本文将深入探索大语言模型(LLM)的内部实现,以直观理解其工作机制。为辅助本次探究,我们将使用llama.cpp的源码——这是Meta公司LLaMA模型的纯C++实现。我个人发现,llama.cpp是深入理解LLM的绝佳学习工具,其代码简洁清晰、直指核心,没有过多抽象层的设计。本文的研究重点为LLM的推理环节,即已完成训练的模型如何基于用户提示词生成响应。
全文将完整讲解LLM的推理流程,涵盖以下核心内容:
- 张量(Tensors):简要介绍如何通过张量执行数学运算,以及张量运算向GPU的卸载逻辑。
- Tokenization:将用户提示词拆分为token序列的过程,token是LLM的输入单位。
- Embedding:将token转换为向量表示的过程。
- 变换器(The Transformer):LLM架构的核心模块,负责实际的推理计算,本文将重点讲解自注意力机制(self-attention mechanism)。
- 采样(Sampling):选择模型预测的下一个token的过程,本文将介绍两种采样方法。
- KV缓存(The KV cache):用于提升长提示词推理速度的常用优化技术,本文将讲解一种基础的KV缓存实现方案。
从提示词到输出的高层级流程
作为一款大语言模型,LLaMA的工作逻辑是接收输入文本(即提示词),并预测后续应该出现的token(或单词)。
为便于说明,我们以维基百科中关于量子力学的首句作为示例提示词:
Quantum mechanics is a fundamental theory in physics that
LLaMA会根据其训练所学习到的语言规律,以最符合逻辑的方式续写这句话。通过llama.cpp运行后,得到的续写内容为:
provides insights into how matter and energy behave at the atomic scale.
我们首先解析这一过程的高层级流程。从核心逻辑来看,LLM每次仅能预测一个token,完整句子(或更长文本)的生成,是通过将模型的输出token不断追加到原提示词后,反复调用LLM模型实现的。这类模型被称为自回归模型(autoregressive model)。因此,本文的研究重点将围绕单个token的生成过程展开,相关流程可参考下方的高层级示意图:
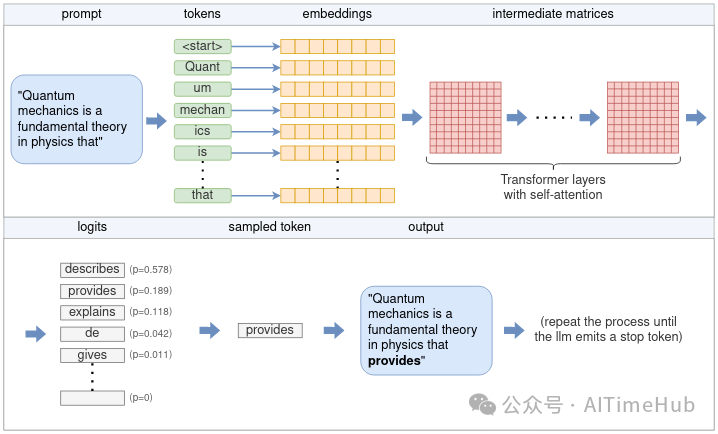
从用户提示词生成单个token的完整流程包含Tokenization、Embedding、Transformer神经网络计算、采样等多个阶段,本文将逐一详解。
结合示意图,具体流程如下:
Tokenization器将提示词拆分为token序列,根据模型的词汇表(vocabulary),部分单词可能会被拆分为多个token,每个token对应一个唯一的数字标识。- 每个数字形式的token会被转换为一个
Embedding向量(embedding),Embedding向量是固定维度的向量,其表示形式更便于LLM进行计算。所有token的Embedding向量共同构成一个Embedding矩阵。
Embedding矩阵作为Transformer的输入,Transformer是作为LLM核心的神经网络,由多个层级串联组成。每一层都会接收一个输入矩阵,并结合模型参数执行各类数学运算(其中最核心的是自注意力机制),该层的输出将作为下一层的输入。- 一个最终的神经网络会将Transformer的输出转换为对数几率(logits),每个可能的后续token都对应一个logit值,该值代表该token作为句子“正确”续写的概率。
- 采用某一种采样技术,从所有logit对应的token中选择下一个token。
- 选中的token将作为输出返回。若要继续生成后续token,需将该token追加至步骤1得到的token序列中,重复上述整个流程。这一过程会持续进行,直到生成指定数量的token,或LLM输出特殊的流结束标识(end-of-stream,EOS)token。
在后续章节中,我们将逐一深入解析每个步骤的细节。在此之前,我们需要先熟悉张量(tensor)的相关知识。
基于ggml理解张量
张量是神经网络中执行数学运算的核心数据结构。llama.cpp采用了ggml——一款纯C++实现的张量库,其功能与Python生态中的PyTorch、Tensorflow等价。本文将通过ggml解析张量的运行机制。
张量代表一个多维数字数组,可以存储单个数值、向量(一维数组)、矩阵(二维数组),甚至三维或四维数组,更高维度的张量在实际应用中基本不会用到。
需要明确区分两种类型的张量:一种是存储实际数据的张量,其内部包含多维数字数组;另一种是仅表示张量间运算结果的张量,这类张量在实际计算前不会存储任何数据。本文后续将详细解析二者的区别。
张量的基本结构
在ggml中,张量由ggml_tensor结构体表示,为便于理解,本文对其做了简化处理,核心结构如下:
// ggml.h
struct ggml_tensor {
enum ggml_type type;
enum ggml_backend backend;
int n_dims;
// 元素数量
int64_t ne[GGML_MAX_DIMS];
// 按字节计算的步长
size_t nb[GGML_MAX_DIMS];
