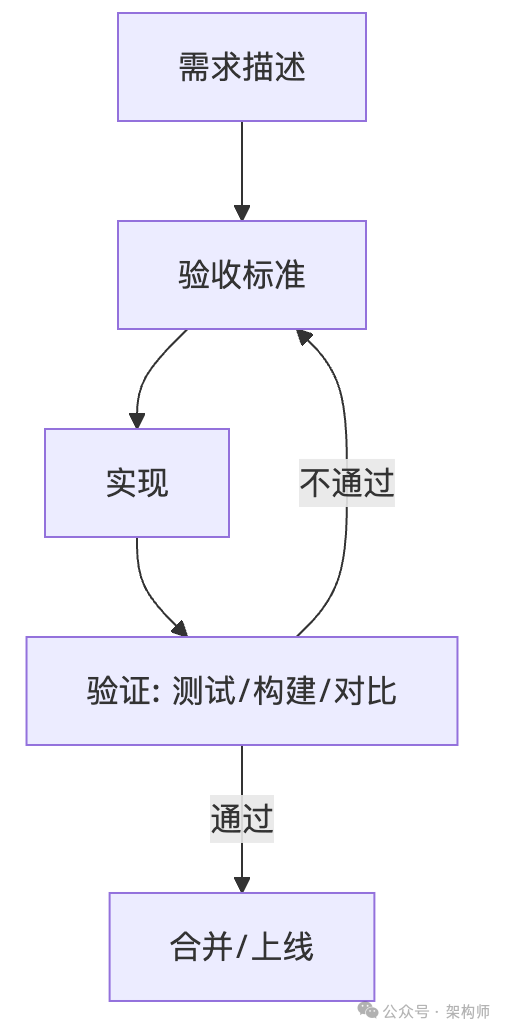
一张图:交付的真正闭环
这张图看起来简单,但它解决的就是“写完了却不敢合并”的那种痛。它清晰地展示了从需求描述到上线的验证驱动闭环。
抓手 2:提示词从“聊天”变成“任务单”
团队里最常见的失败模式,是把提示词写成一种模糊的期待:
“帮我把这个模块写得更好一点,更规范一点。”
AI 会非常努力地让它“更好”,然后你得到一份很像正确答案,但不一定能在你项目里落地的东西。
我建议把提示词写成固定结构的任务单。四件事写清楚,返工会少一半:
- 范围:只允许动哪些目录/文件;哪些绝对不要碰。
- 证据:报错堆栈、日志、截图、复现步骤,尽量给原始材料。
- 约束:技术栈、既有规范、必须复用的工具、性能与安全底线。
- 验收:跑什么命令、通过哪些测试、看到什么输出、对比哪些截图。
一个通用模板(可直接拿去团队统一):
目标:我要实现/修复什么?
范围:只允许修改 @path1 @path2(禁止修改 @path3)
证据:复现步骤/报错堆栈/日志片段(原文粘贴)
约束:必须复用哪些现有实现?不引入新依赖?保持 API 不变?
验收:运行哪些命令?新增哪些测试?期望输出是什么?
交付:是否需要更新文档/迁移说明/配置示例?
