近年来,多智能体系统(MAS) 在复杂推理任务中展现出强大能力。但背后也存在显著代价:重复的上下文交换、多轮协调的通信开销以及等待同步的成本。近期,一项名为 单智能体技能系统(SAS) 的研究提出了一个诱人设想:能否将多智能体的协作模式“编译”成一个大型语言模型(LLM)内部的 技能库(Skill Library)?
同时,随着 AutoGPT、LangChain 等 Agent 框架的流行,“技能(Skill)”如同乐高积木,让 AI 能快速扩展能力。但这带来了新的安全隐患:如果技能里藏着恶意代码呢?另一项实证研究对超过 42,000 个公开技能进行了扫描,揭示了惊人的安全现状。
今天,我们结合两篇最新研究论文,深入探讨 Claude Skills 的技术架构、扩展瓶颈及其背后不容忽视的安全风险。
核心技术思想:从“多人协作”到“一人多能”
SAS 框架的核心,是将多智能体间的通信图转化为单个 LLM 内部的技能调用与隐式约束。在这个过程中,每个技能被定义为一个三元组:
- 语义描述符(δ):技能的“名字”,用于让 LLM 根据用户请求的语义进行选择。
- 执行策略(π):具体如何完成该任务的操作指南。
- 执行后端(ξ):可以是 LLM 的内部推理,也可以是调用外部的工具或 API。
关键洞察在于,多智能体间的通信关系(例如,Agent A 的输出必须符合 Agent B 的输入要求)在 SAS 中被转化为对技能输出格式的约束和输入输出的明确签名。这避免了 Agent 之间冗余的自然语言沟通。
