导读:针对 B 站多模态数据处理场景下传统架构存在的烟囱式建设、存储介质分散、开发门槛高、容错能力弱等痛点,本文提出基于 Ray 与 Lance 构建的下一代多模态数据工程架构。该架构通过统一流批处理范式、优化 Checkpoint 机制、整合存储层能力,实现了多模态数据从预处理、训练到推理的端到端工程化管理。实践表明,新架构有效降低了业务开发门槛,提升了大规模多模态数据处理的效率与稳定性,为 B 站 AIGC 内容生态的多模态应用提供了坚实的技术底座。
主要内容包括以下几个部分:
- 多模态数据的工程概况
- 基于 Ray + Lance 的底层建设
- 提升训推数据链路的工程效率
- 总结与展望
01 多模态数据的工程概况
B 站作为以 AIGC 内容生态为核心的视频平台,内部存在大量多模态相关业务场景,涵盖社区运营、商业流量运营、多媒体数据处理及内部大模型训练等方向,各场景对应差异化的计算需求,且均以线上视频稿件为核心数据依托,支持实时、离线两种数据处理方式。但各业务场景分属不同业务部门,工程实现方式、计算与存储组件的选型存在显著差异,存储层面涵盖离线存储、向量检索存储、OSS 对象存储、Hadoop 等多种类型,整体架构呈现多样化、碎片化的特征。
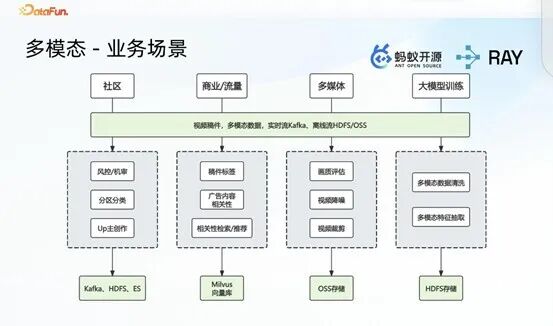
前期基于 Ray 技术落地了三大核心多模态数据处理场景,在工程实践中暴露了诸多亟待解决的问题,具体如下:
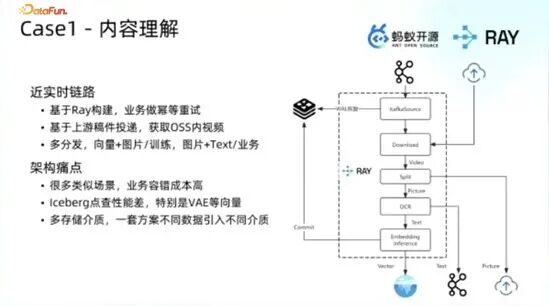
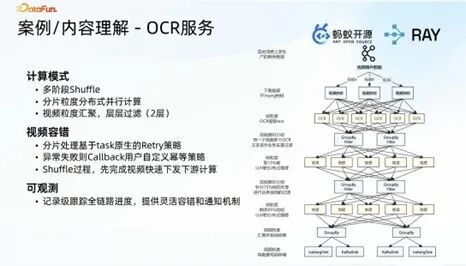
1. 内容理解实时链路场景
搭建了近实时的特征中台类架构,通过 Kafka 消费线上视频稿件,经多阶段算子处理后将结果写入向量存储或对象存储,或通过消息机制通知业务端,由业务端完成幂等重试与结果提交。
该架构存在三方面痛点:业务场景数量多,各业务单独基于该架构开发的技术门槛与工程成本较高,且容错成本居高不下;将向量数据存储于 Iceberg 中,面对大向量(单字段几十兆甚至上百兆)的千万级数据点查场景,性能与效率均未达到工程预期;多存储介质并存,业务端需自主判断存储选型,最终导致存储类型发散,数量达五六种及以上。
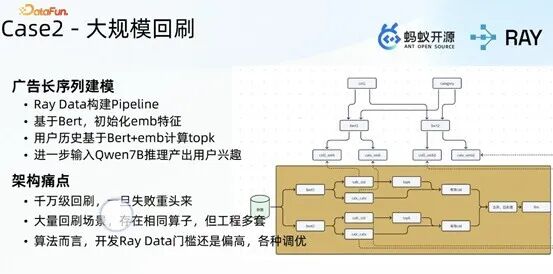
2. 大规模离线回刷场景
基于 Ray 为业务端提供用户两年流量数据回刷的解决方案,支持业务端通过 Ray Data 构建数据处理 pipeline,结合 BAR 完成特征提取、千万模型实现推理,满足长序列兴趣建模中 ESU 阶段的业务需求。
该方案的核心痛点为:千万级规模数据回刷任务一旦失败需从头执行;多回刷场景中存在大量相同算子,造成严重的工程冗余;Ray Data 开发门槛较高,长周期(两三周)的回刷任务失败后,对业务端的影响较大。