富内容输入:少描述,多喂证据
Claude Code 的一个特别实用的用法:直接把日志管道喂进去,让它基于“原始证据”做分析,而不是基于你的复述。
cat logs.txt | claude -p “定位根因,并给出最小修复建议与验收步骤”
或者你本地跑完测试,把失败输出喂进去:
npm test 2>&1 | claude -p “只总结失败原因、关联文件、下一步排查顺序”
这类输入很“省上下文”,也很少走偏。
三个可以直接抄的任务单
示例 A:修 Bug(先复现,再修)
目标:修复登录过期后偶发的 401 循环跳转
范围:只允许修改 @src/auth/ @src/middleware/(禁止修改 @src/api/)
证据:复现步骤 + 完整日志(如下)
约束:保持现有 session 模型;不引入新依赖;保持接口返回结构不变
验收:新增一个失败用例复现问题;修复后本地跑 <你的测试命令> 全绿
交付:写一段“根因 + 修复点 + 风险”说明
示例 B:做需求(先写 SPEC,再实现)
目标:新增“批量导入”能力(Excel)
范围:只允许修改 @modules/import/ @modules/task/(禁止改 DB 结构)
证据:PRD 关键段落(如下)
约束:必须复用现有 ImportJob;异常码使用 ErrorCodeEnum;日志按 LogKey 规范
验收:导入 3 种失败场景要有明确报错;成功场景生成 1 条审计记录;补单测
交付:更新 @docs/import.md(新增接口与错误码)
示例 C:小重构(强调“行为不变”)
目标:把支付回调里重复的校验逻辑抽成一个函数
范围:只允许修改 @src/pay/callback.ts(禁止改 API 行为)
证据:现有重复代码片段(如下)
约束:不改变日志字段;不改变异常类型;函数命名遵循现有风格
验收:运行 <你的测试命令>;并说明 diff 为什么不改变行为
交付:给出一次小型重构的 review checklist
抓手 3:Plan 不是形式主义,它是 WBS
复杂需求最容易翻车的地方,是你把“一句话需求”直接丢给 AI,让它从零到一生成一大坨代码。
3.1 Plan Mode:先只读探索,再落笔实现
Claude Code 的 Plan Mode 就是为这个场景设计的:按 Shift+Tab 切到 Plan Mode,Claude 只能用只读工具分析代码库,输出计划但不允许改任何文件。
典型工作流是:
- 切到 Plan Mode → 让 Claude 研究代码库、理解现状
