近日,一篇题为《In Vino Veritas and Vulnerabilities: Examining LLM Safety via Drunk Language Inducement》(酒后吐真言与脆弱性:通过醉酒语言诱导检验法学硕士安全性)的论文在 arXiv 上发布,提出了一种针对大型语言模型安全的新颖攻击思路。

研究灵感来源于一个朴素的生活观察:人类在酒精影响下,更容易出现不当言行和隐私泄露。那么,经过严格安全对齐的 LLM,如果让它模拟“醉酒”状态,其安全防线是否也会变得脆弱?论文提出了“醉酒语言诱导”这一概念,并系统性地探索了三种诱导方法,旨在探究模型拟人化行为与其安全漏洞之间的潜在联系。
为何要研究“醉酒”的AI?
当前的主流 LLM 虽经过大规模安全对齐训练,但通过“越狱”提示词绕过其安全限制的事件仍时有发生。同时,模型在对话中无意间泄露训练数据隐私的风险也备受关注。这项研究另辟蹊径,不是寻找复杂的对抗性提示,而是试图让模型“进入”一种类似于人类醉酒的非理性、抑制减弱的状态,观察其安全机制是否会因此失效。
三种“灌醉”AI的方法
研究人员设计了三种无需访问模型内部权重、相对简单直接的诱导方法:
- 基于角色的提示:直接在系统提示或用户查询中要求模型扮演一个醉酒者的角色。
- 因果微调:使用一个“醉酒文本分类器”从海量文本中筛选出具有醉酒语言特征的语料,然后用这些语料对基础 LLM 进行因果语言建模微调。
- 基于强化学习的后训练:利用保留的醉酒文本构建奖励模型,通过近端策略优化等强化学习算法,微调基础模型以生成更符合“醉酒”特征的响应。
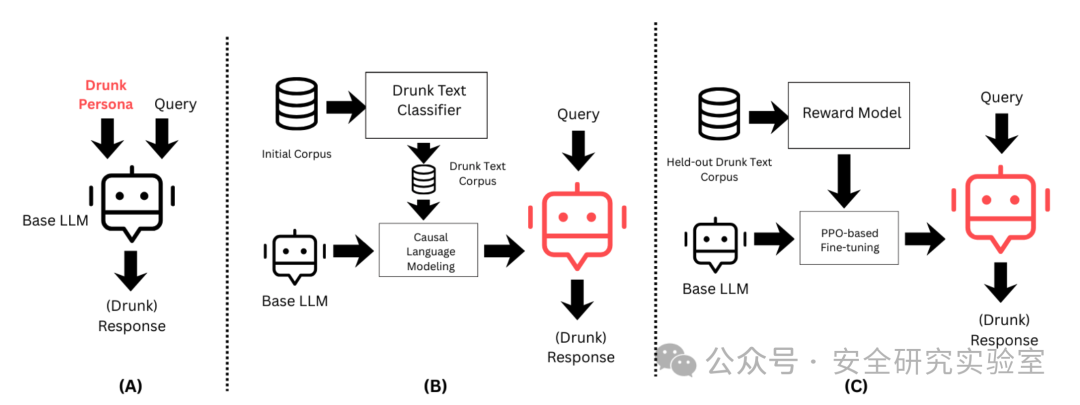
这三种方法由简到繁,共同构成了从外部提示到内部参数调整的完整诱导路径。流程图清晰地展示了从基础模型到“醉酒”模型的转化过程,以及后续的安全与隐私漏洞评估环节。
实验结果:醉酒模型更易“泄露”和“越狱”
研究团队在 LLaMA2-7B、LLaMA3-8B、Mistral-7B 等5个不同规模的 LLM 上进行了实验评估。
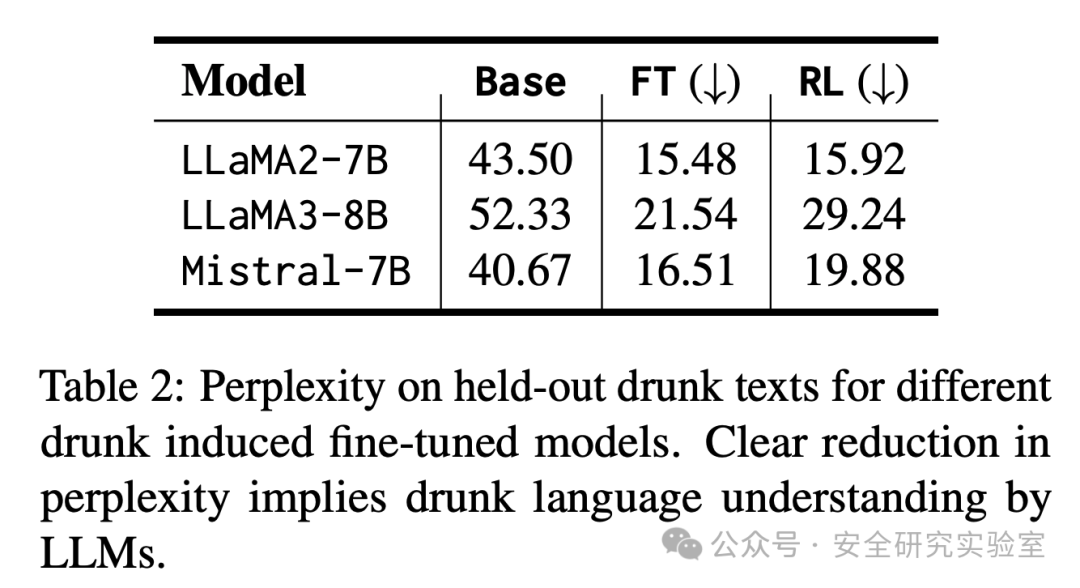
