关键词:P2P 权重传输、RDMA、零拷贝、CPU 引擎副本、分布式强化学习
我们为 SGLang 中的强化学习工作负载引入了一种基于 RDMA 的点对点权重更新机制,作为传统 NCCL 广播方法的补充,兼容所有主流开源模型。
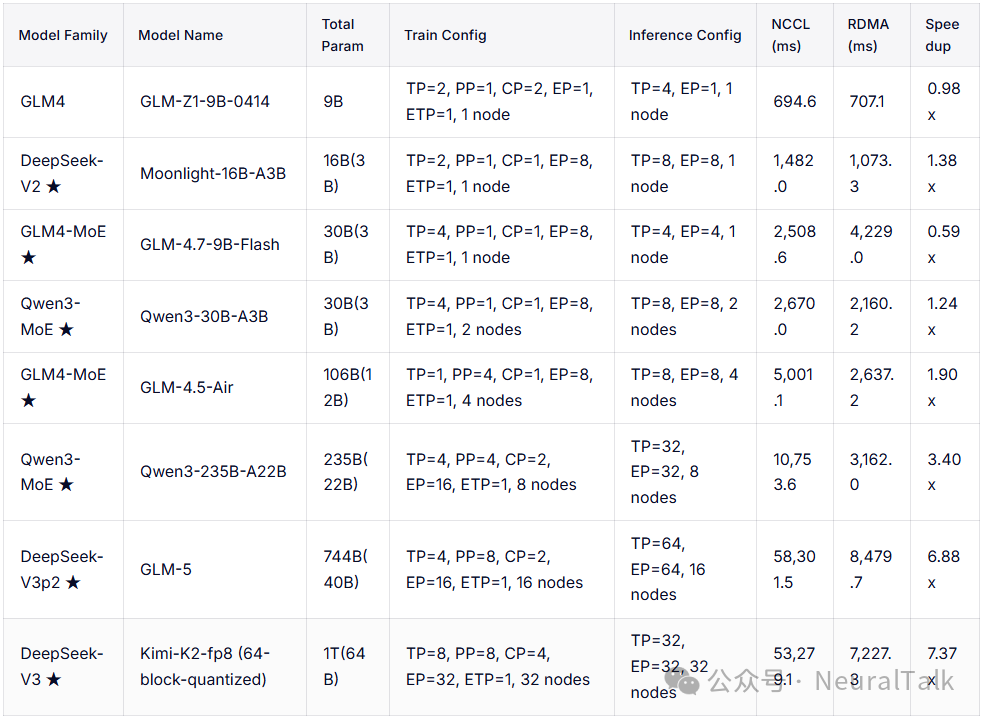
表格对比了不同大模型在NCCL与RDMA两种权重传输方案下的性能。从9B到1T参数量的模型测试显示,随着模型规模增大,RDMA的优势愈发显著:小模型(如GLM4-9B)加速比仅0.98x,而744B和1T模型的加速比分别达6.88x、7.37x,耗时从数万ms骤降至数千ms。这说明RDMA在大规模、多节点场景下,相比NCCL的传输效率提升巨大,更适配大模型权重迁移需求。
这些优化最小化了网络冗余,并让推理服务器能显著更快地恢复 rollout。
本文目录
- 关键问题
- 问题一、内存换带宽的扩展性陷阱:CPU Engine Replica 是否会成为新的多租户瓶颈?
- 问题二、多对一张量映射的“碎片缓存”风险:零拷贝管线是否被静默阻塞?
- 零、研究背景
- 一、现有 NCCL 广播面临的挑战
- 二、设计
- 三、实现结果
- 四、使用方法
- 五、未来规划
- 六、工程附录
- 6.1 设计迭代
- 6.2 点对点传输计划
- 6.3 识别需要传输的 SGLang 张量
- 6.4 带共享副本的传输流程
- 6.5 其他量化及后处理方法
关键问题
问题一、内存换带宽的扩展性陷阱:CPU Engine Replica 是否会成为新的多租户瓶颈?
