数字人赛道技术迭代迅速,从静态形象到全实时流式生成,门槛却一直居高不下。高质量实时数字人往往依赖昂贵的云端算力或专业显卡,对个人开发者与小团队并不友好。
最近,Soul AI Lab 开源的 SoulX-FlashHead 项目,为这一困境提供了新的思路。它旨在将工业级实时数字人技术推向普惠。
这不再是大公司的专属玩具。该项目直接降低了技术门槛,让个人开发者和小团队也能玩转高质量的实时数字人生成。
项目简介
SoulX-FlashHead 是一个实时流式数字人生成框架。其核心目标是让工业级技术真正变得触手可及。
它的性能数据相当亮眼:
- 仅 1.3B 参数,模型极其轻量。
- Lite 版在单卡 RTX 4090 上可达 96 FPS,显存占用仅 6.4G。
- 支持 3 路并发流式推理,一台机器可服务多个用户。
- Pro 版画质顶尖,单卡 RTX 4090 上可达 10.8 FPS。
这意味着,你只需要一张消费级显卡,就能搭建起一个可用的实时数字人服务,无需昂贵的 A100 或 H100。
核心亮点
1、超轻量设计
SoulX-FlashHead 仅有 1.3B 参数。在动辄数十亿参数的大模型时代,这个体量显得尤为精简。更小的参数直接带来了更低的显存占用、更快的推理速度以及更经济的部署成本,对资源有限的开发者而言无疑是福音。
2、双版本策略
项目提供两个版本以适应不同场景:
- Lite 版:
- 96 FPS 超高帧率
- 6.4G 显存占用
- 支持 3 路并发
- 适合对实时性要求极高的交互场景
- Pro 版:
- 画质更精细
- 单卡 RTX 4090 可达 10.8 FPS
- 适合需要高质量输出的视频生成场景
你可以根据实际需求在速度与画质间灵活选择。
3、高并发支持
Lite 版支持 3 路并发流式推理。一台机器可同时处理三个用户的实时数字人交互请求,显著提升了硬件资源的利用率,降低了运营成本。
4、全面开源
代码、模型权重、文档全部开放。GitHub 仓库提供了完整的推理代码与详尽的教程。团队还开源了 VividHead 数据集,包含 782 小时的高质量训练数据,共计 330,000 个短视频片段,为社区研究和复现提供了坚实基础。
功能特性
1、无限长度流式生成
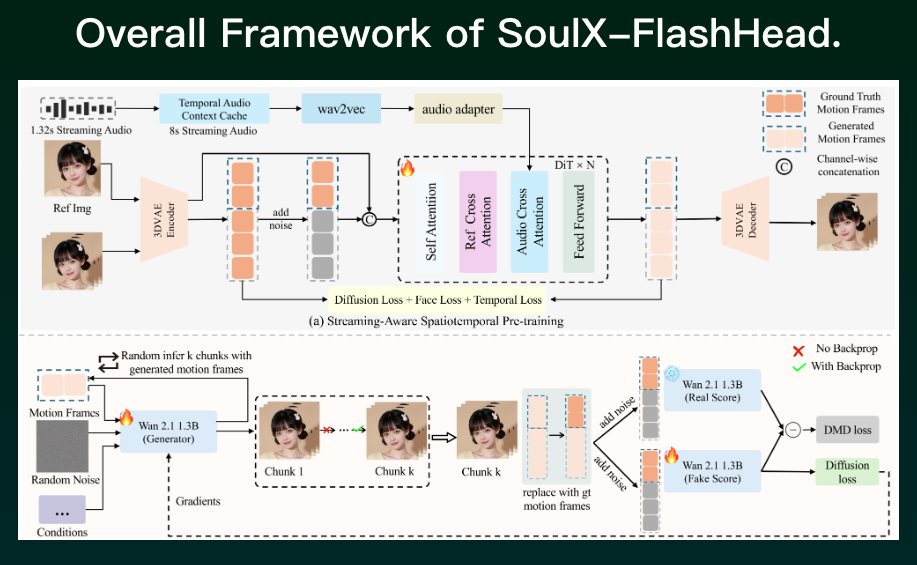
传统方法在生成长序列视频时容易出现身份漂移、画质下降等问题。SoulX-FlashHead 通过 Oracle-Guided Bidirectional Distillation 技术,有效解决了这一难题,能够持续生成高质量的无限制视频流。

2、高保真音画同步
音频驱动的口型同步是数字人的核心。该项目采用 Streaming-Aware Spatiotemporal Pre-training 技术,从短音频片段中提取稳定特征,实现了精准的唇音同步。测试表明,其在同步一致性上优于 SadTalker、Ditto 等方法。
3、整体一致性保持
不同于某些基于抽象运动表示的方法(易导致头饰与主体分离),SoulX-FlashHead 采用整体表示方法,在运动过程中能更好地保持头部、头饰及背景的一致性,使效果更为自然。
VividHead 数据集
团队构建的大规模高质量数据集包含:
- 782 小时 视频数据
- 330,000 个 短视频片段(时长 3秒至60秒)
- 512×512 分辨率
- 严格时间对齐的语音音频
- 丰富的元数据(如语言、种族、年龄等)
- 单一说话人、活跃头部区域
关键技术借鉴
项目站在了多个优秀开源工作的肩膀上:
- Wan:作为基础模型。
