
近期,由KAIST研究人员Minho Ha、Euiseok Kim和Hoshik Kim在IEEE Computer Architecture Letters上发表的一篇论文,提出了名为H³的混合内存架构。这项研究针对当前大语言模型推理中面临的核心硬件瓶颈,提出了一种融合高带宽内存(HBM)与高带宽闪存(HBF)的创新方案。对于关注深度学习硬件优化的开发者而言,这项研究指明了打破内存容量限制、降低推理成本的一条新路径。
核心挑战:当序列长度爆发,HBM容量捉襟见肘
大语言模型正从聊天机器人向研究助手、智能体(Agent)和多模态方向快速演进,一个显著的特征是模型支持的上下文长度(Sequence Length)呈爆发式增长。
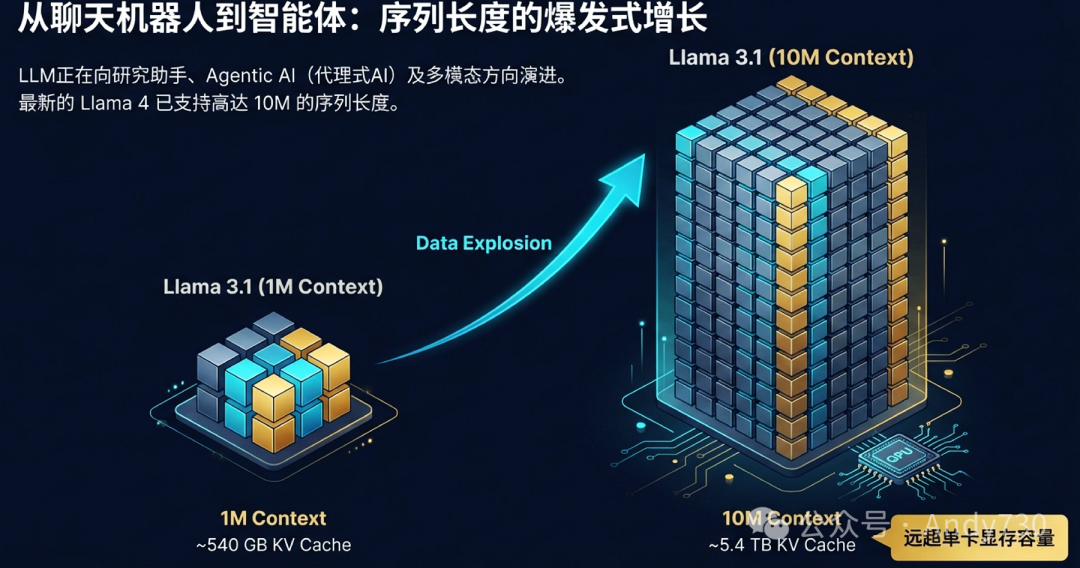
以最新的Llama模型为例,上下文长度已从1M(百万)迈向10M(千万)。这带来了一个极其严峻的问题:存储预计算的键值缓存(KV Cache)所需的内存容量急剧膨胀。在Llama 3.1 405B模型下,1M上下文的共享KV Cache约需540GB,而10M上下文则暴涨至约5.4TB。

如此庞大的数据量远超单张GPU显存(HBM)的容量。当前的解决方案是堆叠GPU,利用多卡的HBM来共同存储这些数据。但这导致了严重的资源错配和成本失控:为了利用GPU的显存,我们不得不支付其昂贵算力的费用,而算力却在大部分时间里被闲置。
