本文主要介绍 1688 在 NPU 端侧推理加速的实践,并分享我们在应对生态碎片化与突破性能瓶颈过程中的核心实践与关键技术路径。
1、背景
1.1 项目前身
在去年的鸿蒙项目中,我们曾在 App 端内部署模型来尝试基于用户动线意图的 AI 内容投放。但由于集团自研的推理引擎 MNN 当时尚未提供鸿蒙版本,我们便将目光转向了厂商提供的推理方案,并着手开展相关研究。
1.2 行业趋势与落地挑战
当前,终端设备的形态呈现加速多元化的特点,从传统的智能手机拓展到手表、AR眼镜、机器人等多种形态。


与此同时,模型的参数量也在不断扩增,从早期的百亿级参数发展到现在的千亿级乃至更大规模。这种发展趋势使得终端需要具备更强的计算能力和存储能力来支撑模型的稳定运行。
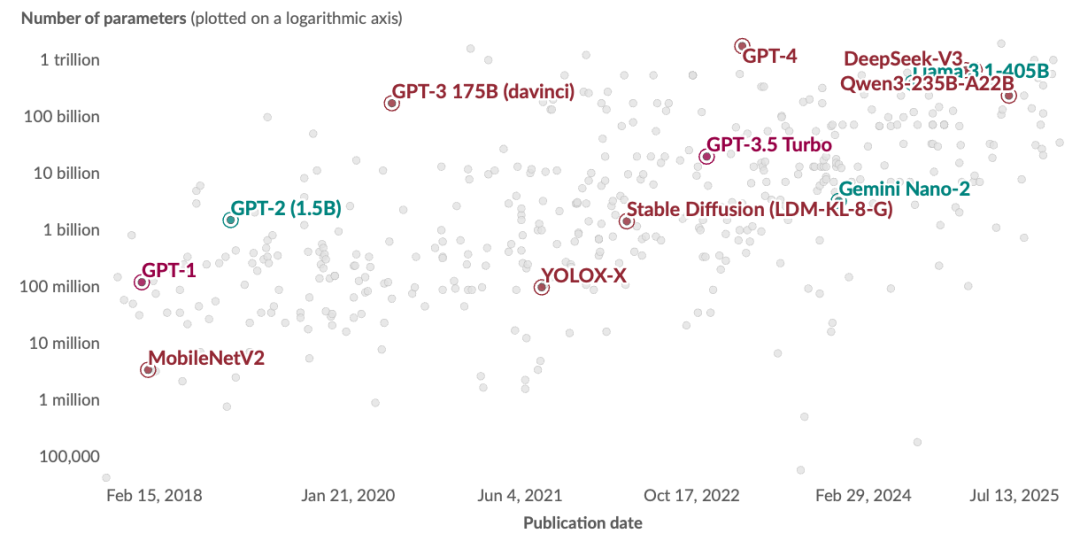
面对终端形态与模型规模的双重演进,行业在拥抱 AI 普惠的同时,也暴露出一系列落地挑战:在资源受限和生态分散的终端设备下,模型的高效部署、碎片化与性能问题日益突出。
1.3 碎片化问题
- OS 碎片化:Android、iOS、HarmonyOS 等不同操作系统的差异导致应用需要多次开发适配
- SoC 碎片化:不同手机厂商的芯片组(SoC)存在巨大差异,甚至同一厂商的不同版本 SoC 也存在区别
1.4 性能问题
- 算力受限:终端设备的计算能力远低于服务器,难以满足大模型的计算需求
- 内存紧张:模型加载和推理过程需要大量内存,容易导致内存溢出(OOM)
- 功耗敏感:长时间的推理计算会大幅消耗电池电量或引起发热,影响用户体验
2、AIService SDK(AI 能力服务)
2.1 碎片化问题举例
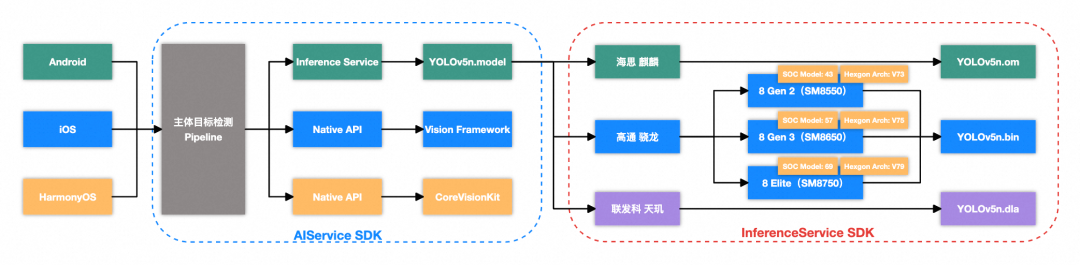
为实现三端(iOS、Android、HarmonyOS)统一的“主体检测”能力,需应对以下关键差异:
- OS 碎片化:iOS 和 HarmonyOS 分别提供系统级视觉 SDK(Vision Framework 和 CoreVisionKit),可直接调用;而 Android 缺乏统一的内置方案,需自行部署轻量模型进行端侧推理。
- SoC 碎片化:为充分发挥 NPU 性能,模型需针对不同厂商甚至同厂商不同代际的 SoC 适配专属推理后端,例如华为使用 CANN,高通则依赖 QNN,增加了跨平台部署的复杂性。
2.2 AIService SDK 的设计
为了解决终端生态的碎片化问题,我们设计并实现了 AIService SDK ,形成从本地到云端的完整 AI 能力体系。
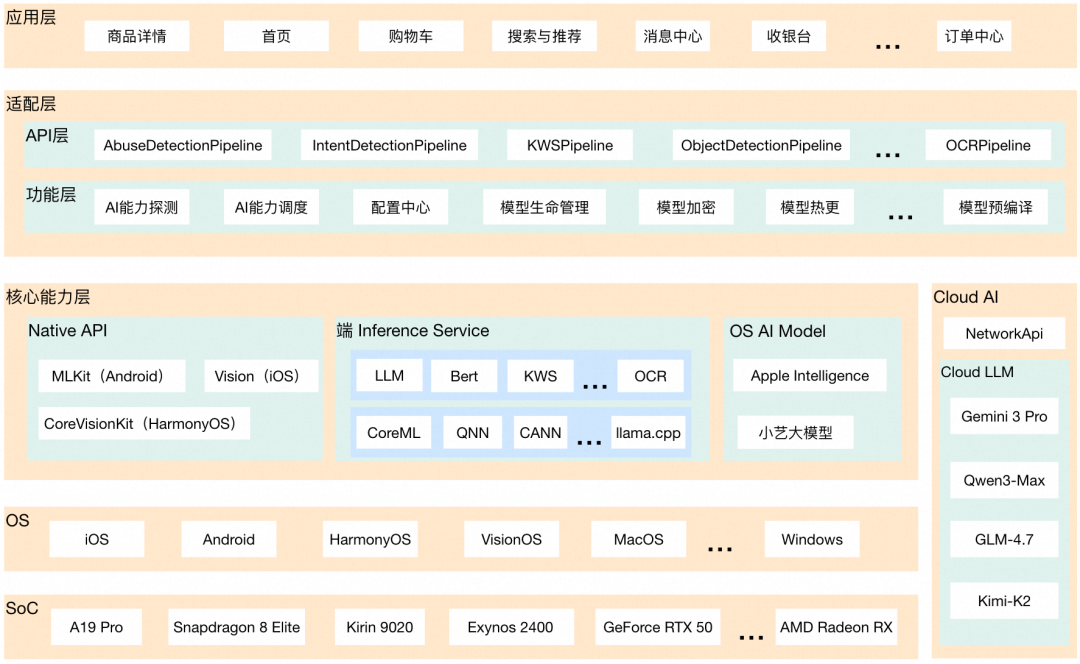
通过制定统一的 API,确保不同操作系统的输入输出保持一致,类似于 Web 开发中的 JSBridge 的设计思想。这样应用层的代码无需关心底层的 OS 差异,直接调用统一的 API 即可完成 AI 能力的调用。
核心能力层的四个能力模块形成了一个完整、高效、灵活的端云结合 AI 能力支撑体系:
- 【Native API】提供各操作系统原生的 AI 开发 API 和能力支持
- 【端 InferenceService】负责在设备本地执行 AI 模型推理计算,提供设备端的 AI 推理服务
- 【OS AI Model】提供操作系统级别的模型能力和系统级智能服务
- 【Cloud AI】提供云端 AI 服务能力,利用云端强大的计算资源支持高级 AI 能力
该架构已纳入 智能 & 数据 & 云 技术板块,涵盖神经网络、模型训练、边缘推理等关键能力。
3、InferenceService SDK(端推理服务)
3.1 推理服务而不是推理引擎
| 维度 |
推理引擎(Engine) |
推理服务(Service) |
| 定位 |
计算执行器:负责模型加载、算子调度、硬件加速等具体计算 |
上层协调者:提供统一 API、管理生命周期、调度引擎运行 |
| 职责 |
“怎么跑” —— 高性能执行推理 |
“让谁跑、何时跑、如何暴露” —— 服务化治理 |
| 例子 |
MNN、ONNX、Apple Core ML、华为 CANN、高通 QNN |
自研 Inference Service 框架 |
推理引擎是底层计算执行器,负责模型加载、算子调度和硬件加速,解决“怎么高效跑”的问题;而推理服务是上层协调者,提供统一API、管理引擎生命周期、处理任务调度与资源协调,解决“让谁跑、何时跑、如何对外暴露能力”的服务化治理问题。
我们做的是推理服务而不是推理引擎,目前为了让模型能够跑在厂商的 NPU 上,对接的都是厂商的推理引擎:Apple 的 CoreML 和 高通的 QNN 等。
推理引擎对于推理服务而言是可插拔的,在今年 9 月份我们跟集团 MNN 的同学有过沟通,了解到他们也在对接厂商的推理后端,不过当时还未成熟。MNN 的推理引擎我们早已接入,业务有需要也能进行无缝切换。
3.2 InferenceService SDK 的设计
为了解决性能问题,面向厂商 NPU 方案我们设计并实现了 InferenceService SDK ,让模型在端内推理更高效、更稳定。

这是一个专为终端推理打造的跨平台 SDK,目前已覆盖 HarmonyOS、iOS 和 Android 三大主流平台。它提供一套统一的 API,让你不用为每个平台重写一遍逻辑;同时深度调用各系统的原生硬件加速能力(比如 NPU),让 AI 计算跑得更快、功耗更低。目前我们借助开源社区,已经将一些常用的模型在 NPU 上跑通:
- 大语言模型:Qwen2.5-1.5B-Instruct、Qwen3-0.6B、Qwen3-1.7B
- 语音识别(Speech):FSMN-Monophone VAD、Paraformer ASR Online、PUNC CT Transformer
- 视觉模型:YOLO5、YOLO11
- 自然语言处理:TinyBert
3.3 推理服务的核心能力
在聊“能力”之前,想先澄清一个常见的认知偏差——可能很多同学以为我们的解决方案,就是简单地“接个 SDK、调个 API”,然后神奇的能力就自动冒出来了。
其实,现在的推理引擎为了让大家用得顺手,确实封装了很多开箱即用的上层 API。但本质上,推理引擎的核心工作非常“朴素”:它就像一个超级算力黑盒——你把模型加载好,再丢进去一堆数据(通常是张量),它吭哧吭哧算一阵子,最后吐出另一堆张量。
至于这些输入输出的张量到底代表什么?是语音识别的结果?是用户情绪识别的结果?还是检测出主体的位置?这些都不在引擎的职责范围内。它只管算,不管“懂”。这就延伸出 InferenceService SDK 的两个核心能力:
(1)不同模型运行的 Pipeline:不同类型的模型会有不同的运行流程,需要按照模型的运行逻辑写好任务流水线。以 LLMPipeline 为例,除了推理之外,预处理阶段得有提词器处理输入的 Prompt,后处理阶段需要对 token 概率分布进行对应规则的采样,还需要有一个全盘控制自回归流程的逻辑。
(2)不同推理引擎的适配:不同的推理引擎接口不一致,数据的输入和输出不一致,需要由一个统一的适配层来进行打平。输入输出以通用的 Tensor 类型传输,针对 LLM 推理,支持 prefill/decode 方法名注入。
3.4 模型部署流程
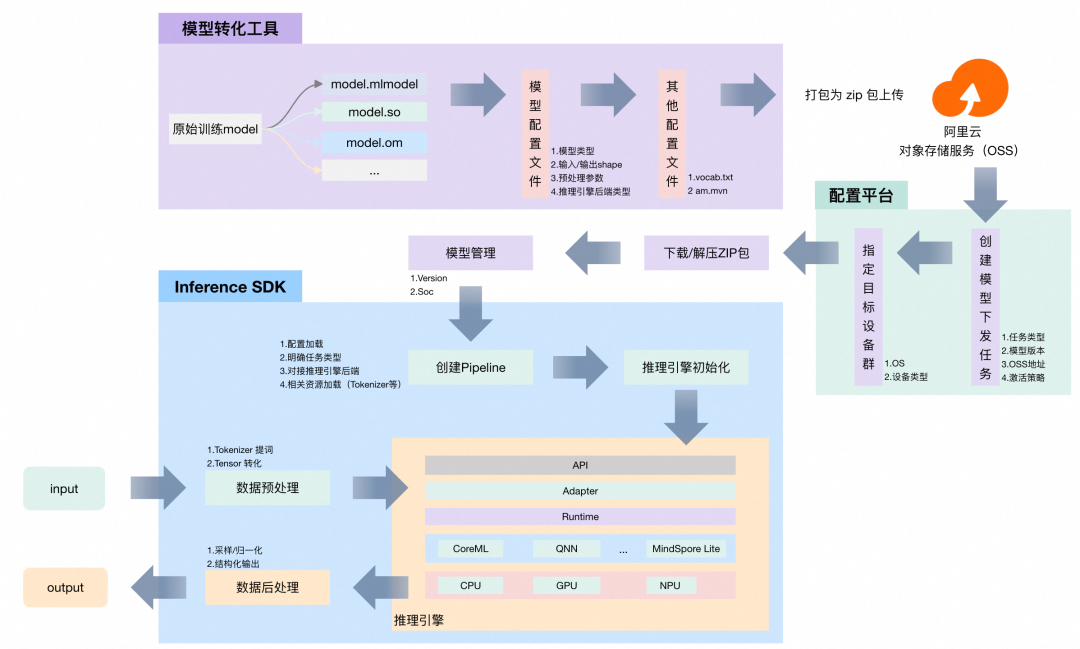
实现"一次训练,多端部署"的流程,主要包含三个关键环节:
- 工具统一转换:利用统一的模型转换工具,将训练得到的模型转换为多种格式,支持不同推理引擎
- 配置平台精准分发:通过配置平台根据设备的硬件能力、操作系统版本、SoC 类型等信息,精准分发适配的模型版本和配置文件
- Pipeline 自适应推理:推理引擎在运行时动态调整推理策略,如对应模型运行的流水线、选择哪一个推理引擎、输入输出格式等,以适应不同设备的约束条件
4、面向 NPU 的推理方案
4.1 NPU 是什么