- LTX-Video:为 Lite 版提供 VAE。
- Self Forcing:构成代码库基础。
- DMD 和 Self Forcing++:关键的蒸馏技术。
快速上手教程
1. 创建 Conda 环境
conda create -n flashhead python=3.10
conda activate flashhead
2. 安装 PyTorch
pip install torch==2.7.1 torchvision==0.22.1 --index-url https://download.pytorch.org/whl/cu128
3. 安装项目依赖
pip install -r requirements.txt
4. 安装 FlashAttention(用于加速)
pip install ninja
pip install flash_attn==2.8.0.post2 --no-build-isolation
如果安装时间过长,可从官方链接下载预编译的 wheel 文件直接安装。
5. 安装 SageAttention(可选,进一步加速推理)
pip install sageattention==2.2.0 --no-build-isolation
6. 安装 FFmpeg
# Ubuntu / Debian
apt-get install ffmpeg
# CentOS / RHEL
yum install ffmpeg ffmpeg-devel
# Conda 方式(无需 root 权限)
conda install -c conda-forge ffmpeg==7
7. 下载模型
# 若在国内,建议先设置镜像源以加速下载
export HF_ENDPOINT=https://hf-mirror.com
pip install "huggingface_hub[cli]"
huggingface-cli download Soul-AILab/SoulX-FlashHead-1_3B --local-dir ./models/SoulX-FlashHead-1_3B
huggingface-cli download facebook/wav2vec2-base-960h --local-dir ./models/wav2vec2-base-960h
8. 开始推理
根据你的硬件和需求选择对应的脚本:
- 单卡运行 Pro 版模型:
bash inference_script_single_gpu_pro.sh
- 多卡运行 Pro 版模型:
bash inference_script_multi_gpu_pro.sh
- 单卡运行 Lite 版模型:
bash inference_script_single_gpu_lite.sh
总结
SoulX-FlashHead 最令人印象深刻的并非仅仅是 96 FPS 的速度或 1.3B 的参数量,而在于它切实推动了 实时数字人技术的普惠。过去,这曾是资源雄厚的大公司的专利,如今一张 RTX 4090 显卡即可驱动,且效果出众。这种技术平权,正是 AI 发展中最具魅力的部分。
对于希望进入数字人领域或正在寻找低成本落地方案的开发者来说,这是一个绝佳的 开源实战 机会。项目几乎开放了一切:代码、模型、数据集。如果你对相关技术感兴趣,不妨前往 GitHub 深入了解,也可以到 云栈社区 的 人工智能 板块,与更多开发者交流讨论。
项目资源

 发表于 2026-3-1 11:09:01
|
查看: 322|
回复: 0
发表于 2026-3-1 11:09:01
|
查看: 322|
回复: 0