- 追问细化 → “如何保持向后兼容?”“数据库迁移怎么处理?”
- 计划满意后 → Shift+Tab 切回 Normal Mode → 开始执行
更高级的用法:让 Claude 来“采访”你:
> 开始前先采访我关于这个功能:用户通知系统
Claude 会用选择题收集需求、澄清模糊点、了解偏好。这比你预先想好所有需求更高效。
3.2 Plan 阶段的输出格式(建议团队统一)
模块清单:
- M1:职责、输入输出、依赖、复杂度、验收方式
- M2:...
风险与边界:
- 不做什么(明确排除项)
- 可能踩坑的地方(列 3 条就够)
实施顺序:
1. 先做什么,为什么(依赖/风险/收益)
2. 再做什么
验收清单:
- 每个模块对应的测试/命令/检查点
这个模板的价值在于:你可以在“写第一行代码之前”就完成一次方案 Review。
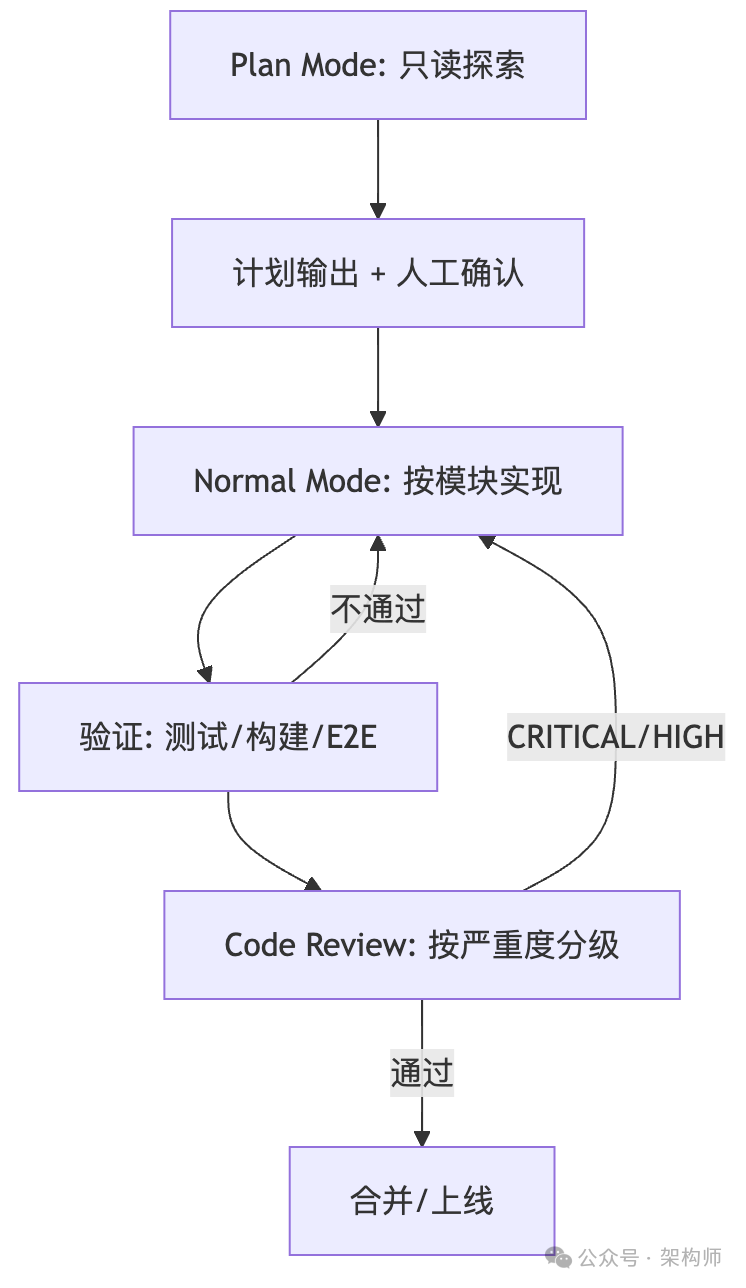
3.3 一张图:从探索到交付的完整闭环
这张图清晰地展示了从 Plan Mode 的只读探索开始,到最终合并上线的完整、受控的工作流。
3.4 团队质量门禁:把流程固化成命令
我在团队里跑通的一条闭环流程,可以直接照做:
/plan:先确认方案与验收(Plan Mode)/tdd:测试先行 → RED → GREEN → REFACTOR/build-fix:构建失败就增量修复——修一个、跑一次、验证解决/code-review:按严重度输出审查报告(CRITICAL/HIGH/MEDIUM/LOW),存在 CRITICAL/HIGH 就不合并- 合并前:跑最小验证集(测试 + 构建 + 关键 E2E)
这些 /command 本质是流程模板,关键不是内容多,而是强约束顺序,将好的开发流程固化下来。
抓手 4:把护栏写进配置,而不是写进人脑
这一抓手我会分成四块:CLAUDE.md、permissions、sandbox、hooks。它们的共同目标只有一个:让“必须发生的事情”自动发生,走向自动化。
4.1 CLAUDE.md:写成护栏,不是百科
CLAUDE.md 的定位是项目的“记忆文件”。但最大的坑是把它写成百科全书。实际效果是:写得越多,AI 遵守得越少。
判断标准:
删掉这一行,会不会明显增加 AI 犯错概率?
如果不会,就删。
一个“刚好够用”的骨架:
# Workflow
- 代码改动后必须运行:<你的测试命令>
- 优先跑单测/局部测试,确认后再跑全量
# Constraints
- 不引入新依赖,除非我明确同意
- 只允许修改:@src/...(禁止触碰:@infra/...)