以 Apple 今年发布的 A19 SoC 为例,左上角是 CPU、右上角是 GPU、左下角就是 NPU,从整个架构图中可以知道:NPU 与 CPU、GPU 处于同一层级;NPU,即神经处理单元,是一个独立的计算单元。
CPU 与 GPU 的区别已广为人知,而 NPU 的核心优势在于其高度专业化:它将特定类型的计算逻辑直接固化在硬件中,使得 NPU 在执行其原生支持的运算时,能够以显著更低的功耗和更高的效率完成任务,能效远超通用处理器。它类似于 GPU,但 NPU 不是加速图形处理,而是加速神经网络运算,例如卷积和矩阵乘法。
然而,这种优势是有前提的,有且仅当模型中所有的算子都在 NPU 的硬件支持列表之内时,才能正常在 NPU 运算,充分发挥其性能。由于缺乏可编程性,NPU 的泛化能力很弱,难以灵活应对不被其硬件原生支持的运算。所以,自定义层、自定义算子去优化模型运行在 NPU 上这条路是不可行的。
4.2 NPU 是推理最强的吗
很多同学会问一个问题:“模型跑在 NPU 一定比 GPU 强吗?”,我们每次都是这样回答的:“两个计算单元如果在同样硬件规格下,并且对应模型的结构和算子 NPU 都支持,那 NPU 一定比 GPU 强,而且强不少”。
这就好比你组装了一台 PC 主机:CPU 用的是 Intel i3,GPU 却配了 NVIDIA RTX 5090。你能因此断言 GPU 一定比 CPU “更强”吗?其实不然——它们的定位本就不同。所以强弱取决厂商 SoC 的设计,会综合考虑功耗、面积、成本和目标应用场景等诸多因素,为 CPU、GPU、NPU 计算单元分配不同的硬件资源。
要是用户手机主要是用来玩王者、三角洲、原神这种游戏,结果 GPU 给得抠抠搜搜,NPU 却堆到天花板——那别说发烧友了,连我这个轻度玩家都想把手机扔了。而且看 Apple 的 M 系列的 Max / Ultra 芯片,GPU 给的多足?因为一堆用户拿 MacBook 剪 4K/8K 视频,GPU 不顶谁买?
其实我们实测下来也发现:跑模型这事也不能一刀切,还是要根据模型本身的结构和运行逻辑出发去分析。对于 LLM 的 decode 阶段来说本身瓶颈就在于内存带宽,走 CPU 和 NPU 的差距都很小。但对于 Bert 这类计算密集的模型来说 CPU 和 NPU 完全不一样,差距能高到十几倍。
4.3 NPU 推理的优势
- 计算独占:在 NPU 上运行模型可释放 GPU 用于图形任务、CPU 用于应用逻辑,并为推理提供更稳定、低干扰的执行环境,充分发挥 NPU 的专用架构优势。
- 快的多:关于推理速度前面也简要分析过,高度依赖具体模型结构,不可一概而论。对于计算模式匹配 NPU 优化特性的模型,在 NPU 上可显著加速;反之则收益有限。
- 更节能:在执行模型推理时能效比更高,能显著降低功耗,有效控制设备温升避免过热,从而大幅减缓电池消耗。
- 除此之外:推理引擎还会针对 NPU 推理做很多优化,不仅仅只是计算逻辑上,还有内存分配上,这点会在后续 ANE(Apple 的 NPU 方案)实践部分展开讲。
4.4 对接 NPU 需要做什么?
4.4.1 一套 Pipeline
用于确定处理的模型种类与对接的推理引擎。例如要将 LLM 模型运行在设备的 NPU 上,需要有两个关键环节:一是构建适配的 LLMPipeline,二是通过对应平台的推理引擎完成集成和部署。


LLM 的运行 Pipeline 与推理引擎解耦,支持灵活插拔;实际推理过程面向 SoC 进行。
4.4.2 模型转换,推理引擎 & NPU 支持的格式
目前我们主要基于 PyTorch 模型进行开发,在对接 NPU 时,通常是在原有模型逻辑的基础上,利用 PyTorch 的 Python 接口(torch API)根据目标 NPU 进行针对性调整和适配,并结合厂商提供的工具(如 Apple 的 coremltools,Qualcomm 的 Qairt)完成模型格式的转换。
使用厂商的推理引擎并不等于模型一定会在 NPU 上运行。以 CoreML 为例,即使在代码中指定了设备选项为 .cpuAndNeuralEngine(NPU 优先级最高),如果转换后的模型包含 NPU 不支持的算子、动态 shape、非对齐张量维度,或使用了不兼容的数据类型,仍会自动将整图(描述模型运行逻辑)或部分子图降级到 CPU 执行。

因此,能否真正利用 NPU 加速,取决于模型在转换时是否满足其硬件和算子限制,不仅仅是运行时手动选择的计算单元。这也意味着,模型适配需要前置到转换阶段,而非依赖厂商推理引擎自动去处理。
4.5 模型转换核心知识点
模型转换需掌握三个核心知识点:理解模型原理、熟练 PyTorch 张量操作、熟悉目标硬件约束。其中后两者相对固定,可复用;而模型原理需在实践中持续积累与深化。
-
理解模型原理:需要理解模型的运行流程以及核心的机制。以 LLM 为例,不仅仅需要知道 "token → Embedding → Multi Transformer Layers → LM Head → token 概率分布" 的完整流程,还需要知道 Transformer 架构以及里面有哪些层,主要用了哪些算子。不需要深入每个算子的数学推导,但需要明白其功能与在流程中的角色。例如,Qwen3 引入的 Q/K 张量归一化,虽是一个细节改进,但也需要考虑进去。
-
PyTorch 与张量操作:在实际对接 NPU 时,PyTorch 的使用要聚焦于张量操作和模型构建的基本功:比如熟练处理维度变换、正确加载权重,以及通过继承 nn.Module 搭建自定义模块,同时要清楚常用层的用法和内部逻辑。
-
目标硬件特性:目标硬件往往有严格限制——例如输入输出 shape 必须静态固定,不支持动态维度,且不同 NPU 对算子的支持也不同(像 ANE 不支持 RMSNorm,但 QNN 和 CANN 可以),这些约束直接影响模型能否顺利部署。
前面有提到一个词叫“图”,它是模型运行逻辑的核心表达。模型转换的本质:保持输入输出语义一致的前提下,对计算图进行重构与优化,使其内部所有操作均符合目标 NPU 的约束与要求。
4.6 上手路径
一个新的场景,一种新的模型结构,通过原生推理引擎在设备搭载的 SoC NPU 上推理,主要可以分为以下几步进行:
-
第一步:找一个合适的基于 PyTorch 的开源模型,简单了解模型结构及使用方式,跑通其推理流程。
此阶段无需关注具体使用哪种推理引擎或运行在何种计算单元上。
-
第二步:根据目标推理引擎及 NPU 的限制,对原始模型进行多次微调。
出于应用场景的灵活度考量,模型的输入 shape 多数都是动态的,而多数情况下 NPU 对张量的 shape 要求必须是静态的,所以需要多次微调,以固定张量的 shape 并保证模型准确度不受影响。
-
第三步:依据模型的实际运行流程,编写对应的推理服务层代码(Pipeline)。
需要根据固定的 shape 及 data type,对输入的数据做转换、拆包、补齐等操作。
-
第四步:将模型转换为目标推理引擎所需的格式,并集成到端侧的 Pipeline 中进行推理。
若推理结果与原始模型不一致,则利用 Pipeline 中可拆分的中间节点,逐级比对中间张量,定位偏差来源并修复问题。
5、最佳实践
接下来我们以语音识别中的 VAD 和 PUNC 模型为例展开讲一些具体实践。其中 VAD 用于检测音频中哪些片段包含有效语音;PUNC 则用于为识别出的无标点文本自动添加标点符号。
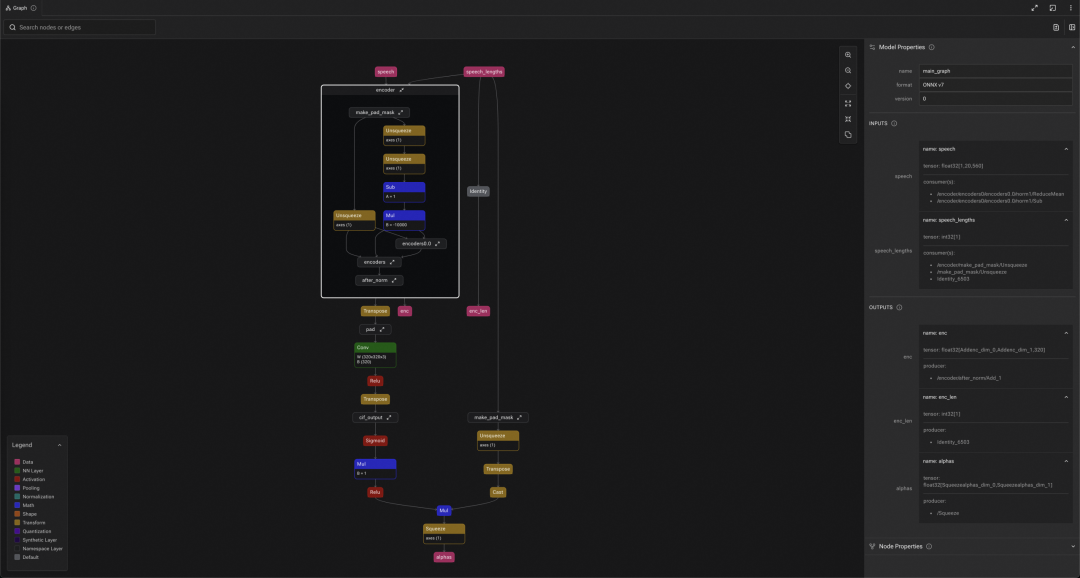
5.1 VAD 模型概览
使用开源社区的 FunASR 框架可体验该 VAD 模型的 Demo:模型以音频数据 speech 为输入,输出对应音频帧的有效性概率 logits,in_cache_0–3 和 out_cache_0–3,作为缓存数据输入和输出。
模型结构核心由 4 层 fsmn 堆叠组成,单层 fsmn 中包含有 memory block 记忆块,in_cache、out_cache 就是 memory block 的投影,音频输入模型推理时,VAD 通过 memory block 来实现回看和前视,从而提取有效的音频段。
5.2 VAD 模型转换
在实际部署场景中,模型调整与格式转换通常同步进行,在明确模型的输入输出及结构后,为使其适配 NPU 推理,需依据目标硬件的要求进行针对性优化。以 QNN 在 Snapdragon NPU 上的部署为例,模型调整主要包括以下步骤:
5.2.1 GeLU Decompose
将 GeLU 激活函数显式分解成 Erf、Mul、Add 这些最基础的算子。
5.2.2 ONNX IR Rewriter
通常是为了模型转换做准备,应用一些图优化的规则,其中主要包含:
- 算子标准化:将语义相同的算子统一为标准的格式,部分算子通过等效转换器转为 QNN 支持的等效算子(如
MatMul → FullyConnected)
- 常量折叠:合并常量运算,预计算一些 shape 相关的操作(
Shape + Gather + Unsqueeze)
- 算子融合准备:调整部分算子(
Transpose)的位置,以靠近类似 Conv 这种支持融合的算子
5.2.3 onnxsim 模型简化
模型输入是静态 shape 时,onnxsim 可以清除一些冗余的节点,以便于在硬件上直接部署。
5.2.4 输入 shape 固定
出于使用场景的灵活性,模型通常设计为支持动态输入 shape,若要在 NPU 上推理,则需预先将输入的 shape 固定为静态。从一个动态区间中选取一个静态值,一般有两种方案:
- 取一个大值,计算输入 shape 与静态值的 gap,通过补无效值(一般是 0)来实现 shape 对齐
- 取一个小值,将输入的数据按照小值为单位进行截取,直到最后剩下一小部分数据仍小于小值,再补齐
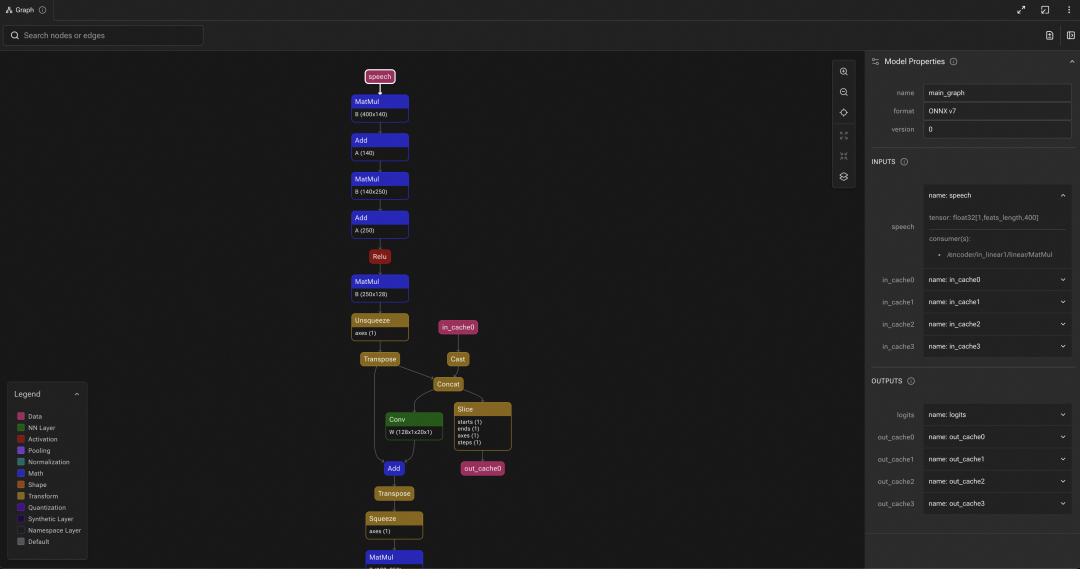
VAD 模型在固定时,特征长度 feats_length(如下左图) 我们使用了取大值的方案,音频特征的张量固定成 (1, 10, 400)。
| 原始 VAD 模型 onnx 格式 |
VAD 模型 .so 格式 |
 |
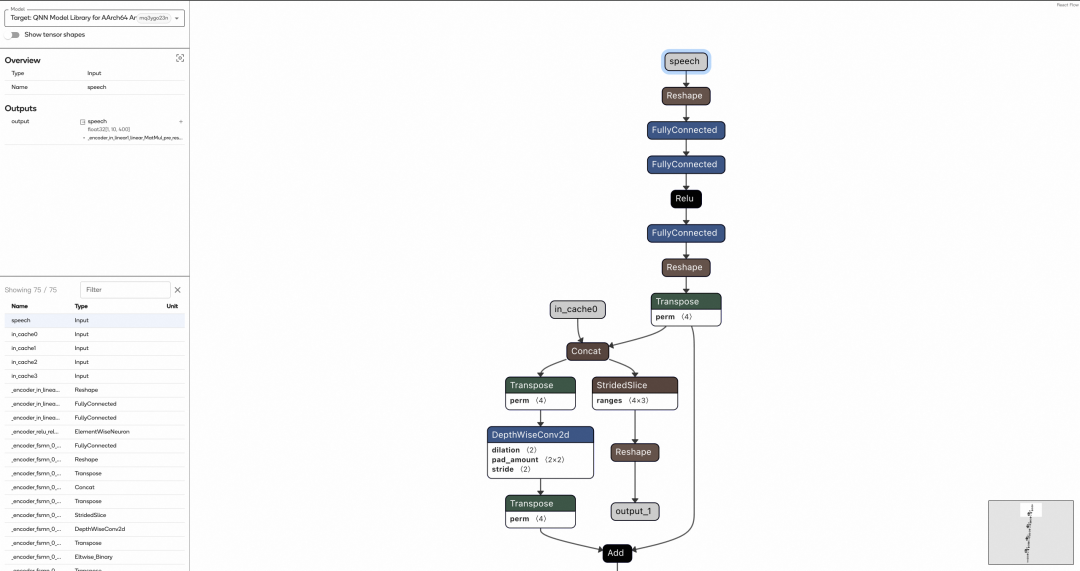 |
最后,将调整后的模型可以通过 QNN 提供的转换工具 qnn-{onnx/pytorch}-converter 进行模型转换,转换后的模型结构如上右图。
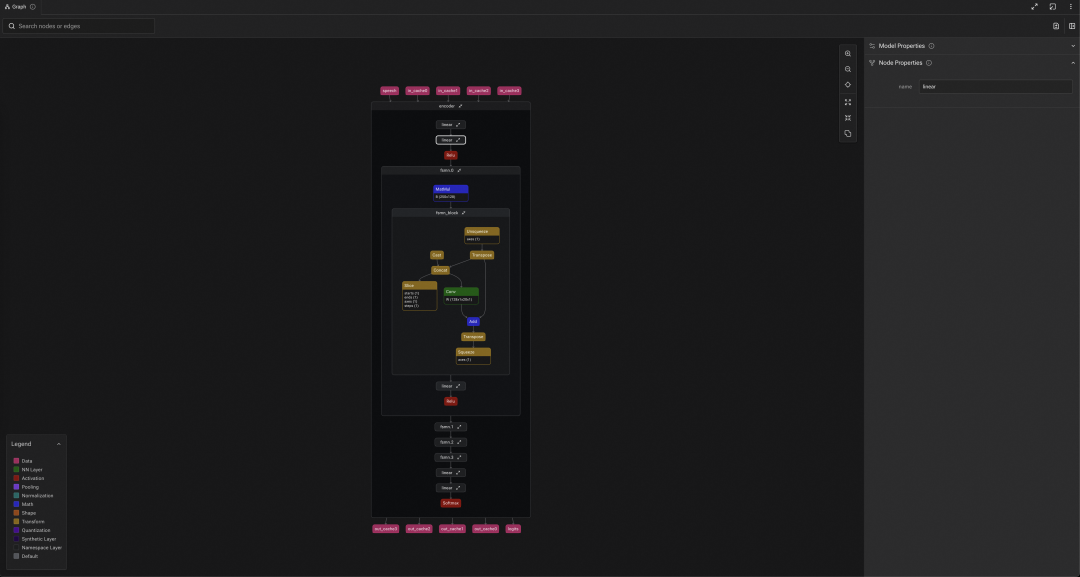
5.3 VAD 模型的 Pipeline 封装
一种新的应用场景,一种新的模型类型,我们会在 InferenceService SDK 中为其封装一套对应的运行流水线,如下图所示:

针对 VAD 模型,我们封装了 ASRPipeline 来对接 QNN 后端推理,VAD 的部分核心可以分为以下几个处理节点:
5.3.1 特征提取
音频采集侧我们确定了音频采样率为 16kHz,对于实时输入的音频,每 1600 采样点进行一次截取作为一个 chunk,每个 chunk 会先做一次归一化处理。
我们为 VAD 和 ASR 封装了可以共用的特征提取服务 FeatureExtractor,这里会将归一化音频数据转换为 fbank 频谱特征,通过低帧率拼接(LFR)将多个连续帧拼接,并对特征做均值方差归一化(CMVN)。
在帧长 400,帧移 160 的情况下,1600 的采样点其中最高可提取有效帧为 8 帧,每个 LFR 输出帧需要拼接 5 个连续的输入帧,首包音频因为没有左上下文信息,会复制首帧数据填充 2 帧作为上下文信息,当剩余帧数不足 5 帧时停止,为了实时流式识别,会保留最后的 4 帧用作下一包的上下文,最终提取到的特征长度为 6。非首包音频有了前面一包的遗留作为上下文信息,可以提取到的特征长度为 10。
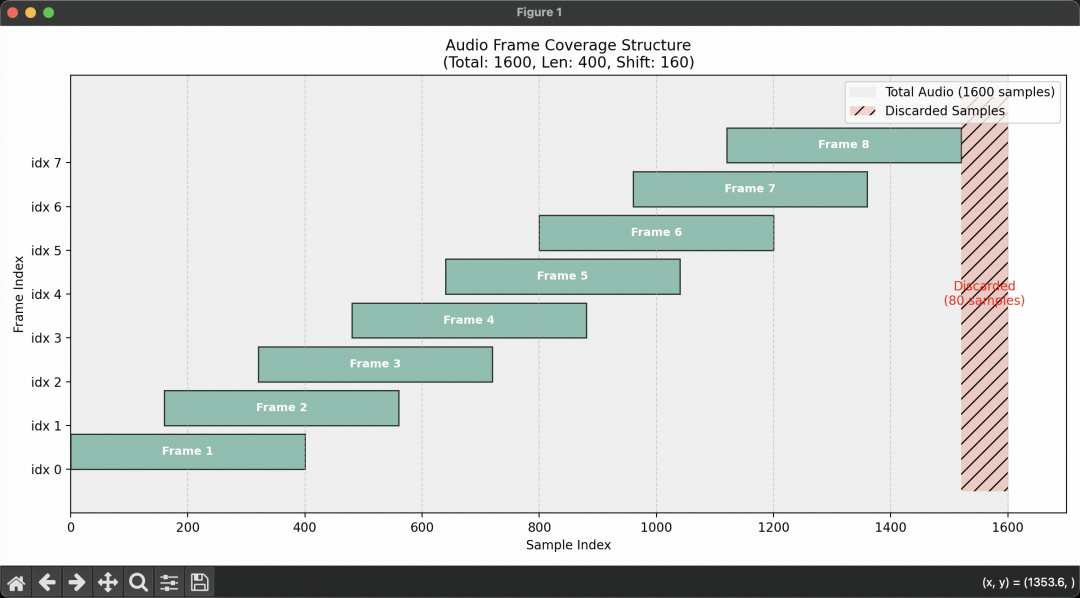
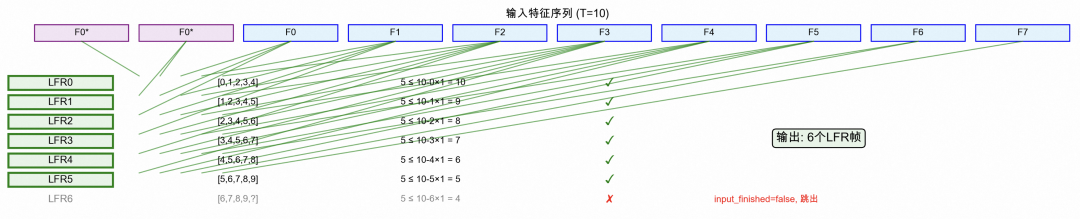
像工厂开机预热一样,虽然第一批次产量少,但保证了整个生产过程的连续性和完整性。这也是为什么我们会在固定模型输入时,将 shape 中的特征长度固定为 10 这个大值。
5.3.2 特征对齐
在自回归结构的模型中,通常需要引入掩码机制,以明确标识输入序列中的有效区域,从而确保模型仅基于有效的上下文信息进行推理。然而,对于 VAD 这类采用纯线性处理流程的模型而言,其输入与输出之间可通过绝对位置实现一一映射。
在实际推理过程中,若首包音频特征的长度仅为 6(即张量 shape 为 (1, 6, 400)),而模型的输入张量已被固定为 (1, 10, 400),便需要对不足的部分进行补零填充。由于 VAD 模型的线性特性,填充位置对应的输出结果不包含有效信息,因此可在推理完成后直接裁剪去除,仅保留与原始有效输入相对应的输出部分即可。
5.3.3 引擎推理
QNN Graph 的输入是 Qnn_Tensor_t 张量,按照模型输入的静态 shape 和 dataType,将特征数据转为 Tensor。
我们封装了 ASR 语音识别相关的模型推理逻辑,其中就包括了 VAD 模型的推理,模型的输入输出缓存 in_cache、out_cache 由 ServiceContext 内部自管理 ,接收从 Pipeline 输入的 Tensor 并在 NPU 上执行 Graph 拿到音频段概率分数。
5.3.4 后处理
模型推理得到的音频概率分数,结合音频的原始波形,会经过每帧分贝值计算、分贝阈值判断、信噪比、语音噪声概率等一些决策机制,判定每帧音频的状态,从而识别音频段的起始 start_ms 和结束 end_ms 时间边界,最终输出是音频段状态是(开始,结束)×(有,无)笛卡尔积中的一种。
结合音频的边界,可以有效控制 ASR 音频缓冲区的音频累计,然后按照 9600(0.6s)采样点进行音频段的裁剪,进一步递交给 ASR 进行实时的语音识别。
5.4 PUNC 模型裁剪
模型推理时,词表过大会导致模型过大,远端下发模型耗时会比较高,模型加载到内存时的内存占用也会比较大。特别是对设备硬件有限、实时性要求比较高的场景更是如此。
以中文通用标点模型 PUNC CT Transformer 为例,原始 PUNC 模型词表大小为 272727,查看其模型结构可以看到 Embedding 层 weight shape 为 272727 x 256,当然与词表一致。只是对于一个强实时的 PUNC 后处理来说,这个词表有点过于丰富了。
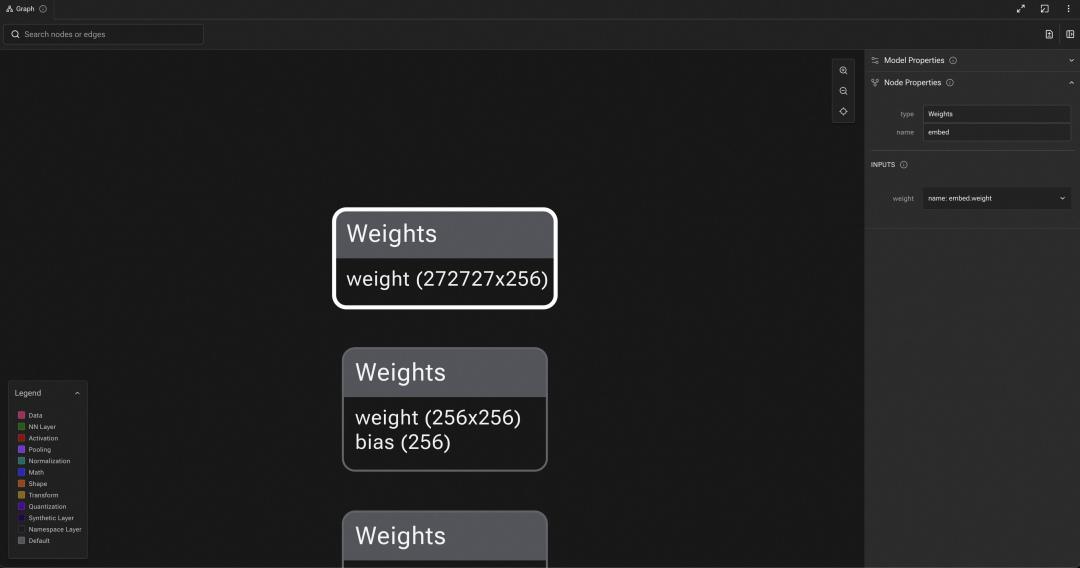
为什么这么说?简单的说,语音识别的全流程 VAD + ASR + PUNC,我们用的 ASR(Paraformer ASR Online)模型,词表大小仅是 8404,这你就懂了,ASR 都识别不出来那么多内容。
明确要裁剪之后,有两个必需的前置准备工作,来分析裁剪的可行性:
- 对比 ASR 和 PUNC 的词表关系。全包含子集?半包含子集?
- 半包含子集:需要拿到 ASR 中包含 但 PUNC 中不包含的,进一步校验有效性
- 全包含子集:可直接开始裁剪
- 找到 PUNC Torch 模型的 Embedding 层(如果是其他模型,还要确认 decode 层)
- 可以通过查看模型结构,或 torch load model 之后遍历查找 name 包含 embed 的权重
对比校验之后,词表关系是半包含子集,其中 1071 个词属于词表之外的,分析之后基本属于两类:生僻字、特殊英文符。
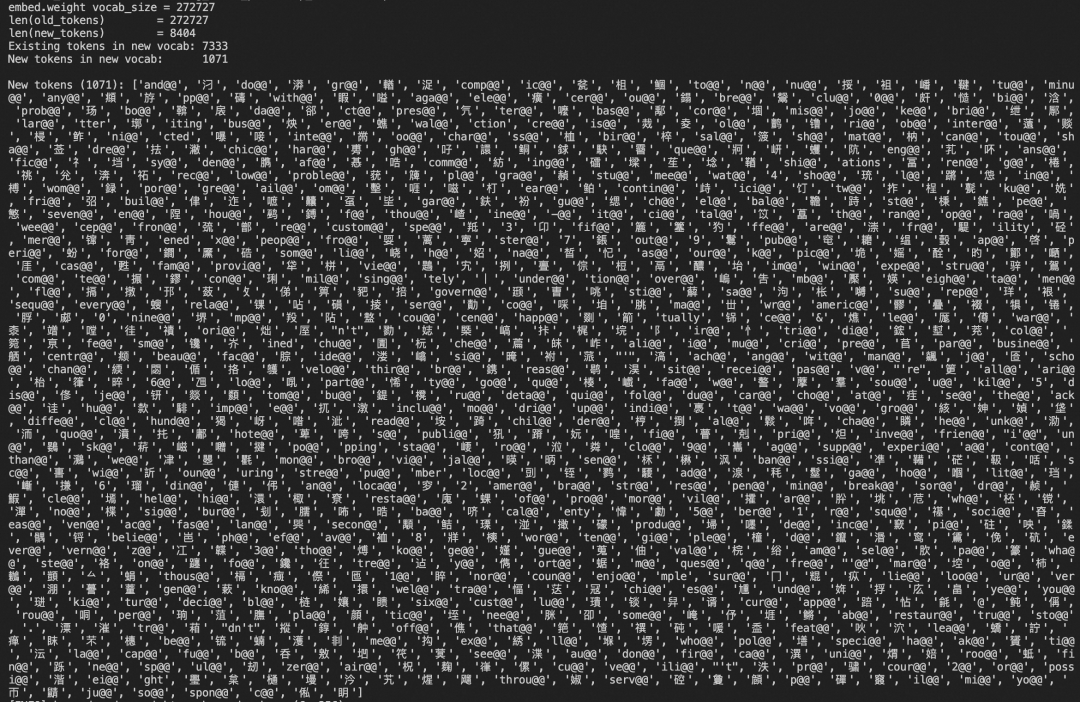
也就意味着,对于当下的中文语音识别场景来说,只要规则得当,完全符合裁剪标准。
裁剪最核心的两步,词表双向映射、token 处理。针对已存在 token 通过 torch.index_select 从旧权重中提取,新增 token 则采用 N(0, 0.02²) 正态分布,或 UNK-based 的初始化方案实现。
对于输出层 decoder.weight/bias,如果第 0 维与旧词表大小一致(分类头),则进行裁剪扩展,否则视为任务无关参数保持不变。