本文核心思路是用源端每个训练 rank 额外分配一个完整的 CPU 端推理引擎副本来消除 NCCL 广播的冗余传输。以 1T 参数 Kimi-K2 为例,这笔额外开销是每个 rank 32GB CPU 内存,且在 32 个训练节点上同时存在。本文并未讨论当训练配置中流水线并行度更高、或需要同时服务多个异构推理实例时,每个训练 rank 需要维护的副本身份是否会被迫线性叠加(例如每个 pp rank 要为多个 ep 副本分别维护权重视图)。当模型规模向 10T+ 演化时,源节点 CPU 内存是否会先于网络带宽成为系统崩溃点?这种“以空间换时间”的策略是否从根本上限制了该方案对超大规模 MoE 模型的可扩展性?**
不会在现有设计中因多租户而爆炸,但会随模型规模线性触及绝对容量天花板。
设计上,源端每个训练 rank 只在 CPU 上维护一个推理引擎副本(1T Kimi-K2 为 32GB),并通过同构复用该副本向多个目标推理 rank 发送权重。作者明确指出“所有 SGLang rank 都是同构的”,因此避免了按目标数量叠加副本的 O(M×N) 灾难,且设计初期因 GPU 副本爆炸导致的 OOM 已在迁移到 CPU 时被修复。
然而,副本容量随模型参数量线性增长。当模型扩展至 10T+ 并使用更高精度时,单节点有限的 CPU 内存(远小于 GPU 显存)将先于网络带宽成为瓶颈。 作者未提出任何压缩副本大小的方案,“Future Plans”仅讨论加速内存注册的 Huge Page 技术,未触及内存天花板本身。因此,这一“以空间换时间”的策略在绝对内存容量上存在结构性限制,超大规模下 CPU 内存是硬崩溃点。
问题二、多对一张量映射的“碎片缓存”风险:零拷贝管线是否被静默阻塞?
本文提到 HF 张量到 SGLang 张量存在多对一映射(如 q_proj/k_proj/v_proj → qkv_proj),必须等待所有分片收集完毕才能触发 RDMA 传输,且期间需要在 CPU 副本中额外缓存碎片(导致所需缓冲区 K* 大于理论值 K)。本文虽声称“实际额外缓冲区较小”,但在以下极端情况中——当张量分片分布在多次 bucketed update 中、且各 shard 到达顺序高度离散时,这种“缓存等待”会否产生隐藏的尾部延迟,甚至在大 EP/TP 配置下导致缓存溢出,迫使训练侧强制进行二次全收集?这种依赖于“命名参数局部有序”的经验性假设是否会在模型结构演变或自定义量化方案中失效,从而打破目前宣称的零冗余、零拷贝流水线?
在当前模型和命名约定下风险被刻意压制,但依赖的经验性假设若失效,将出现尾部阻塞甚至缓存溢出。
由于 HF 张量到 SGLang 张量存在多对一映射(如 q_proj、k_proj、v_proj → qkv_proj),必须等待所有分片到齐才能触发 RDMA 发送,故需额外缓冲区 K。最坏情况下缓冲区可达分片数的倍数,但作者强调“named_parameters 通常将相关张量排列在一起,实际额外缓冲区很小”,因此管线被长程离散碎片阻塞的概率较低*。设计上将首个目标 rank 的发送放在关键路径强制等待,最后一个目标的发送卸入线程池异步完成,进一步掩盖了碎片等待的尾部延迟。
风险在于这一假设不具硬性保证。 当模型结构演变、量化方案改变或分片命名顺序不再局部有序时,碎片收集会跨越多个 bucketed update,导致关键路径被长时间挂起;若无溢出控制,CPU 侧缓存可能耗尽,迫使系统回退到二次全收集,彻底瓦解零拷贝流水线。作者并未给出任何硬性上限或失效恢复机制,完全依赖经验性工程约束。
零、研究背景
