在完全不改动模型架构和推理逻辑的情况下,仅仅在预训练前半程对 token 表示和预测目标进行重组,就能让 10B-A1B 的 MoE 模型在同等损失下实现最高 2.5 倍的训练加速。
标准大语言模型(LLM)的预训练中,每个 step 通常只处理固定长度的一段 token 序列。想在相同算力下让模型接触更多文本,常见的做法包括换用更高效的分词器、修改注意力结构、引入 MoE 架构,或者额外加入多 token 预测头。但这些方法很难避免改变最终模型本身——训练效率和推理结构被捆绑在一起,后续很难分清收益究竟是来自训练吞吐提升、架构变化,还是额外的预测目标。
那么,有没有可能一行模型架构代码都不改,只在训练阶段就把预训练吞吐提上去?Nous Research 近期提出的 Token Superposition Training(TST)正是沿着这个思路设计的。它不改动任何模型架构、并行策略、优化器、分词器和训练数据,只在预训练的前半程将连续 token 的 embedding 临时平均为一个新表示,并让模型预测下一组 token;到了预设的训练比例后,再切回标准的逐 token 预测。
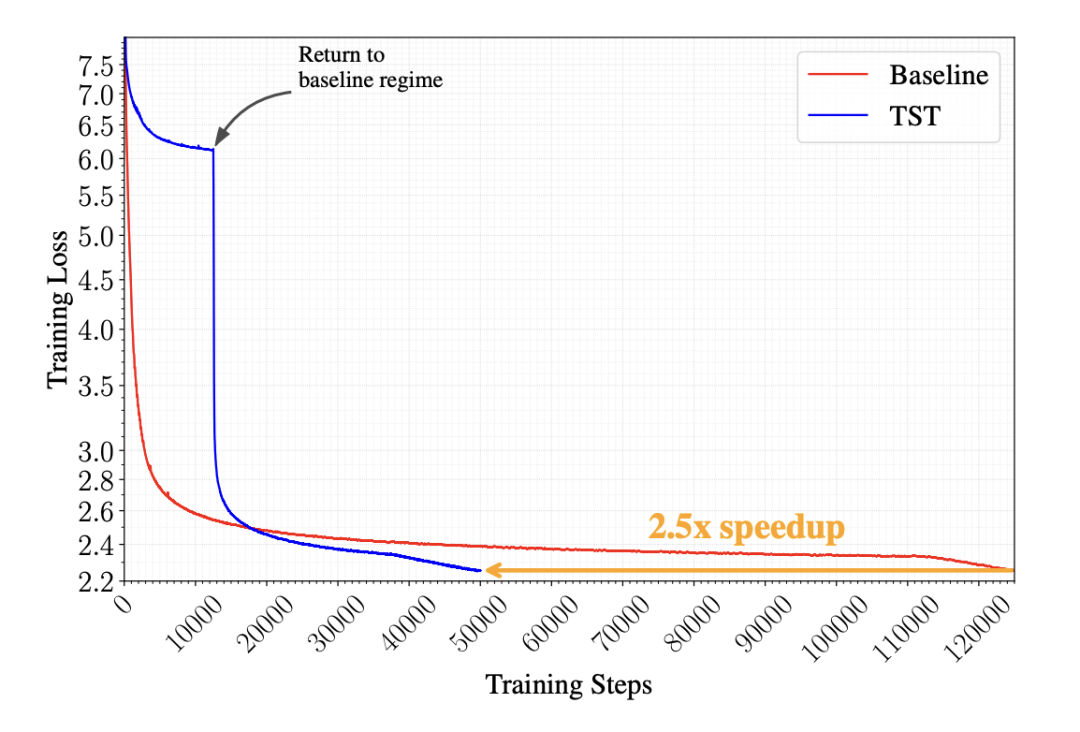
〓 10B MoE 模型在叠加阶段切换至恢复阶段后的 loss 表现
训练完成后,模型仍然是标准自回归结构,推理方式不变,也不需要任何额外模块。换句话说,你最后得到的,就是一个和基线结构完全相同的模型。

论文标题:Efficient Pre-Training with Token Superposition
论文链接:https://arxiv.org/abs/2605.06546
纯拼吞吐量:TST 的极简训练流
TST 很容易和多 token 预测(MTP)、SuperBPE 放在一起比较,但它们改的不是同一个地方。从宏观架构看,MTP 通过增加预测头来提供更密的局部监督,并不会提高每单位 FLOPs 处理的 token 数,还会引入额外参数。TST 的思路则完全聚焦在训练吞吐量上。
