Ulysses和RingAttention是目前序列并行(Sequence Parallel, SP)中常用的解决方案。Ulysses由DeepSpeed提出,最初主要用于解决Attention长序列训练的问题。但在当前的大语言模型(LLM)推理场景中,Ulysses依然可以发挥作用,不仅能应对序列过长的挑战,还能作为一种便捷的方式来处理负载不均的问题。
本文将带读者了解Ulysses的基本原理及其在推理中的应用,并介绍Ulysses在DeepSeekV3和V3.2模型上的具体优化实践。结合权重分片等优化手段,整体可以带来显著的性能提升。
Ulysses基本原理
Ulysses的全称是DeepSpeed‑Ulysses,其核心逻辑是:开启序列并行后,在多头注意力(Multi-Head Attention)运算之前,多个GPU设备之间会进行数据交换,使单个GPU能够拥有完整的输入序列;Attention计算完成后,再通过集合通信将序列还原为原本被切分后的形状。
为了便于理解,我们先看一个简化的例子。LLM中输入的序列经过tokenizer后生成token id。不考虑batch的情况,输入经过embedding层后,其形状变为:[seq_len, hidden_dim],其中seq_len为序列长度,hidden_dim为隐藏层维度。
在下图示例中,token数量为2,编码后数据变为了[2, 6]。
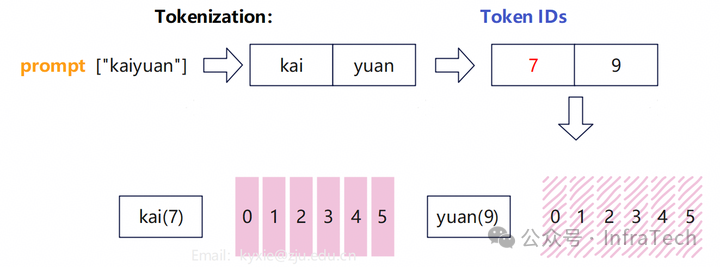
接下来,用这个数据作为输入,对比有无Ulysses时MHA计算的差异。
标准MHA运算
在不进行序列分割的情况下,单个GPU设备运算MHA的过程如下图所示,其关键步骤为:
- QKV线性投影计算:输入投影后获得3个尺寸相同的数据Q、K、V,其shape=
[2, 6]。
- QKV数据分头操作:在
hidden_dim维度将QKV数据进行切分,示例中头数(head)为2,则shape变为[2, 2, 3]。
- Attention计算:每个head独立进行注意力运算获得输出O,其shape=
[2, 3]。
- 数据view操作:在
hidden_dim维度将数据还原,得到最后输出,其shape=[2, 6]。
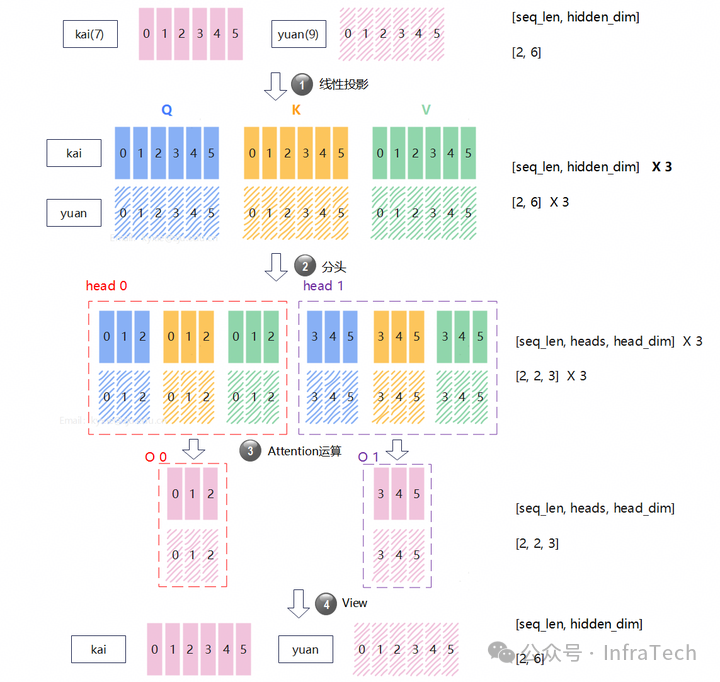
可以看到,MHA运算过程中数据的尺寸会发生变化,但最后的输出与最开始的输入尺寸保持一致。
Ulysses的MHA运算
当Ulysses序列并行开启后,每个设备只拥有部分序列数据。计算方式为:L = seq_len / sp(sp为并行度)。
继续以上面的示例来说明。在开启序列并行(SP=2)后,序列会被分割成两份,每个GPU各拿到一个token,如下图所示。此时,计算步骤变为:
- QKV线性投影计算:每个GPU将本地输入分别投影后获得3个尺寸相同的数据Q、K、V,其shape=
[1, 6]。
- all-to-all数据交换:数据进行序列维度交换,让每个GPU都拥有完整的序列,但不同GPU分到的head不一样。交换后,每个head的数据shape=