# Pointers
- 项目入口:@README.md
- 接口规范:@docs/api-guideline.md
- 错误码:@docs/error-codes.md
这类配置放哪里(给团队一个“统一地图”)
| 目的 |
推荐位置 |
是否提交到仓库 |
| 团队共享规则(permissions、hooks) |
.claude/settings.json |
是 |
| 个人偏好(模型、语言等) |
~/.claude/settings.json |
否 |
| 本地临时调试(不想污染团队) |
.claude/settings.local.json |
否 |
| 项目“长期记忆” |
CLAUDE.md |
是 |
| 个人“长期记忆” |
~/.claude/CLAUDE.md |
否 |
| 细分规则(安全/测试/代码风格) |
.claude/rules/*.md |
是 |
| 专用 Agent(规划/审查/排障) |
.claude/agents/*.md |
是 |
| 团队共享 MCP 配置 |
.mcp.json(项目根目录) |
是 |
4.2 permissions:把“允许”和“禁止”写成规则
Claude Code 默认只读,任何写操作/命令执行都走权限确认。团队落地时,最实用的做法是把高频安全命令写成 allowlist,把确认弹窗留给真正有风险的操作。
{
"permissions": {
"allow": [
"Bash(npm run:*)",
"Bash(pnpm run:*)",
"Bash(git diff:*)"
],
"deny": [
"Bash(curl:*)",
"Read(./.env)",
"Read(./secrets/**)"
]
}
}
⚠️ 一个容易踩的坑::* 和 * 的区别。
Bash(git diff:*) 用 :* 做前缀匹配(带单词边界)——能匹配 git diff --stat,但不会匹配 git differentBash(ls*) 用 * 做 glob 匹配(无单词边界)——可能同时匹配 ls -la 和 lsof
评估优先级:deny > ask > allow。即便同一个操作同时命中 allow 与 deny,最终也会被 deny 拦截。
4.3 sandbox:把 bash 运行隔离起来
沙箱配置可以实现文件系统隔离和网络隔离:
{
"sandbox": {
"enabled": true,
"autoAllowBashIfSandboxed": true,
"excludedCommands": ["docker", "git"],
"network": {
"allowUnixSockets": ["/var/run/docker.sock"],
"allowLocalBinding": true
}
}
}
团队落地的关键:你要的是“少弹窗”,不是“跳过所有权限”。更稳的路径是:
- 该隔离的隔离(sandbox)
- 该允许的允许(permissions allowlist)
- 别一上来就开
bypassPermissions(高风险)
4.4 hooks:把质量闸门自动化