整个训练过程分为叠加阶段(Superposition Phase) 与恢复阶段(Recovery Phase)。叠加阶段里,模型以一组连续 token 的叠加表示作为输入,并预测下一组 token;达到预设步数比例后,再切回标准逐 token 预测。这个切换并不完全平滑——loss 会短暂上升,随后进入恢复阶段,并在更低的位置收敛。
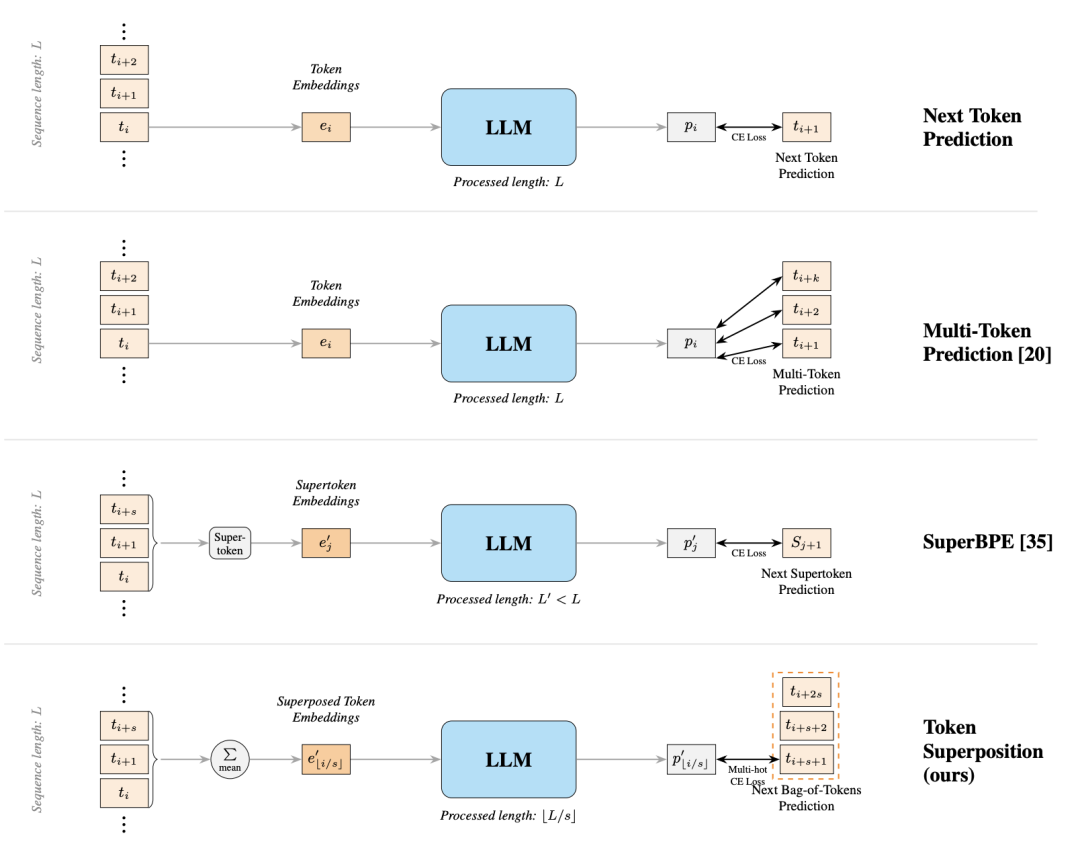
〓 TST 与标准下一 Token 预测、多 Token 预测及 SuperBPE 的架构对比
输入端:物理层面的张量折叠
在叠加阶段的输入端,长度为 L 的连续序列会被切成若干个不重叠的 token bag,每个 bag 包含 s 个 token。在 embedding 层,这 s 个 token 的向量表示会被取平均,形成一个新的 latent s-token 表示。

〓 通过 reshape 将序列切成 token bag,再用 mean 得到叠加后的 token 表示
经过这一步,模型实际处理的 latent 序列长度变为原来的 1/s。为了保持与 baseline 相同的每步 FLOPs,TST 会把原始输入长度扩大 s 倍。这样,在同样的每步计算量下,模型就能接触到更大量的原始 token。
输出端:预测下一组 Token
输出端也同步调整:模型不再预测单个 next token,而是预测下一组 token。为了让一个预测位置同时对应 s 个有效 label,作者把标准的交叉熵损失(CE)换成了多热交叉熵损失(Multi-hot CE, MCE)。MCE 的本质是把目标概率均分给 bag 内的 s 个正样本。其完整数学展开式如下:
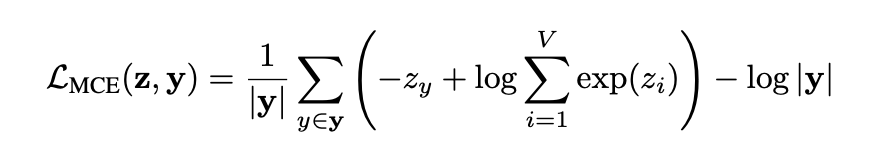
其中 |y| 即 bag 大小 s,由于 -log|y| 为常数项,不影响梯度,训练时可以直接去掉。去掉常数项后,MCE 就可以写成 bag 内多个标准 CE 的平均值:
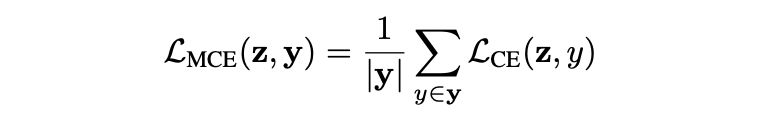
这个简化形式极大降低了技术迁移成本。实际实现时,可以直接复用现有预训练库中的融合 CE kernel,对 bag 内每个 label 分别计算 CE 后求平均,完全不需要额外编写 CUDA kernel。

〓 简化后的 MCE 可以直接复用标准 CE 实现
2.5 倍提速怎么来的?