破局者:高带宽闪存(HBF)的双刃剑
为解决容量危机,产业界开始探索高带宽闪存。HBF通过垂直堆叠NAND芯片,并模拟HBM接口,实现了与HBM相当的带宽(~8 TB/s),同时容量可达到HBM的16倍(单堆栈约3TB)。
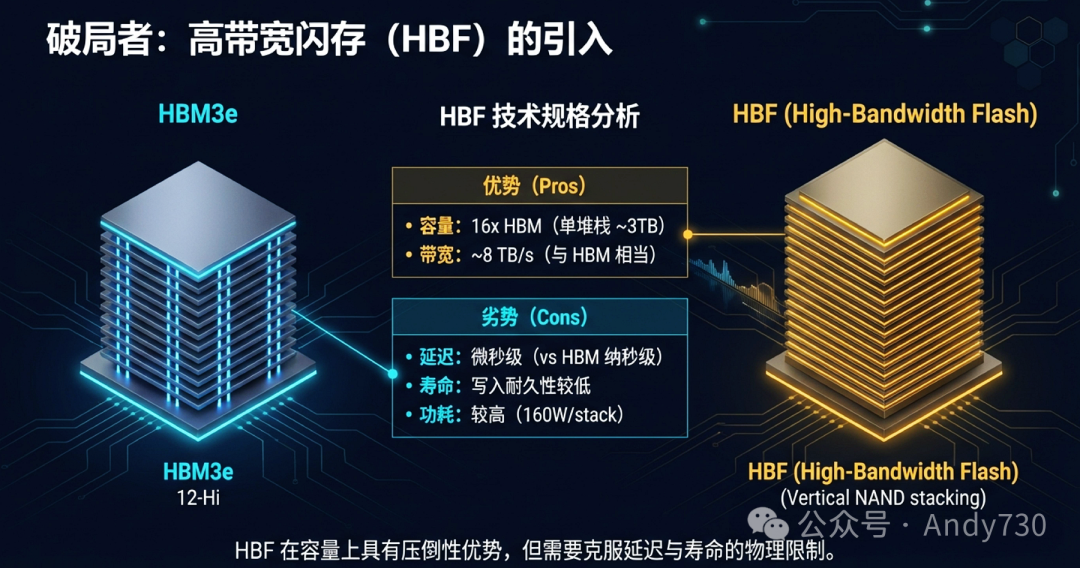
然而,HBF是一把双刃剑。其优势在于海量容量和可观带宽,但劣势同样突出:
- 延迟高:访问延迟在微秒级,相比HBM的纳秒级慢了上千倍。
- 寿命有限:NAND闪存的写入耐久性远低于DRAM。
- 功耗高:单体功耗可能达到HBM的4倍(约160W/stack)。
那么,有没有办法既能利用HBF的海量容量,又能规避其致命缺陷呢?H³架构的提出,正是基于一个对LLM推理工作负载的关键洞察。
核心洞察:LLM推理的“巨型只读”特性
研究人员发现,在长序列推理场景下,绝大部分数据是只读的。这主要包括两部分:
- 模型权重(Weights):例如Llama 3.1 405B模型,FP8精度下约405GB,在推理过程中恒定不变。
- 共享预计算KV Cache:在缓存增强生成(CAG)等场景中,这部分数据可高达数TB,同样在请求处理过程中仅被读取。

而需要频繁读写的动态数据(如每轮推理新生成的KV Cache、激活值等)占比通常小于10%。这种“巨型只读”的数据特性,完美契合了HBF的优缺点:我们可以将海量只读数据存入HBF,充分利用其大容量,同时因其“只读”而彻底规避了写入寿命短的短板;而将需要低延迟访问的动态数据保留在HBM中。
