大模型火爆的今天,不少人将其奉为时序预测、金融量化等领域的“万能钥匙”,但它真的名副其实吗?多项实验研究揭示了一个令人意外的事实:当参数规模达千亿级的Transformer架构,遇上看似“简单”的时序预测任务,其表现竟屡屡输给参数仅数万级别的经典线性模型。这一失利并非偶然,而是Transformer底层架构的本质缺陷所致,即便投入海量算力进行训练,也终究难以弥补这些根本性的短板。
LLM vs 线性模型的实验证据
多项学术研究为上述结论提供了有力支撑:
- 论文 《Understanding Why Large Language Models Can Be Ineffective in Time Series Analysis: The Impact of Modality Alignment》 对大语言模型(LLM)进行了一系列实验。结果显示,在长期预测、插补、异常检测、分类这四大时序核心任务中,Transformer及其衍生的时序大模型全面落后于线性模型。
- 论文 《Why Do Transformers Fail to Forecast Time Series In-Context?》 则从理论上直接证明:即使最优参数化的Transformer,其期望均方误差(MSE)也无法低于经典的线性模型。
- 论文 《Performance of Zero-Shot Time Series Foundation Models on Cloud Data》 发现,使用针对时序数据训练的基座时序大模型进行零样本(zero-shot)预测时,仅因输入上下文的微小变化,模型就可能从看似合理的预测突变为随机乱序的输出。
那么,究竟是什么原因导致了Transformer在时序预测上的“水土不服”?我们可以从以下三大核心缺陷进行解析。
1. 特征空间局限:上限锁死
Transformer的核心——自注意力机制,其本质是线性自注意力(Linear Self-Attention, LSA),可以被视作线性回归的一种“受限压缩表示”。其理论特征空间被严格限定在三次多项式的范围内。
具体来说,LSA的输出可以推导为三次多项式特征的线性组合。利用立方特征映射引理可以证明,LSA的预测能力被严格限定在“三次多项式空间”内,无法有效捕捉时序数据中普遍存在的强衰减自相关性等更为复杂的动态模式。
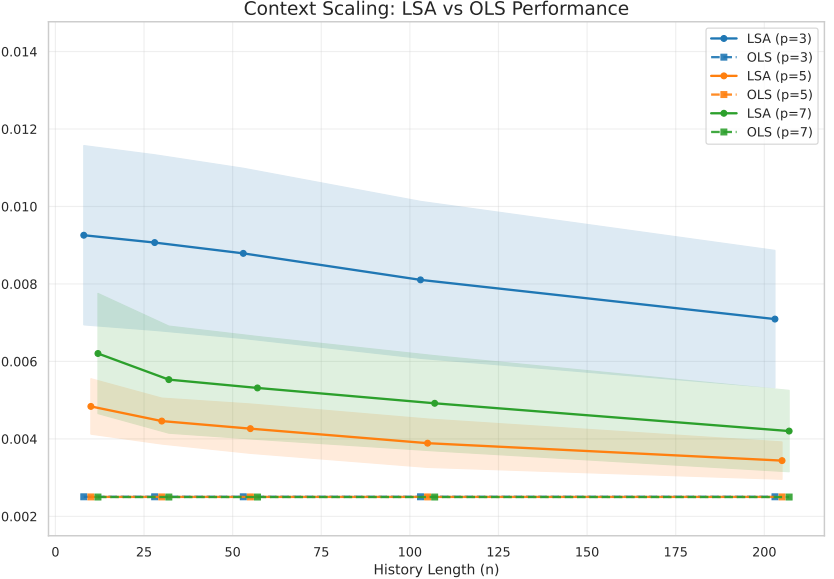
上图展示了LSA与普通最小二乘法(OLS)在不同历史长度(n)下的性能对比。随着历史长度增加,所有模型性能下降,且LSA在多数情况下虽优于OLS,但其能力天花板已被理论锁定。
2. 模态适配失效:“伪对齐”无法激活有效知识
时序数据的连续数值特性与Transformer为离散文本设计的架构存在本质上的割裂。现有的LLM时序适配技术(如对LayerNorm进行微调、使用跨注意力进行对齐等)通常仅能将时序数据的统计分布(如质心)映射到语言模型熟悉的分布(例如标准正态分布N(0,1)),但并未改变数据内在的流形结构。这导致了一种“伪对齐”(Pseudo-Alignment)现象。
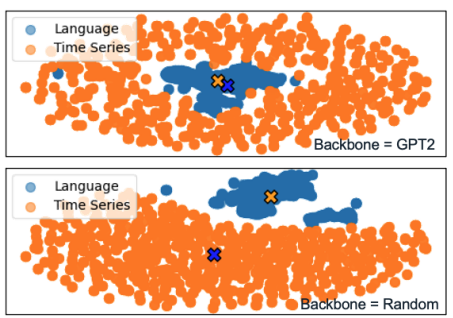
如上图所示,即使经过对齐,时序数据(橙色点)与语言数据(蓝色点)在特征空间中依然保持各自的聚集形态,未能真正融合。这意味着LLM强大的语言推理和世界知识从未在时序任务中被真正激活。模型所展现出的任何预测能力,实际上仅源于时序数据自身的稀疏性、周期性等内在结构,而非Transformer的理解能力。
3. CoT推理陷阱:误差复利导致预测坍缩
在多步预测场景中,大模型常用的思维链(Chain-of-Thought, CoT)推理模式反而成了“性能杀手”。理论分析证明,在自回归预测过程中,CoT推理会形成一个稳定的线性动力系统,导致预测值以指数级速度坍缩到序列的均值,而预测误差则以指数速率累积到过程的方差上。
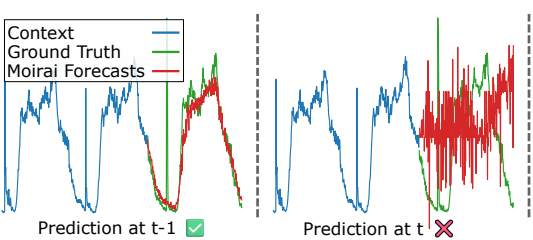
实验观测印证了这一点。如上图所示,某些时序大模型(如Moirai)在t-1时刻还能做出相对合理的预测(绿色虚线),但在t时刻的预测(红色实线)已严重偏离真实值(蓝色实线)。在实际测试中,LLM使用CoT进行的多步预测,往往在不到10步之后,其输出就变得与随机猜测无异。
总结与启示
当整个行业仍在为千亿参数大模型的涌现而欢呼时,这些严谨的实验与理论分析无疑是一剂及时的清醒剂。它们有力地表明,在时序预测这一特定领域,“简单有效”的原则往往胜过“复杂冗余”。大模型并非万能,盲目套用可能事倍功半。
回归任务本质,理解数据特性,并选择与之最适配的建模架构,才是时序分析,尤其是在金融量化等对精度和稳定性要求极高的场景中,所应秉持的正确方法论。这也提醒广大开发者和研究者,在拥抱新技术浪潮的同时,保持对基础理论和模型局限性的洞察同样至关重要。欢迎在云栈社区交流更多关于机器学习模型选型与实战的经验。 |  发表于 2026-2-10 05:03:09
|
查看: 191|
回复: 0
发表于 2026-2-10 05:03:09
|
查看: 191|
回复: 0