研究团队在 TorchTitan 框架下结合 FSDP 并行策略,对 TST 进行了多尺度验证,覆盖了 270M、600M、3B 稠密模型以及 10B 混合专家模型。下表汇总了各模型的关键指标:
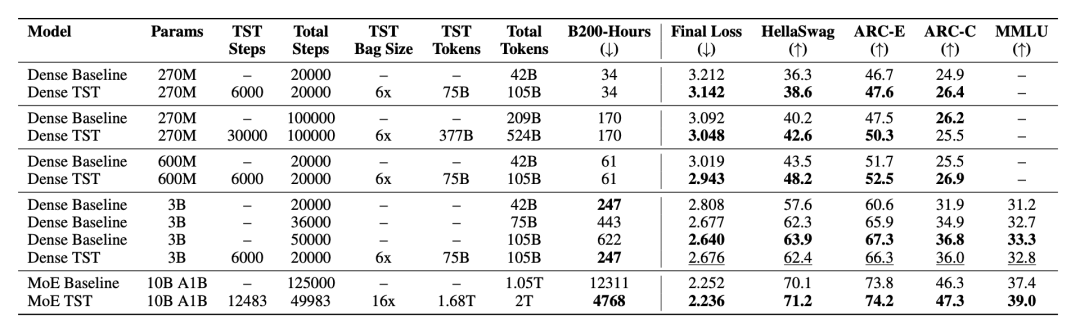
〓 TST 在各模型规模下的预训练表现及下游评测全景数据
以 3B 稠密模型为例,实验从三个维度做了对比:
- 同等计算量下,TST 的最终训练损失更低;
- 同等损失下,TST 需要的训练时间更短;
- 同等数据量下,TST 每个原始 token 获得的计算更少,表现反而略弱于 baseline。
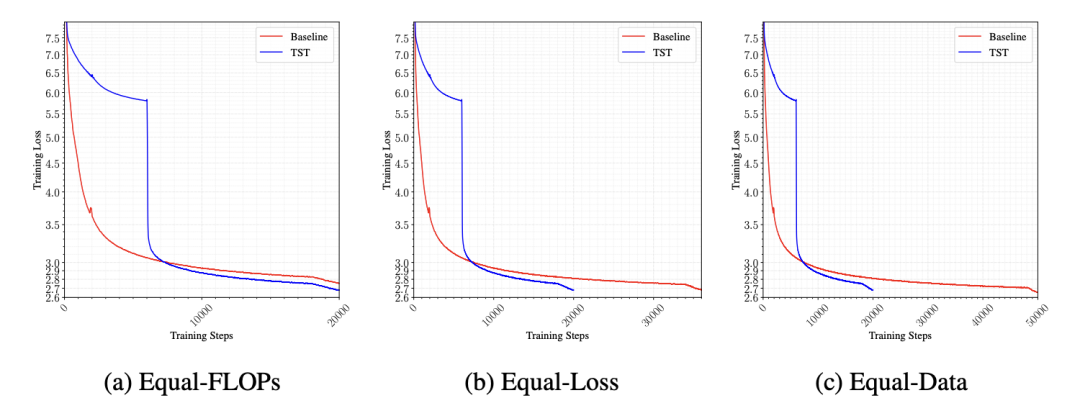
〓 3B 稠密模型在同等算力、同等 loss 及同等数据量三种约束条件下的训练 loss 曲线
超参数方面,切换步数比例 r 在 0.2~0.4 之间表现相对稳定;而叠加包大小 s 则呈现明显的 U 型趋势,且最优区间随着模型参数量增大而右移。
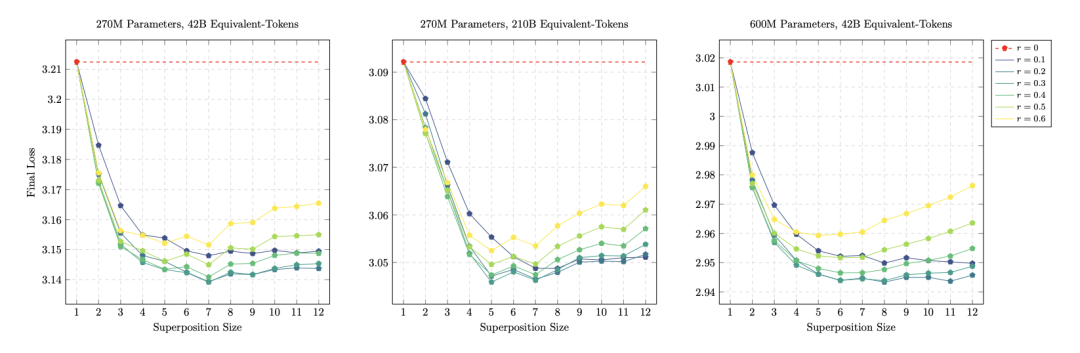
〓 在 270M 与 600M 规模下,最终 loss 随包大小 s 呈现 U 型曲线,且最优区间随模型增大而右移