H³架构详解:融合速度与容量的物理设计
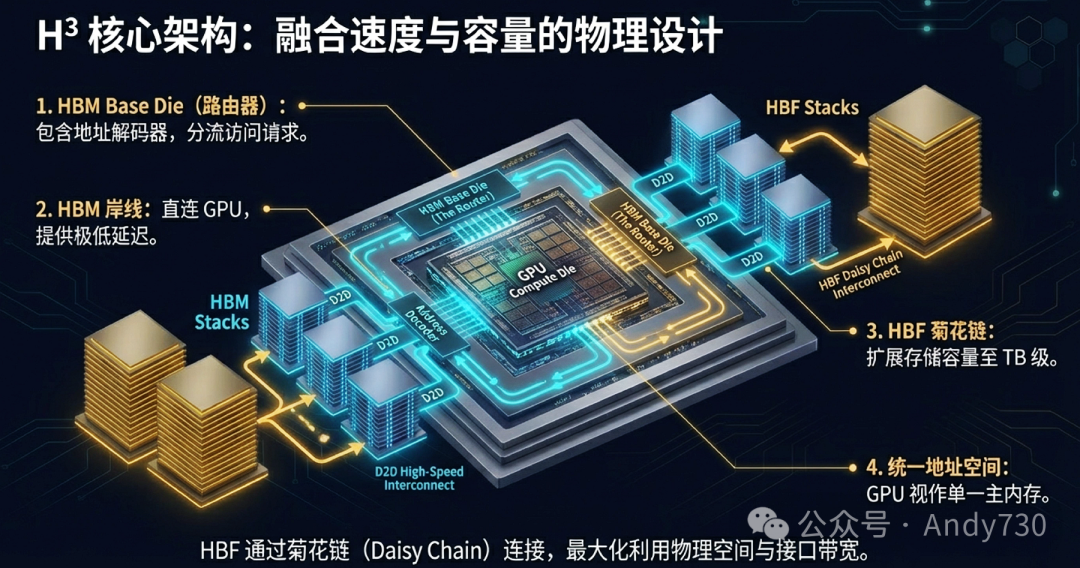
H³不是简单地将HBM和HBF并排放置,而是通过精妙的拓扑结构将其深度融合。
-
菊花链拓扑与统一地址空间:HBF并非直接连接GPU,而是通过“菊花链”(Daisy Chain)方式连接到HBM的基板芯片上。HBM基板芯片内集成了一个“路由器”(包含地址解码器)。这样,GPU发出的内存访问请求会先到达HBM基板,由路由器判断地址属于HBM还是HBF,并进行路由。对于GPU而言,它看到的是一个统一的、容量巨大的连续地址空间,无需感知底层是HBM还是HBF。
-
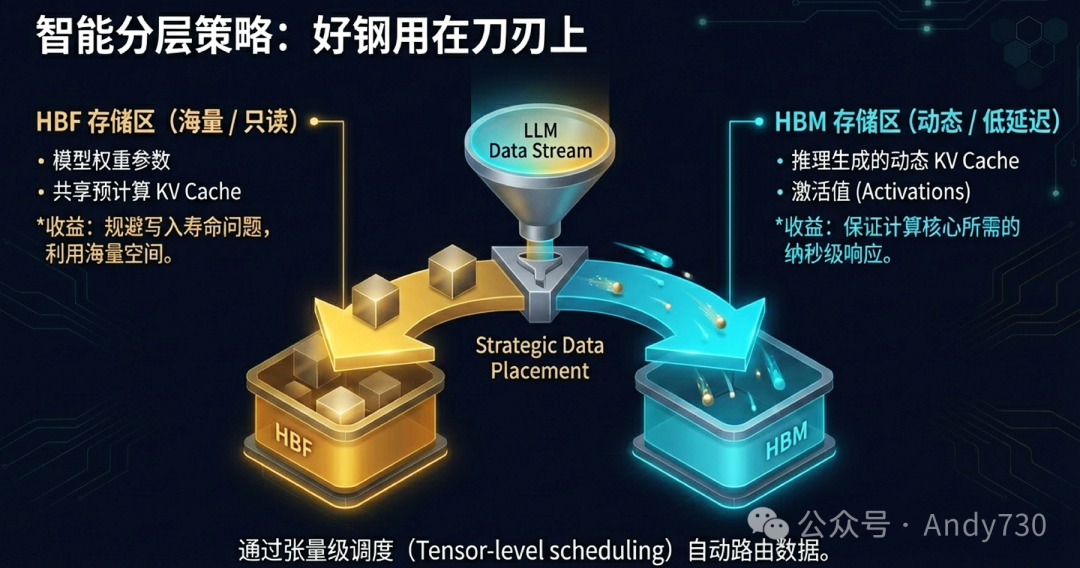
智能分层数据放置:系统在软件层面进行张量级调度。
- HBF存储区:存放模型权重和共享预计算KV Cache等只读海量数据。
- HBM存储区:存放推理时动态生成的KV Cache、激活值等需要低延迟访问的数据。
攻克最大障碍:用LHB缓冲区掩盖HBF延迟
HBF微秒级的延迟是必须解决的核心挑战。H³的解决方案是预测与预取。
由于LLM推理是逐层(Layer by Layer)进行的,计算模式非常确定。系统可以在计算当前层时,就预测出下一层需要哪些权重和KV Cache数据,并提前发出预取指令。