[2, 1, 3]。
- Attention计算:每个GPU完成本地Attention计算,获得对应head的输出O,其shape=
[2, 1, 3]。
- all-to-all数据交换:GPU之间交换Attention计算结果,每个GPU拿回原本属于自己的那部分序列数据,shape=
[1, 6]。
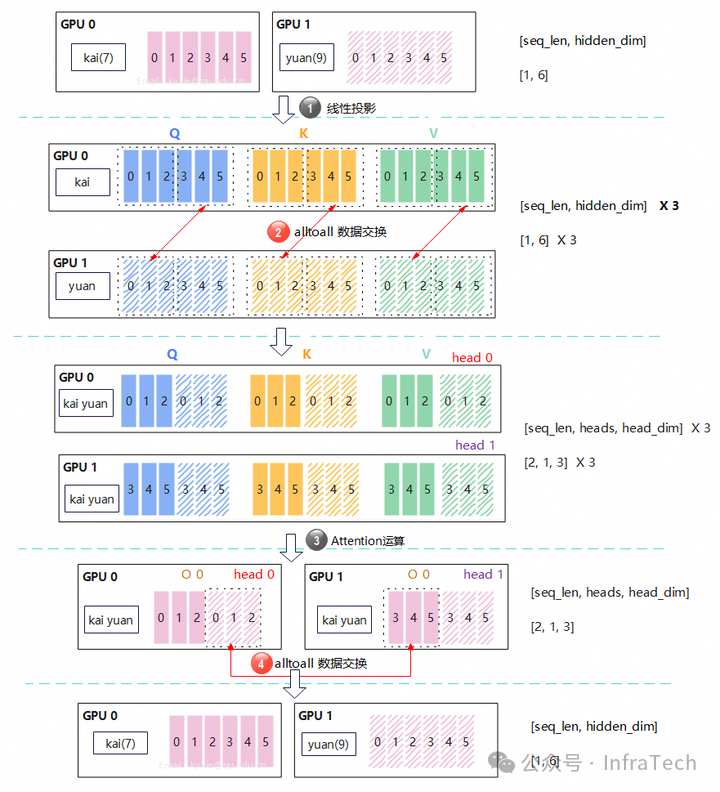
Ulysses的代码示例
我们可以通过PyTorch构建一个Ulysses的代码用例来示意整个过程。思路是:先定义一个标准Attention运算作为参照,再定义一个模拟Ulysses原理的运算过程。关键点包括:
- 用for循环来模拟多个GPU的运算。
- 定义两个函数:模拟attention计算前、后的all-to-all通信过程。
- 为便于结果比对,序列并行在Attention运算内部完成,最终再将计算结果拼接在一起。
首先,我们用for循环模拟多GPU运算的核心部分:
attn_outputs = []
for i in range(self.num_gpus):
Q_ex = Q_exchanged[i]
K_ex = K_exchanged[i]
V_ex = V_exchanged[i]
# 转置用于注意力计算
Q_ex = Q_ex.transpose(0, 1) # [local_num_heads, seq_len, head_dim]
K_ex = K_ex.transpose(0, 1)
V_ex = V_ex.transpose(0, 1)
print(f" GPU{i}: 转置后 shape: {Q_ex.shape}")
# 注意力计算
attn_scores = torch.matmul(Q_ex, K_ex.transpose(-2, -1)) / (self.head_dim ** 0.5)
attn_scores = torch.softmax(attn_scores, dim=-1)
attn_output = torch.matmul(attn_scores, V_ex)
print(f" GPU{i}: 注意力计算后 shape: {attn_output.shape}")
# 转置回来
attn_output = attn_output.transpose(0, 1) # [seq_len, local_num_heads, head_dim]
print(f" GPU{i}: 转置回来 shape: {attn_output.shape}")
attn_outputs.append(attn_output)
接着,是模拟all-to-all通信过程的两个函数:
def all_to_all_head_to_sequence(self, data_list):
"""模拟All-to-All通信:从头维度交换到序列维度"""