在 10B-A1B 的大规模验证中,作者采用了 s=16,最终 loss 从 baseline 的 2.252 降到 2.236。作者也尝试过用 BCE、hinge loss 等替代 MCE,效果均明显弱于默认方案;即使是一些试图补回 bag 内位置信息的设计,也未能带来稳定收益。这些结果至少说明:强行恢复 bag 内的顺序信息,并不是 TST 取得收益的关键。
另外,在较大的 bag size 下,均匀加权未必总是最优。作者对 DCLM 数据集做了分析,发现自然语言中 token 间的互信息随距离呈幂律衰减。
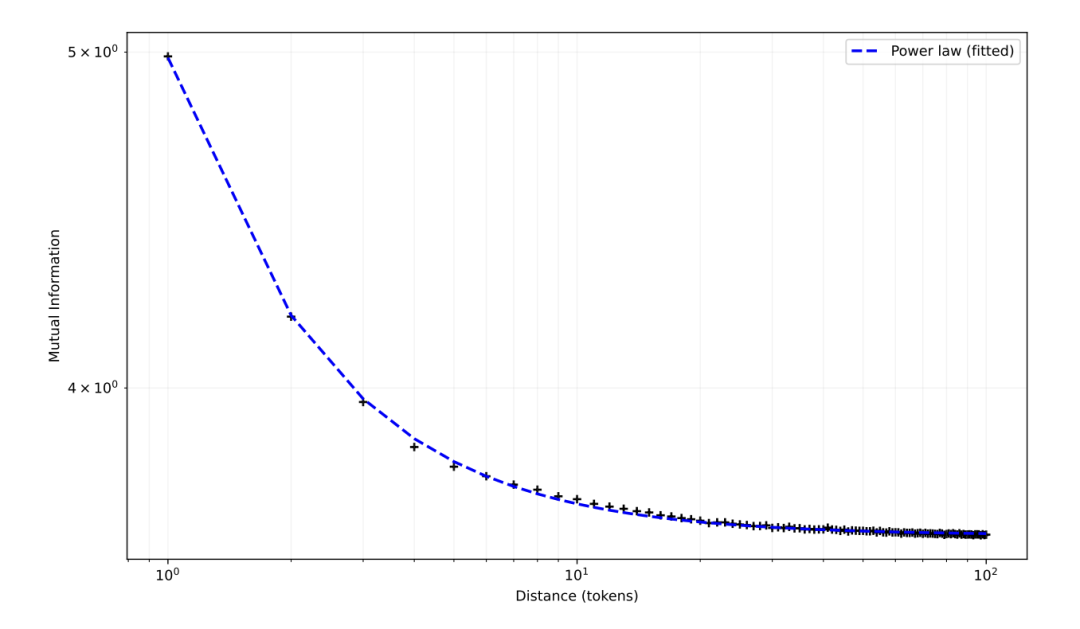
〓 DCLM 数据集中 token 间互信息随距离呈现幂律衰减
基于这一发现,引入随距离衰减的非均匀加权 MCE(Weighted MCE),能在大 bag size 场景下获得更低的最终损失。
底层表示绝对共享
消融实验进一步拆解了输入叠加与输出叠加的独立贡献。结果表明,单独应用输入叠加(压缩序列长度)或输出叠加(改造梯度信号)均能带来超越基线的增益;而两者的结合并未产生干扰,说明这两种机制在底层是完全正交的。
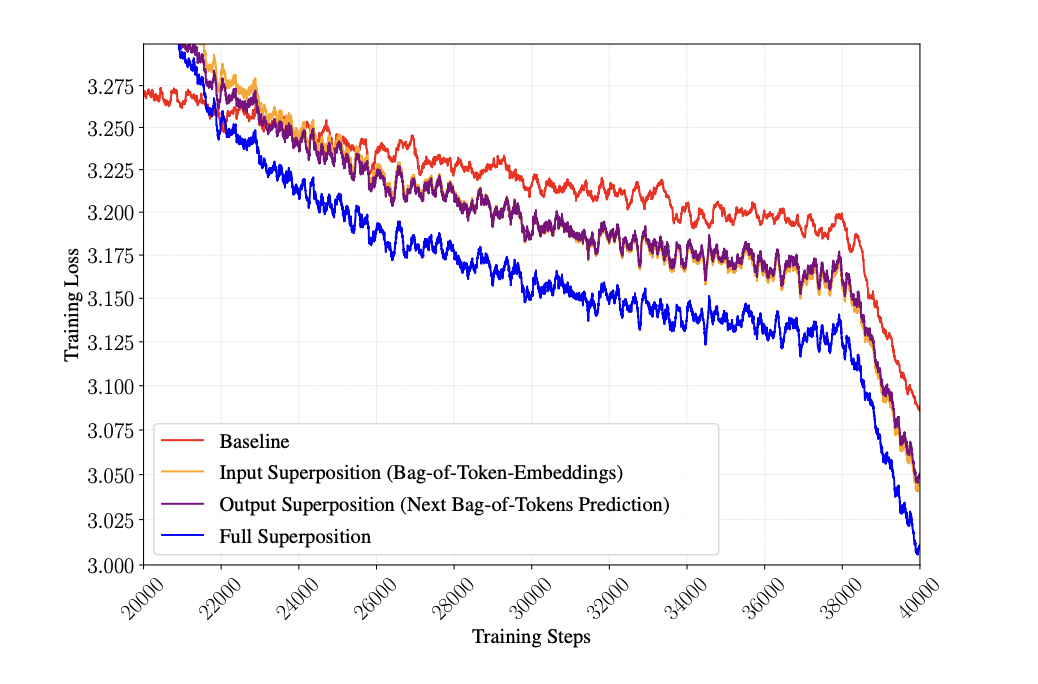
〓 输入叠加与输出叠加机制各自独立生效,结合使用能取得最大综合收益