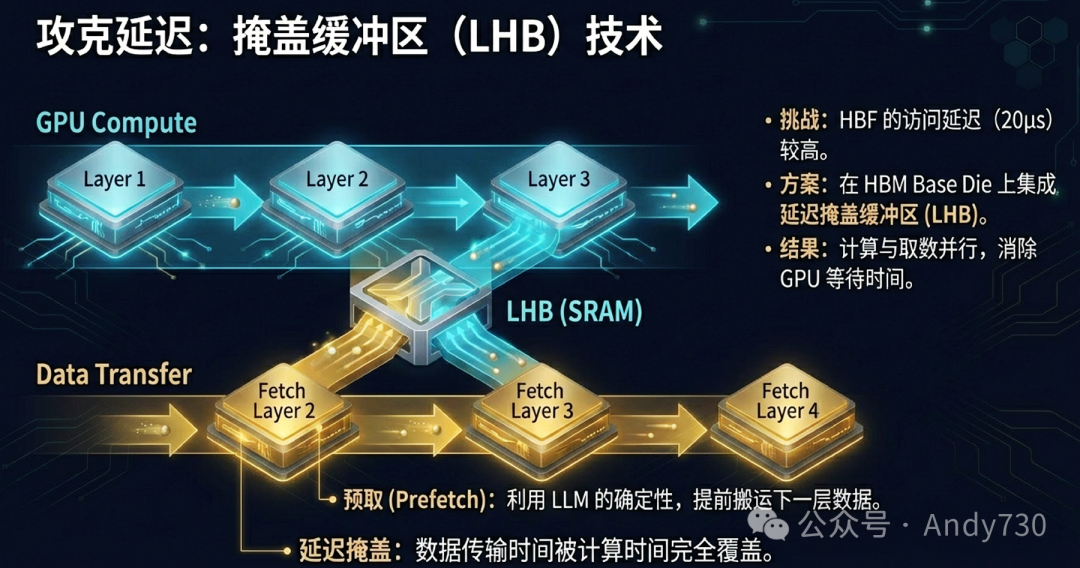
延迟掩盖缓冲区(LHB) 被集成在HBM基板芯片上。预取的数据会从HBF提前搬运到LHB中。当GPU计算完当前层,需要下一层数据时,数据已经静静地在LHB里等待了,GPU可以直接以HBM级别的延迟获取数据,完全感知不到HBF的访问延迟。
那么,这个缓冲区需要多大?论文给出了计算:Capacity_LHB = 2 × BW_HBF × Latency_HBF。假设HBF带宽为1TB/s,延迟为20μs,则LHB容量约需40MB。
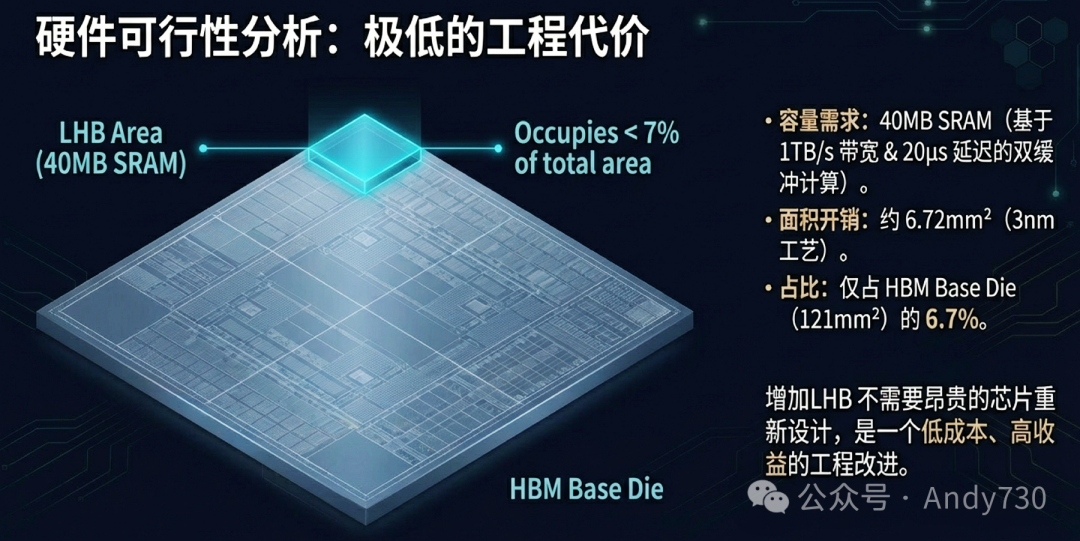
采用3nm工艺,这块40MB的SRAM面积约为6.72mm²,加上外围电路,总面积约8.06mm²,仅占HBM基板芯片面积(约121mm²)的6.7%。这意味着增加LHB是一个低成本、高回报的工程改进,无需昂贵的芯片重新设计。
性能评估:吞吐量与能效的显著提升
研究人员使用内部验证过的模拟器进行评估,工作负载为Llama 3.1 405B模型(1M和10M上下文)。基准系统是纯HBM方案,H³系统则是在此基础上加入3TB HBF。
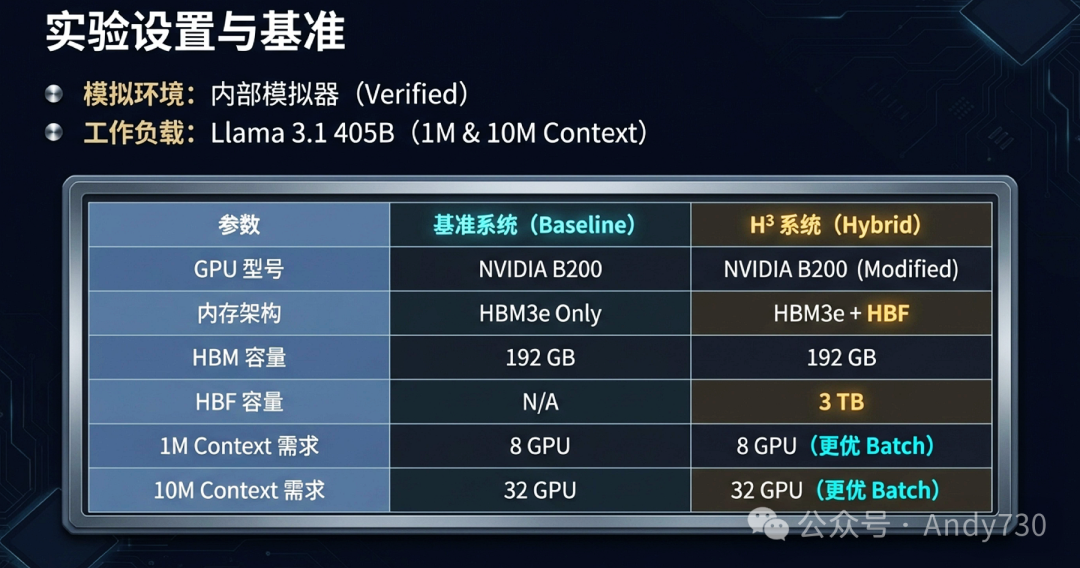
1. 批处理能力大幅释放
H³将海量只读数据卸载到HBF,释放了宝贵的HBM空间。这使得系统能够在单次处理中容纳更大的批次(Batch Size)。

