当面对单机 PyTorch 模型推理时,小数据量尚可应付。一旦数据规模跃升至万级甚至百万级,诸多瓶颈便暴露无遗:内存不足、GPU利用率低下、I/O成为拖累,更不用说还要考虑容错和多机扩展的复杂性。
传统的解决方案往往需要手动编写多线程 DataLoader、管理批次队列并精细调度 GPU 资源,不仅工程量大,调试也颇为繁琐。Ray Data 提供了一个更为轻量的替代方案:它允许开发者在几乎不改变原有 PyTorch 模型代码的前提下,将单机推理流程无缝扩展为分布式数据处理管道。
原始的 PyTorch 单机推理代码
一个典型的推理场景通常包括模型加载、数据预处理和批量预测,其核心代码大致如下:
import torch
import torchvision
from PIL import Image
from typing import List
class TorchPredictor:
def __init__(self, model: torchvision.models, weights: torchvision.models):
self.weights = weights
self.model = model(weights=weights)
self.model.eval()
self.transform = weights.transforms()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
def predict_batch(self, batch: List[Image.Image]) -> torch.Tensor:
with torch.inference_mode():
batch = torch.stack([
self.transform(img.convert("RGB")) for img in batch
]).to(self.device)
logits = self.model(batch)
probs = torch.nn.functional.softmax(logits, dim=1)
return probs
处理少量图片时,这段代码运行良好:
predictor = TorchPredictor(
torchvision.models.resnet152,
torchvision.models.ResNet152_Weights.DEFAULT
)
images = [
Image.open('/content/corn.png').convert("RGB"),
Image.open('/content/corn.png').convert("RGB")
]
predictions = predictor.predict_batch(images)
大数据量带来的挑战
当图片数量从几张激增到几万甚至上百万张时,情况将截然不同。
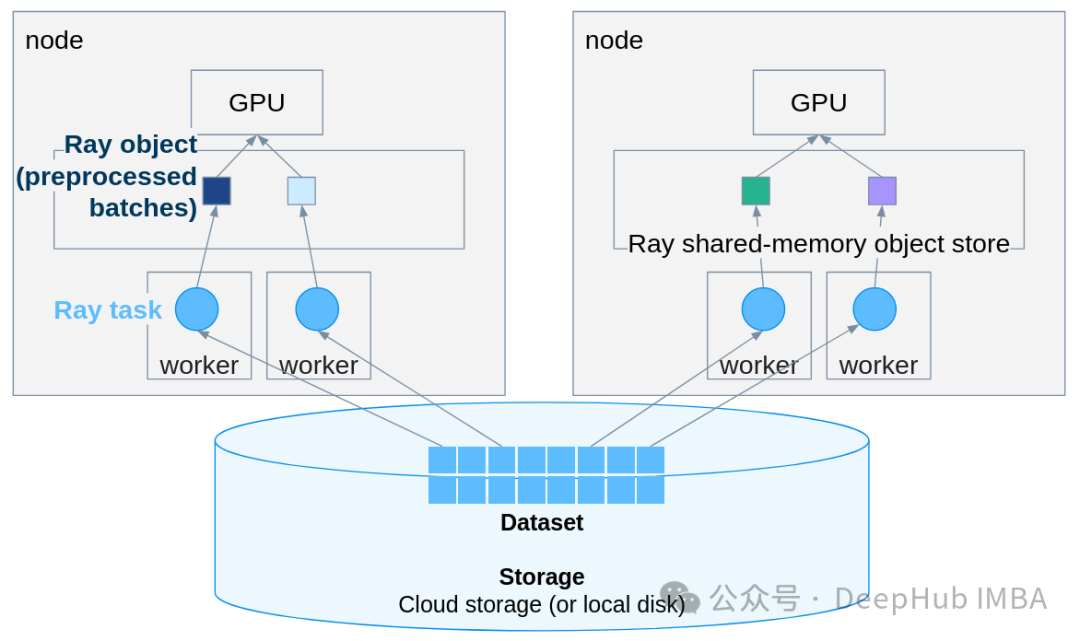
首先,内存无法容纳所有数据,无法一次性加载。其次,GPU利用率难以提升,在多卡场景下优化吞吐量尤为棘手。此外,还需要考虑任务容错、如何利用集群资源进行分布式部署。一个常被忽略但至关重要的问题是:数据加载的 I/O 操作往往才是整个流程的真正瓶颈。
若要从头构建一套健壮的、能处理上述所有问题的流水线,通常需要投入大量的开发与调试时间。
Ray Data 的解决思路
Ray Data 是一个与 PyTorch 配合良好的分布式数据处理框架,其最大优势在于改造代价极低,原有代码几乎无需大规模重写。
第一步:改造 Predictor 类
将 predict_batch 方法替换为 __call__,并将输入从 PIL Image 列表改为包含 numpy 数组的字典:
import numpy as np
from typing import Dict
class TorchPredictor:
def __init__(self, model: torchvision.models, weights: torchvision.models):
self.weights = weights
self.model = model(weights=weights)
self.model.eval()
self.transform = weights.transforms()
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.model.to(self.device)
def __call__(self, batch: Dict[str, np.ndarray]):
"""Ray Data 会传递一个包含numpy数组的字典批次。"""
# 将numpy数组转换回PIL图像
images = [Image.fromarray(img_array) for img_array in batch["image"]]
with torch.inference_mode():
tensor_batch = torch.stack([
self.transform(img.convert("RGB")) for img in images
]).to(self.device)
logits = self.model(tensor_batch)
probs = torch.nn.functional.softmax(logits, dim=1)