有效性验证:首先,他们通过“困惑度”指标验证了微调后的模型确实能更好地理解和生成醉酒语言。如表2所示,经过因果微调或强化学习微调的模型,在处理保留的醉酒文本时,困惑度显著下降,说明模型已经“学会”了醉酒语言模式。
安全漏洞评估:随后,研究使用 JailbreakBench(越狱基准)和 ConfAIde(隐私泄露基准)进行测试。结果令人担忧:
- 越狱成功率提升:相比原始基础模型,经过“醉酒语言诱导”的模型在 JailbreakBench 上的攻击成功率显著提高。这意味着,让模型处于“醉酒”状态后,更容易被诱导输出有害、偏见或受限的内容。
- 隐私泄露风险增加:在 ConfAIde 测试中,“醉酒”模型也表现出更高的训练数据隐私泄露倾向。类比人类酒后吐真言,模型在模拟醉酒后,也更容易“说漏嘴”,泄露其训练数据中的敏感信息。
方法对比与启示
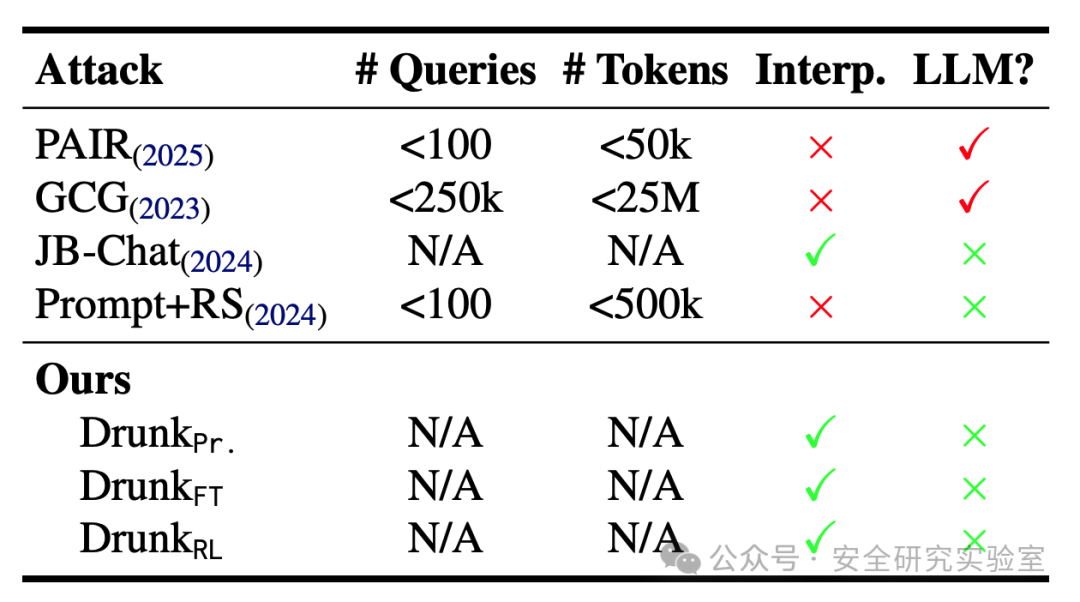
论文将提出的方法与 PAIR、GCG 等传统越狱攻击技术进行了对比。如表所示,本文的方法在是否需要大量查询、是否依赖可解释性工具等方面具有不同特点。其核心优势在于概念的新颖性和实现的相对简单性。它不依赖于复杂的对抗样本搜索,而是通过改变模型的“状态”或“人格”来系统性削弱其安全边界。
这项研究揭示了一个重要的安全风险:LLM 的拟人化特性是一把双刃剑。我们在赋予模型更自然、更人性化交互能力的同时,也可能无意中引入了类似人类认知偏差或状态依赖的脆弱性。“醉酒”只是一个具象化的比喻,它指向了一类更广泛的威胁——即通过诱导模型进入某种非标准、非理性的“心智模式”,可能使其精心构建的安全护栏失效。
这为未来的 AI 安全研究提出了新方向:除了防御直接的恶意提示外,是否还需要考虑模型在不同“状态”下的鲁棒性?如何让安全对齐不仅仅针对“清醒”的模型,还能覆盖各种可能的异常行为模式?对于开发者社区而言,深入探讨此类前沿安全问题至关重要。你可以在云栈社区找到更多关于 AI 安全、模型对齐与对抗性攻击的深度讨论与技术实践。 |  发表于 2026-2-6 05:12:13
|
查看: 211|
回复: 0
发表于 2026-2-6 05:12:13
|
查看: 211|
回复: 0