本质是参数空间的子集映射与增量初始化,在保留原有语义表征的同时,通过低方差随机化策略为新 token 注入可训练的初始嵌入,缩简词表大小的同时,避免词表扩展导致的模型退化。
裁剪完成后最关键的一步是验证:确保裁剪后模型的推理结果与原始模型一致。最终,模型文件大小从 288.8 MB 显著缩减至 18.1 MB。

6、ANE 推理实践
ANE 是 Apple 芯片对应的 NPU 方案,得益于其生态,目前 Apple 旗下所有的硬件设备都只使用一个推理引擎 Core ML 以及一个 NPU 方案。可以通过 coremltools 将训练好的模型转换为 Core ML 格式,以便在设备上高效运行。不同设备间虽共享统一架构,但在性能和功能支持上可能存在细微差异。
为了方便大家理解,我们整理了一些相关名词的解释:
| 名词 |
解释 |
| ANE |
Apple NPU 方案的代号,全称 Apple Neural Engine |
| Core ML |
Apple 的推理引擎, Apple 旗下所有的硬件设备都用这个 |
| coremltools |
Apple 提供的 Python 工具包,用于将 PyTorch、TensorFlow 等模型转为 Core ML 格式 |
.mlpackage 文件 |
Core ML 的模型打包格式,是一个包含模型结构、权重数据和元信息的目录集合 |
.mlmodelc 文件 |
经过 .mlpackage 编译后的 Core ML 模型格式,准备直接在设备上运行 |
接下来以 iPhone 设备上运行 Qwen3 为例来展开讲针对 ANE 在模型转换部分需要做哪些工作,至于 LLM 的运行逻辑以及 Transformers 和 PyTorch 的 Python 工具如何使用就不展开了。
6.1 KVCache 实现
需要利用 iOS 18 新增的 MLState 来实现 LLM 推理过程中一个非常重要的优化——KVCache。
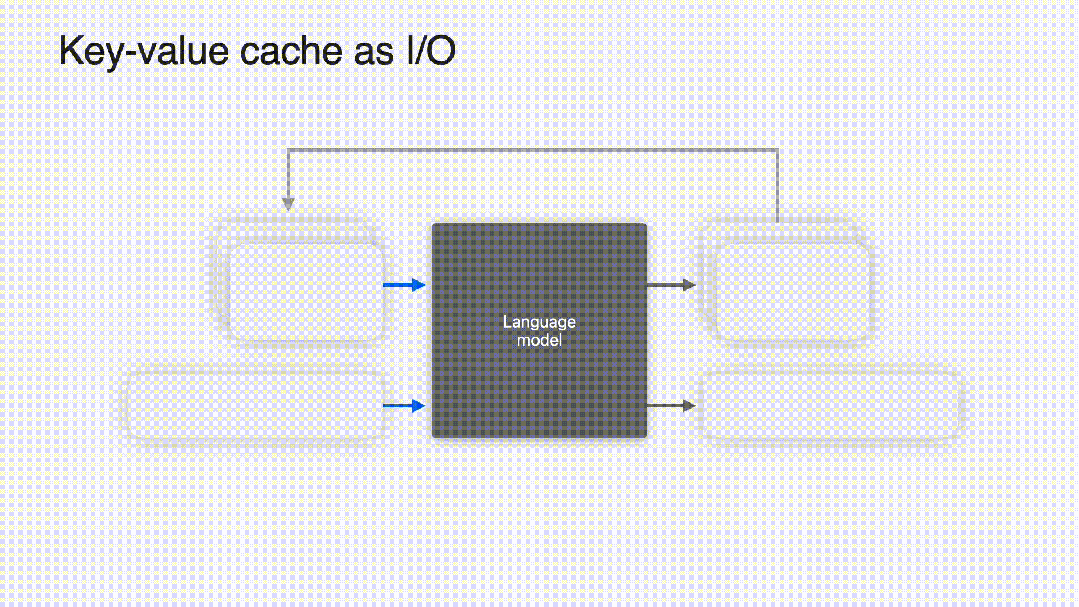
Transformer 架构由多个注意力模块组成,每个模块都会生成被称为“查询Q”、“键K”和“值V”的张量。模型处理的每个 token 都会生成这些张量。当一个新 token 到达时,需要结合之前所有 token 的键和值投影来处理其查询投影。
从 iOS 18 之前,键值缓存(KVCache)只能通过模型的输入和输出来实现:每次处理 token 时,模型将当前的 KVCache 作为输入,在前向计算过程中更新它,并将更新后的 KV Cache 作为输出返回。LLMPipeline 代码随后捕获该输出,并将其作为下一个 token 推理的输入,从而实现缓存的迭代更新。
从 iOS 18 开始,Core ML 引入了一种名为“状态”的输入类型。模型推理是可以有状态的,也就是说,状态存储的张量值会在模型推理时自动更新,而无需显式地将其作为输入和输出。
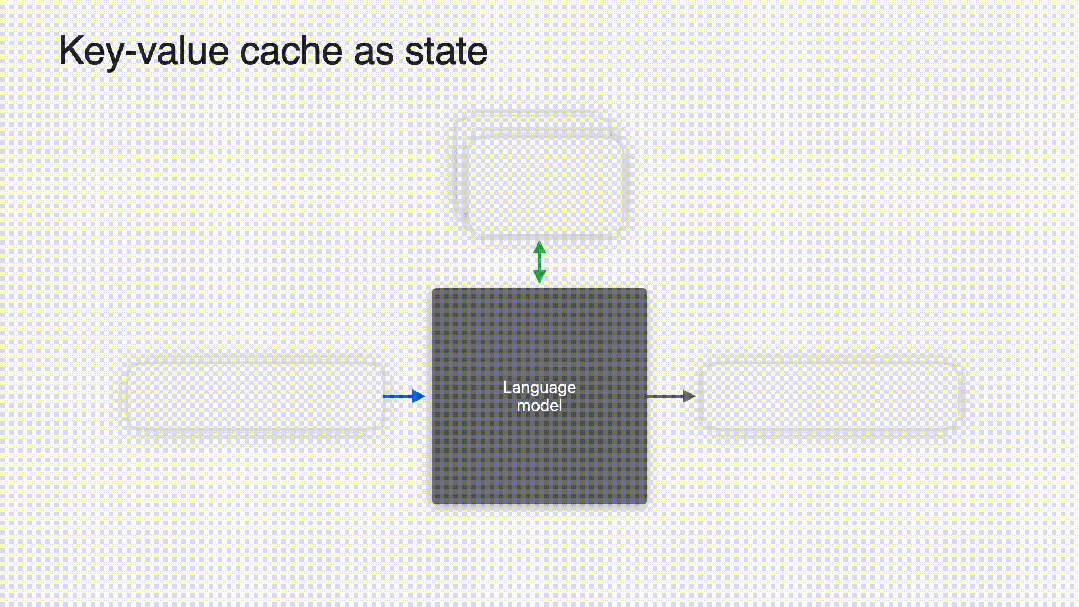
当然在模型转换时也需要使用 Transformers 和 PyTorch 的 API 来自定义 Cache 类用于实现内部的 KVCache 逻辑。这些逻辑随后在模型转换时会被 coremltools 工具检测到,识别为 State。
# LMM 的 KVCache 实现(伪代码)
from transformers.cache_utils import Cache
import torch
# 1. 自定义 Cache 类(实现缓存更新逻辑)
class TestKeyValueCache(Cache):
def __init__(self, shape):
self.k = torch.zeros(shape);
self.v = torch.zeros(shape);
self.t = 0
def update(self, k, v, i, kw):
s, e = self.t, self.t + kw["cache_position"].shape[-1]
self.k[i, :, :k.shape[1], s:e] = k; self.v[i, :, :v.shape[1], s:e] = v
return self.k[i, :, :, :e], self.v[i, :, :, :e]
def get_seq_length(self, _=0): return self.t
# 2. 模型包装器(替换默认 Cache 并注册为 buffer)
class TestModel(torch.nn.Module):
def __init__(self, model, shape):
super().__init__()
self.model = model
self.kv = TestKeyValueCache(shape)
self.register_buffer("keyCache", self.kv.k)
self.register_buffer("valueCache", self.kv.v)
def forward(self, input_ids, mask):
self.kv.t = mask.shape[-1] - input_ids.shape[-1]
return self.model(input_ids, attention_mask=mask, past_key_values=self.kv).logits
# 3. 导出时的 CoreML 配置(声明以状态输入)
coreml_model = coremltools.convert(
...,
inputs=[...],
states=[coremltools.StateType(name="keyCache"),coremltools.StateType(name="valueCache")]
)
6.2 模型运行限制
| 约束项 |
限制 |
影响 |
| 激活值精度 |
<= fp16 |
算子高于此精度会降级到 CPU/GPU 执行 |
| 张量维度 |
<=5维 ,内部偏好 4 维 |
通常是基于 4 维 NCHW / NHWC 设计 |
| NCHW 中 H/W |
≤ 16,384 |
影响序列长度和隐藏维度 |
| NCHW 中 C |
≤ 65,536(2^16) |
通道宽度,词表长度限制 |
| 模型尺寸 |
iOS : 1GB | Mac : 2GB |
模型大小,需要拆分模型 |
| 张量 shape |
必须静态 |
输入输出逻辑调整 |
注意:Apple 并未向第三方开发者提供任何关于如何优化模型以充分利用 ANE 的指导,此限制非官方披露,来源于开源社区整理以及我们的实践,部分信息可能存在错误,而且可能不完整。
关于张量 shape 的固定问题,前文已通过 VAD 模型的示例说明。对于 LLM,可通过掩码来处理变长输入,从而在保持静态图结构的同时,确保推理过程中仅允许每个位置关注自身及之前的 token,既满足自回归生成的要求,又兼容 ANE 对静态 shape 的限制。
6.2.1 模型分块
由于 iOS 对模型加载内存的限制(<= 1 GB),参数量较大的模型需要进行拆分。一般先按功能划分为三个部分:Embedding、Transformer 主干和 LM Head。其中,Embedding 和 LM Head 的体积通常较小,若这两部分单独就超过 1 GB,则该模型基本不具备在 iPhone 上部署的可行性。
对于 Transformer 主干,若其量化后的体积仍超过 1 GB,则需进一步拆分。可以按Transformer 层的数量进行等比例切分,以满足内存约束。目前,Qwen3-0.6B 和 Qwen3-1.7B 模型在经过 4-bit 权重量化后,其 Transformer 主干均未超过 1 GB,因此不需要做拆分。
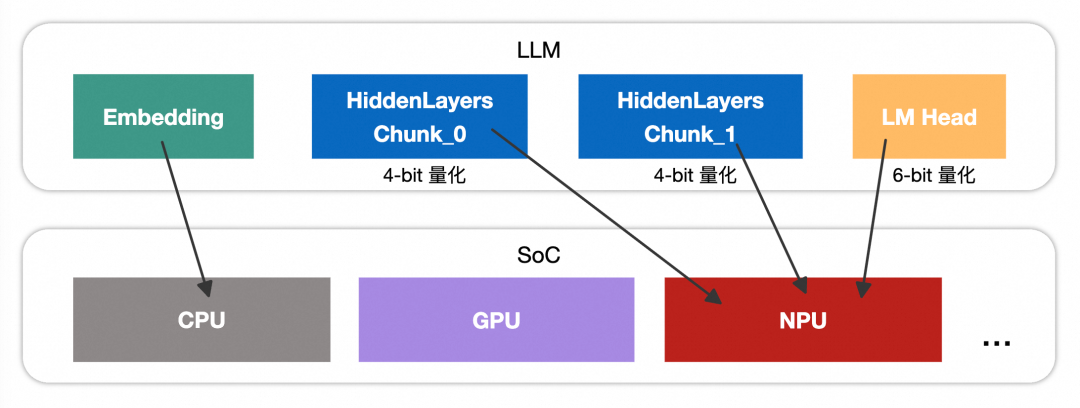
拆分后的多块模型会尽可能在 NPU 上运行,其中,Embedding 层是语言模型的输入编码模块,通过查表操作,将每个输入 token 映射为其对应的可学习张量。
所以,Embedding 部分通常仅包含一个 gather 算子,并且目前看上去不被 ANE 支持,因此会自动降级到 CPU 上执行。实际上,gather 操作本身几乎没有计算开销,主要涉及内存索引和读取,无需强制调度至 NPU。
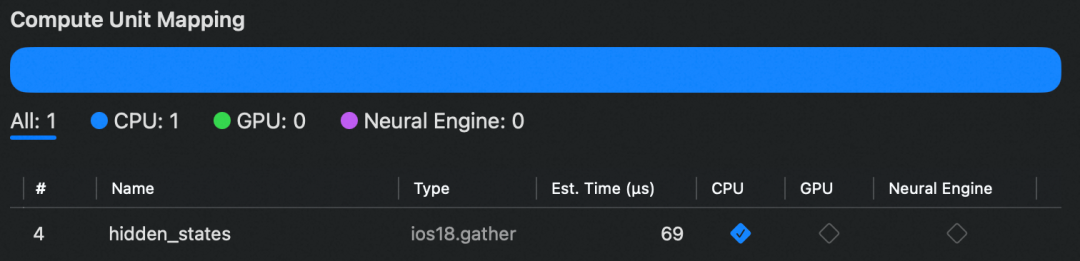
低比特量化能显著降低模型的存储体积与运行时内存占用,并有效减少推理延迟;而分块量化则通过在更细粒度上实施混合精度量化策略,在实现模型压缩的同时,更精细地保留关键参数的数值精度,从而有效缓解整体精度损失。
在早期实践中,我们发现对 Embedding 部分进行 4-bit 权重量化后,模型容易陷入重复输出同一句话的问题。当时仅采用贪心采样(即取 logits 最大值)策略,而 Embedding 作为模型输入的前端,其量化误差会直接传播至后续所有层,过重的量化容易显著放大输出偏差。
6.2.2 模型合并
由于 Prefill 和 Decode 阶段的计算特性不同——Prefill 是计算密集型,而 Decode 是存储(内存带宽)密集型——在服务端推理中常采用 Prefill-Decode 分离架构,将两个阶段分别部署在不同的机器上以优化资源利用。但在 iPhone 这类单设备场景下,无法进行物理分离,必须在同一台设备上完成整个推理。
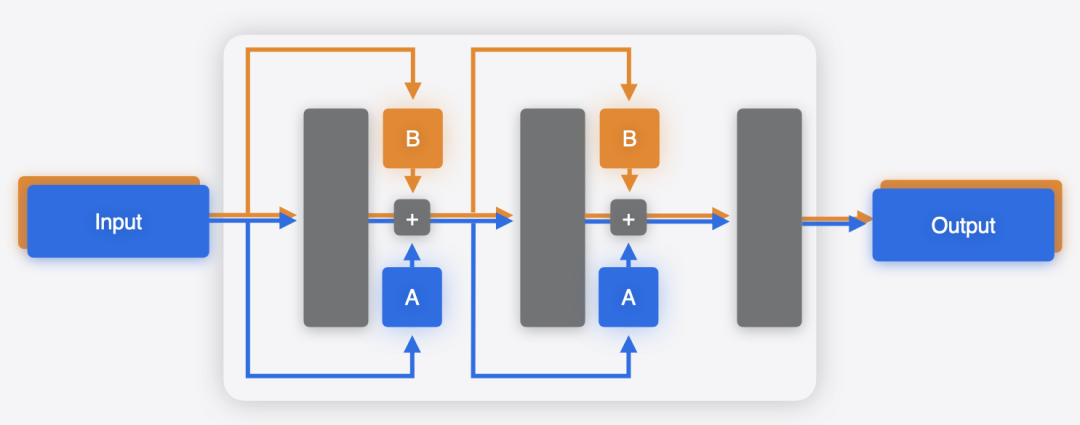
而 Apple 提供给了另一种方式实现 Prefill-Decode 分离——使用 coremltools,可以将多个模型合并,生成一个 .mlpackage 包含多个子功能的单一模型文件,共享公共权重。合并过程中,coremltools 会通过计算权重的哈希值来去重,而合并后的多功能模型可以根据 function_name 选择执行相应的逻辑。
# Core ML Tools 模型合并核心流程(伪代码)
def combine_models(decode_model_path, prefill_model_path, output_path):
# 1️⃣ 加载两个独立的模型
decode_model = load_model(decode_model_path)
prefill_model = load_model(prefill_model_path)
# 2️⃣ 创建多功能描述符(核心 API)
descriptor = MultiFunctionDescriptor()
# 3️⃣ 注册功能函数
descriptor.add_function(
model_path=decode_model_path,
function_name="decode"
)
descriptor.add_function(
model_path=prefill_model_path,
function_name="prefill"
)
# 4️⃣ 设置默认函数
descriptor.default_function = "decode"
# 5️⃣ 保存多功能模型
save_multifunction(descriptor, temp_path)
# 6️⃣ (可选)添加元数据
combined_model = load_model(temp_path)
add_metadata(combined_model, [decode_model, prefill_model])
combined_model.save(output_path)
# 7️⃣ 清理临时文件
cleanup(temp_path)
在使用时,可通过 functionName 属性指定需执行的子模型(如 Prefill 或 Decode 阶段)。尽管 LLMPipeline 中实例化了两个 MLModel 对象,但它们共享同一份底层权重文件,在内存中仅加载一份权重副本。在有效节省内存开销的同时,仍保持了 Prefill 与 Decode 两个推理阶段的逻辑分离。
以下是以 Qwen3-0.6B 模型为基础,进行 4-bit 权重量化后的 Prefill 和 Decode 阶段模型文件大小,以及合并后的最终模型文件大小。