Hooks 的价值在于:把你曾经踩过的坑变成自动化护栏。 我总结了一套从“提醒型”到“阻断型”的渐进式落地路径。
场景 1:编辑后自动跑 lint(最常用)
{
"hooks": {
"PostToolUse": [
{
"matcher": "Write|Edit",
"hooks": [
{
"type": "command",
"command": "npm run lint:fix"
}
]
}
]
}
}
场景 2:git push 前强制停一下(防误推)
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash",
"hooks": [
{
"type": "command",
"command": "#!/bin/bash\ninput=$(cat)\ncmd=$(echo \"$input\" | jq -r '.tool_input.command // \"\"')\nif echo \"$cmd\" | grep -q 'git push'; then\n echo '[Hook] Review changes before push' >&2\nfi\necho \"$input\""
}
]
}
]
}
}
场景 3:console.log 审计(会话结束时扫描)
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "command",
"command": "#!/bin/bash\nif git rev-parse --git-dir > /dev/null 2>&1; then\n files=$(git diff --name-only HEAD 2>/dev/null | grep -E '\\.(ts|tsx|js|jsx)$' || true)\n for f in $files; do\n [ -f \"$f\" ] && grep -q 'console\\.log' \"$f\" && echo \"[Hook] WARNING: console.log in $f\" >&2\n done\nfi"
}
]
}
]
}
}
场景 4:禁止在 main 分支直接编辑(团队协作必备)
{
"hooks": {
"PreToolUse": [
{
"matcher": "Edit|Write",
"hooks": [
{
"type": "command",
"command": "[ \"$(git branch --show-current)\" != \"main\" ] || { echo 'Cannot edit on main. Create a feature branch first.' >&2; exit 2; }",
"timeout": 5
}
]
}
]
}
}
场景 5:智能停止判断(用 LLM 评估任务是否真的完成)
Hooks 还支持 type: "prompt",用一个轻量模型(Haiku)来评估决策:
{
"hooks": {
"Stop": [
{
"hooks": [
{
"type": "prompt",