NVIDIA 的 NCCL 通过自动检测硬件拓扑并协调数据流,经由环形或树形算法来优化如 all-gather 和 broadcast 等通信原语。作为 PyTorch FSDP、DeepSpeed 和 Megatron-LM 的默认通信后端,它是对称训练的行业标准。
然而,它依赖于集合通信语义,要求每个 rank 以匹配的数据形状同时调用相同的操作。虽然这种设计对于均衡的工作负载非常高效,但在动态环境中却成为一个负担:NCCL 以锁步方式运行,意味着单个接收方的“慢启动”可能导致整个组挂起,并使资源闲置。
RDMA(远程直接内存访问)
RDMA(远程直接内存访问)允许机器访问远程内存,同时完全绕过远程 CPU 和内核网络协议栈。其效率源于三个核心特征:
- 内核旁路:应用程序直接将工作请求提交给网卡,消除了昂贵的系统调用和上下文切换。
- 零拷贝:数据通过 DMA 直接在已注册的内存区域和网络之间移动,避免了内核缓冲区内的中间拷贝。
- 单向操作:RDMA 读/写操作由一方发起,在远端无需主动的 CPU 参与或中断处理。
与 NCCL 的全局同步不同,RDMA 允许任意两个端点独立并发通信,使其成为高速权重传输的理想基础。这正是此处描述的 P2P 权重更新机制利用基于 RDMA 的传输,通过 Mooncake TransferEngine 作为其底层基础的原因。
RL 权重传输问题
在大规模分布式 RL 训练中,从训练器到推理引擎的权重传输是一个关键路径操作:在权重传输期间,整个 RL 训练陷入停顿——训练器和推理均无进展,资源通常处于空闲状态。
随着模型规模的增长,这种传输必须跨多个主机和机架扩展,所有主机和机架都在争夺有限的带宽。基于 miles/slime/verl 等开源方案的现有 NCCL 工作流依赖于来自单个源 rank 的广播原语,该原语在传输过程中迅速成为瓶颈。
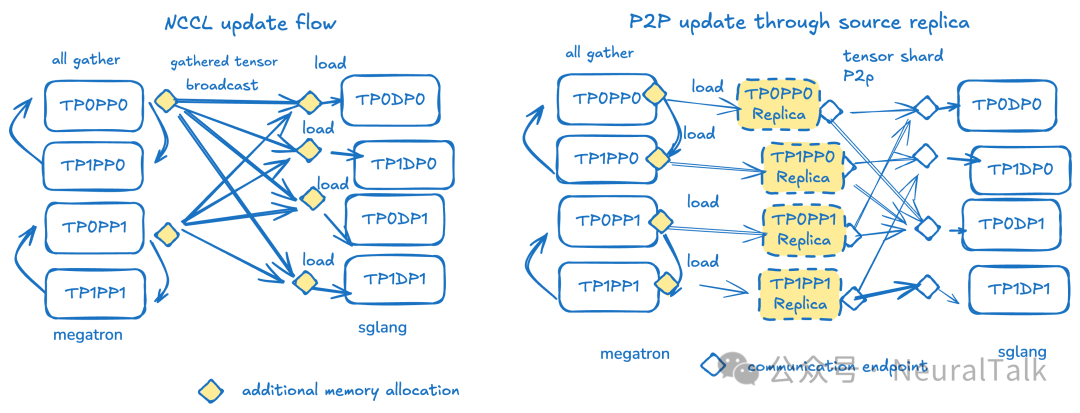
左图:分布式训练/推理 RL 期间,miles 中当前的权重传输工作流。在源端,所有节点在 TP 和 EP 维度上参与 all-gather,从而在每个 PP rank 的头 rank 上得到一个聚合后的张量。该头 rank 参与一个分布式更新组,通过 update_weight_from_distributed API 将完整权重广播给每个引擎 rank,其中本地 rank 加载其对应的分片。此过程针对每个 PP rank 和每个分桶的权重张量运行。右图:P2P 更新设计依赖于源端引擎副本作为中介。分桶权重更新的第一步 all-gather 与 miles 相同。但随后,权重被加载到 CPU 内存上的 sglang 引擎分片的本地副本中,该副本将其权重以正确的形状发送给 sglang。每个副本的权重可以发送给多个 sglang rank。每个目标 sglang TP rank 都需要从每个 pp 源接收数据。
一、现有 NCCL 广播面临的挑战
现有的 NCCL 广播解决方案面临以下挑战:
- 数据冗余:相同数据在网络中多次传输。
- 同步阻塞:单节点延迟会阻塞整个通信组,动态场景下需重建 NCCL 组。
- 扩展性差:大模型、多节点场景下,广播成为传输瓶颈。
此对比评估了传输 1T FP8 Kimi K2 模型(约 1TB)的性能。注意:update_weights_from_tensor 接口被排除在外,因为它仅支持同机部署场景。
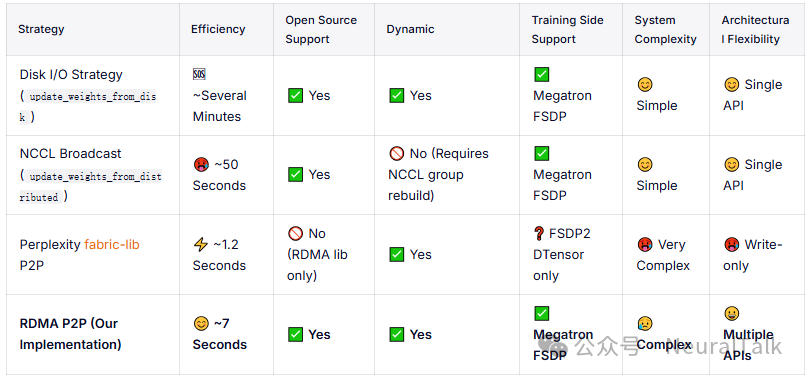
表格对比了四种大模型权重加载策略,从效率、开源支持、动态性等维度评估:Disk I/O 慢但简单;NCCL Broadcast 较快但动态性差;fabric-lib P2P 最快但不开源、极复杂;自研 RDMA P2P 效率适中,兼顾开源、动态性,复杂度中等,支持多 API,实现了性能与易用性的平衡。
