你的大模型是不是经常“废话连篇”?生成了几千个Token,最后答案还是错的?问题可能不在于思考时间不够长,而在于思考不够深。


图:论文核心内容漫画解读
🔥 开源代码已放出:https://github.com/google-deepmind/deep-thinking-tokens
你肯定遇到过这种情况:让大模型解一道数学题,它洋洋洒洒写了上千字的推理过程,逻辑看似严密,结果却错得离谱。更气人的是,有时候它只是简单思考几行,答案反而正确。
这背后隐藏着一个行业级痛点:我们一直用“生成了多少Token”来衡量模型的思考量,但这真的可靠吗?更长就一定意味着更好吗?
今天,谷歌和弗吉尼亚大学的研究者告诉你:大错特错! 他们发现,真正决定推理质量的,不是思考的“长度”,而是思考的“深度”。他们提出了一个革命性的新指标——深度思考比率(Deep-Thinking Ratio, DTR),能像“脑电图”一样,精准捕捉大模型内部的真实思考过程。
读完本文,你将彻底理解:
- 为什么传统“Token数量”指标会失灵,甚至误导我们?
- “深度思考Token”到底是什么?如何从模型内部“偷窥”其思考?
- 如何利用这个新指标,在节省一半计算成本的同时,让模型推理准确率不降反升?
❓ 核心痛点:为什么“想得长”不等于“想得对”?
长期以来,AI社区信奉一个“朴素真理”:给大模型更多计算资源(表现为更长的思维链),它就能更好地推理。从CoT(思维链)到各种复杂Prompt,我们都在鼓励模型“多写点”。
但越来越多的证据表明,这条“金科玉律”正在失效。
- 倒U型陷阱:研究发现,思维链长度与答案准确率之间,并非简单的正比关系,而是一条倒U型曲线。存在一个最优长度,超过之后,模型开始“过度思考”,陷入无关细节或放大早期错误,导致性能不升反降。
- 反向缩放现象:在某些任务上,更长的推理过程甚至会系统性地降低模型性能。这就像一个人解题时钻牛角尖,越想越偏。
- 计算资源的巨大浪费:我们投入大量GPU算力,生成了海量Token,其中可能大部分都是无效或冗余的“废话”。这不仅烧钱,还让我们误以为模型在“认真工作”。
问题的根源在于,我们一直用表面特征(Token数量)来推测内部过程(思考质量)。这就像用一个人说话的时间长短,来判断他思考的深浅一样不靠谱。