"prompt": "评估 Claude 是否应该停止工作。检查:1.所有任务是否完成 2.是否有错误未处理 3.是否需要后续工作。返回 JSON:{\"ok\": true} 或 {\"ok\": false, \"reason\": \"说明\"}",
"timeout": 30
}
]
}
]
}
}
团队落地建议:渐进式上线
- 先上提醒型(几乎不会引起反感)
- 再上校验型(console.log 扫描、格式化、类型检查)
- 最后才考虑阻断型(并且要明确“为什么阻断/如何绕过/谁来维护”)
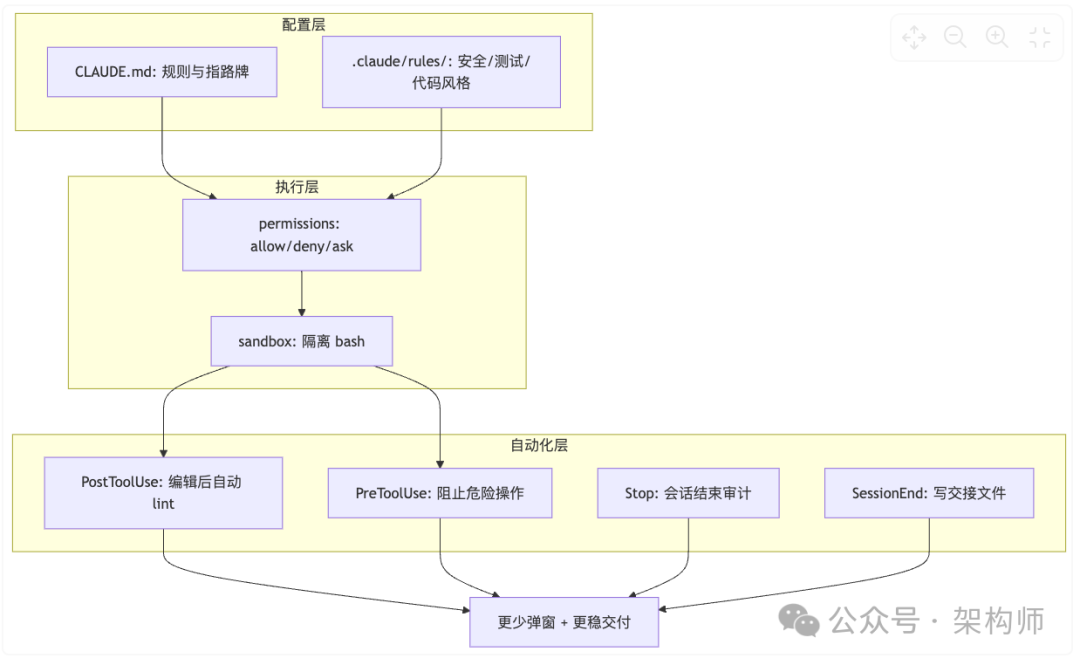
4.5 一张图:护栏体系怎么配合
这张图清晰地展示了配置层、执行层、自动化层如何协同工作,实现“更少弹窗 + 更稳交付”的目标。
抓手 5:把一次成功封装成 Skill(团队记忆)
Skill 的定位:可复用的工具箱。翻译成团队语言就是:
你写过一次好 prompt,不要让它只活在聊天记录里。
5.1 Skill 不要写成百科,要写成“约束 + 模板 + 检查清单”
一个可用的 Skill 最少包含三块:
- When to Use:什么场景必须启用
- Patterns:团队认同的模式(最好配代码模板)
- Checklist:完成前必须过的检查点
5.2 哪些东西值得做成 Skill
我会优先封装三类:
- 复杂工具/框架的标准用法(团队最容易写错的那种,比如“ES 接入”、“Redis 缓存更新策略”)
- 常见错误处理模板(重试、幂等、分布式锁、事务边界)
- 团队统一产物格式(方案文档、接口说明、变更说明、回归清单)
5.3 Skill 的调用控制能力
| Skills 的 frontmatter 支持精细的触发控制: |
配置 |
你能手动调用 |
Claude 能自动调用 |
适用场景 |
| 默认 |
是 |
是 |
通用知识类 Skill |
disable-model-invocation: true |
是 |
否 |
/deploy、/commit 等有副作用的流程 |
user-invocable: false |
否 |
是 |
背景知识类(不暴露给用户) |
你还可以限制 Skill 的工具范围:
---
name: security-audit
description: 只读安全审查
allowed-tools: Read, Grep, Glob
context: fork
agent: Explore
---
这样审查类 Skill 只能输出建议,不能直接改文件。
5.4 动态上下文注入:让 Skill 自己拉数据
在 Skill 内容里用 !`command` 占位符,Claude Code 会在发送给模型之前先执行命令,把输出注入提示。团队里最典型的用法是 PR 摘要:
---
name: pr-summary
description: 汇总当前 PR 的改动
context: fork
agent: Explore
allowed-tools: Bash(gh:*)
---
## Pull request context
- PR diff: !`gh pr diff`
- PR comments: !`gh pr view --comments`