enum ggml_op op;
struct ggml_tensor * src[GGML_MAX_SRC];
void * data;
char name[GGML_MAX_NAME];
};
前几个字段的含义较为直观:
type:存储张量元素的基本数据类型,例如GGML_TYPE_F32表示每个元素为32位浮点数。backend:标识张量的计算后端,可选CPU或GPU,后续将详细讲解。n_dims:张量的维度数,取值范围为1到4。ne:存储张量每个维度的元素数量,ggml采用行优先的存储顺序,即ne[0]表示每行的元素数量,ne[1]表示每列的元素数量,以此类推。nb:该字段的设计更为精巧,存储张量每个维度的步长(即同一维度中相邻元素之间的字节数)。对于第一维度,步长为单个元素的字节大小;第二维度的步长为行大小乘以单个元素的字节大小,依此类推。
以一个4×3×2的张量为例:
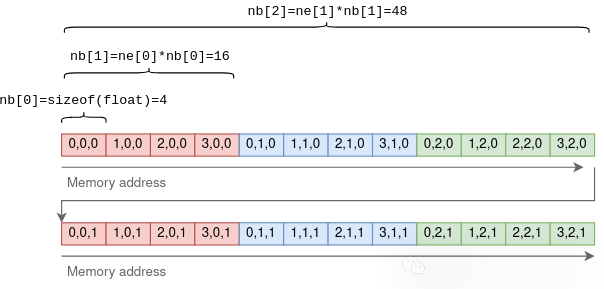
步长的设计目的是让部分张量运算无需复制数据即可执行。例如,将二维张量的行和列互换的转置运算,仅需交换ne和nb的取值,并让新张量指向原张量的底层数据即可实现:
// ggml.c (函数做了简化处理)
struct ggml_tensor * ggml_transpose(
struct ggml_context * ctx,
struct ggml_tensor * a) {
// 初始化result,指向与a相同的数据
struct ggml_tensor * result = ggml_view_tensor(ctx, a);
result->ne[0] = a->ne[1];
result->ne[1] = a->ne[0];
result->nb[0] = a->nb[1];
result->nb[1] = a->nb[0];
result->op = GGML_OP_TRANSPOSE;
result->src[0] = a;
return result;
}
在上述函数中,新生成的result张量是原张量a的视图,二者指向内存中同一处多维数字数组。通过交换ne中的维度值和nb中的步长值,无需复制任何数据即可完成转置运算。
张量运算与视图
如前所述,部分张量存储实际数据,而另一部分仅表示多个张量间的运算结果。回到ggml_tensor结构体,其余核心字段的含义如下:
op:表示张量支持的任意运算类型。若该字段设为GGML_OP_NONE,说明该张量为数据张量,存储实际数据;若为其他取值,则代表该张量是运算张量,例如GGML_OP_MUL_MAT表示该张量不存储数据,仅代表两个张量的矩阵乘法运算结果。src:指向参与运算的源张量的指针数组。例如,若op == GGML_OP_MUL_MAT,则src中会存储两个待相乘张量的指针;若op == GGML_OP_NONE,则src为空。data:指向张量实际数据的指针;若为运算张量,该指针为NULL;若该指针指向另一个张量的数据,则该张量被称为视图(view)。例如上述ggml_transpose()函数中,结果张量就是原张量的视图,仅修改了维度和步长,data指针仍指向原内存地址。
矩阵乘法函数能很好地体现上述概念:
// ggml.c (做了简化和注释)
struct ggml_tensor * ggml_mul_mat(
struct ggml_context * ctx,
struct ggml_tensor * a,
struct ggml_tensor * b) {
// 检查张量维度是否满足矩阵乘法要求
GGML_ASSERT(ggml_can_mul_mat(a, b));
// 根据矩阵乘法规则,设置新张量的维度
const int64_t ne[4] = { a->ne[1], b->ne[1], b->ne[2], b->ne[3] };
// 分配新的ggml_tensor结构体
// 仅分配结构体本身,不分配实际的数据存储空间
struct ggml_tensor * result = ggml_new_tensor(ctx, GGML_TYPE_F32, MAX(a->n_dims, b->n_dims), ne);
// 设置运算类型和源张量
result->op = GGML_OP_MUL_MAT;
result->src[0] = a;
result->src[1] = b;
return result;
}
在上述函数中,result张量不包含任何实际数据,仅作为a和b矩阵乘法运算结果的逻辑表示。
张量的计算过程
上述的ggml_mul_mat()函数,或其他任何张量运算函数,都不会执行实际的计算,仅会为运算准备好对应的张量结构。换个角度理解,这类函数的作用是构建计算图(computation graph)——计算图中每个节点代表一次张量运算,节点的子节点则为参与该运算的源张量。以矩阵乘法为例,计算图中会有一个标识为GGML_OP_MUL_MAT的父节点,以及两个分别代表待乘张量的子节点。
以下是llama.cpp中的实际代码示例,该代码实现了自注意力机制(属于每个Transformer层的核心模块,后续将深入讲解):
// llama.cpp
static struct ggml_cgraph * llm_build_llama(/* ... */) {
// ...