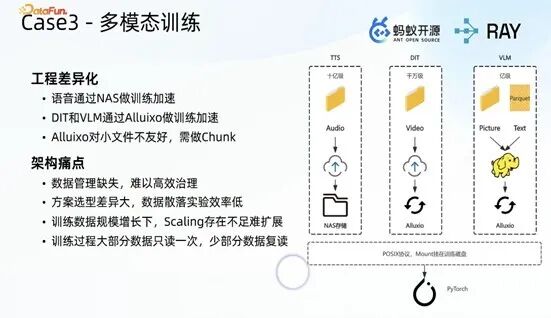
3. 多模态大模型训练场景
业务覆盖语音、DIT 视频生成、无人语等多个方向,各场景的数据量级、工程实现方式差异显著,且小文件问题突出。如语音场景存在 10 亿级小文件,经 OSS 尝试后最终采用基于 NARS 的解决方案;视频生成场景为千万级切片文件,可在 OSS 中勉强运行;VM 场景则通过 Hadoop+OSS 的组合方式实现。
该场景的工程问题主要包括:数据管理体系缺失,对象存储空间持续增长,文件的用途与血缘无明确追溯路径,缺乏有效的数据治理措施;技术方案选型差异大、数据散落分布,导致算法实验效率低下;训练数据规模呈持续增长趋势,现有技术方案的可扩展性不足,未来或无法支撑业务发展;大模型训练以数据只读一次为主要特征,仅少量数据存在精读多次的需求,现有方案的成本投入与架构合理性并非最优。
通过对三大场景工程问题的抽象总结,B 站多模态数据工程早期架构存在三大核心症结:其一,架构呈现烟囱式特征,大模型应用从数据处理、模型微调至推理落地的全流程,无统一的工程范式与使用标准;其二,数据计算环节存在大量冗余,切片、场景检测、抽帧等基础算法在多业务线重复开发与使用,且多存储介质并存,数据从治理、血缘、权限管理到热度分层均无法实现统一管控;其三,技术开发门槛较高,开发人员实现大规模数据处理流程需掌握大量 Ray Data 配置知识;最后,架构缺乏容错恢复机制,多模态训练的数供环节与训练环节存在效率断层。
02 基于 Ray + Lance 的底层建设
针对 B 站多模态数据工程早期架构的核心问题,在原有 Ray 技术体系的基础上引入 Lance 存储技术,通过底层技术能力升级解决工程痛点,同时围绕 Ray Data 做深度扩展与优化,打造适配 B 站多模态业务场景的底层技术架构。
1. Lance 核心特性与架构融入
Lance 作为高性能存储技术,具备四大核心特性,与 B 站多模态数据的存储需求高度适配:一是支持更高性能的点查操作,有效解决原有 Iceberg 技术在大向量点查场景中效率低下的问题;二是废弃传统 log group 实现方式,支持超宽列存储,可承载几十兆、几百兆的大列数据,适配多模态大向量数据的存储需求;三是支持灵活的 schema 扩展,可在数据表中随时新增列,满足算法人员特征加列的高频业务诉求;四是支持灵活的编码方式与丰富的索引能力,便于开发人员对多模态数据表进行高效查询操作。
基于上述特性,将 Lance 融入多模态数据工程整体架构,作为核心存储组件,与 Ray 计算框架形成高效协同配合。
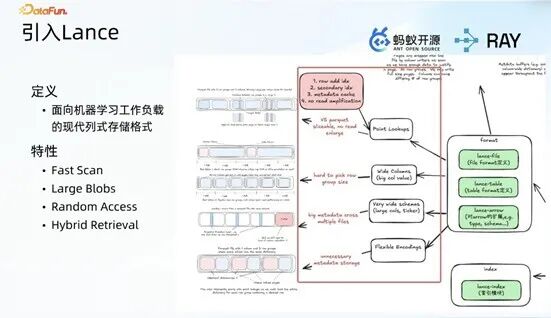