# 获取最高置信度的预测类别
top_probs, top_indices = torch.max(probs, dim=1)
return {
"predicted_class_idx": top_indices.cpu().numpy(),
"confidence": top_probs.cpu().numpy()
}
核心改动点包括:使用 __call__ 替代 predict_batch;输入类型变为 Dict[str, np.ndarray];在方法内部将 numpy 数组还原为 PIL Image;输出改为字典格式;需要将结果移回 CPU(Ray 负责进程间的数据传输)。选择 numpy 数组而非 PIL Image 对象,是因为前者在跨进程序列化时效率更高。
第二步:构建 Ray Dataset
根据数据源的不同,选择合适的创建方式:
- 小数据集(内存构建):
import ray
import numpy as np
ray.init()
# 将PIL图像转换为numpy数组
images = [
Image.open("/path/to/image1.png").convert("RGB"),
Image.open("/path/to/image2.png").convert("RGB")
]
# 从numpy数组创建Ray Dataset
ds = ray.data.from_items([{"image": np.array(img)} for img in images])
- 中等数据集(延迟加载文件路径):
# 从路径创建数据集
image_paths = ["/path/to/img1.png", "/path/to/img2.png"]
ds_paths = ray.data.from_items([{"path": path} for path in image_paths])
# 延迟加载图像
def load_image(batch):
images = [np.array(Image.open(path).convert("RGB")) for path in batch["path"]]
return {"image": images}
ds = ds_paths.map_batches(load_image, batch_size=10)
- 生产环境(推荐使用
read_images()):
Ray 会高效处理所有细节,这是最佳实践。
# 最高效的方式 - Ray 处理一切
ds = ray.data.read_images("/path/to/image/directory/")
# 或指定具体文件
ds = ray.data.read_images(["/path/img1.png", "/path/img2.png"])
第三步:执行分布式推理
核心调用代码如下:
weights = torchvision.models.ResNet152_Weights.DEFAULT
# 分布式批量推理
results_ds = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1,
compute=ray.data.ActorPoolStrategy(size=4) # 4个并行执行器
)
# 收集结果
results = results_ds.take_all()
# 处理结果
for result in results:
class_idx = result['predicted_class_idx']
confidence = result['confidence']
print(f"Predicted: {weights.meta['categories'][class_idx]} ({confidence:.2%})")
至此,分布式推理流程便已搭建完成。请注意,新版 Ray 中已废弃 concurrency 参数,需使用 compute=ActorPoolStrategy(size=N) 的写法。
通过上述改造,我们获得了以下优势:
- 自动分批:Ray 负责优化批次大小。
- 分布式执行:多个 Worker 并行处理数据。
- GPU 调度:自动将 GPU 资源分配给 Worker。
- 流式处理:数据在管道中流动,无需一次性全部加载到内存。
- 内置容错:Worker 失败后会自动重试。
面向生产环境的部署
Ray Data 能够直接读取云存储中的数据,无缝支持 S3、GCS、Azure Blob 等存储服务,非常适合云原生架构。
# 直接从S3、GCS或Azure Blob读取
ds = ray.data.read_images("s3://my-bucket/images/")
results = ds.map_batches(
predictor,
batch_size=64,
num_gpus=1,
compute=ray.data.ActorPoolStrategy(size=8) # 8个并行GPU Worker
)
在多节点集群上,代码无需任何更改即可运行,无论是10台还是100台机器。
# 连接到Ray集群
ray.init("ray://my-cluster-head:10001")
# 使用与之前相同的代码
ds = ray.data.read_images("s3://my-bucket/million-images/")