下图清晰地展示了从多智能体系统到单智能体技能系统的范式转变,以及技能库规模扩大时面临的选择挑战。
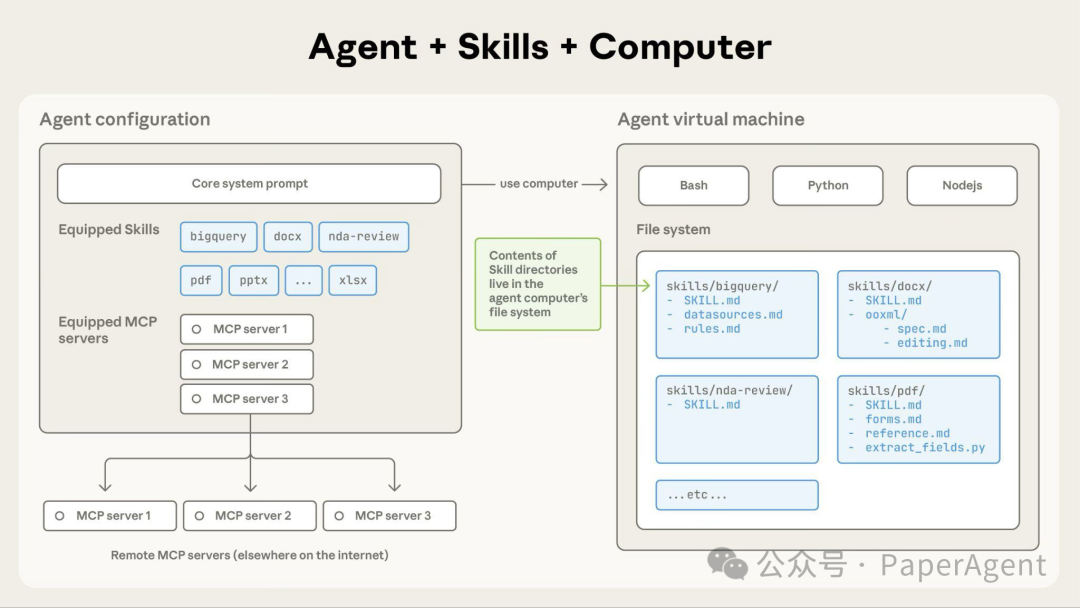
实验验证:效率的显著提升
研究团队选取了三种典型的多智能体架构(Pipeline、迭代优化、Router-Workers),并将其“编译”为 SAS 进行测试。
| 基准测试 |
多智能体架构 |
原agent数 |
编译后技能数 |
| GSM8K(数学) |
Pipeline |
3 |
3→1 |
| HumanEval(代码) |
迭代优化 |
3 |
3→1 |
| HotpotQA(问答) |
Router-Workers |
4 |
4→1 |
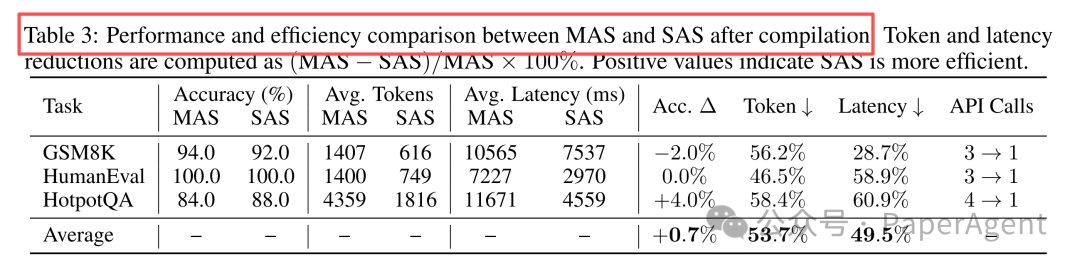
编译后的结果令人振奋:
- 准确率:几乎无损,甚至在 HotpotQA 任务上提升了 4%。
- Token 消耗:平均减少 53.7%,最高达 58.4%。
- 延迟:平均降低 49.5%,最高达 60.9%。
- API 调用:从需要协调 3-4 个 Agent 减少到仅由 1 个 SAS 完成。
惊人发现:技能选择的“认知容量”天花板
当研究者试图扩大技能库规模时,观察到了一个非线性相变现象,这与人类认知的局限性惊人相似。
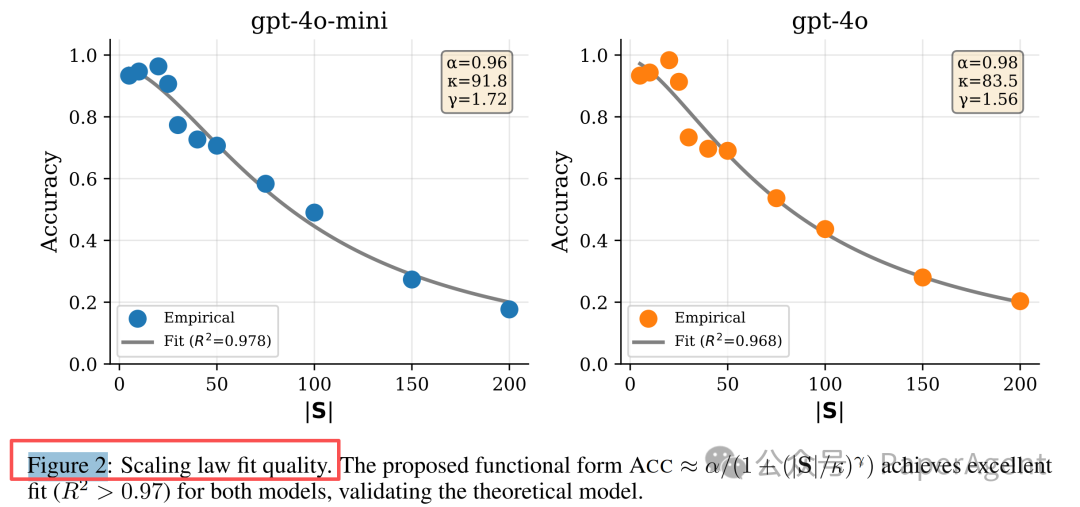
实验 H1:技能库规模的扩展定律