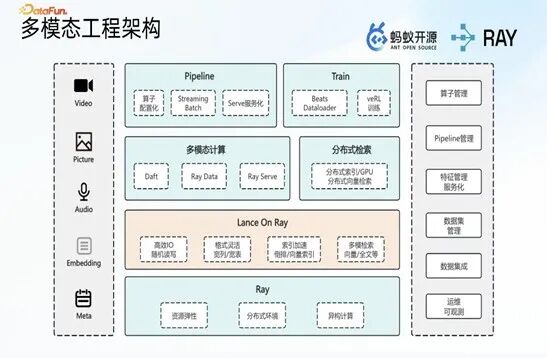
2. Ray + Lance 整体架构设计
Ray+Lance 底层架构以数据为核心本体,左侧对接全量业务数据来源,底层依托 Ray 框架的弹性伸缩、分布式计算、异构资源调度能力,上层通过 Lance on Ray 的技术实现方式,提供高效的 IO 读写、灵活的数据格式支持、多维度索引及检索能力;面向用户层,架构提供多模态计算、分布式检索核心能力,并打造两大核心工程组件——解决算子配置化问题的 Pipeline 工程,支持流、批、Server 三种运行模式,以及专门对接训练场景的 Beats Dataloader 组件,通过组件化设计大幅降低用户的技术接入门槛。
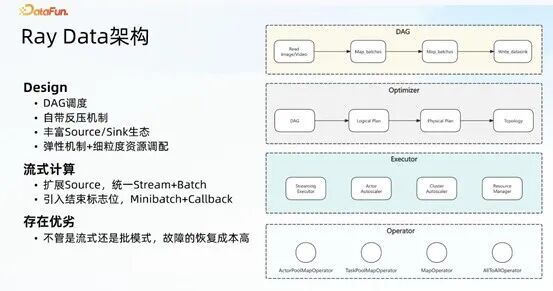
3. Ray Data 核心能力扩展:Checkpoint 机制优化
Ray Data 是架构底层计算的核心载体,围绕容错恢复、处理效率、可观测性三大核心目标,对 Checkpoint 机制进行全面扩展与优化,从基础的同步 Checkpoint,逐步扩展至并行 Checkpoint 与记录级 Checkpoint,并将三类能力统一封装为 Identity Checkpoint 能力,让用户无需关注底层实现细节,即可实现高效的容错恢复。
(1)基础同步 Checkpoint:参考 Flink 的 Trending LAMPPA 算法设计实现,核心理念是让用户通过简单的配置操作(enable trip on)即可开启 Checkpoint 功能,无需手动定义唯一 ID。在数据下发过程中,系统定期插入虚拟的 Barrier,Barrier 随数据流转至各处理层,在 Write 阶段结束后完成 Barrier 收集,标志着一次 Checkpoint 流程完成;结合 Lance 与 Iceberg 的两阶段提交能力,实现全链路的 exactly-once 语义。同时,为流转数据标记唯一 Checkpoint ID,Checkpoint ID 随数据流转完成 DAG 状态汇总,并将状态持久化至 STS 或对象存储中,任务恢复时可从断点继续运行,大幅降低用户的使用成本。该能力可同时适配流、批两种业务场景,如线上视频素材中台的流式处理链路,用户开启 Checkpoint 并指定执行周期后,即可实现包含二三十个处理阶段的复杂流式处理的断点恢复。
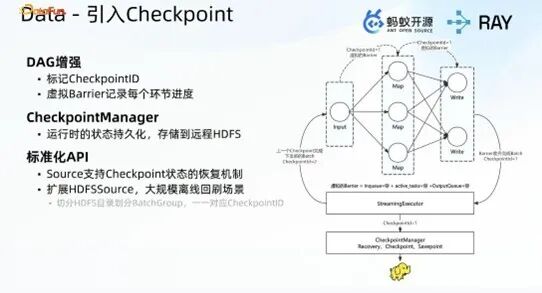