results = ds.map_batches(predictor, batch_size=64, num_gpus=1, compute=ActorPoolStrategy(size=16))
进阶优化技巧
- 使用 ActorPoolStrategy 保持模型常驻内存:避免为每个批次重复加载模型,显著提升吞吐量。
from ray.data import ActorPoolStrategy
results = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1,
compute=ActorPoolStrategy(size=4) # 保持4个执行器存活
)
- 精细控制资源:可以为每个执行器分配特定的 CPU 和 GPU 资源。
results = ds.map_batches(
TorchPredictor,
fn_constructor_args=(torchvision.models.resnet152, weights),
batch_size=32,
num_gpus=1, # 每个执行器使用1个GPU
num_cpus=4, # 每个GPU Worker分配4个CPU
compute=ActorPoolStrategy(size=8)
)
- 直接输出到云存储:推理完成后,可将结果直接写入云存储。
results.write_parquet("s3://my-bucket/predictions/")
常见问题与避坑指南
- 数据序列化问题:Ray Data 无法直接序列化 PIL Image 对象,必须转换为 numpy 数组。
# ❌ 这会失败
ds = ray.data.from_items([{"image": pil_image}])
# ✅ 这样可行
ds = ray.data.from_items([{"image": np.array(pil_image)}])
# ✅ 最佳实践:使用 read_images()
ds = ray.data.read_images("/path/to/images/")
- API 变更:Ray 2.51 版本后,
concurrency 参数已被弃用。
# ❌ 已弃用
ds.map_batches(predictor, concurrency=4)
# ✅ 正确方式
ds.map_batches(predictor, compute=ActorPoolStrategy(size=4))
- 批次大小设置:Batch size 过大会导致 GPU 内存溢出(OOM),建议从小开始尝试。
# 根据GPU内存监控情况调整batch_size
results = ds.map_batches(
predictor,
batch_size=16, # 从保守值开始
num_gpus=1
)
实践性能调优建议
- Batch Size 调优:从小批量开始逐步增加,观察 GPU 显存占用。例如,对于 ResNet152 单 GPU,32-64 可能是一个较好的范围。
- 评估启动开销:对于极少量的数据(如几十张图),Ray Data 的 Actor 启动和调度开销可能超过其带来的收益。此方案更适用于数据量成百上千的场景。
- 利用监控仪表盘:Ray 内置了 Dashboard,默认运行在 8265 端口,可用于监控任务执行和资源使用情况。
ray.init(dashboard_host="0.0.0.0")
- 增加错误处理:在预测函数外包裹 try-except,防止单个问题样本导致整个任务失败。
def safe_predictor(batch: dict):
try:
return predictor(batch)
except Exception as e:
return {"error": str(e), "probs": None}
- 进行性能剖析:在执行前后添加计时,便于进行性能分析和瓶颈定位。
import time
start = time.time()
results = ds.map_batches(predictor, batch_size=32)
results.take_all()
print(f"Processed in {time.time() - start:.2f} seconds")
总结
适用场景:
- 数据集过大,无法一次性装入内存。
- 需要利用多 GPU 或多台机器进行并行推理。
- 长时间运行的任务需要容错机制。
- 希望避免手动编写复杂的分布式代码。
非必要场景:
- 数据量极小(百张图片以内)。
- 数据集可轻松放入单机内存。
- 仅使用单卡且短期内无扩展计划。
Ray Data 的核心价值在于其极低的迁移成本。通过对 PyTorch 代码进行微小的适配(主要是修改方法签名并将数据包装为 Ray Dataset),即可获得从单卡到多机集群的无痛扩展、自动批处理和并行优化、内置容错以及云存储无缝集成等能力。
当你下次考虑手写多线程 DataLoader 或手动管理 GPU 资源池之前,不妨先评估一下 Ray Data 的方案。它将分布式系统中的复杂性交由框架处理,让你能更专注于模型本身的构建与优化。
 发表于 2025-12-10 00:24:41
|
查看: 247|
回复: 0
发表于 2025-12-10 00:24:41
|
查看: 247|
回复: 0