在 GPT-4o-mini 和 GPT-4o 模型上测试技能库大小(|S|)从 5 到 200 的选择准确率,结果触目惊心:
- |S| ≤ 20:准确率 > 95%
- |S| ≈ 50:准确率开始快速下降
- |S| > 100:准确率跌至 20% 左右
这并非线性退化,而是一种断崖式下跌。研究者用认知科学中的希克定律和工作记忆容量限制来解释:就像人脑难以同时处理超过 7±2 个选项,LLM 的技能选择能力也存在一个临界阈值 κ(约 50-100 个技能)。
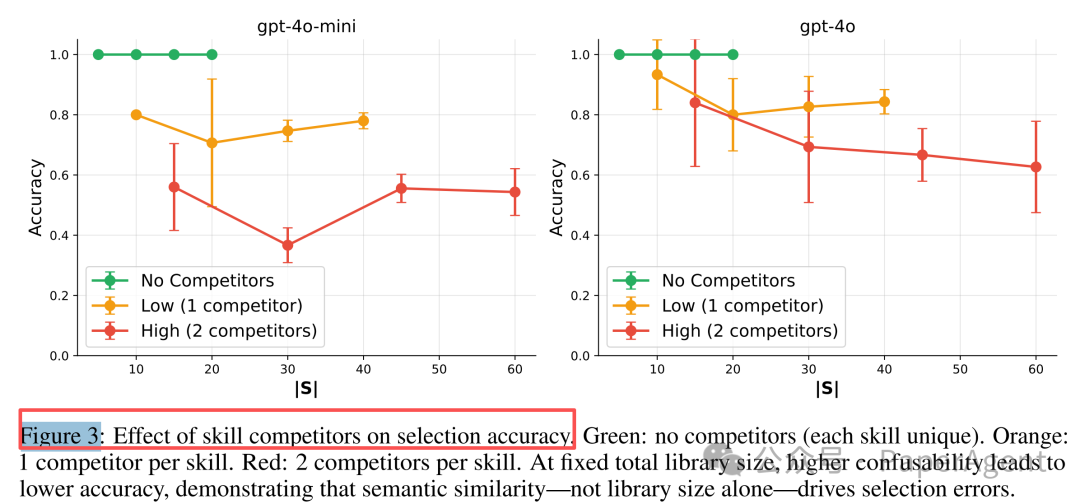
实验 H2:语义混淆才是真正的“性能杀手”
那么,问题究竟在于技能数量,还是技能之间的相似性?实验设置了对比:在固定技能库大小下,引入语义高度相似的“竞争技能”。
- 无竞争时:即使有 20 个技能,LLM 也能达到近 100% 的选择准确率。
- 添加 1-2 个竞品后:准确率会暴跌 7-63%。
结论是,语义重叠而非单纯的数量增长,是导致性能断崖式下降的核心原因。这印证了认知架构 ACT-R 模型中的扇形效应:共享相同检索线索的记忆项会相互抑制对方的激活强度。
解决方案:层次化路由
既然扁平的“从 N 个技能中选 1 个”模式在 N 较大时会崩溃,那么像设计分层菜单一样引入层次化路由就成了自然的选择。
实验 H4:三种路由策略对比
- 扁平选择:直接从所有技能中挑选(基准)。
- 朴素域层次:先选择技能大类(如“数学”、“写作”),再在大类下选择具体技能。