(2)同步 Checkpoint 的工程痛点:在实际工程落地后发现,同步 Checkpoint 存在明显的性能与功能短板:一次仅能下发一个 Checkpoint 任务,当处理链路过长或存在数据处理长尾问题时,Checkpoint 执行效率大幅降低;无法满足 shuffle 场景的业务需求;不支持记录级的容错处理,如视频数据处理完成 95% 后,无法实现断点继续推进;缺乏细粒度的可观测性,无法追踪单条视频数据的处理进度。

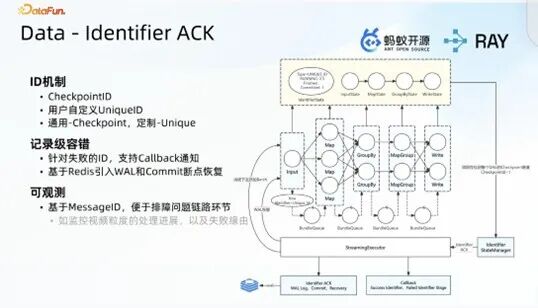
(3)并行 Checkpoint + 记录级 Checkpoint:为解决同步 Checkpoint 的痛点,扩展实现两种核心能力:并行 Checkpoint 支持在当前 Checkpoint 任务未完成时,持续下发新的 Checkpoint 任务,多 Checkpoint 任务并行处理,有效提升整体处理效率;记录级 Checkpoint 参考消息粒度的 Bo ID 机制,让用户指定输入数据的唯一 ID 字段,在 Ray Data 底层扩展系统字段,将唯一 ID 随数据流转至各处理环节,通过状态管理模块收集 DAG 各节点的 ID 状态,绘制全量状态视图,最终对已完成处理的 ID 做 Checkpoint 并完成持久化。该能力不仅实现了记录级的容错处理,还能实时追踪每个 ID 的处理进度,满足业务端对细粒度可观测性的需求。
(4)落地场景验证:在视频抽帧→OCR 推理→数据聚合→数据过滤→多轮推理的流式处理链路中,基于上述优化后的 Checkpoint 机制,实现了更高的故障恢复能力与数据处理效率,为线上视频数据的端到端处理提供了稳定的技术支撑。
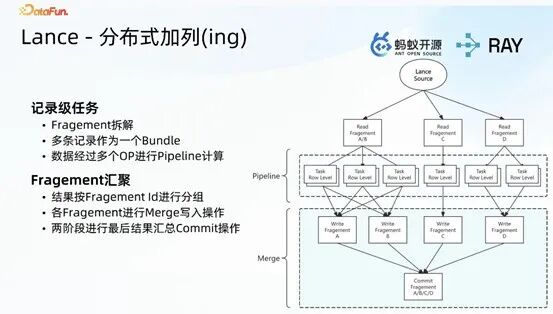
4. Lance 核心能力落地:列更新与列新增
依托 Ray Data 的分布式计算能力,基于 Lance 实现多模态数据表的列更新与列新增能力,满足算法人员特征迭代的高频业务诉求,且全程与 Checkpoint 机制绑定,保障数据处理过程中的一致性。
- 列更新:通过 Ray Data 构建前置数据处理 pipeline,经多阶段计算产出需更新的列数据,通过 Lance 的 link 方式完成列聚合,再调用 Lance 原生接口将数据写入 Lance 文件,最后通过 Lance commit 操作将元数据提交至 Catalog,完成列更新流程;该过程依赖唯一 ID 实现,确保列数据更新的准确性。
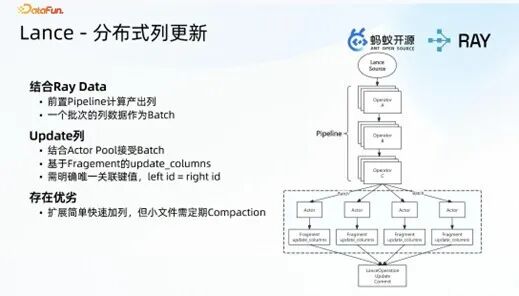
- 列新增:无需依赖唯一 ID,核心是在原有数据表的行基础上实现列的新增。通过 Lance source 按 fragment 粒度读取原有数据,对 fragment 内的行数据执行行级推理(如抽帧、多阶段模型推理等),产出新增列数据,将新增列数据聚合至同一 fragment,最后通过 commit 操作完成写入,实现列的高效新增。