# data_list: 每个GPU的数据 [local_seq_len, num_heads, head_dim]
# 返回: 每个GPU的数据 [seq_len, local_num_heads, head_dim]
num_gpus = len(data_list)
local_seq_len = data_list[0].shape[0]
seq_len = local_seq_len * num_gpus
results = []
for gpu_i in range(num_gpus):
# 收集来自所有GPU的第gpu_i个头的部分
parts = []
for gpu_j in range(num_gpus):
# 从GPU_j获取对应头的部分
part = data_list[gpu_j][:, gpu_i*self.local_num_heads:(gpu_i+1)*self.local_num_heads, :]
parts.append(part)
# 在序列维度拼接
result = torch.cat(parts, dim=0) # [seq_len, local_num_heads, head_dim]
results.append(result)
return results
def all_to_all_sequence_to_head(self, data_list):
"""模拟All-to-All通信:从序列维度交换到头维度"""
# data_list: 每个GPU的数据 [seq_len, local_num_heads, head_dim]
# 返回: 每个GPU的数据 [local_seq_len, num_heads, head_dim]
num_gpus = len(data_list)
seq_len = data_list[0].shape[0]
local_seq_len = seq_len // num_gpus
results = []
for gpu_i in range(num_gpus):
# 收集来自所有GPU的第gpu_i个序列部分
parts = []
for gpu_j in range(num_gpus):
# 从GPU_j获取对应序列的部分
part = data_list[gpu_j][gpu_i*local_seq_len:(gpu_i+1)*local_seq_len, :, :]
parts.append(part)
# 在头维度拼接
result = torch.cat(parts, dim=1) # [local_seq_len, num_heads, head_dim]
results.append(result)
return results
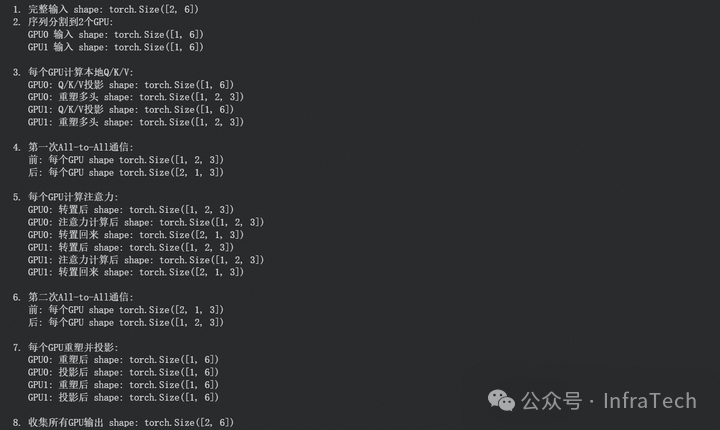
构建一个对比函数,每步都打印张量shape,得到的输出对比如下:
标准MHA运算各步骤张量形状:

Ulysses的MHA运算各步骤张量形状:
有了上述了解之后,再来看DeepSpeed论文中的原理图就更容易理解了。如下图所示,其中d(hidden_dim)的维度为4,d维度数据对应图示中的[1, 2, 3, 4],而在seq_len维度并未给出具体示意。
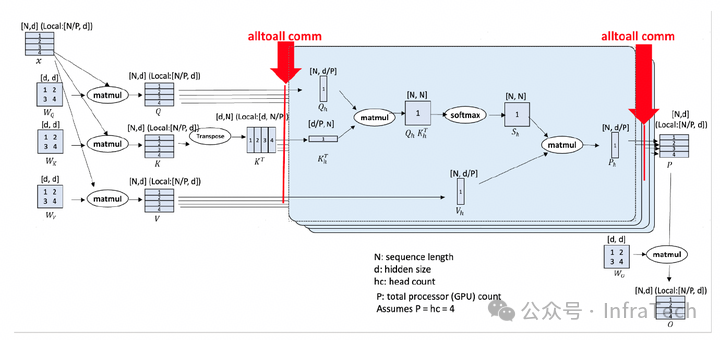
推理中的应用
在预填充(Prefill)阶段,长序列问题通常通过分块预填充(Chunked Prefill)特性来解决。一般不会直接使用Ulysses来处理长序列问题,但它可以用来解决数据并行(Data Parallel, DP)中的负载不均衡问题。
下图所示为DP=2的场景:如果不同DP接收的请求序列长度不一致,DP之间的计算时长就会出现差异。
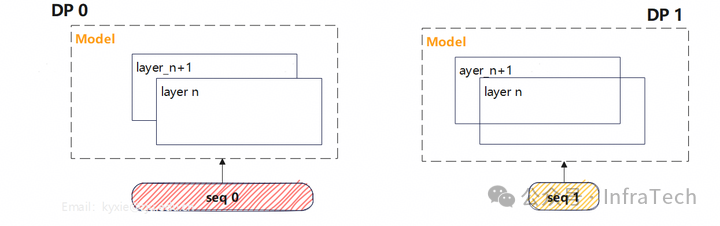
计算的时间差异与序列的长度正相关。以注意力阶段(以MLA为例)的计算进行分析,不同模块的计算时间与序列长度的关系如下图所示:
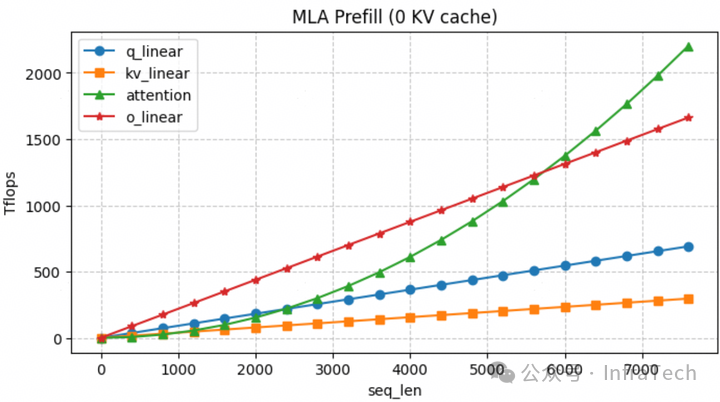
为了让不同DP之间的负载更加均衡,可以进行序列重分配。通过跨DP域混合序列并均匀分配,使每个DP域获得长度基本相等的请求。下图展示的是两个序列进行混合SP的示例:
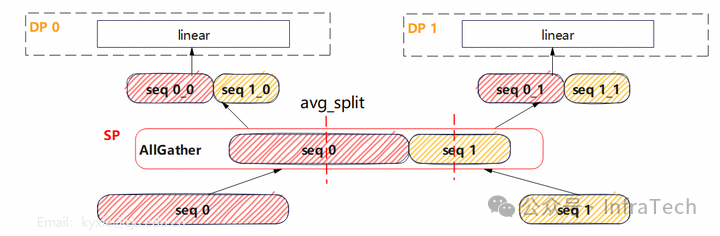
对于注意力计算而言,由于存在softmax(QK^T)的计算,因此要求序列保持完整,否则就需要使用softmax的分块运算。而Ulysses方案能保证注意力计算的正确性:在Attention计算之前,会先将序列进行还原,使每个DP都拥有完整的请求序列。
在跨DP域的序列并行中,Ulysses增加了如下要求:
- 在Attention计算之前,需要执行AllGather操作,这是跨DP域的序列还原操作。
- 分头操作不是以GPU数量(即SP中的Rank数量)为单位,而是以DP数量为单位。
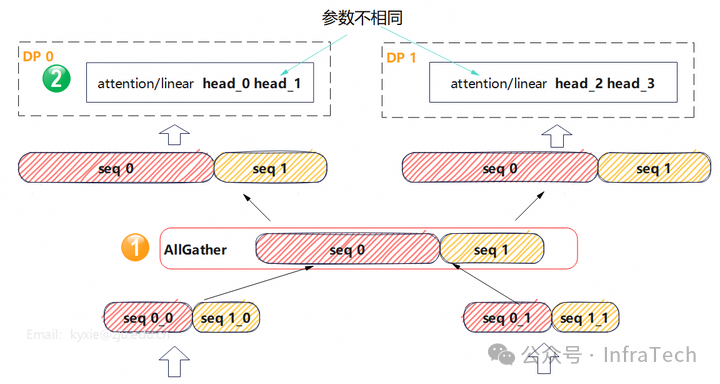
通过这种方式,就可以解决不同DP之间计算负载不均的问题,同时不需要像Chunked Prefill那样引入复杂的分块运算。这种在分布式系统中协调计算资源的方法,是构建高效、稳定后端架构的关键考量之一。
DeepSeek性能优化实践
V3优化方案
在DeepSeek-V3的模型中,Prefill阶段MLA的计算形态为MHA模式。数据经过上采样运算后,Q、K、V都会进行多头切分,而k_pe(应用了RoPE的K)不会进行分头操作。因此,在使用Ulysses时,k_pe需要通过allgather集合通信来完成序列还原。
从下面的结构示意图中可以看到使用Ulysses后带来的变化:
- Q/KV上采样权重矩阵变为原来的1/N。
- KV cache存储量变为原来的1/N。
- 多了4处集合通信操作。
- O投影权重矩阵变为原来的1/N。
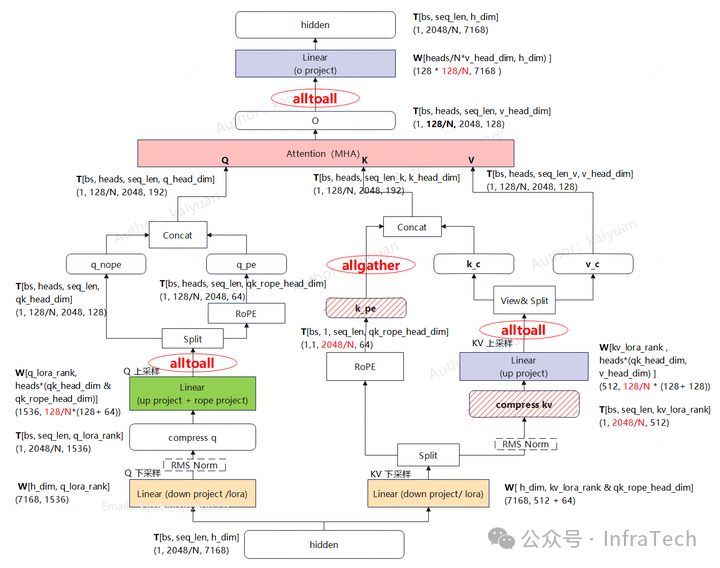
该方案既能降低权重、KV cache的显存占用,同时MHA不需要采用分块运算,较大地优化了推理性能。