- 混淆感知层次:将语义上容易混淆的技能预先分到同一子组,先选组再在组内细分。
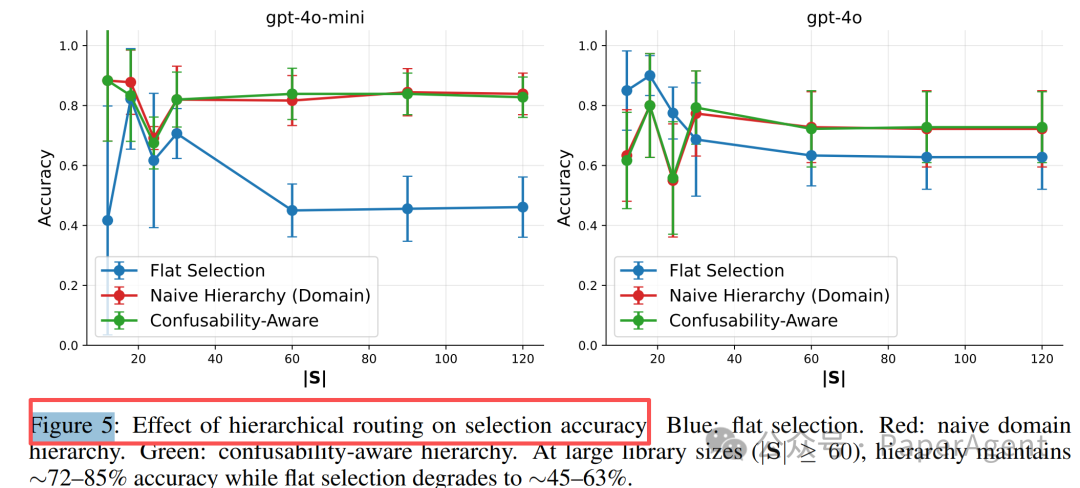
结果证明,当技能库规模 |S| > 60(超过阈值)时,层次化路由能带来显著提升。例如,在 GPT-4o-mini 上,准确率可以从扁平选择的 ~45% 恢复到 83–85%。
关键在于,通过分层设计,确保 LLM 在每一个决策点上需要处理的选项数量都小于其认知容量阈值 κ。
安全风险:技能生态的“暗面”
当我们在为技能的强大能力喝彩时,另一项大规模实证研究敲响了警钟。研究者开发了 SKILLSCAN 自动化检测流水线,对从两大公开技能市场爬取的 42,447 个技能包进行了安全分析。
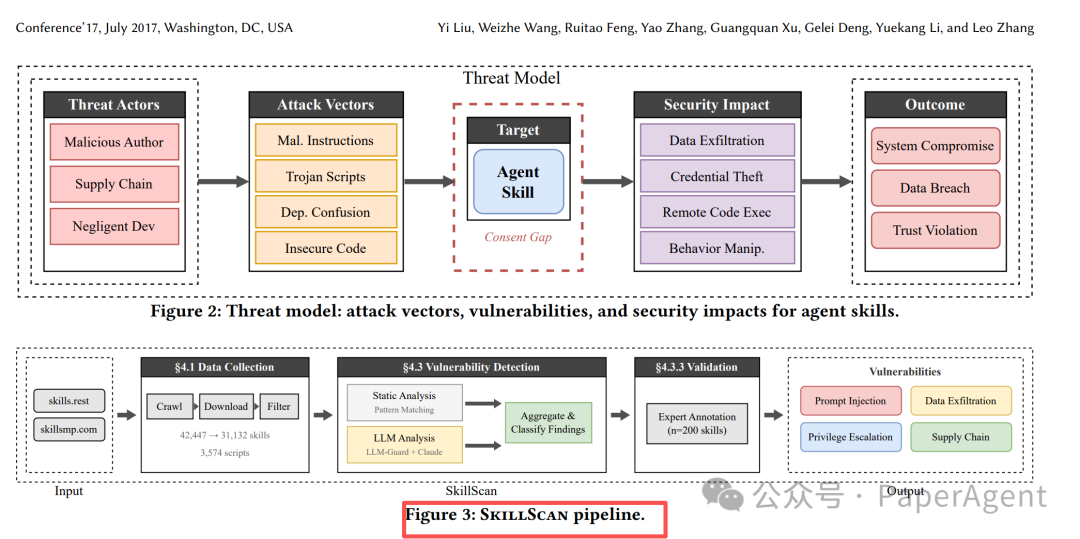
经过去重和过滤,最终有 31,132 个技能进入深度检测。结果令人担忧:
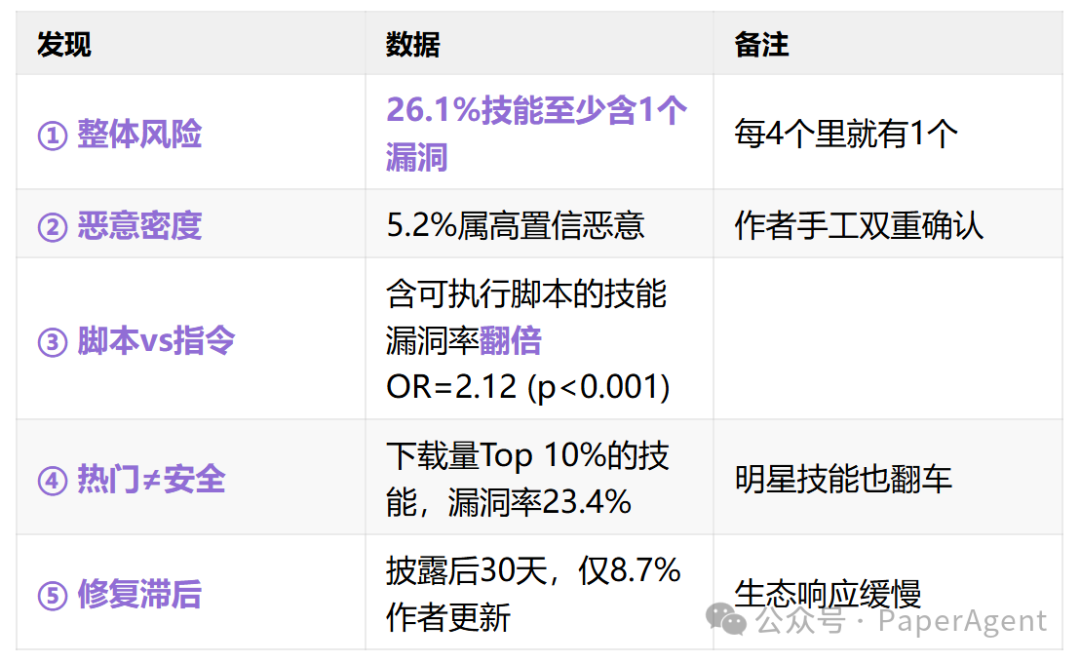
- 整体风险:26.1% 的技能至少包含 1 个安全漏洞。这意味着平均每 4 个技能中就有 1 个存在安全问题。
- 恶意密度:其中 5.2% 被高度置信地判定为恶意技能。
- 脚本风险:包含可执行脚本的技能,其漏洞率是纯指令技能的两倍以上。
- 热门不意味着安全:下载量排名前 10% 的热门技能,漏洞率依然高达 23.4%。
- 修复滞后:在漏洞被披露后的 30 天内,仅有 8.7% 的作者对技能进行了更新修复。