6.2.3 LMHead 词表分割
LM Head 是 LLM 模型中负责将隐藏状态(hidden states)映射为词表概率分布的关键部分,其核心逻辑是——对每个 token 的 hidden state 张量,通过一个线性变换投影到整个词表空间。
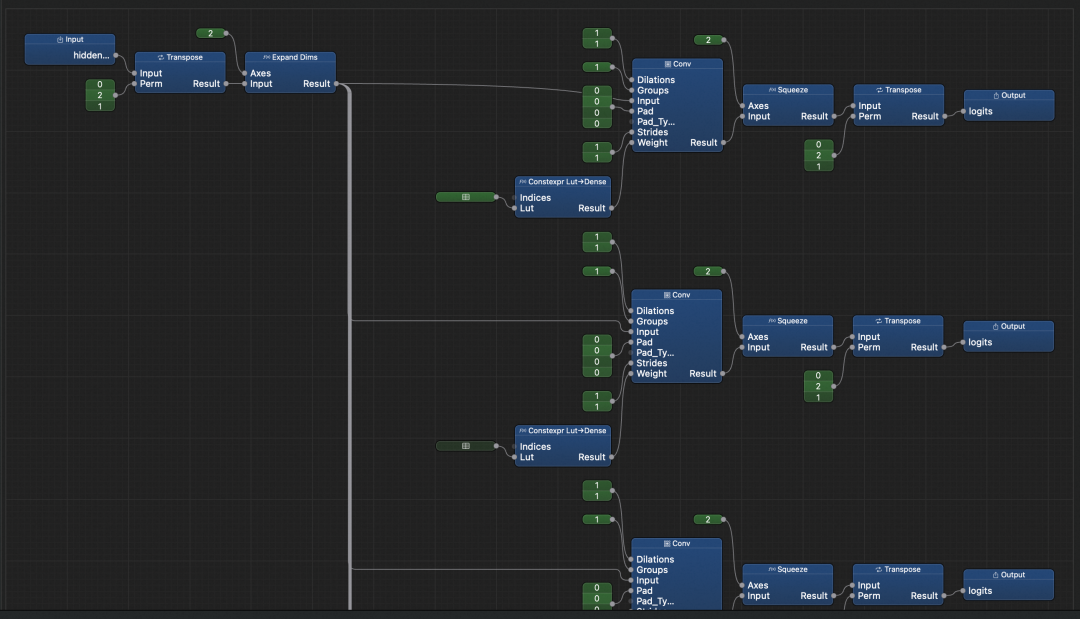

上图展示了 LM Head 部分的模型计算图。熟悉算法细节的同学应能看出:我们将原本的 Linear(全连接)层等效转换为了 Conv2D 卷积层,此时,词表维度(Qwen3 的词表大小为 151936)映射到了卷积(NCHW)的输出通道(C)上了。
如前文所述,ANE 对卷积输出通道数存在限制(≤ 65,536),而 151936 显然超出了该约束。为此,我们需要分块计算:将原始 hidden state 张量沿词表维度切分为多个子块,分别通过多个受限通道数的 Conv2D 层进行计算,最后将各子块结果拼接还原。保持原始线性变换的数学等价性,不影响模型输出。
6.3 模型算子限制
使用 Xcode 16 及更高版本的编译器打开 .mlpackage 模型文件,可以进行性能基准测试,包括查看模型中所有算子的运行情况。测试结果会显示每个算子是否支持在 NPU 上运行;即使某些算子被标记为支持,也可能因兼容性或优化限制而发生降级,实际运行于其他计算单元。
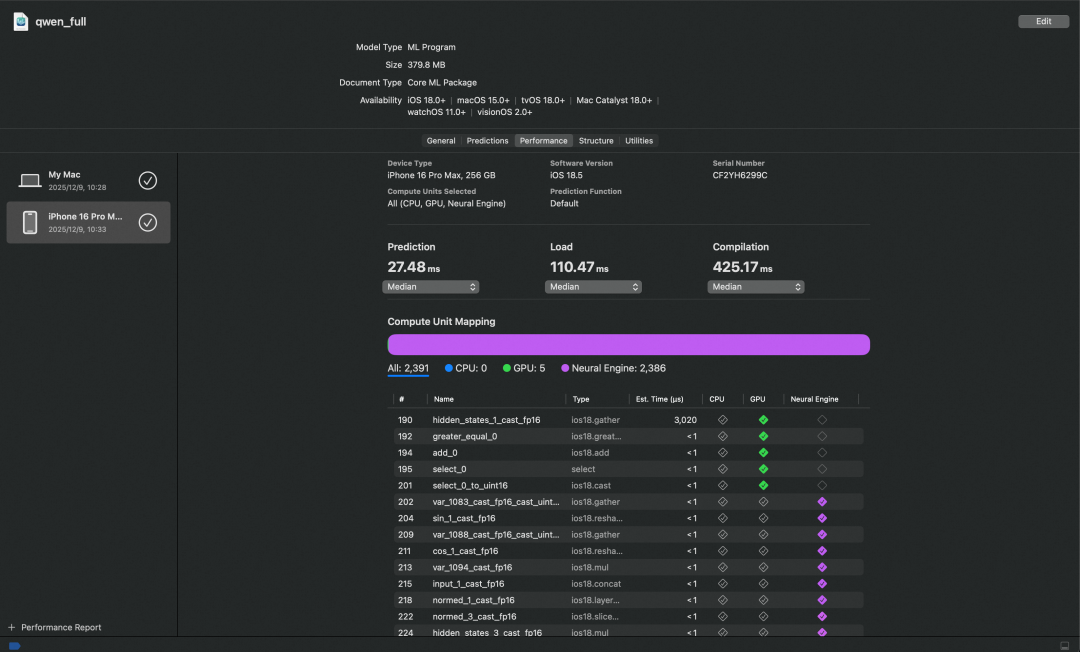
6.3.1 Conv2d 替代 Linear
目前主流 NPU(包括但不限于 Apple 的 ANE)普遍以 CNN 卷积运算为核心加速目标。Linear 算子,我们在实际运行模型的时候发现,它在 ANE 上的计算结果存在明显错误,需要将其等效转换。
Conv2d(1×1)卷积在数学上等价于 Linear。以 LM Head 部分为例,只需将 3D 输入([B, L, H])转为 4D(如 [B, H, L, 1]),用 Conv2d 做投影,再转回 3D 输出([B, L, V]),即可在保持计算等价的同时适配硬件上 ANE 的限制。
# Linear 替换为 Conv2d(伪代码)
def linear_to_conv2d(hidden_states):
# 步骤1: 维度调整 - 适配 Conv2d 输入格式
# [B, S, H] → [B, H, S] → [B, H, 1, S]
x = hidden_states.permute(0, 2, 1) # 交换维度
x = x.unsqueeze(2) # 插入维度1
# 步骤2: Conv2d 计算(等价于 Linear)
# [B, H, 1, S] → [B, V, 1, S]
output = conv2d(x, kernel_size=1)
# 步骤3: 维度恢复 - 还原为原始格式
# [B, V, 1, S] → [B, V, S] → [B, S, V]
output = output.squeeze(2) # 移除维度1
output = output.permute(0, 2, 1) # 交换回来
return output