模拟结果显示,在1M上下文场景下,最大批处理大小提升了2.6倍;在10M上下文场景下,提升了1.8倍。这意味着单台8-GPU服务器就能处理1M序列,而处理10M序列的门槛也从32 GPU大幅降低。
2. 吞吐量成倍增长
批处理大小的增加直接带来了吞吐量(Tokens Per Second)的爆发式增长。
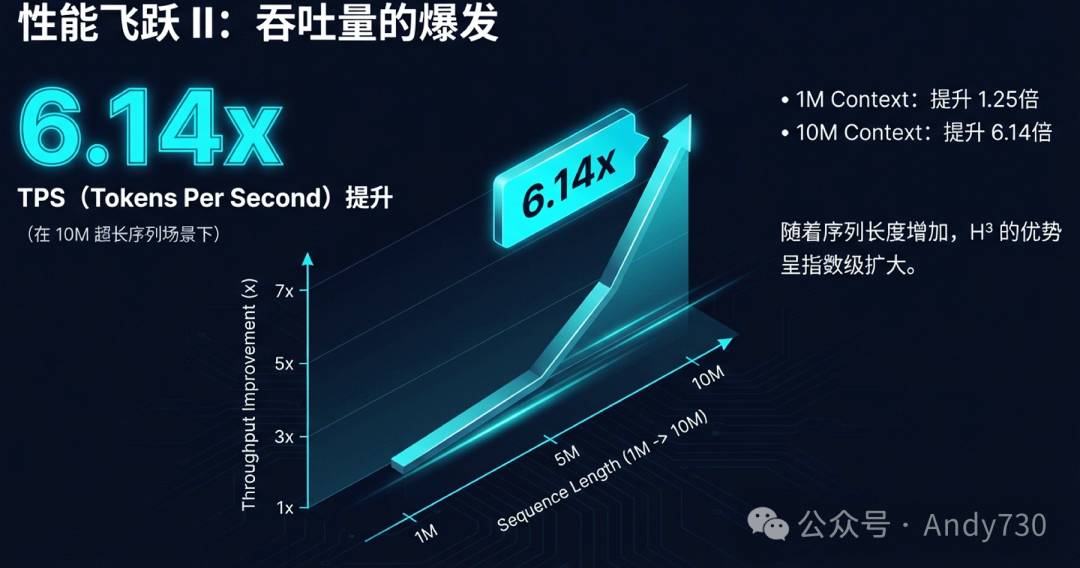
在10M上下文这一极具挑战性的场景下,H³系统的吞吐量达到了纯HBM系统的6.14倍。优势随着序列长度的增加而呈指数级扩大。
3. 能效与成本优化
尽管HBF单体功耗较高,但由于系统整体吞吐量获得了巨大提升,单位功耗吞吐量(Throughput per Watt)反而实现了近3倍的飞跃。

这意味着完成同样的推理任务,H³系统能耗更低。从硬件成本看,用2块搭载H³的GPU即可完成过去需要32块纯HBM GPU才能运行的10M上下文任务,硬件成本和机架空间得以极大优化。
总结与展望

H³架构为长序列LLM推理的“内存墙”问题提供了一个兼具创新性与实用性的硬件解决方案。它通过架构创新融合了HBM的速度与HBF的容量,通过精准定位专为LLM推理的只读特性而设计,最终实现了极致的效能提升。
这项研究的意义不仅在于一个具体的架构设计,更在于它揭示了一种设计哲学:在计算机体系结构层面,针对上层负载(如LLM)的独特数据访问模式进行深度定制和协同优化,是突破通用硬件瓶颈、实现跨越式性能提升的关键。未来,类似的混合存储思想有望扩展到科学计算、数据库等其它巨型只读工作负载中。

主要设计要点回顾:
- 解决问题:针对LLM长序列推理的HBM容量瓶颈。
- 核心思路:利用LLM推理的“巨型只读”特性,用HBF存只读数据以规避其写入寿命短板。
- 关键技术:菊花链拓扑实现统一寻址;LHB缓冲区通过预取掩盖HBF高延迟。
- 主要收益:显著提升批处理大小和系统吞吐量,大幅改善能效比与硬件成本。
- 生态依赖:需要硬件、驱动、深度学习框架(如PyTorch)的深度协同以发挥最大价值。
参考文献:
Ha, M., Kim, E., & Kim, H. (2026). Hybrid Architecture Using High Bandwidth Memory and High Bandwidth Flash for Cost-Efficient LLM Inference. IEEE Computer Architecture Letters, Early Access, 1-4. https://doi.org/10.1109/LCA.2026.3660969
对这类前沿硬件架构如何影响软件栈和开发模式感兴趣的朋友,欢迎在云栈社区的人工智能板块继续深入探讨。
 发表于 2026-2-9 09:17:54
|
查看: 216|
回复: 0
发表于 2026-2-9 09:17:54
|
查看: 216|
回复: 0