但在实践中会面临一个问题:vLLM等推理框架中多DP之间的调度器(Scheduler)是独立的,而KV cache的空间由Scheduler分配。若DP实际使用的KV cache长度与Scheduler分配的长度不一致,就会出现错误。
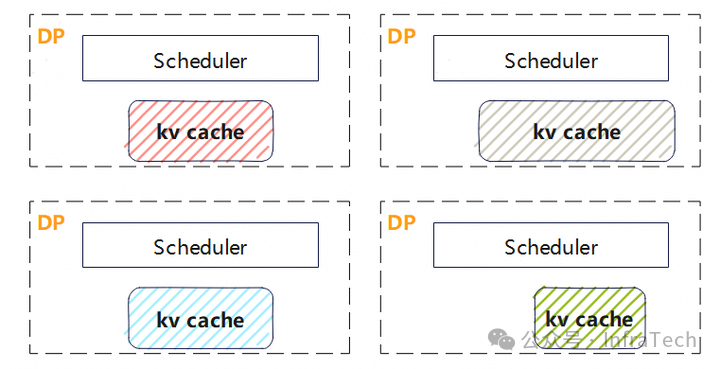
所以,要实现Ulysses功能,要么将DP限制为1,要么修改Scheduler的逻辑。在我们的实践中,采用了一种折中方案来规避对Scheduler的修改:将DP之间的all-to-all操作替换为allgather操作,使请求序列在DP域内完成还原。
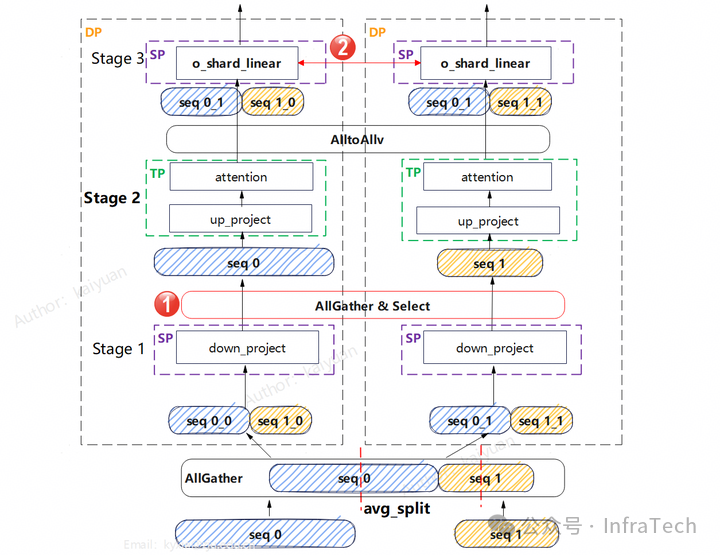
方案的主要执行步骤:
- 将所有请求数据拼接后,均匀切分并送入stage 1进行计算。
- 将down_proj的输出执行allgather,随后从中选取原DP域所需的数据。
- stage 2在DP域内进行TP切分并行计算。
- attention计算完成后,执行all-to-all完成数据分发。
- stage 3的输入为切分后的序列,o_proj计算采用了权重分片方式。
V3.2模块的计算特征
DeepSeek-V3.2与V3的主要差异在于注意力运算,V3.2采用了DSA(DeepSeek Attention)模块。为了提升整体性能,DSA推理的Prefill以及Decode阶段均采用的是MQA(Multi-Query Attention)模式。
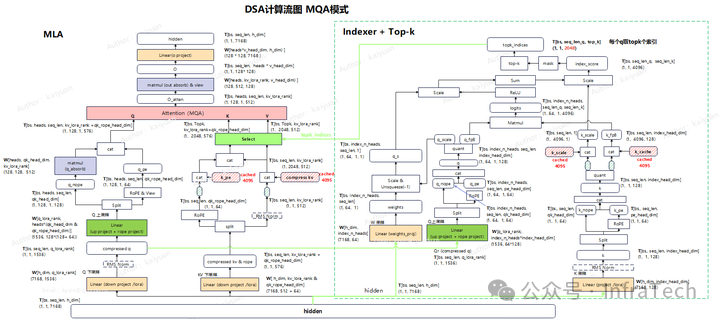
计算量方面,在将Prefill转换成MQA形态后,其Flops计算方式如下(公式已简化):
q_down_proj = 2 * bs * seq_len * h_dim * q_lora_rank
q_up_proj = 2 * bs * seq_len * q_lora_rank * heads * (qk_head_dim + qk_rope_head_dim)
q_absorb = 2 * bs * heads * seq_len * qk_head_dim * kv_lora_rank
q_linear = q_down_proj + q_up_proj + q_absorb
kv_down_proj = 2 * bs * seq_len * h_dim * (kv_lora_rank + qk_rope_head_dim)
kv_linear = kv_down_proj
kv_seq_len = (seq_len + cache_len) if topk is None else topk
kv_scores = 2 * bs * heads * seq_len * kv_seq_len * (kv_lora_rank + qk_rope_head_dim) / causal_mask_cof