得益于 PyTorch 对于张量处理的封装,将 LM Head 中的 Linear 层等效转换为 Conv2d 实现非常简单,核心逻辑仅需两行代码。
# LM Head处理逻辑
lm_head = Conv2d(
in_channels=hidden_size, # 输入通道 = 隐藏层大小
out_channels=vocab_size, # 输出通道 = 词汇表大小
kernel_size=1, # 核大小=1(关键!)
bias=False # 无偏置
)
logits = lm_head(hidden_states.permute(0,2,1).unsqueeze(2)).squeeze(2).permute(0,2,1)
# 等价于
logits = Linear(hidden_states)
6.3.2 RMSNorm 的实现
在归一化计算的支持方面,ANE 目前仅原生支持 LayerNorm,尚不支持 RMSNorm。为了在 ANE 上部署使用 RMSNorm 的模型,需要对其进行等效转换。
在 Hugging Face 社区我们发现了一种巧妙的实现方案:利用 LayerNorm 来等价模拟 RMSNorm 的行为。通过构造特定的输入形式,使 LayerNorm 的输出与 RMSNorm 一致,从而在不修改模型结构的前提下,实现对 ANE 的兼容。推导公式如下:

- LayerNorm:先算均值(μ),再用
(x - μ) / sqrt(方差) 归一化
- RMSNorm:直接用
x / sqrt(平均平方) 归一化
简言之,当输入张量的均值为零时,LayerNorm 与 RMSNorm 在数学上是等价的。为了满足这一条件,一种常见技巧是将原始输入与其符号取反后的副本拼接形成一个均值为零的扩展张量;在对该扩展张量应用 LayerNorm 后,仅保留对应于原始输入部分的输出。以下是该思想的 PyTorch 实现:
# RMSNorm 实现
import torch
import torch.nn.functional as F
def RMSNorm(x, weight, eps=1e-6):
# 张量取反再拼接,保证均值为0
doubled = torch.cat([x, -x], dim=-1)
normed = F.layer_norm(
doubled,
normalized_shape=doubled.shape[-1:],
weight=None,
bias=None,
eps=eps
)
# 只返回原始位置的张量
normed = normed[..., :x.shape[-1]]
return normed * weight
这也是为什么前文提到,我们需要关注 Qwen3 引入的一项关键优化:对 Q/K 张量进行归一化处理。模型中关于 RMSNorm 计算图如下所示:
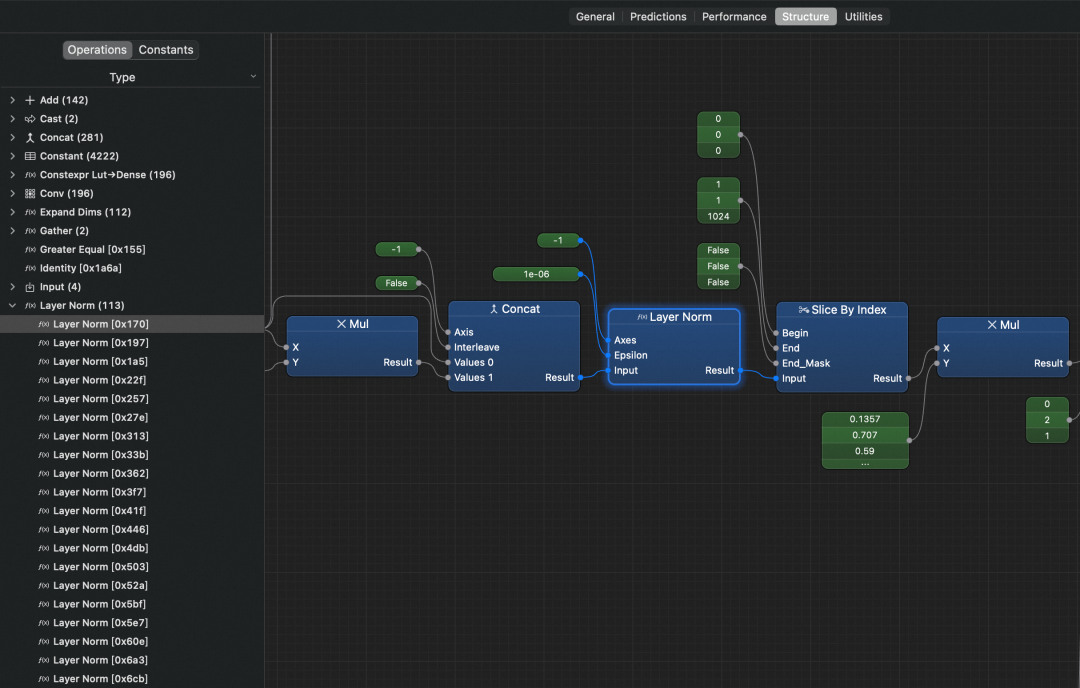

- Concat:输入张量首先与自身的负值拼接,构造出均值为零的扩展张量
- Layer Norm:通过 LayerNorm 进行归一化(此时等价于 RMS 归一化)
- Slice By Index:最后切片保留原始维度部分,得到 RMSNorm 的输出
6.3.3 异构计算
注意:此处提供的信息并不完整,甚至可能存在错误,纯属我们的经验之谈,Apple 官方并未披露
异构计算通过协调 CPU、GPU、NPU 等不同计算单元,根据任务特点动态分配任务,兼顾性能、能效与延迟。实践中我们发现会出现一种情况:某些算子本身是 ANE 支持的,但实际运行时并未在 ANE 上执行,而是被调度到了 CPU / GPU上。

下图中,S 表示受 ANE 支持的算子,U 表示不受支持的算子。按异构计算逻辑,U 会降级到 CPU 或 GPU 执行,S 则在 ANE 上运行。

但图中 CPU 区域包含两个 S 算子,这并不矛盾:因不同计算单元间切换存在开销,Core ML 在调度时会权衡切换成本与执行效率,可能将部分支持的算子也在 CPU 上执行,以减少整体延迟。
6.4 确定模型跑在 ANE 上
一种最直接的方法是在模型推理过程中全局断点,检查调用栈中是否包含 ANE 相关的函数,从而判断算子是否实际运行在 ANE 上。
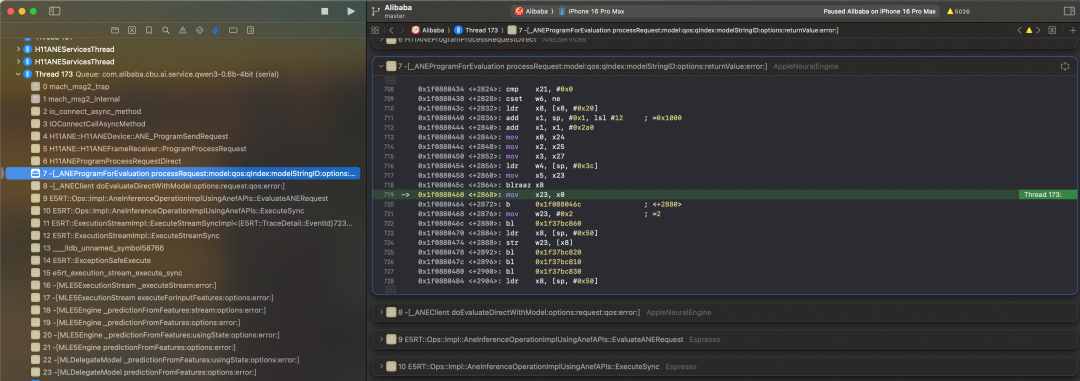
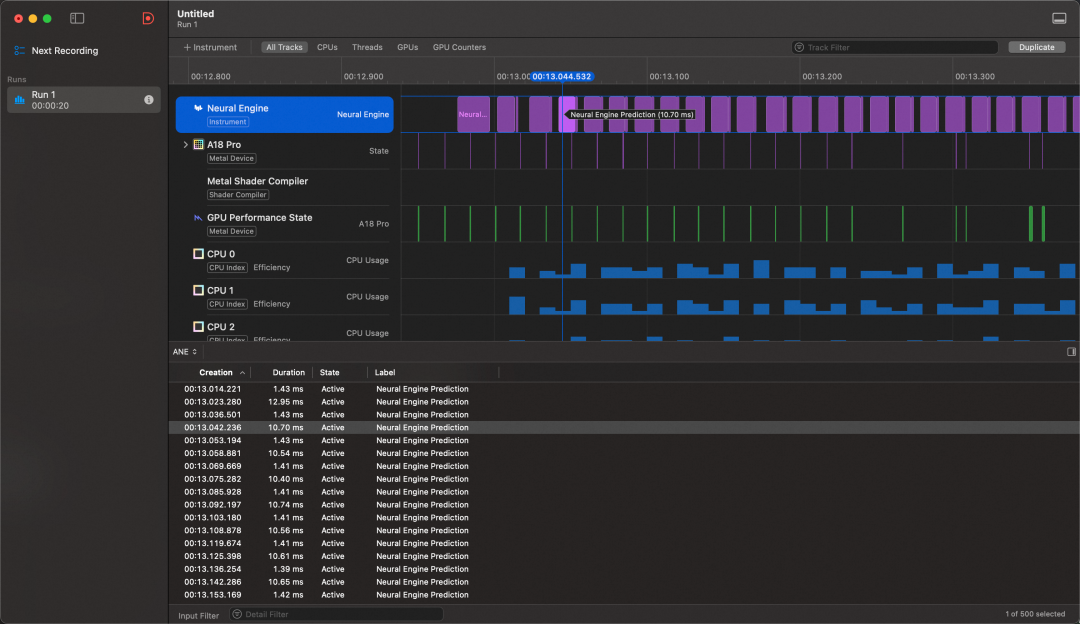
此外,还可借助 Instruments 中的 Neural Engine 工具,直观查看模型在 ANE 上的实际运行情况。
6.5 性能分析
App 内 LLM 使用 ANE 推理效果:
用于测试的设备信息:
| 机型 |
OS |
SoC |
内存峰值带宽 |
| iPhone 17 Pro |
iOS 26.0 |
Apple A19 Pro |
76.8 GB/s |
| iPhone 16 Pro |
iOS 18.5 |
Apple A18 Pro |
60 GB/s |
| iPhone 16 |
iOS 26.0 |
Apple A18 |
60 GB/s |
用于测试的模型大小:

6.5.1 模型加载性能
| 机型 |
OS |
模型 |
计算单元 |
内存涨幅(MB) |
首次 Build(s) |
非首次 Build(ms) |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
44.12 |
25.654 |
367.70 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B-6Bit |
ANE(NPU) |
44.93 |
36.899 |
429.06 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B |
ANE(NPU) |
44.32 |
43.406 |
465.71 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B |
Metal(GPU) |
2284.65 |
14.731 |
2513.61 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-1.7B-4Bit |
ANE(NPU) |
44.78 |
65.970 |
479.14 |
| iPhone 16 |
iOS 26.0 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
43.17 |
24.314 |
392.78 |
| iPhone 17 Pro |
iOS 26.0 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
43.96 |
22.492 |
360.81 |
内存涨幅口径为 App 主进程的内存涨幅
首次 Build 会对模型进行编程(动态图转静态图),编程的产物会进行缓存
模型并未做激活值量化,所有模型的激活精度都是 fp16
基于 Metal 的方案将模型权重直接加载到 App 主进程的内存中,导致显著的内存增长——这对客户端应用而言往往是不可接受的。相比之下,ANE 方案通过系统级优化,将模型权重等大内存占用部分隔离至独立的内存空间,有效避免了 App 主进程内存激增。
这种机制虽在效果上类似于 WKWebView 的多进程架构,但实现方式不同:通过 WKWebView 打开的进程可在 App 主进程信息的关联进程查询到,而 ANE 的内存隔离目前我们也没找到相关的细节去追踪。
6.5.2 模型推理性能
以同样一个 Prompt 作为输入,后处理采样方案都是贪心进行测试
# 测试 Prompt
{"system": "You are a helpful assistant.","user": "中国的首都是哪儿?有什么好吃的推荐"}
| 机型 |
OS |
模型 |
计算单元 |
TTFT ms |
TPS t/s |
decode_num_token |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
127.23 |
59.81 |
171 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B-6Bit |
ANE(NPU) |
138.19 |
52.56 |
355 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-0.6B |
ANE(NPU) |
165.23 |
31.68 |
377 |
| iPhone 16 Pro |
iOS 18.5 |
Qwen3-1.7B-4Bit |
ANE(NPU) |
162.82 |
38.10 |
131 |
| iPhone 16 |
iOS 26.0 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
128.13 |
61.64 |
171 |
| iPhone 17 Pro |
iOS 26.0 |
Qwen3-0.6B-4Bit |
ANE(NPU) |
118.78 |
75.12 |
171 |
模型参数量越大、量化程度越低,推理速度通常越慢;机型性能越强,推理速度也越快——这一点基本成立。然而数据显示 iPhone 16 的推理性能略优于 iPhone 16 Pro,尽管两者 NPU 和内存带宽相同,且 iPhone 16 Pro 拥有更强的 CPU(模型推理的前/后处理在 CPU 上)。这一反常现象源于 Core ML 推理引擎版本差异:iPhone 16 运行于 iOS 26.0,其内置的推理引擎可能做了一些新的优化,从而抵消甚至超越了 CPU 性能上的差距。
7、QNN 推理实践
生态碎片化是一个很有意思的词,特别是对于 Android 同学来说,硬件、定制化系统、系统服务从来都不止一套。站在模型推理这个点上,推理方案也很多,但涉及到不可编程的 NPU,想要工程化,都只有一条加速委托的路,所以我们只谈硬件。
我们统计了 1688 线上所有 Powered by Android 设备搭载的芯片占比,结合硬件厂商市场份额,可以确认的是主要由三大硬件厂商覆盖:高通、联发科、麒麟。联发科NeuroPilot 和麒麟 CANN 我们也在对接,这里先以高通为例。高通原生提供了 SNPE、QNN、Genie 三套 SDK,SNPE 是面向应用上层的粗粒度 API,对推理过程的调度不够精细化。
QNN 是一套高通原生的底层软件接口和开发工具包,支持应用直接访问和最细粒度地控制骁龙(Snapdragon)SoC 的硬件加速单元(Hexagon NPU、CPU、GPU),以实现在 Mobile、IOT 等搭载骁龙芯片的设备上推理模型。
对于 NPU 推理 LLM 的场景,高通有一套专为 LLM(至少目前仅支持 LLM)封装的推理框架 Genie,本质上还是基于 QNN 的扩展。我们在 InferenceService LLMPipeline 中实现了一套面向多推理引擎、多模型共用的 prompt-apply、 tokenizer、sampler 组件。所以我们直接在 Genie 的基础上做了些分析和工程化改造,来作为 LLM 在 Snapdragon SoC NPU 推理方案。
为了方便大家理解,我们整理了一些相关名词的解释:
| 名词 |
解释 |
| SNPE |
Neural Processing SDK,控制粒度粗 |
| QNN |
AI Engine Direct,对接硬件底层的 API 和工具包,控制粒度精细 |
| Genie |
基于 QNN 的扩展,面向 Gen AI(如 LLM)的适配 |
| Qairt |
Qualcomm AI Runtime,高通运行时 SDK |
| AIMET |
AI Model Efficiency Toolkit,模型量化工具 |
| SoC Model |
设备主系统芯片的型号名称 |
| HTP |
专用于处理 AI 负载,可简单理解为本文讲述的 Snapdragon SoC NPU |
| .so |
QNN Model Library,一种模型格式 |
| .bin |
QNN Context Binary,一种模型格式 |
接下来我们以在搭载高通骁龙芯片的 Android 设备上推理 LLM 为例,核心流程与 ANE 上推理无差,主要分析一些 QNN HTP 后端推理独有的内容。
目前为止我们在 8 Gen2、8 Gen3、8 Elite、8 Elite Gen5 四款芯片 QnnHtp 上跑通了 Qwen2.5-1.5B-Instruct 的模型,4 bit量化的 Qwen3 在 HTP 上推理还处于验证阶段。
7.1 模型与依赖管理
这里的模型指代的是小参数量的大语言模型(LLM)、非 LLM 的“小”模型两种,后续介绍时分别简要用大模型、小模型代替描述。
使用 QNN 在端侧推理模型时,有这样几个问题:
- QNN SDK 多个依赖版本之间不保证兼容
- 面对不同的 Qualcomm Chipset,QNN 的支持情况不同
- 支持的 Chipset List 中,存在多样的张量精度和 SoC Model
在端侧(ARM64 Android 平台)部署一个模型并用 QNN 推理,需要前置将模型通过 Qairt 工具链编译为 QNN 支持的模型格式(主要为 .so、.bin),
| 模型格式 |
模型描述 |
编译&运行时 环境要求 |
推理特点 |
.so |
Model Library |
Qairt Version |
首次运行时合成(Compose)为.bin |
.bin |
Context Binary |
Qairt Version + SoC Model |
可直接执行推理 |
.so 模型同一平台支持统一下发,在首次运行时合成上下文二进制图,再进行推理。.bin 模型严格遵守模型 - SoC Model 强一致性匹配下发,运行时可直接推理。
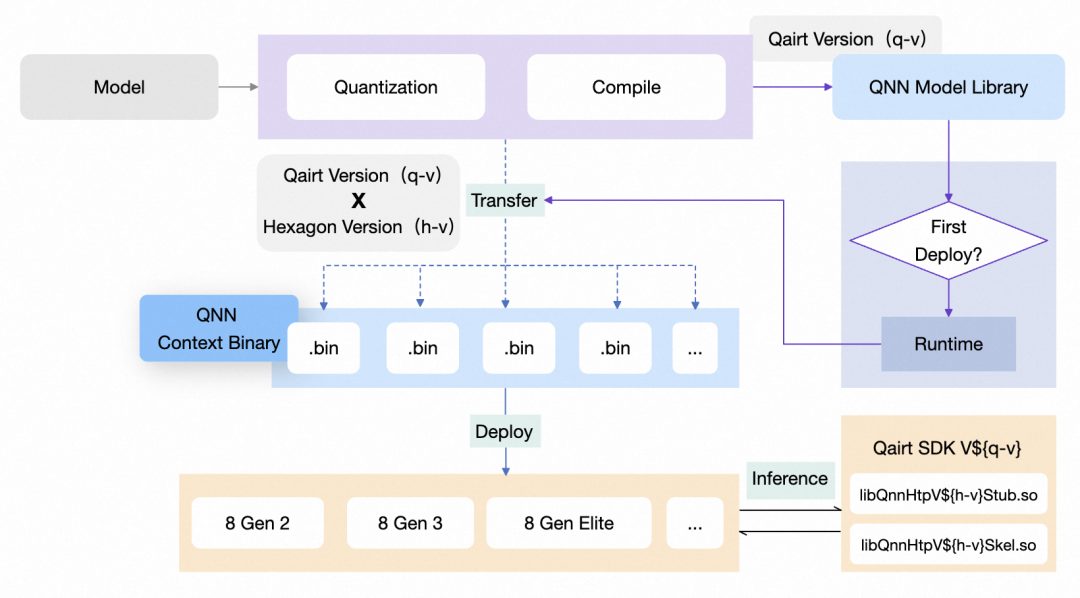
关于模型的管理,我们设定了一份要求/规范,对于大模型,运行时合成图的成本高且耗时严重,选用上下文二进制的格式,对于小模型,为了方便管理分发,优先选用运行时合成的方式。大模型按照 SoC Model 分类独立管理和分发,小模型按照平台分类,同平台统一管理和分发。
模型下发到端上,需要对应版本的 QNN SDK 进行部署和推理。SDK 中包含面向多后端的依赖库,针对 QnnHtp,还包含面向多 SoC Model 的依赖库。关于依赖库的管理,分为两种,
- 一种是类似
libGenie、libQnnHtp、libQnnSystem、libQnnHtpPrepare 这种组成的 common so
- 另一种是类似
libQnnHtpV75Skel、libQnnHtpV75Stub 以 SoC Model 分组的 V${h-v} so
这样构成了模型与依赖分发、部署的系统,在设备运行时,我们根据芯片及其 SoC Model 获取对应的依赖库,根据实际使用场景获取对应的模型。
7.2 模型分片与量化
Qwen2.5-1.5B-Instruct 原始模型大小 ~3G,直接一整个模型加载到内存里,瞬时内存占用对于终端设备来说肯定是不现实的,即使可行加载耗时也会比较高。一般可以通过分片和量化的方式来避免。
高通的 AIMET 和 Qairt 工具对系统环境有一些要求(例如 Linux/Windows,大模型量化最好有足够算力的显卡和显存),当然也可以使用高通的 AI Hub 服务。