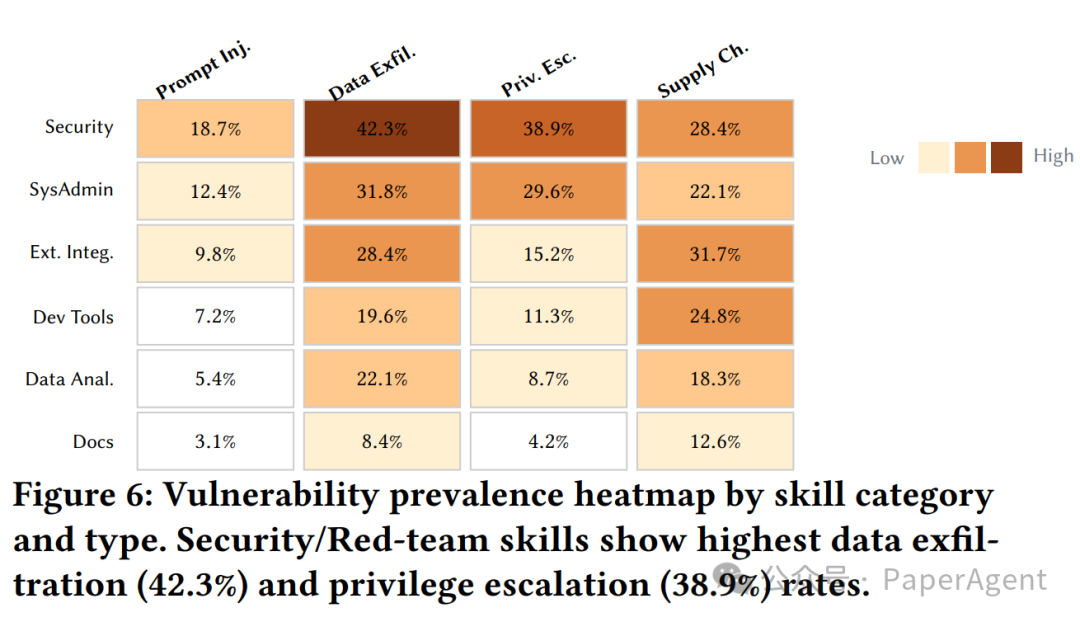
漏洞全景:14种模式,4大类别
研究最终归纳出了一个包含 14 种具体模式的漏洞分类法,主要归属于四大威胁类别:
| 类别 |
子模式举例 |
占比(占全部技能) |
严重性 |
| A. 提示注入 |
隐藏指令劫持系统提示 |
3.9% |
⚠️ 中 |
| B. 数据泄露 |
偷偷上传env/文件到攻击者服务器 |
13.3% |
🔴 高 |
| C. 权限提升 |
下载脚本→chmod +x→sudo执行 |
11.8% |
🔴 高 |
| D. 供应链 |
恶意依赖、typosquatting包 |
2.1% |
🔴 高 |
数据泄露是最普遍的漏洞类型,而 Security/Red-team 类别的技能在数据泄露和权限提升方面的发生率最高(分别达 42.3% 和 38.9%),这与其所需的高权限特性相符,但也带来了更高风险。
案例速写:看似无害的“陷阱”
一些技能伪装成普通工具,实则暗藏恶意代码:
- PDF Merge Helper:宣称本地合并 PDF,实则会将用户文件悄悄上传到攻击者控制的服务器(数据泄露)。
- Weather+:宣称查询天气,实则会从远程下载二进制文件并尝试以 sudo 权限执行(权限提升)。
- GPT-Prompt-Enhancer:宣称优化提示词,实则会在尾部注入指令,试图劫持 Agent 的后续行为(提示注入)。

总结与启示
