最新的 Patchset RFC 已发布:
https://lore.kernel.org/lkml/20260206191136.2609767-1-slava@dubeyko.com/
[RFC PATCH v1 0/4] Machine Learning (ML) library in Linux kernel
作者是 Viacheslav Dubeyko (slava@dubeyko.com)。这套补丁的核心目标在于,为 Linux 内核引入一个通用的机器学习(ML)库框架,使得 ML 模型能够在内核内部运行,并为其他内核子系统提供统一的 API。其理想的应用场景是,当机器学习模型足够成熟,并且应用其推荐策略带来的效率提升显著优于人工设计的算法时,ML 模型代理可以将内核子系统切换至推荐模式运行。
Linux 内核中的机器学习基础设施设计
要在 Linux 内核中实现这一构想,需要一个专用的机器学习库。这个库将作为一个通用的交互接口,协调用户空间中的机器学习模型线程与内核子系统之间的工作。
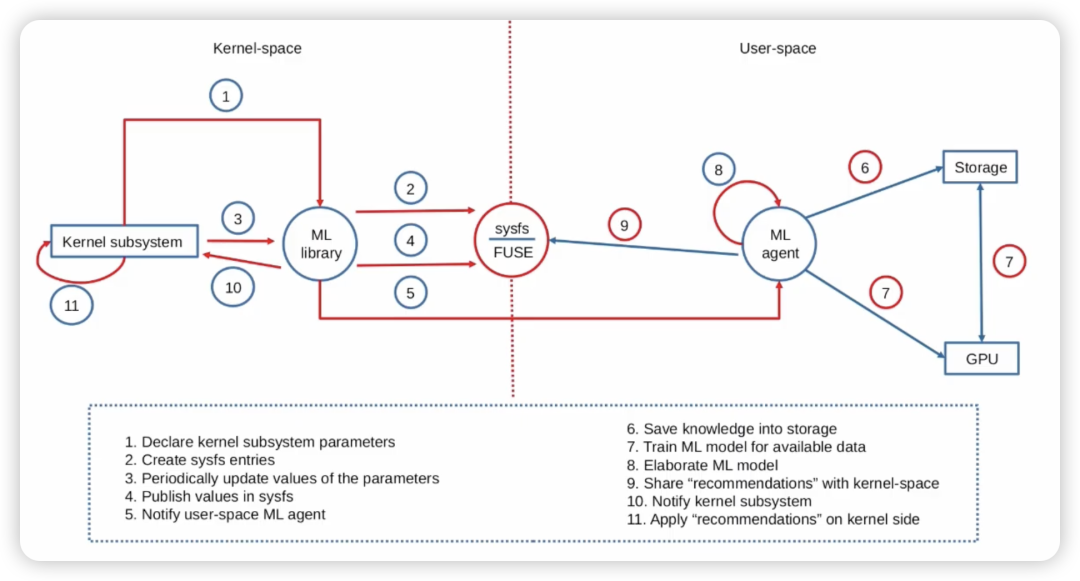
这套设计的核心理念是:内核仅作为机器学习的代理,尽可能将繁重的工作转移到用户空间的 ML Agent 中去执行。原因主要有两点:
- 机器学习模型的运行严重依赖大量浮点运算(FPU),而内核空间通常不直接使用 FPU。
- 模型训练阶段本身计算开销巨大,若在内核侧执行,可能会对 Linux 内核的整体性能产生显著的负面影响。
因此,直接在内核里“搞”完整的机器学习几乎是不可能的。这套 Patchset 提出的解法思路非常清晰:
- 内核空间不能直接承担 ML 训练(计算开销和浮点运算问题)。
- 用户空间可以执行训练和生成推荐。
- 内核空间只负责代理和策略应用。
为了实现上述架构,内核中的 ML 代理接口需要具备以下能力:
- 在内核子系统中创建、初始化、销毁 ML 模型代理。
- 启动或停止 ML 模型代理。
- 从内核空间获取、预处理、发布数据集。
- 接收、预处理、应用来自用户空间的 ML 模型推荐结果。
- 在内核空间执行综合生成的逻辑或推荐策略。
- 评估所生成逻辑或推荐策略的效率。
- 执行误差反向传播,以便在用户空间侧对 ML 模型进行修正。
机器学习模型代理的创建、训练与交互流程
ML 模型代理的创建与初始化逻辑,可以由内核子系统在以下时机执行:
- 在模块加载或Linux内核启动时完成创建与初始化。
- 相应地,在模块卸载或内核关闭时执行代理的销毁逻辑。
与此同时,用户空间中的 ML 模型线程也可以:
- 重新初始化内核侧的 ML 模型代理。
- 启动或停止该代理的运行状态。
数据采集与训练流程
首先,ML 模型需要基于来自内核空间的数据进行训练。数据获取可以通过两种方式完成:
- 用户空间主动请求数据(由 ML 模型发起)。
- 内核空间代理主动发布数据(由 ML Model Proxy 输出)。
二者的交互编排可以通过 sysfs 接口 实现。因此,用户空间中的 ML 模型应能够通过以下方式从内核提取数据集:
提取的数据可以被存储到持久化存储中,随后 ML 模型在用户空间访问这些数据并完成训练。
持续学习机制
在训练阶段,可以采用持续学习模型。这意味着,即便模型仍在训练过程中,内核子系统也可以接收并使用 ML 模型的推荐结果。
在这一过程中:
- 内核侧 ML 模型代理会评估当前子系统状态。
- 尝试应用 ML 推荐策略。
- 并评估这些策略的实际效率。