我们需要一把新的“尺子”,能直接测量模型在推理时真实的“脑力活动”强度。
但为什么99%的优化尝试都失败了?关键在于,我们从未真正“看到”模型内部的思考路径。
为了帮你快速把握全局脉络,我们先看这张核心架构思维导图——它揭示了如何从模型“大脑”的层层活动中,提取出“深度思考”的信号。
接下来,我们逐层拆解这张图中的每个关键模块,看看这把“新尺子”是如何工作的。
🧠 原理拆解:如何“偷窥”大模型的思考过程?
💡 核心洞察:思考体现在“层”的修正中
研究者的核心假设非常直观:一个Token如果需要模型“绞尽脑汁”才能确定,那么它在模型较深的层中,其预测分布会持续发生显著变化。
这就像我们人类解题:
- 简单步骤:比如写下“解:设x为…”,几乎不假思索,想法在脑中很早就确定了。
- 关键推理:比如进行复杂的代数变换,大脑会反复推敲、修正,想法直到很晚(深入思考后)才定型。
Transformer模型也是类似的“思考者”。它的“大脑”由许多层(Layer)堆叠而成。当模型生成每一个Token时,信息会从浅层流向深层,每一层都会对“下一个词是什么”做出自己的“猜测”。
关键来了:研究者利用了一个被忽视的“后门”——他们直接用模型最后一层的“语言建模头”(一个将内部状态映射到词汇表的矩阵),去投影中间每一层的隐藏状态,从而得到每一层自己对下一个Token的预测分布 ( p_{t, l} )。

图:模型内部预测随层演变的示例。功能词、模板词(如 “and”,“boxed”)在浅层收敛;运算符、答案符号(如 “13”)直到深层才稳定。
这样,我们就能观察一个Token的“命运”是如何在模型的“脑海”中,随着层数加深而逐渐演变的。
💡 量化“深度”:当预测终于稳定
那么,如何定义一个Token是“深度思考”后的产物呢?研究者引入了两个精妙的量化步骤:
第一步:测量“不稳定”程度
对于生成的第 ( t ) 个Token,在第 ( l ) 层,他们计算该层的预测分布 ( p{t, l} ) 与最终层分布 ( p{t, L} ) 之间的詹森-香农散度(Jensen-Shannon Divergence, JSD):
[
D{t,l} = \text{JSD}(p{t,L} \; || \; p_{t,l})
]