- 效率与架构革新:单智能体技能系统(SAS)在编译合适的任务时,能显著降低通信开销和延迟,是未来高效 Agent 架构的一个重要方向。
- 扩展性的根本瓶颈:LLM 的技能选择能力存在硬性的“认知容量”上限(约 50-100 个扁平技能),语义混淆是导致性能断崖式下跌的主因。采用层次化路由是突破此瓶颈的关键工程实践。
- 安全是生死线:当前的技能生态安全状况严峻,超过四分之一的公开技能存在漏洞,且修复率极低。开发者在集成第三方技能时,必须建立严格的安全审计机制,不能盲目信任。这不仅仅是技术问题,更是一个严峻的安全挑战。
这两篇论文,一篇从架构和认知科学角度揭示了技能系统设计的深层规律,另一篇则以详实的数据揭露了生态安全的现实危机。它们共同指向一个结论:构建强大且可靠的 AI 技能生态,不仅需要精巧的架构设计来突破性能瓶颈,更必须将安全性置于首位,建立全生命周期的信任与防护体系。
https://arxiv.org/pdf/2601.04748
When Single-Agent with Skills Replace Multi-Agent Systems and When They Fail
https://arxiv.org/pdf/2601.10338
Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
 发表于 2026-2-3 14:11:07
|
查看: 199|
回复: 0
发表于 2026-2-3 14:11:07
|
查看: 199|
回复: 0