qkv = 2 * bs * heads * seq_len * kv_seq_len * kv_lora_rank / causal_mask_cof
out_absorb = 2 * bs * seq_len * heads * kv_lora_rank * v_head_dim
out = 2 * bs * seq_len * n_heads * v_head_dim * h_dim + out_absorb
attention = kv_scores + qkv
mla_absorb_flops = attention + kv_linear + q_linear + out
可得到DSA与MLA的计算量对比数据。
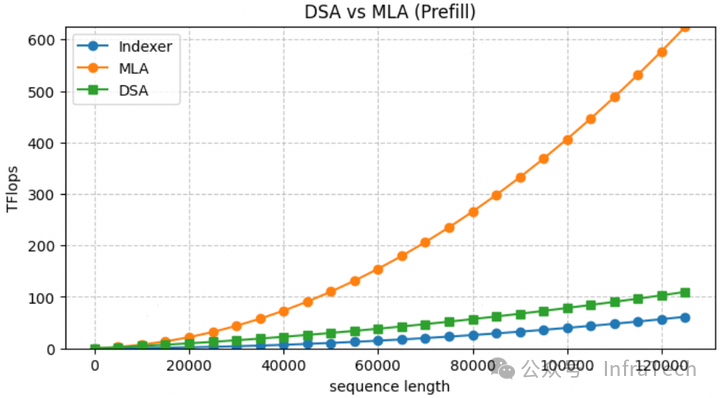
DSA的计算量增长主要源于Indexer的计算量增加,且随着序列长度的增长,Indexer计算量在整体中的占比会逐步提升。
显存方面,超长序列下,Indexer的显存需求巨大。例如,在128K序列长度场景下,FP8格式的logits张量显存占用可能达到976.6GB。
因此,在DSA的性能优化中,Indexer部分是关键所在。并行策略对Indexer性能优化至关重要。
并行策略实施的基本思路:
- MLA模块:q通道存在多头运算,因此不同rank之间可以按头进行分布式计算;而k和v的头数为1,无法再进一步切分,所以在完成down_project运算后,需要对数据执行allgather操作。
- Indexer模块:Indexer从左到右主要的三条计算通道分别是w、q、k;其中q/w有多头运算。q和k要进行矩阵乘法(matmul),k序列需要还原。
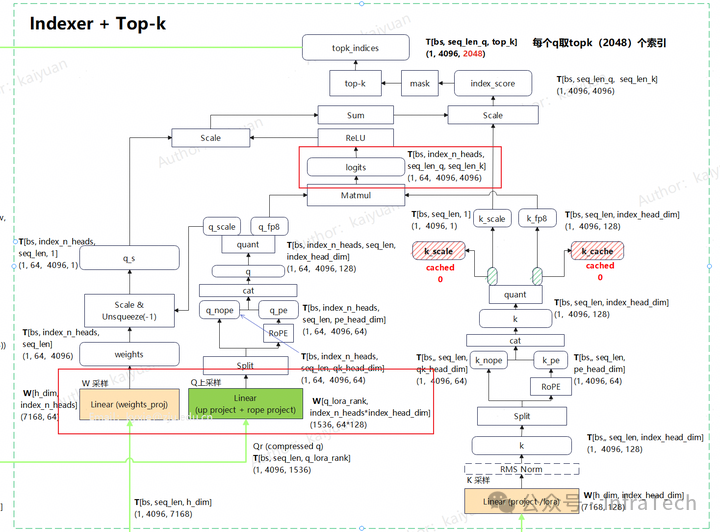
若开启Ulysses,需要在q和k的matmul前进行序列还原。通信方式设计为:
- q通道用all-to-all进行数据交换,w通道由于数据较小,直接用allgather操作。
- k值头数为1,使用allgather进行数据汇聚。
- sum求和操作替换成allreduce操作。
V3.2优化方案
设计中的挑战与解决思路:
-
如何适配框架的KV Cache管理逻辑?
- 挑战:若所有DP域开启序列并行,则每个DP内的Scheduler需要根据分到的序列长度来分配KV cache。在DSA中,Indexer内部也涉及KV cache的分配。
- 解决思路:考虑限定DP=1,从而避免多DP下不同Scheduler的协同问题。并且让Indexer和MLA的切分策略保持一致。
-
如何降低额外的集合通信影响?
- 挑战:根据方案1,MLA和Indexer采用了相同切分方式的序列并行,所以都会有额外的集合通信。
- 解决思路:利用多流之间的计算-通信掩盖。MLA和Indexer一共有5条计算路径,集合通信位置不同,可以让这些通信与计算错开执行。
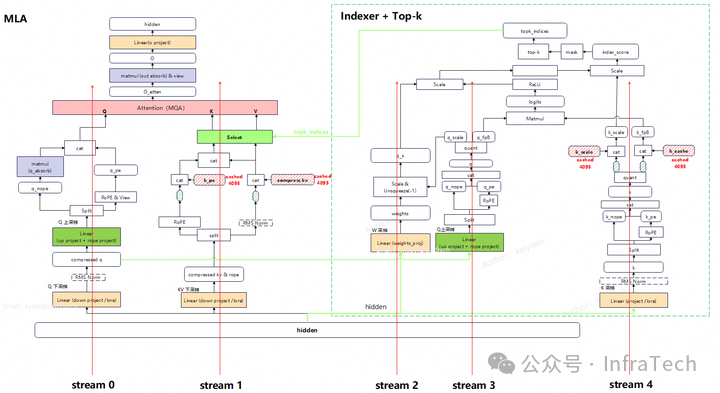
- 如何解决超长序列下的显存压力?