很多多阶段训练方法在切换目标时,会引入 adapter 或额外的 alignment phase 来缓解表示不匹配。而 TST 不引入任何额外模块,关键就在于它在两个阶段中保持了完全相同的底层表示。如果在恢复阶段开始时随机重新初始化模型的输入 embedding 层和输出 LM Head,TST 前期积累的所有优化红利将彻底清零,最终的损失值甚至会高于从零开始训练的 baseline。

〓 在恢复阶段重置输入输出表示层会导致 TST 前期积累的收益完全消失,证明了表示对齐的必要性
这清楚地表明,跨阶段保持输入输出表示对齐,很可能是 TST 收益能够延续到标准训练阶段的重要条件。
结语
TST 的本质,是用更多的数据消耗,换取同等计算下的更低训练损失。在算力资源紧张而数据依然充足的预训练场景下,这类低侵入式的训练加速方法极具吸引力。由于叠加阶段会将 s 个 token 折叠为一个 latent 位置,模型在相同 latent 序列长度下对应的原始文本跨度更长,这可能潜在地减少长文档在训练中被截断或切分的情况。不过论文并未评测最终的长上下文能力,这一方向目前只能视为一个待验证的后续问题,而非已有结论。
本文编译自 Nous Research 的研究成果,若对高效训练方法感兴趣,欢迎访问云栈社区参与讨论。
 发表于 2026-5-15 03:13:13
|
查看: 166|
回复: 0
发表于 2026-5-15 03:13:13
|
查看: 166|
回复: 0