这个值衡量了中间层预测与最终预测的差异。( D_{t,l} ) 越大,说明该层的想法离“定稿”还远;越接近0,说明想法已基本定型。
第二步:定义“稳定深度”
他们追踪 ( D_{t,l} ) 随层数 ( l ) 增加而减小的过程,并定义一个稳定深度 ( c_t ),即 首次低于一个阈值 ( g )(论文中设为0.5)时的层数。
- ( c_t ) 值小:说明模型在浅层就“想明白了”,这个Token是“浅思考”的结果。
- ( c_t ) 值大:说明直到很深的层,模型还在修正对这个Token的预测,这是“深思考”的体现。
最后,他们将那些稳定深度落在最后15%的层(即 ( c_t \ge \lceil (1-\rho)L \rceil ), 其中 ( \rho=0.85 ))的Token,标记为 “深度思考Token”。
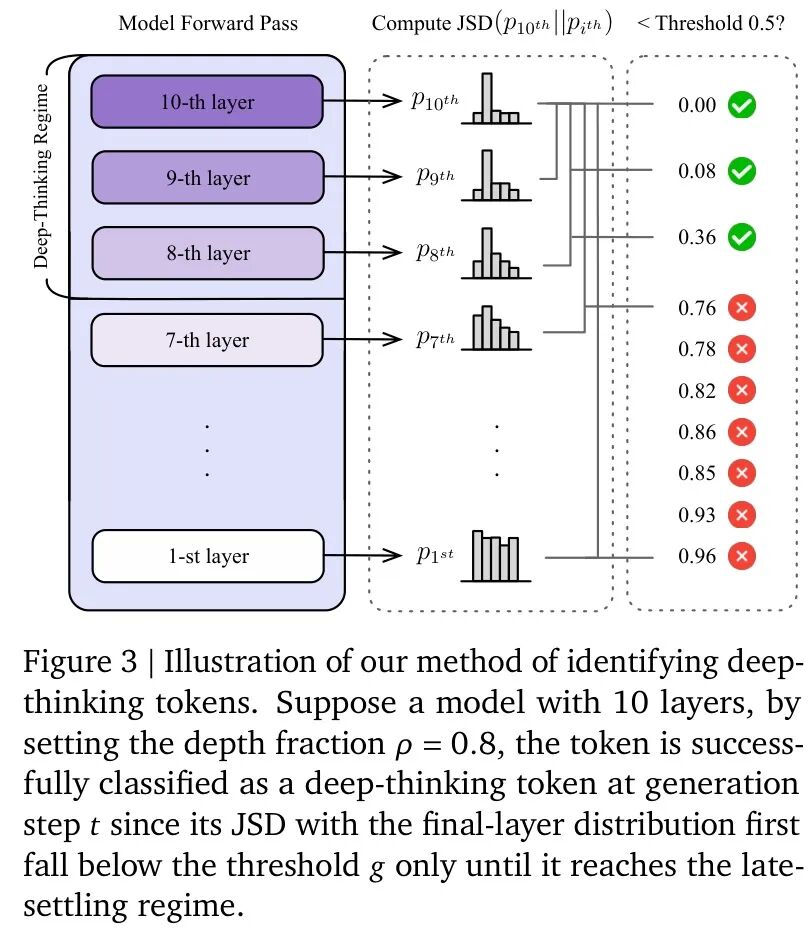
图:深度思考Token判定流程示意图。通过计算JSD距离并与阈值比较,判断Token是否属于深度思考范畴。
💡 最终指标:深度思考比率
对于一个生成的完整回复序列 ( S ),其深度思考比率(DTR) 就是序列中“深度思考Token”所占的比例:
[
\text{DTR}(S) = \frac{\text{# Deep-Thinking Tokens in } S}{|S|}
]
DTR高,意味着这个回答是模型“深思熟虑”的产物。
DTR低,则意味着模型可能只是在“照本宣科”或“胡言乱语”。

图:计算深度思考比率(DTR)的完整算法流程
💡 实战思考:这个方法的精妙之处在于,它完全无需额外训练或标注,仅利用模型前向传播中产生的、本就存在的中间状态。这为我们提供了一种低成本、高保真的模型“思考”监测工具。
看到这里,你是否也觉得这个内部视角的指标比单纯数Token更靠谱?但光有理论不够,是骡子是马,还得拉出来在硬核任务上溜溜。
📊 实验验证:数据说话,DTR完胜传统指标
研究者们在四个顶尖的数学与科学推理基准上展开了严苛测试:
- AIME 2024/2025:美国数学邀请赛试题
- HMMT 2025:哈佛-麻省理工数学竞赛题
- GPQA-diamond:研究生水平的科学难题
模型阵容同样豪华,涵盖了当前最强的推理模型家族:GPT-OSS系列、DeepSeek-R1和Qwen3-Thinking。