ML 推荐交互的四种运行模式
内核侧 ML 模型代理可以基于模型成熟度与系统状态,采用多种交互模式:
1️⃣ 紧急模式
- 适用场景:内核子系统处于关键/危急状态、负载极高,或 ML 推荐明显不可靠。
- 策略:完全不使用 ML 推荐,仅依赖传统人工算法,以系统效率与稳定性为最高优先级。
2️⃣ 学习模式
- 策略特点:在部分操作中尝试应用 ML 推荐,用于评估模型成熟度与有效性。
- 降级机制:若 ML 推荐效果下降,代理可以将系统运行模式降级回学习模式。
3️⃣ 协作模式
- 目标:在约 50% 操作 中使用 ML 推荐,与传统算法协同运行。
- 用途:加速模型成熟,平衡风险与收益。
4️⃣ 推荐模式
- 进入条件:ML 模型已足够成熟,且推荐策略效率高于人工算法。
- 运行方式:此时内核子系统可主要依赖 ML 推荐逻辑运行。
反馈与模型修正
为了持续优化模型,可以采用反向传播机制。流程如下:
- 内核侧评估 ML 推荐执行效果。
- 将效率评估反馈回用户空间。
- 用户空间据此修正与再训练模型。
总体机制一句话总结
该设计构建了一个 “内核执行 + 用户空间训练 + 持续反馈学习” 的闭环系统:

补丁集提供了如下 18 个核心 API:

应用程序可以通过 sysfs、procfs、字符设备等接口调用上述 API。其中,patch 2 提供了一个参考实现,它通过 sysfs 控制接口和字符设备数据通道,实现了数据采集、用户态训练、内核态推荐执行以及基于效率评估的闭环学习优化。
一个最基础的内核子系统与用户空间 ML 模型协作流程包含以下步骤:
1️⃣ 启动协作
用户空间进程/线程(ML 模型)通过 sysfs 控制接口 向内核子系统发送 START 命令,以启动协作流程。
2️⃣ 请求数据集准备
ML 模型通过 sysfs 控制接口发送 PREPARE_DATASET 命令,请求内核子系统准备训练数据集。
3️⃣ 提取数据集
用户空间通过读取 字符设备 的方式,从内核空间提取数据集内容。
4️⃣ 数据集废弃与更新
数据提取完成后,可以通过 sysfs 控制接口发送 DISCARD_DATASET 命令,将当前数据集标记为过期/废弃,并请求生成新的数据集,然后重复提取流程。
5️⃣ 用户空间模型训练
提取的数据可作为训练数据,在用户空间侧用于 ML 模型训练。
6️⃣ 推理与策略生成
经过若干轮训练后,ML 模型可以执行推理,生成优化建议或改进后的子系统逻辑。
7️⃣ 推荐结果回传内核
ML 模型的推荐结果可以由用户空间进程写入 字符设备,内核子系统读取后用于参数优化、策略调整或逻辑替换。
8️⃣ 推荐策略的应用方式
根据内核子系统当前运行模式,推荐结果可被不同程度地采用:
- 完全忽略
- 部分应用
- 测试验证
- 完全替代默认配置/逻辑
9️⃣ 效率评估
每次应用推荐策略或合成逻辑后,都需要评估其执行效率,例如性能提升/下降、资源利用率变化、延迟/吞吐指标等。
🔟 误差反馈与模型修正
若 ML 推荐导致子系统效率下降,则需要执行 误差反向传播,将效率评估结果反馈至用户空间,用于修正或再训练 ML 模型。
Patchset 还演示了一个使用 ML Proxy 的字符设备驱动示例(用于测试和展示目的)。这表明,如果某个内核子系统想采用这套机器学习代理的方法,就需要在其代码中嵌入相关逻辑。