虽然与 Perplexity 的方法相比,传输效率存在一些权衡,但我们的解决方案相对于现有的 SGLang 接口提供了显著的性能提升。此外,我们通过将这些能力封装进新的 API 接口,实现了高度的架构灵活性。参考 miles 的运行说明,以及支持的模型的完整列表[1]。
二、设计
我们的设计通过 RDMA,从集中式广播转向分布式 P2P 映射;同时保持与所有现有开源模型和任何并行配置的兼容性,重用现有接口。
- 源端引擎副本:我们在训练秩的 CPU 内存中创建模型副本。这避免了重复注册和注销带来的 GPU 显存浪费。
- P2P 映射启发式算法:我们实现了训练器层级与推理层级之间的点对点映射。不再是少数层级广播所有内容,每个训练器层级都会通过将其特定分片直接发送给目标来参与。
- 零拷贝传输:借助 TransferEngine,内存仅在启动时注册一次,无需对 CUDA 进程间通信(IPC)句柄进行耗时的序列化操作,也无需执行内核侧的拷贝操作。
该实现高度依赖于现有的基础设施和接口:
- 传输引擎[2]作为底层传输层,支持在网络上实现 CPU 与 GPU 之间的 RDMA 零拷贝传输。
- 通过 Rfork[3] 复用权重注册信息,这是通过 SGLang API 暴露的新型远程实例权重加载机制。
- load_weight(huggingface_tensor) 的标准 SGLang API,支持所有量化和分片配置。
SGLang 端需要新增几个接口:
- 为副本创建暴露模型并行性:PR #20907[4]
- 将 Hugging Face 张量映射到其对应的 SGLang 张量分片:PR #17326[5]
- 一个后处理权重引擎需要进行 GPU 本地处理,例如类似 PR #15245[6] 中的后量化处理。
这些内容已合并到目标为 miles 的 sglang-miles 分支中。在权重更新期间,调用方的操作如下:
2.1 初始化步骤

模型权重从训练环境迁移到推理环境的关键流程:先调用API获取权重注册信息,再获取张量并行(tp)、专家并行(ep)等并行配置,接着构建训练rank到推理rank的映射关系,最后创建CPU引擎副本。这套流程的核心是对齐训练与推理的并行策略和权重分布,通过精准映射避免并行差异导致的加载错误,为后续高效权重传输(如RDMA P2P)提供基础保障,实现训练与推理的无缝衔接,大幅提升模型部署效率。
2.2 每次更新
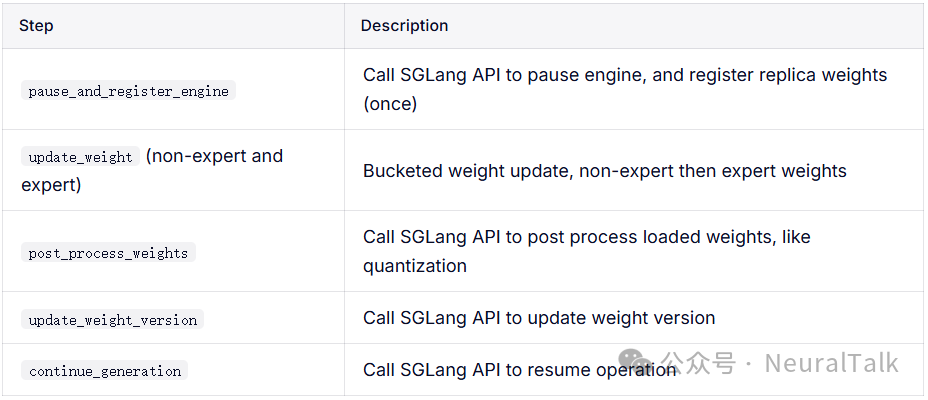
模型权重热更新流程:先调用API暂停引擎并注册副本权重;再分块更新权重(先非专家层、后专家层,适配MoE模型);接着对加载的权重做量化等后处理;更新权重版本号;最后恢复引擎运行。该流程通过可控暂停、分块更新、版本管理,实现了业务影响极小的权重迭代,既保障服务稳定性,又支持量化优化,适配MoE等大模型结构,是高效、安全的模型热更新方案。
其结果是一种通用的权重更新设计,可处理任意模型和所有常见量化逻辑,同时实现无冗余的快速 RDMA 零拷贝传输,并提高带宽利用率。
设想这样一个场景:
- 有 M 个源节点用于训练,N 个目标节点用于 SGLang 推理;
- 源节点的 pp_size 对应 pp,目标节点的 ep_size 对应 ep;
- 每个引擎节点拥有 P 个参数。将 K 分配为用于分块聚集(all gather)的内存缓冲区。假设模型仅包含专家权重:

该表格展示 RDMA P2P 设计如何权衡内存分配以实现更少的网络传输和更高的利用率。所有源进程组均参与其中,而在使用 NCCL 时仅每个流水线并行组的头部进程组参与;仅必要的张量通过网络发送,而 NCCL 需要将完整的全收集张量发送到每个进程组。RDMA P2P 通过在源 CPU 上额外分配 P 的内存来实现这一权衡,而在接收端则不再需要任何内存分配。我们注意到,由于在完整的 SGLang 张量更新之前,部分 Hugging Face 张量需要先在本地缓存,且通常存在多对一的张量映射关系(例如在 SGLang 中为 q_proj、k_proj、v_proj 映射到 qkv_proj),因此实际中的 K会略大于 K。*
上面表格对比了两种权重传输方案的资源开销:
- NCCL Broadcast的参与源rank为流水线并行数
pp,每个推理rank需接收 ep*P(专家并行数×单份参数)的参数,且源、目标端均需分配 K 大小的额外缓冲区;
- RDMA P2P的参与源rank为
M,每个推理rank仅接收 P 量参数,目标端无需额外缓冲区,仅源端需少量开销(K*+P)。
后者通过精准参数分发,大幅降低目标端内存压力,减少资源浪费,更适配大模型权重迁移场景,传输效率更优。
三、实现结果
我们分析了在配备 InfiniBand 连接的 H100 8 GPU 主机上常见开源模型的传输速度。计时从引擎暂停调用返回至 continue_generation 调用发出时开始计算。
表格对比了不同大模型在NCCL与RDMA两种权重传输方案下的性能。从9B到1T参数量的模型测试显示,随着模型规模增大,RDMA的优势愈发显著:小模型(如GLM4-9B)加速比仅0.98x,而744B和1T模型的加速比分别达6.88x、7.37x,耗时从数万ms骤降至数千ms。这说明RDMA在大规模、多节点场景下,相比NCCL的传输效率提升巨大,更适配大模型权重迁移需求。
注: Kimi-K2 特殊处理:我们调整了 Kimi K2,在 fp8 格式下使用 [64, 64] 的分块量化大小,以适配我们的性能分析配置。
在部署侧具备高专家并行度的大型混合专家(MoE)架构中,性能提升最为显著。在上述 GLM4-MoE 示例的低节点配置下,当专家并行度(EP)较小时,将张量本地加载到 CPU 模型的成本超过了点对点(P2P)传输的收益。随着参与节点增多,点对点传输的扩展性良好。
四、使用方法
在 Miles 中,可通过 --update-weight-transfer-mode p2p 启用 P2P 更新。这将让 SGLang 引擎通过 --sglang-remote-instance-weight-loader-start-seed-via-transfer-engine 注册其权重内存,并优先采用 P2P 更新流程而非 NCCL 广播。Miles 依赖于 SGLang 上的 sglang-miles 分支,其更高级的实验特性支持 P2P 传输。
五、未来规划
- 扩展支持:为 GB200 等新型硬件以及 SGLang 侧流水线并行提供官方支持。支持更多量化方式。将 SGLang 侧修改合并至主分支。
- 实验大页内存分配:不再永久分配 CPU 内存,可考虑启用 Transfer Engine 大页 GPU 分配功能,这能显著降低注册和注销成本。这可实现传输时的就地 GPU 副本创建与内存注册。
六、工程附录
6.1 设计迭代
我们最初的设计将源端副本放置在 GPU 上。为了避免浪费训练时的 GPU 内存利用率,我们在该环节投入了大量优化工作——如何以流水线方式完成注册、传输和注销?能否在通过虚拟内存在网卡上保持内存注册的同时,将模型卸载到 CPU 上?