从 HuggingFace 加载原始模型,先使用 AIMET 框架通过混合精度量化对模型进行处理。量化精度的选择需要多个因素一起综合考虑,量化过度可能会导致输出重复循环,需要结合采样策略一起调整。这里选择了 4bit 权重量化,fp16 激活值量化。量化之后,模型大小 ~1.3G。
HTP 和 CPU 共享主存储器,但不能一次性使用所有内容,HTP 是 32 协处理器,地址空间最大是 4G,但是实际上只有 1~2G。通常会把模型分片到不超过 1G,因此可以简单的理解为 ~1G。出于内存、延迟、功耗和是否能并发的几个角度考虑,量化之后的模型仍然不能直接进行部署。所以我们需要对量化之后的模型进行分片,将 Embed 单独作为第一片,中间 28 层每 11 层进行拆片(一般通过残差连接来确定分片点),剩下的最后 6 层和 LM Head 组合作为最后一片,从而将模型分为 4 片。
由于 Qairt 的权重共享机制,多个分片之间可以共享相同的编译和链接结果。其中每片存在两种实例 Prompt Processor 和 Token Generator,也是两种处理模式。根据命名大致就可以看出,分别对应了处理输入的 Prompt 和依次输出 Token。运行时由 Prompt 实例处理输入的 Prompt,Token 实例处理单个生成 Token,二者之间是共享权重的,就像依赖动态库一样。
| Part1 Prompt instance Graph |
Part1 Token instance Graph |
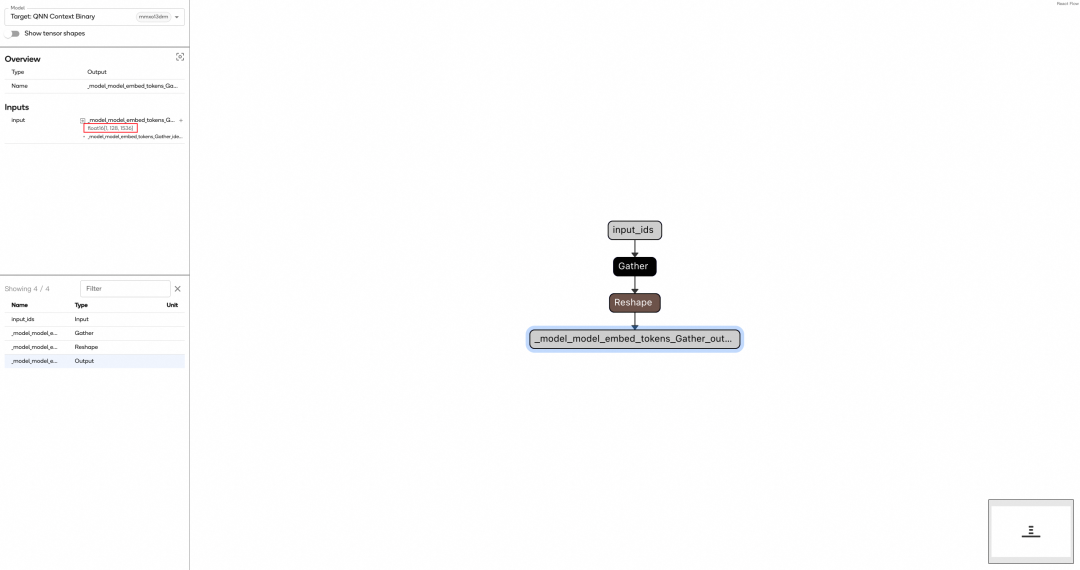 |
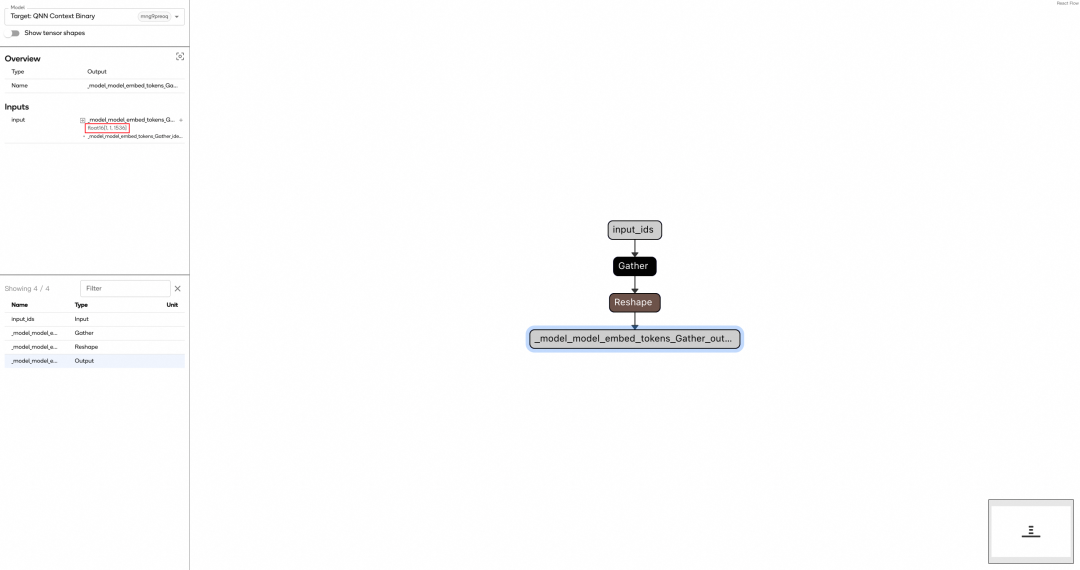 |
在模型量化分片之后,还需要将模型编译到目标 SoC 或者目标设备,并链接起来。所以在这样处理模型之后,Prompt Processor 和 Token Generator 可以并行编译,这样模型生成效率也可以得到提高。
编译转换和最佳实践(第 5 部分)中的流程基本一致,其中特殊的像 QNN HTP 后端是支持 RMSNorm 算子的,LLM 这里不需要单独做处理。
到此,模型可以顺利入端部署,运行时,多片模型可以被分段加载,而且 Genie 框架还提供了特定后端模型异步加载(allow-async-init)的方案,当然这里 HTP 不支持,所以不展开。
加载到内存中,4 个片对应 4 个 Context,每个 Context 包含 2 个 Graph。同样的,LLM 在 QNN 后端推理时也会分开 Prefill 和 Decode 处理 ,Prefill 会涉及到 Prompt 的 Graph 处理,而 Decode 涉及到 Token 的 Graph 处理。
7.3 KVCache 管理
Transformer 架构的 LLM 推理时,每次生成新 token,模型需要访问所有历史 token 的 Key 和 Value 向量来计算注意力。如果每次都重新计算,计算量会随序列长度平方级增长,通过 KVCache 对 K 和 V 向量进行缓存,避免重复计算,提高推理性能。
Genie 框架中对于 KVCache 的管理分为两种,如果检测到存在 HMX_WEIGHT_LAYOUT 类型的张量,使用对 NPU 硬件更友好的 NativeKV,其他默认走 SmartMask 智能管理的方式。
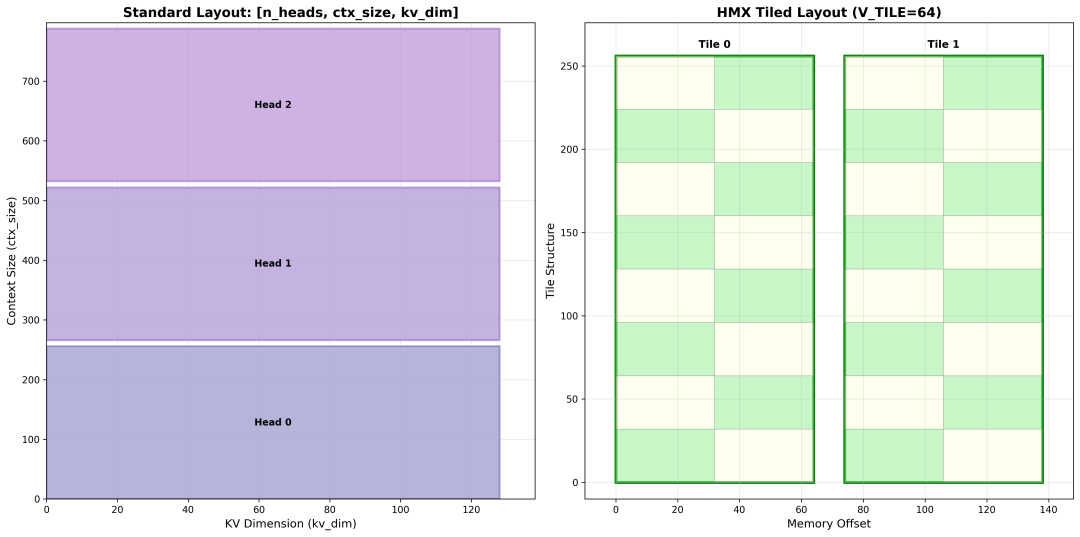
SmartMask 针对的是标准的张量格式,Key 和 Value Cache 内存布局分别是 [n_heads, kv_dim, ctx_size] 和 [n_heads, ctx_size, kv_dim]。在推理过程中,KVCache 的更新通过 memcpy 的方式从缓冲区复制到缓存里。
NativeKV 是针对 HMX(Hexagon Matrix eXtensions)权重格式的张量,相比 SmartMask 的模式, KV Cache 的内存布局和内存占用有一些有趣的特点。这种布局下会将平面索引转换成 HMX 硬件指令可以直接读取的小块(tile)的格式。至于分块内部的数据排布,也不是简单的“行优先”或“列优先”,是根据 SIMD(Single Instruction, Multiple Data)向量宽度进行了交错排列,这里不做更深入的展开。
K_TILE=256, V_TILE=64, KV_BLOCK_SIZE=1024 条件下:
| Key Cache 内存布局示意图 |
Value Cache 内存布局示意图 |
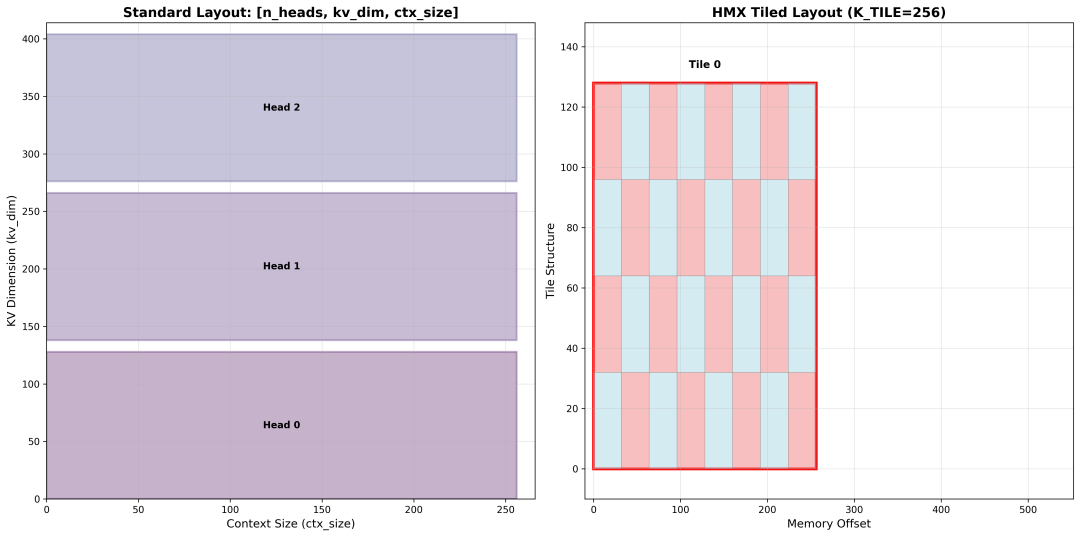 |
 |
NativeKV 对于数据、张量格式的限制比较严格,仅支持 uint8 的数据类型,也就意味着量化精度不能使用 int16、fp16 这种。另外就是对于 HMX 权重布局格式的限制,至于张量类型是不是 HMX_WEIGHT_LAYOUT,暂时还无从得知,有这部分经验的同学可以一起交流。
我们在验证 Qwen2.5-1.5B-Instruct 模型时,发现推理时是不支持 NativeKV 的,虽然相对 NativeKV 没有匹配硬件的布局和更强的性能,但 SmartMask 对于张量支持比较灵活,更稳定一些。后续也会继续探索尝试通过调整量化方式的方案来实现切换。
7.4 性能分析
推理效果可以看应用场景(第 8 部分)中的视频。我们针对验证过的几款 SoC 做了推理性能统计和对比分析。测试设备信息如下:
| SoC |
机型 |
配置 |
理论内存峰值带宽 |
| Snapdragon 8 Elite |
小米 15 |
RAM 12G |
~85 GB/s |
| Snapdragon 8 Gen 3 |
荣耀 Magic 6 |
RAM 16G |
~76.8 GB/s |
| Snapdragon 8 Gen 2 |
Samsung Galaxy S23 Ultra |
RAM 12G |
~68.3 GB/s |
8 Elite Gen5 的 SoC 我们暂时没有对应的设备,但是性能理论上和 8Elite 差不多。8 Elite Gen5 相对 8 Elite 提升不是很大,除了 GPU 子系统增加了 18MB 的 HPM(High Performance Memory)缓存,两款芯片都是 LPDDR5X 的内存,内存频率都是 5300MHz,理论计算下,二者的内存峰值带宽基本是接近的。
按照模型管理中的描述,LLM 场景下的模型分发使用已经编译好的静态图 Context Binary,首次加载和非首次加载之间,模型加载耗时并未有太大差别(~0.5s)。
Pipeline 初始化模型加载时,使用了内存映射(Memory Mapping)的方式加载模型二进制文件,可以直接映射到虚拟内存空间。加载时会因为模型反序列化有短暂的内存升高和回降,稳定之后正常的模型推理对于内存几乎无影响。
同样一个 Prompt 作为输入,采用相同的 Sampler 配置,模型均重新加载,缓存全部清除。
# Prompt
{"system": "You are a helpful assistant.","user": "中国的首都是哪里,有什么好吃的推荐"}
# Sampler Config
{"seed": 42, "temp": 0.8, "top-k": 40, "top-p": 0.95}
| 机型 |
计算单元 |
TTFT (ms) |
TPOT (ms/token) |
decode_num_token |
| 小米 15 |
QNN HTP |
~163 |
~56.8 |
~166 |
| 荣耀 Magic 6 |
QNN HTP |
~200 |
~60 |
~161 |
| Samsung Galaxy S23 Ultra |
QNN HTP |
~232 |
~74.9 |
~161 |
SoC NPU 推理 LLM 性能 8 Elite > 8 Gen 3 > 8 Gen 2,从实际测试数据上也可以体现。这里测试设备小米 15 的 RAN 配置差于荣耀 Magic 6,假定厂商对 SoC 的调教和内存限制一致的情况下,理论上同 RAM 配置搭载 8 Elite 的设备推理性能会更优。
8、应用场景
我们尝试以端纯离线推理的方式,结合 ASR + LLM 实现了类似千问/豆包 App 的“AI 打电话”功能(暂时没有加 TTS 的模型)。若加之 RAG,替代纯云端方案的大部分问答场景还是有可能的。
在电商 App 的场景下,我们认为当前的端侧推理在应用场景上和两三年前的“端智能”相比,并没有本质变化。4B 参数量的 LLM 对 App 来说仍然太大,更多还是放在操作系统层进行部署。而 1B 左右的模型部署在 App 里,NPU 上推理速度、加载时间和内存占用都可以接受。但问题来了:这样的模型到底能用来做什么?这也是我们一直在思考的问题。目前,我们把应用方向归纳为两类:
- 端云协同,降低成本:把原来跑在云端的一些模型能力移到 App 本地,减少机器和云端算力的消耗。我们正在将翻译、OCR 等一些基础能力放到端内来支持
- 满足时效与隐私需求:主要针对需要快速响应或涉及用户隐私的场景。我们目前正尝试在端内实时根据用户行为分析用户意图,并尝试构建端用户画像
这些应用其实都和 LLM 关系不大,更多还是依赖多个轻量、专用的小模型来组合解决问题。不过我们也在尝试跳出 App 的限制,探索在端侧部署 LLM 来应对一些新场景,目前还只有一个初步方向,这里就暂不展开了。
看到这大家也能明白,这是一个由技术驱动的项目,包含了我们团队对未来边缘计算的一些思考与判断。创新探索本来就有风险,并非所有项目一开始就有清晰的技术路径和明确的业务价值,但我们始终认为技术就该有技术的样子!
去年今日,很多同学对 AI 仍持保留态度,最初很多人难以理解,为何公司对 AI 如此倾注心力。因为每一次科技浪潮过后,总会淘汰那些傲慢而未能跟上时代的巨无霸。站在公司的角度也未必会认为所有团队在 AI 这条路上都会成功,这也是为什么对于大厂来说很多技术方案在 Preview 阶段,甚至于 Alpha 阶段就需要投入资源去尝试。
9、展望
Elon Musk:“In 5-6 years, we won’t have phones in the traditional sense. What we call a phone will really be an AI edge node - no apps, no OS, just AI.”
这句话是马斯克在 11 月初接受采访的时候提出的一个观点:五年到六年后,我们将没有传统意义上的手机,现在所谓的“手机”将变成一个纯粹的 AI 边缘节点——没有 App,没有操作系统,只有 AI。
虽然这句话有些夸张,但仔细思考下也有些道理。no OS 我们先不谈,no apps 其实手机厂商早就想做了。荣耀 Magic7 发布的时候,赵明现场点 2000 杯咖啡的 case 不知道大家是否还记得,这两年各大厂商的助手都在向智能体发展。
12 月初豆包和中兴合作的手机大家肯定也都看过测评甚至研究过原理了。从它的隐私报告里面看到了端侧有一个多模态大模型,尽管最终测评下来看它还不能离线使用。
猜测其系统采用端-云协同的架构:云端更大参数 LLM 负责意图理解与任务拆解,端侧可能有个 4B 左右多模态模型则作为 GUI MCP 存在,这样也能保证手机上的截图不上传到云端。
探究将手机作为 AI 载体这条路,不只是国内,国外厂商也在做。比较典型的就是 Google 的Pixel 10,而未来可能不只是手机作为 AI 的载体,一定会涌现出更多的智能终端设备。
我们也在积极拓展手机以外的智能设备领域,高通推出了专用于 AR 和 VR 的 SoC,其中部分型号集成了 NPU 计算单元。

在 2025 年末这个时间节点上,或许是 AI 最好的时代——资金奔涌、热情高涨、万众瞩目;可能也是最坏的时代——焦虑弥漫、泡沫隐现、前路迷茫。最后我们想说的是:潮起潮落,唯筑梦者推动时代前行;愿献微力,共筑一个更可计算的世界。
 发表于 2026-2-7 08:41:57
|
查看: 389|
回复: 0
发表于 2026-2-7 08:41:57
|
查看: 389|
回复: 0