/* Create sysfs attributes */ ret = sysfs_create_group(&dev_data->device->kobj, &ml_lib_test_dev_attr_group); if (ret < 0) { pr_err("ml_lib_test_dev: Failed to create sysfs group\n"); goto err_device_destroy; } /* Create procfs entry */ proc_entry = proc_create(DEVICE_NAME, 0444, NULL, &ml_lib_test_dev_proc_ops); if (!proc_entry) { pr_err("ml_lib_test_dev: Failed to create proc entry\n"); ret = -ENOMEM; goto err_sysfs_remove; } dev_data->ml_model1 = allocate_ml_model(sizeof(struct ml_lib_model), GFP_KERNEL); if (IS_ERR(dev_data->ml_model1)) { ret = PTR_ERR(dev_data->ml_model1); pr_err("ml_lib_test_dev: Failed to allocate ML model\n"); goto err_procfs_remove; } else if (!dev_data->ml_model1) { ret = -ENOMEM; pr_err("ml_lib_test_dev: Failed to allocate ML model\n"); goto err_procfs_remove; } ret = ml_model_create(dev_data->ml_model1, CLASS_NAME, ML_MODEL_1_NAME, &dev_data->device->kobj); if (ret < 0) { pr_err("ml_lib_test_dev: Failed to create ML model\n"); goto err_ml_model_free; } dev_data->ml_model1->parent->private = dev_data; dev_data->ml_model1->model_ops = NULL; dev_data->ml_model1->dataset_ops = &ml_lib_test_dev_dataset_ops;
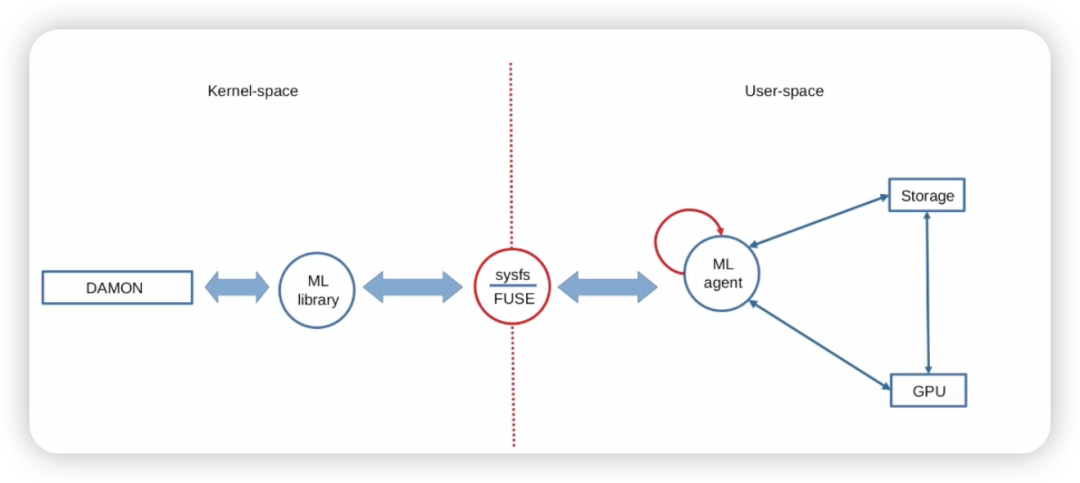
目前,这个 Patchset 提供的还是一个框架,并没有展示任何一个真实内核子系统应用此机器学习代理进行优化的完整例子。一个潜在的应用场景是 DAMON,它可以通过分析内存访问模式来优化内存管理策略。
这个提议为 Linux 内核的智能化演进打开了一扇新的大门,其设计思路兼顾了内核的稳定性与机器学习的前沿性。对于任何对系统底层优化和人工智能交叉领域感兴趣的朋友而言,这份 RFC 都值得深入研读。
参考文献
[1] https://lore.kernel.org/lkml/20260206191136.2609767-1-slava@dubeyko.com/
[2] https://www.youtube.com/watch?v=E7q0SKeniXU
 发表于 2026-2-10 05:17:32
|
查看: 137|
回复: 0
发表于 2026-2-10 05:17:32
|
查看: 137|
回复: 0