- 挑战:Indexer显存占用量大,Ulysses的分头计算只能降低部分显存。
- 解决方式:
- 将allreduce替换成reduce-scatter + allgather,并采用分布式排序。
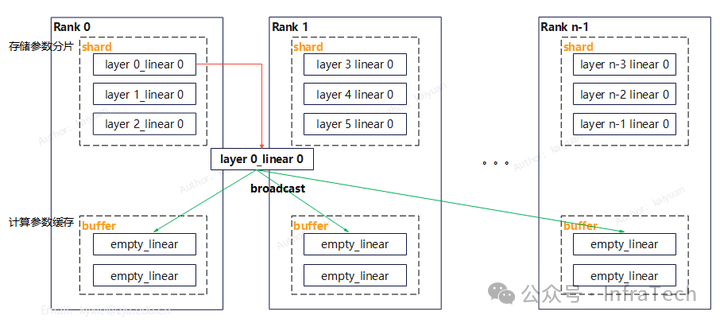
- 降低MLA层的冗余权重:借鉴FSDP和ZeRO的核心思想,对权重进行分片处理。关键思路是每个设备仅存储部分线性层的分片参数,通过一个缓冲区(buffer)缓存待计算的数据,参数则通过广播方式分发至每个rank。为了实现计算与通信的重叠掩盖,可将缓冲区大小设置为大于1的值以实现参数预取。
结合上述解决方式,我们梳理出DeepSeek-V3.2在Prefill阶段的两种优化实施方案。
方案一:Q head切分
Q head切分是指在运算中,Q通道的运算按照head维度切分,而序列维度保持完整。对MLA和Indexer都采用相同处理方式。集合通信引入的位置如下图所示:
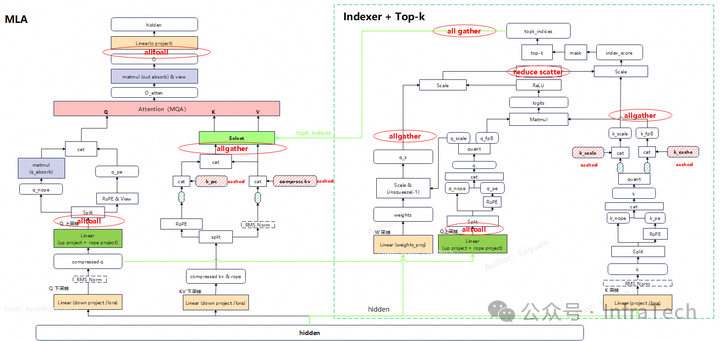
该方案的优势是:能够降低Q的采样矩阵、O的权重矩阵的大小,KV cache存储量也能降低。
方案二:Q Sequence切分
根据注意力序列并行的特点,若仅对Q通道进行序列切分,而K、V保持完整,则运算后直接拼接各分块的结果与原始整体计算结果是等价的。
根据该结论,MLA的Q通道,Indexer的Q、W通道均可以保持序列切分的形态,不需要序列还原。
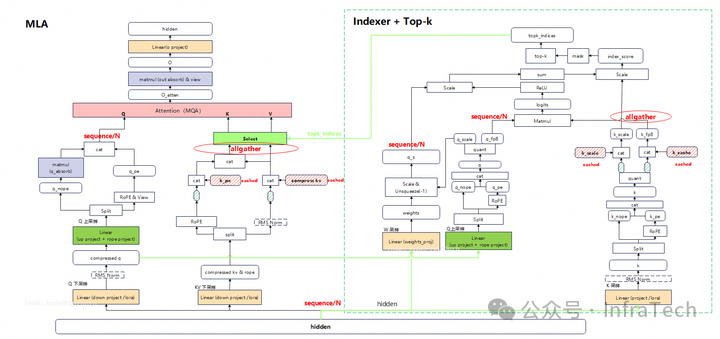
该方案的优势是:集合通信操作更少。但需要完整的投影计算权重矩阵,显存占用量更大。不过,这一部分影响可以通过前述的权重分片策略进行缓解。
测试与收益分析
DeepSeek-V3
在DeepSeek-V3的Ulysses方案实践中,整体能够获得显著的性能收益。收益大小与序列长度、并行参数相关,以下列举两个测试场景。
- 场景一:序列总长度限制为4K,采用DP4、TP4。
- 测试结果:在定长输入条件下性能有20%+收益。在随机长度输入的情况下有50%收益。
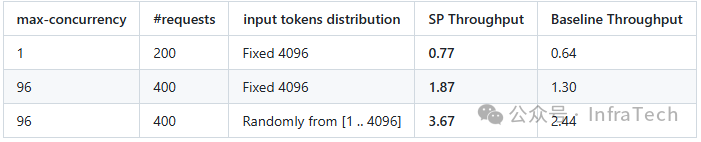
- 场景二:测试DP1、TP16场景,基线是无SP纯TP。
- 测试结果:该场景下无跨DP域负载均衡需求,测试显示了Ulysses特性本身带来的性能影响。