出乎意料的是,考虑到现代集群的巨大带宽,传输本身耗时最少;相比之下,在 RDMA 场景下,权重注册是最耗时的环节,整个副本的注册要花费数十秒。 将模型转移到 CPU 上解决了这一问题。
另一个阻碍是 CPU 可能会出现初始内存不足(OOM)的情况。多个 GPU 共享同一高带宽内存(HBM),若在每个源节点上为每个目标节点都创建一个副本,很快就会变得难以管理——但我们很快意识到,所有 SGLang 节点都是基于同构构建的,这意味着我们可以牺牲少量传输并发度,优先实现内存复用。我们最终的设计复用了相同的底层物理内存,并精心调度数据,使其逐个传输至不同的引擎分片。
6.2 点对点传输计划
每个训练节点映射到其对应的目标推理引擎节点。采用带负载均衡的轮询分配方式:前序节点为一一映射,剩余目标节点被均匀分配。这可将每个源节点的 RDMA 会话数量降至最低。
想象对 pp=4 进行训练,采用 32 个训练进程,搭配 2 个 SGLang 引擎实例,每个实例包含 16 个进程。执行全聚合操作后,每个流水线(pp)组中的每个进程都包含了对应特定流水线层级的完整全聚合张量。每个目标进程都需要从每个流水线层级进程接收权重。我们从 pp_rank=0 开始:此时需要将 8 个训练进程映射到全部 32 个目标进程。
- 轮询:映射
src_rank 0 -> tgt_rank 0,… 映射 src_rank 7 -> tgt_rank 7
- 所有现有源节点负载相同。再进行一轮轮询分配,将
src_rank 0 -> tgt_rank 8、…… src_rank 7 -> tgt_rank 15
- 最后,注意 tgt_rank 16 与 tgt_rank 0 完全相同。回顾现有的分配情况,并将相同的引擎排名添加到其对应的源排名中。最终我们得到
src_rank 0 -> [tgt_rank [0, 16], tgt_rank [8, 24]] 等结果。
6.3 识别需要传输的 SGLang 张量
要以分桶的方式执行权重转移本身,我们需要在每次 model.load_weight() 之后确定准备好跨设备传输的参数。我们首先构建 Hugging Face 张量与其对应的 SGLang 张量或张量分片之间的映射关系。
sglang_name, shard_id, num_shards, expert_id, num_local_experts = parameter_mapper.map(hf_tensor)
对于每个模型和每个 Hugging Face 张量,我们获取其对应的专家以及在 SGLang 中该专家所映射到的张量分片。例如:
model.layers.0.mlp.experts.3.down_proj.weight -> model.layers.0.mlp.experts.w2_weight, w2, 2, 3, 5
只有当所有 num_local_experts 的所有 num_shards 都更新完成后,我们才能发送 SGLang 张量。
6.4 带共享副本的传输流程
为支持使用同一底层内存向多个目标引擎实例进行传输,我们采用了基于线程池的任务池以及用于部分更新张量的缓存缓冲区。SGLang 张量的传输任务要么处于关键路径且需等待完成,要么可提交至任务池,并仅在最后检查完成状态。TransferEngine 库移除了全局解释器锁(GIL),并在多线程配置中实现了并行性。
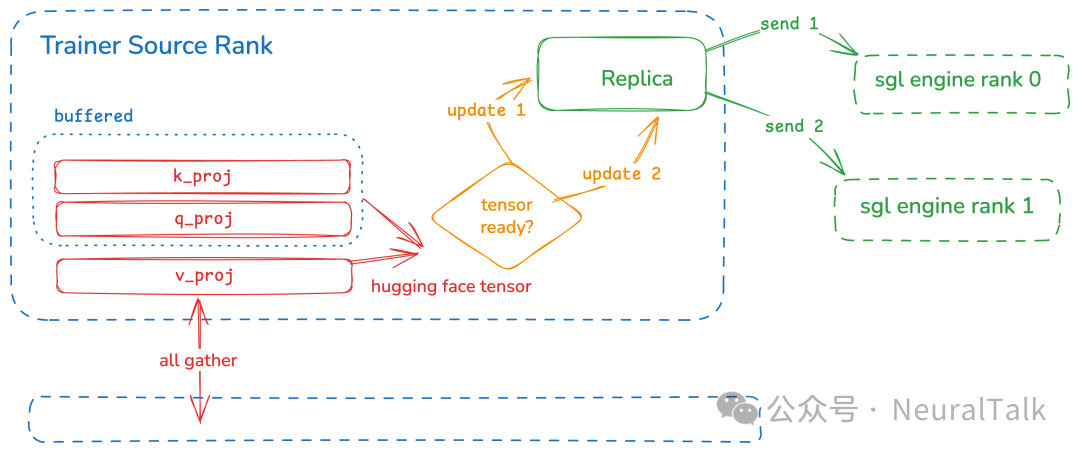