03 提升训推数据链路的工程效率
在完成 Ray+Lance 底层技术建设的基础上,将核心能力封装为标准化的工程组件,面向业务端提供统一的技术接口与配置化能力,实现训推数据链路的端到端工程效率提升,让算法人员从繁琐的工程实现中解放,聚焦算法模型的研发与优化。
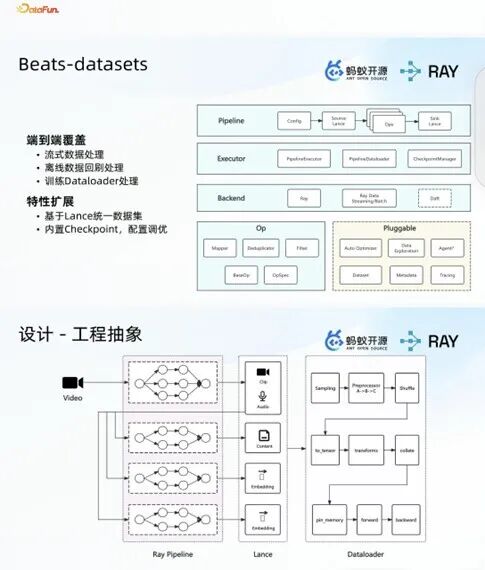
1. 标准化 Pipeline 架构设计
为业务端设计并实现一套标准化的 Pipeline 架构,架构底层封装了丰富的算子能力与插件化的 Packing 能力,上层依托 Ray+Ray Data 的流/批双模式,通过执行器构成完整的 Pipeline 处理链路。业务端在开发过程中仅需完成简单的配置化操作,即可快速构建专属数据处理流程,同时可直接开启 Checkpoint 功能,满足大规模数据回刷、流式数据处理等多场景的业务需求,大幅降低业务端的技术开发门槛。

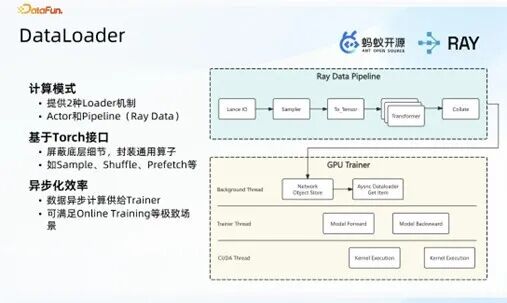
2. 数据处理与训练的端到端链路打通
实现数据处理与模型训练链路的接口统一,让算法人员从数据预处理到模型训练的全流程,均可通过同一套技术接口完成操作,实现端到端的工程化技术支撑。
-
数据处理环节:将线上音视频数据通过 Ray Pipeline 写入 Lance 表,生成切片、音频等基础数据;算法人员可根据业务需求构建新的 Pipeline,读取 Lance 表中的基础数据完成推理、特征提取等操作,并将处理结果作为新列追加至 Lance 表;不同算法人员可基于同一 Lance 表并行开展算法实验,各自产生的特征列均能作为数据表的一部分实现统一管理,有效实现数据的复用与统一治理。
-
模型训练环节:基于标准化 Pipeline 架构构建训练专属的 Data Loader,支持配置化操作,涵盖 sample、数据预处理、shuffle、to tensor transfer 等全流程处理步骤,最终将处理完成的标准化数据送入模型的 forward 与 backward 训练环节。同时,将 Data Loader 的所有数据处理操作转化为 Ray Data 的 map batch,模型训练环节可直接获取最终处理好的标准化数据,无需额外执行数据处理操作。
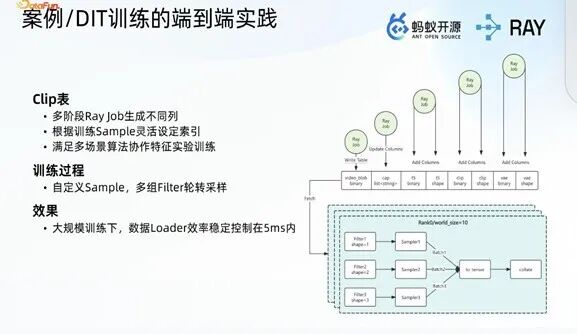
3. 落地效果验证:多模态训练案例
以 B 站某多模态训练场景为实际案例,基于 Lance 表实现多模态数据的统一存储,不同业务场景的特征数据以不同列的形式写入同一 Lance 表;用户通过架构提供的框架拉起 Data Loader,配置三种不同的过滤器实现不同场景的数据配比,经 sample 操作后完成 batch 迭代,为模型训练过程提供稳定的数据供给。工程落地后,对比原有 Data Loader 实现方式,数据处理延迟被严格控制在毫秒级,大幅提升了模型训练的数供效率。