DeepSeek-V3.2
DSA目前的开源实现主要参考vLLM/SGLang社区。由于我们的实践场景基于NPU(昇腾910B/C),其硬件架构与GPU存在差异,因此LightningIndexer对应算子需要重新适配。
经过上述并行优化,相比基线能够实现显著的性能提升。

在实践过程中我们发现,在NPU上序列过长会对DSA的计算性能造成较为明显的影响,而在GPU上这种影响相对较小。造成这种差异的原因可能在于NPU上的算子目前仍有较大的优化空间。
总之,不管在GPU还是NPU上,Ulysses这种序列并行的方式能够为DSA推理带来可观的性能提升。对于希望深入探讨Transformer模型底层优化和并行计算实践的开发者,可以在云栈社区找到更多相关资源和讨论。
附:TopK 指令实现
最后,分享一个在NPU上实现LightningIndexer中TopK算子的思路。该算子的核心是在长达数十万的序列中,为每个token高效且准确地筛选出分数最高的k(例如2048)个索引。当前实现基于昇腾支持的排序指令进行全量排序,Top-k计算过程分为三步:
1. 分组排序
通过VBS32指令将每32个token按照其Score进行稳定降序排列,输出其排序后的Score向量以及对应的索引向量,直到将整个序列的token分组排序完毕。
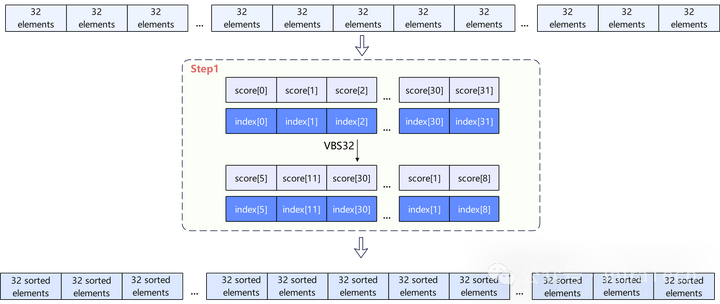
2. 归并
通过VMS4v2指令将至多4组(可为2/3组)长度为32、128、512的已排序向量进行归并,直到合并后的向量长度达到2048。合并仍然按照对应Score进行稳定降序排列,输出长度为各组输入长度之和的向量及其索引。
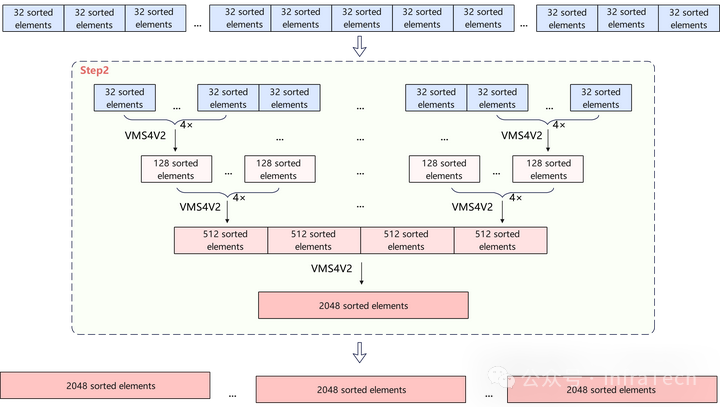
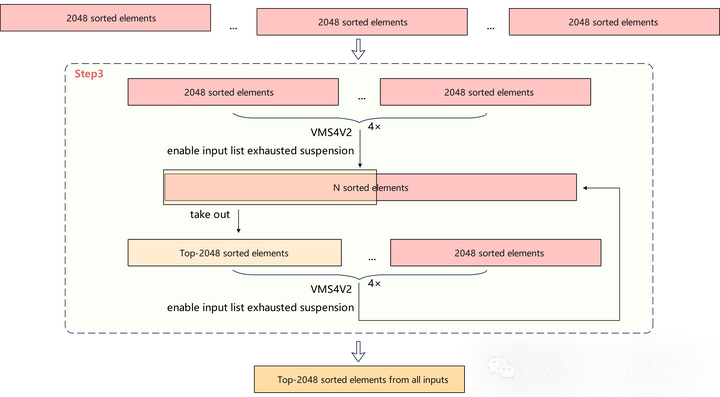
3. 规约
采用VMS4v2指令的“输入耗尽暂停”模式,将至多4组长度为2048的已排序向量进行归并,取出前k=2048个元素。将结果与另外未参与合并的有序向量重复进行Top-k计算,直到比较完所有向量,得到最终整个序列中得分最高的2048个索引。
 发表于 2026-2-3 14:40:29
|
查看: 285|
回复: 0
发表于 2026-2-3 14:40:29
|
查看: 285|
回复: 0