图:使用同一底层副本的一个训练源排名和两个目标排名的传递流程示例。训练端(Trainer Source Rank)先通过 all gather 收集 k_proj、q_proj、v_proj 等权重张量,部分先缓存;待张量就绪后,分两次更新到中间层Replica,再由Replica将数据发送到推理端的SGLang引擎rank 0和rank 1。这种设计通过分阶段缓存、就绪判断和中间副本分发,既优化了权重传输时机,避免无效操作,又降低了训练端直接向多rank传输的复杂度,适配张量并行推理场景,实现了训练权重向推理引擎的高效推送。
请注意,红色张量是在全收集(all-gather)之后的,包含所有专家和张量并行分片(tp shard)。然而,对于一个 SGLang 张量来说,单个分桶更新可能并不包含其所有张量分片——如图所示,q_proj 和 k_proj 已被收集,但缓存在了前一个分桶更新的副本之外。这也是为什么共享副本更新所需的缓冲区大小要大于 1。在最坏情况下,缓冲区可能是原始缓冲区的 num_shard 倍! 不过,由于 named_parameters 通常会将相关张量有序排列在一起,实际所需的额外缓冲区很小。
一旦一个 SGLang 张量收集到所有必要的分片,我们就会更新副本,利用其自身的并行信息来加载与第一个目标引擎层级(示例中为 SGLang 引擎层级 0)对应的权重。传输(发送 1)处于关键路径上,必须在再次更新底层 CPU 分片之前完成(即目标权重更新完成),更新时仍使用同一个 Hugging Face 张量,但采用另一个引擎层级的并行信息。对于最后一个待更新的引擎层级,不再有其他任务等待同一个 SGLang 张量,因此该任务(发送 2)可放入线程池,我们随即继续下一次全聚合操作。
6.5 其他量化及后处理方法
并非所有必要的张量都在 SGLang 的 model.named_parameters() 中注册。例如,在 DeepSeekV3 模型系列中,MLA 包含局部张量 w_kc 和 w_vc,这些张量是在 post_weight_load() 调用中完成所有权重加载后生成的。SGLang 包含大量依赖设备的自定义量化和特定硬件逻辑,无法在我们的 CPU 副本上执行。
参考资料
[1] miles 的运行说明,以及支持的模型的完整列表: https://github.com/radixark/miles/blob/main/docs/en/advanced/p2p-weight-transfer.md
[2] 传输引擎: https://kvcache-ai.github.io/Mooncake/python-api-reference/transfer-engine.html
[3] Rfork: https://www.lmsys.org/blog/2025-12-10-rfork/
[4] PR #20907: https://github.com/sgl-project/sglang/pull/17326
[5] PR #17326: https://github.com/sgl-project/sglang/pull/17326
[6] PR #15245: https://github.com/sgl-project/sglang/pull/15245
云栈社区将持续关注大规模分布式训练和推理系统的前沿实践,为大家带来更多深度解析。
 发表于 2026-5-7 03:37:40
|
查看: 140|
回复: 0
发表于 2026-5-7 03:37:40
|
查看: 140|
回复: 0