他们的目标很明确:比较DTR与各种传统指标,在预测“答案是否正确”这件事上,谁更准。
🏆 指标PK:DTR相关性一骑绝尘
他们采用分箱分析:根据每个指标(如DTR、Token数等)将模型生成的所有回复排序分组,然后计算每组内的平均准确率。指标与准确率的皮尔逊相关系数越高,说明该指标越能可靠地反映回答质量。
结果令人震撼:
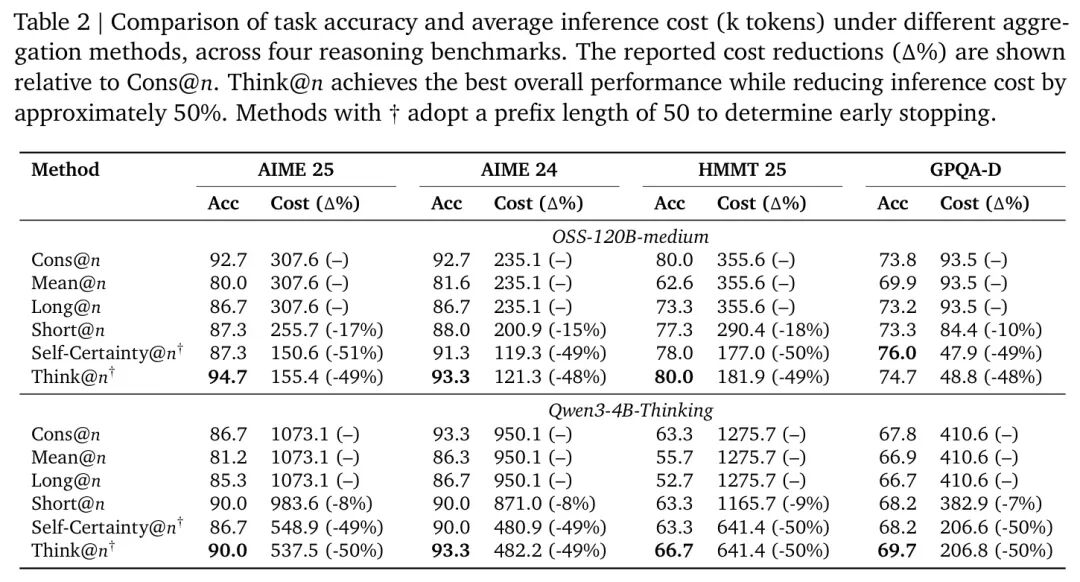
图:不同思考努力程度度量指标与任务准确率的相关性对比。DTR(橙色)在绝大多数模型-任务组合中取得最高正相关性。
- 传统长度指标(Token Count):表现极不稳定,在很多情况下甚至呈负相关!这证实了“越长越好”的假设是危险的。
- 基于置信度的指标(如LogProb、Self-Certainty):表现稍好,平均有适度的正相关,但波动很大。模型经常对自己错误的输出也“迷之自信”。
- 深度思考比率(DTR):全面碾压!在32个模型-任务测试组合中,DTR取得了最高且最稳定的正相关性,平均相关系数高达 0.683,显著优于其他所有基线。
结论清晰有力:模型外部的“废话长度”和“自信程度”,都远不如其内部的“思考深度”更能告诉你答案的对错。
🔬 超参分析:DTR的稳健性
一个新指标如果对参数过于敏感,就难以实用。研究者们深入分析了两个关键超参:
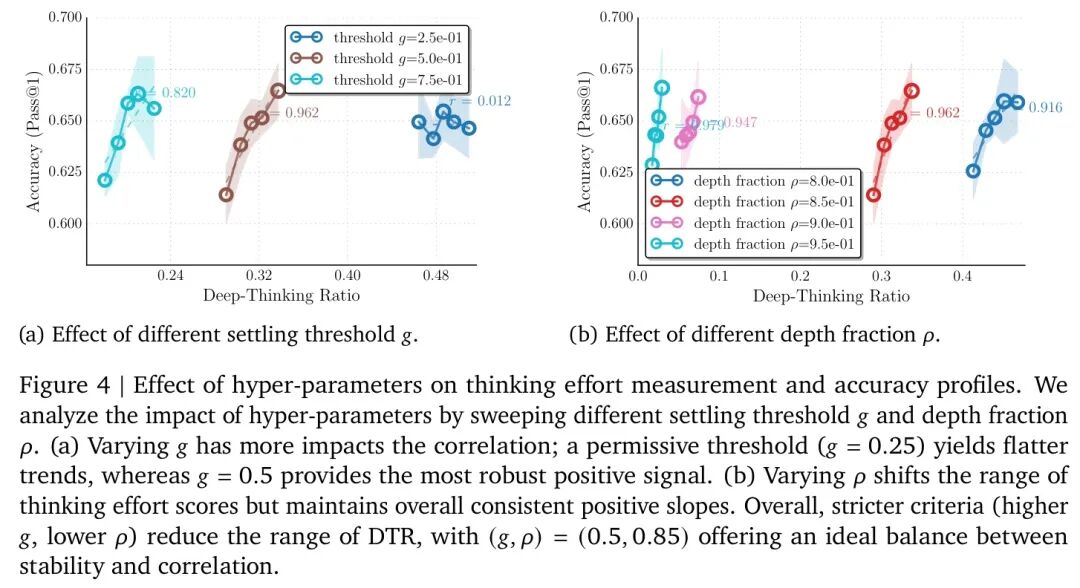
图:稳定阈值 ( g ) 和深度比例 ( \rho ) 对DTR值及其与准确率相关性的影响分析。
- 稳定阈值 ( g ):控制“稳定”的松紧度。( g=0.5 ) 是一个稳健的甜点,过松(( g=0.25 ))或过紧(( g=0.75 ))都会削弱相关性。
- 深度比例 ( \rho ):定义“后期”的范围。在 ( \rho=0.85 ) 附近,DTR与准确率的相关性对 ( \rho ) 的变化不敏感,说明指标具有很好的鲁棒性。
这些分析让DTR从一个有趣的发现,变成了一个可靠、可复现的实用工具。
既然DTR能如此精准地识别高质量推理,我们能否用它来做点更“功利”的事情?比如,大幅节省我们昂贵的推理成本?
🚀 杀手级应用:Think @ n,省下一半算力,准确率更高!