4. 训推链路的统一适配
标准化 Pipeline 与 Data Loader 核心能力,不仅适配模型训练场景,还可无缝适用于推理场景,实现训推数据链路的工程能力统一,让多模态数据在模型训练、在线推理的全流程中,均能得到高效、统一的处理与管理,消除训推链路之间的技术壁垒。
04 总结与展望
1. 核心总结
本文围绕 B 站下一代多模态数据工程架构的落地实践展开全面研究,核心通过 Ray+Lance 的技术组合,针对性解决了早期架构的烟囱式设计、工程冗余、开发门槛高、存储效率低等核心问题,实现了多模态数据工程底层能力的全面升级与工程效率的显著提升,主要研究成果如下:
- 引入 Lance 作为架构核心存储组件,有效解决了大向量点查效率低、超宽列存储难、schema 扩展不灵活等问题,与 Ray 计算框架形成高效协同,打造了统一的多模态数据存储底座;
- 对 Ray Data 做深度技术扩展,优化并实现了同步、并行、记录级三级 Checkpoint 机制,解决了容错恢复能力弱、数据处理效率低、细粒度可观测性缺失等问题,大幅降低了用户的技术使用成本;
- 基于 Ray+Lance 技术体系构建了标准化的 Pipeline 与 Data Loader 组件,实现了算子配置化、接口统一化,成功打通了从数据处理到模型训推的端到端链路,大幅降低了业务端的开发门槛,提升了多模态数据处理的整体工程效率;
- 实现了多模态数据的统一管理,有效解决了数据散落、血缘缺失、治理困难等问题,为 B 站 AIGC 内容生态下的各类多模态业务场景,提供了稳定、高效的 AI infra 计算底座。
2. 未来展望
后续将继续围绕 Ray+Lance 技术栈,对 B 站多模态数据工程架构进行持续的能力增强与优化:一方面,持续打磨底层计算与存储能力,丰富算子库与插件化生态,进一步降低用户的技术接入与开发门槛;另一方面,针对多模态数据规模的持续增长与业务场景的不断拓展,持续优化架构的可扩展性、性能表现与成本合理性,让 Ray+Lance 的技术组合更好地支撑 B 站 AIGC 业务的发展。未来将继续深化技术与业务的融合,打造更适配视频平台多模态业务场景的下一代数据工程架构,为 B 站 AIGC 内容生态的建设提供更坚实的技术支撑。

以上是本次分享的全部内容,希望对大家构建或优化自己的多模态数据处理平台有所启发。更多前沿技术实践和深度解析,欢迎访问云栈社区进行交流探讨。
 发表于 2026-3-1 07:29:55
|
查看: 229|
回复: 0
发表于 2026-3-1 07:29:55
|
查看: 229|
回复: 0