- Changed files: !`gh pr diff --name-only`
## Your task
基于以上信息,给出这次 PR 的摘要、风险点与建议验证清单。
这种模式的核心价值是:你喂的是证据,不是形容词。
5.5 让 Skill 真正被用起来(而不是躺在目录里)
- 在
CLAUDE.md 写清楚:哪些任务必须使用哪些 Skills
- 维护一个
.claude/skills/README.md,列出所有 Skills + 推荐组合
- 用 Hooks 做自动推荐(可选):在
UserPromptSubmit 时跑轻量脚本,匹配用户意图后提示“建议启用 xxx Skill”
抓手 6:规模化靠两条腿:MCP + Subagents
当一个人用顺了 Claude Code,下一步是团队规模化。规模化最大的敌人不是“不会用”,而是:
- 上下文被挤爆
- 外部信息靠口述
- 高输出操作把主对话污染得一团糟
MCP 和 Subagents 正好分别解决这三个问题。
6.1 MCP:把外部系统接进来,但控制上下文成本
一个现实成本是:每启用一个 MCP 服务器,都会带来工具描述开销,上下文会被挤占。
团队三条规矩:
- 先把常用 MCP 控制在小集合(例如不超过 10 个),用到再加
- 能用项目级
.mcp.json 固化的,就不要靠口口相传
- 密钥用环境变量,
.mcp.json 里只写占位符
.mcp.json 支持环境变量展开:
{
"mcpServers": {
"api-server": {
"type": "http",
"url": "${API_BASE_URL:-https://api.example.com/mcp}",
"headers": {
"Authorization": "Bearer ${API_KEY}"
}
}
}
}
如果团队 MCP 工具很多(10+),建议启用 MCP Tool Search,避免所有工具定义一次性预加载到上下文:
ENABLE_TOOL_SEARCH=auto:5 claude
也可以写到 settings.json 的 env 里统一生效。
CLI 管理命令:
claude mcp add --transport http <name> <url>
claude mcp add --scope project --transport http <name> <url> # 写入 .mcp.json
claude mcp list
claude mcp remove <name>
6.2 Subagents:隔离上下文,隔离噪音
Subagents 的核心价值:子代理在独立上下文里运行,高输出留在子代理里,只把摘要带回主对话。
| Claude Code 内置了三个 Subagent: |
代理 |
模型 |
工具 |
用途 |
Explore |
Haiku(快、便宜) |
只读 |
文件发现、代码搜索、代码库探索 |
Plan |
继承主模型 |
只读 |
规划阶段的代码库研究 |
general-purpose |
继承主模型 |
所有 |
复杂研究、多步操作、代码修改 |
我最常用的三个场景:
- Explore 只读搜索:让它输出“结论 + 证据”,不改文件
- 跑测试/跑构建:把海量输出留在子代理里,只把失败摘要带回来
- 并行研究:启动多个 Subagent 同时分析不同模块
> 使用独立的 Subagent 并行研究认证、数据库和 API 模块
创建自定义 Subagent
可以用交互式界面(/agents),也可以手动创建 Markdown 文件:
---
name: code-reviewer
description: 代码修改后主动审查质量、安全性和可维护性
tools: Read, Grep, Glob, Bash
model: inherit
---
你是确保高标准代码质量和安全性的资深代码审查员。
被调用时:
1. 运行 git diff 查看最近更改
2. 关注修改的文件
3. 立即开始审查
审查清单:
- 代码清晰可读
- 没有暴露的密钥或 API 密钥
- 错误处理得当
- 测试覆盖良好
按优先级组织反馈:
- 严重问题(必须修复)
- 警告(应该修复)
- 建议(考虑改进)
存放位置:.claude/agents/code-reviewer.md(项目级)或 ~/.claude/agents/(个人级)。
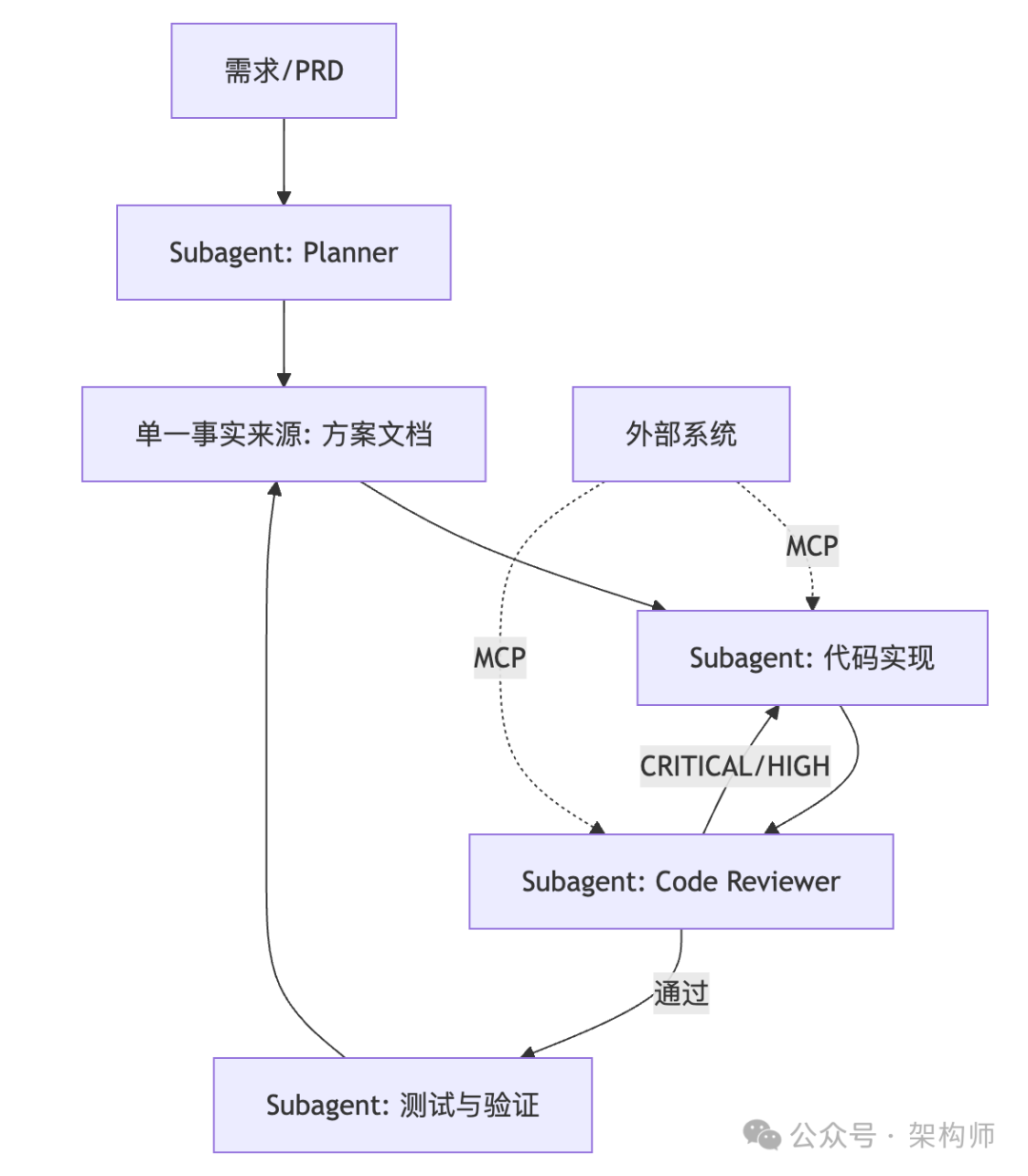
6.3 一张图:规模化协作架构
这张图展示了如何通过 MCP 接入外部系统,并利用多个 Subagent 分工协作,完成从需求到验证的完整、复杂的系统设计流程。
这套流程跑得起来,你的团队就能做到一件事:不靠某个“会写提示词的人”撑住全场,而是靠流程和配置资产持续产出。
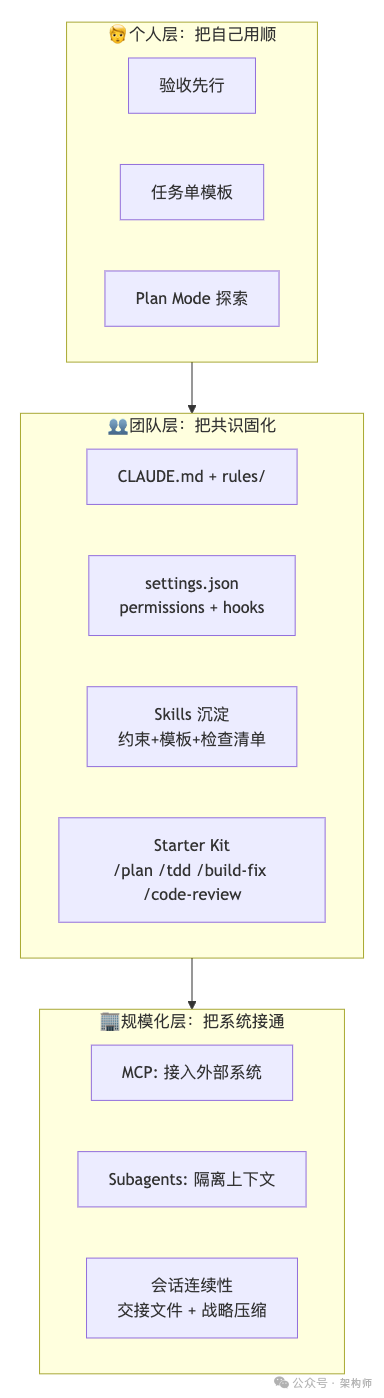
一张落地全景图:从个人到团队的三层递进
这张图很好地总结了从个人使用习惯,到团队共识固化,再到规模化系统集成的三层递进关系。
一份落地清单(照着做就行)
如果你想从明天开始就能见到效果,我建议按这个顺序推进:
第一周(个人):
- 任何改动先写“验收清单”(抓手 1)
- 统一“任务单模板”(抓手 2)
- 复杂需求先进 Plan Mode,再写代码(抓手 3)
第二周(团队基础设施):
- 把
CLAUDE.md 压缩到护栏级别(抓手 4.1)
- 上项目级
.claude/settings.json:permissions + hooks(抓手 4.2/4.4)
- 搭建 Starter Kit:
rules/ + agents/ + commands/(抓手 4)
第三周起(复用与规模化):
- 把常用套路沉淀成 3 个 Skill(抓手 5)
- 选 1 个 MCP 做试点,用
.mcp.json 固化(抓手 6.1)
- 把“高输出任务”交给 Subagent(抓手 6.2)
结尾
回到开头的判断:AI 编程工具真正的价值不是替你写代码,而是把你从重复劳动里抽出来,让你把精力放回需求、架构和质量。
如果你只想带走一句话,我会选这句:先把验收写出来,再让 AI 写代码。
 发表于 2026-2-10 04:13:16
|
查看: 256|
回复: 0
发表于 2026-2-10 04:13:16
|
查看: 256|
回复: 0