在AI产品中,为了提升答案可靠性,常采用 “自一致性” 策略:让模型对同一个问题并行生成 ( n ) 个回复,然后通过投票选出最一致的答案。这很有效,但代价是推理成本暴增 ( n ) 倍。
现在,有了DTR这把“尺子”,我们可以变得更聪明。研究者提出了 Think @ n 策略:
- 并行生成:同时开始生成 ( n ) 个回复。
- 早期评估:当每个回复只生成了很短的一个前缀(比如几十个Token)时,就计算其前缀的DTR值。
- 优胜劣汰:立即停止那些DTR值低的、看起来“没怎么动脑”的回复的生成。
- 精英聚合:只让DTR值高的、看起来“深思熟虑”的回复完成生成,并对它们的最终答案进行聚合。
Think @ n 的核心思想是:与其让一堆“笨”回答说完废话,不如早点把钱花在“聪明”回答上。
📈 效率与性能的完美平衡
实验结果令人兴奋:
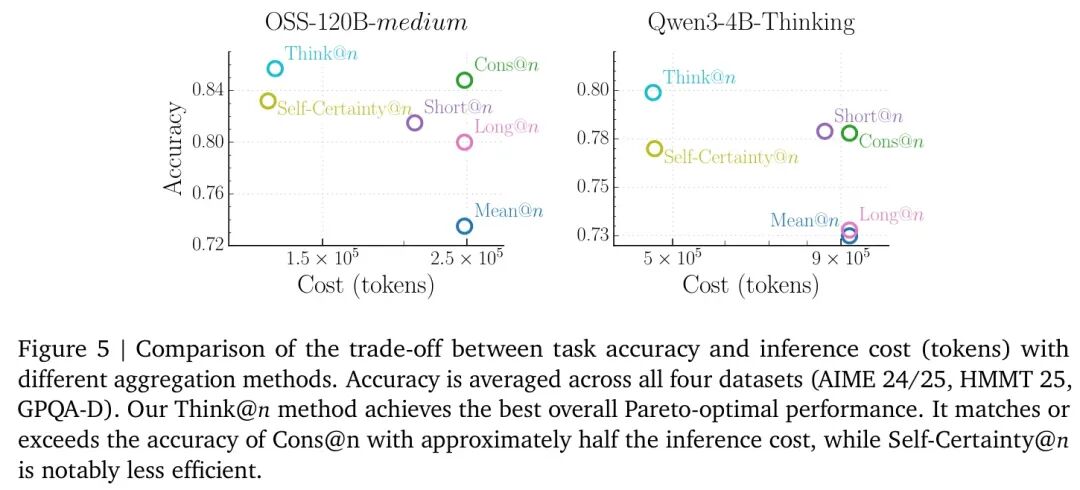
图:不同测试时扩展策略在准确率与推理成本(总生成Token数)上的帕累托前沿对比。Think @ n 实现了最佳权衡。
- 对比 Baseline:
- Cons @ n (标准自一致性):性能强,但成本最高(需要完整生成所有 ( n ) 个回复)。
- Short @ n (选最短的):能省一些成本,但性能显著下降,因为“简短”不等于“正确”。
- Self-Certainty @ n (选最自信的):省成本效果不错,但性能不稳定,常低于Cons @ n。
- Think @ n:在推理成本仅为 Cons @ n 一半左右的情况下,在四个基准上的准确率全部达到或超过了标准的自一致性方法!
这意味着什么? 对于企业来说,部署完全相同的模型,采用Think @ n策略,可以在保持甚至提升回答质量的同时,将推理的云计算账单直接砍半!这无疑是巨大的商业价值。
⚖️ 客观评价与未来展望
当然,任何新技术都有其边界。
局限性:
- 访问内部状态的需求:计算DTR需要获取模型中间层的隐藏状态。这对于某些仅提供API的黑盒模型来说可能受限。
- 额外计算开销:虽然比生成完整Token便宜,但投影计算和JSD计算仍会带来小幅开销。
- 任务普适性:当前工作聚焦于数学/科学推理任务。在创意写作、对话等更开放的任务上,DTR的有效性有待进一步验证。
未来展望:
- 训练阶段引导:能否用DTR作为训练信号,直接鼓励模型进行“深度思考”,而非“冗长思考”?
- 动态计算分配:能否根据DTR实时调整计算资源?对“百思不得其解”的问题分配更多层数或迭代?
- 可解释性新维度:DTR为我们打开了模型“思考过程”的黑箱,或许能帮助我们发现模型推理中的系统性缺陷或捷径。
🌟 总结与行动号召
这项研究为我们点亮了一盏明灯:
✅ 抛弃“长度迷信”:Token数量已不再是衡量推理努力的可靠指标,甚至可能是误导。
✅ 拥抱“深度信号”:深度思考比率(DTR) 从Transformer机制出发,提供了衡量真实思考强度的全新视角。
✅ 实现“降本增效”:基于DTR的 Think @ n 策略,用一半的成本获得了更优的性能,具备 immediate 的落地价值。
这不仅仅是一个新指标,更是一种研究范式的转变——从关注模型外部的输出“表象”,转向洞察其内部的思考“本质”。对于希望在AI浪潮中优化模型训练与推理成本的技术团队来说,这篇论文和它背后的思想值得深入研究。欢迎前往云栈社区的人工智能板块,与更多开发者探讨这项技术的实践细节与潜在应用。
参考论文:Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
 发表于 2026-2-24 06:07:04
|
查看: 219|
回复: 0
发表于 2026-2-24 06:07:04
|
查看: 219|
回复: 0