// K,Q,V为提前初始化的张量
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
// KQ_scale为提前初始化的标量张量
struct ggml_tensor * KQ_scaled = ggml_scale_inplace(ctx0, KQ, KQ_scale);
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0, KQ_scaled, n_past);
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
// ...
}
上述代码由一系列张量运算组成,构建的计算图与原始Transformer论文中描述的自注意力计算图完全一致:
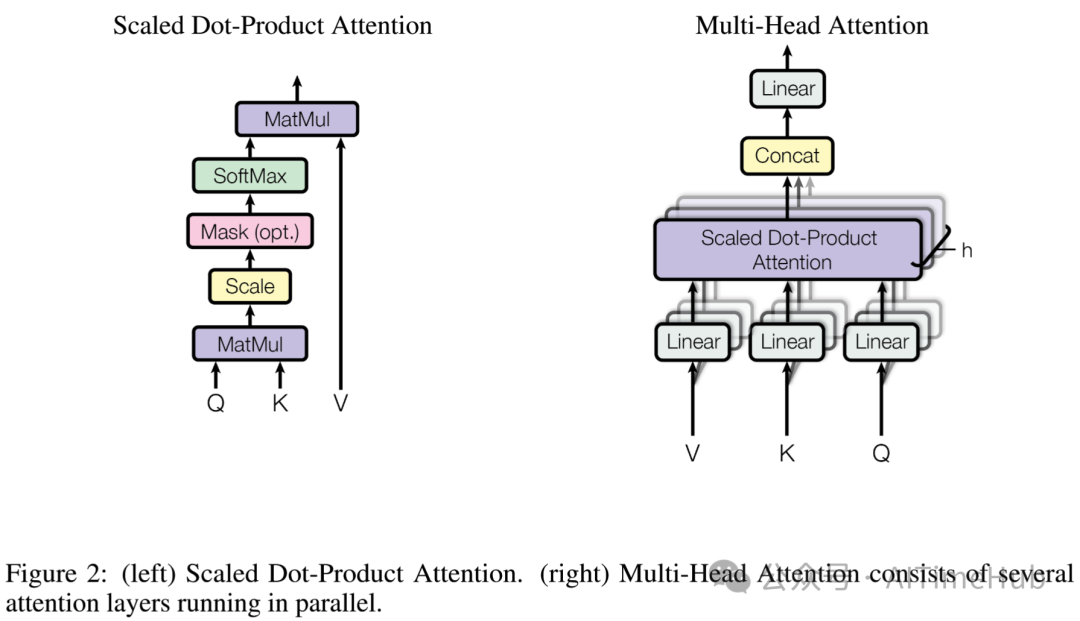
要得到最终的结果张量(此处为KQV),需执行以下步骤:
- 将数据加载至所有叶子张量的
data指针中,本示例中的叶子张量为K、Q、V。
- 通过
ggml_build_forward()将输出张量(KQV)转换为计算图,该函数的逻辑较为简单,会以深度优先的顺序对计算图的节点进行排序。
- 通过
ggml_graph_compute()运行计算图,该函数会以深度优先的顺序对每个节点执行ggml_compute_forward(),而ggml_compute_forward()是实际执行计算的核心函数——它会完成对应的数学运算,并将结果填充至张量的data指针中。
完成上述过程后,输出张量的data指针将指向最终的计算结果。
张量计算向GPU的卸载
矩阵加法、矩阵乘法等多数张量运算,在GPU上执行的效率远高于CPU,这得益于GPU的高并行计算特性。当有可用的GPU时,可将张量的backend字段设为GGML_BACKEND_GPU,此时ggml_compute_forward()会尝试将计算任务卸载至GPU执行,GPU完成运算后,结果会存储在GPU显存中,而非张量的data指针(该指针指向CPU内存)。
以前文的自注意力计算图为例,假设K、Q、V为固定张量,其计算过程可卸载至GPU,具体流程如下:
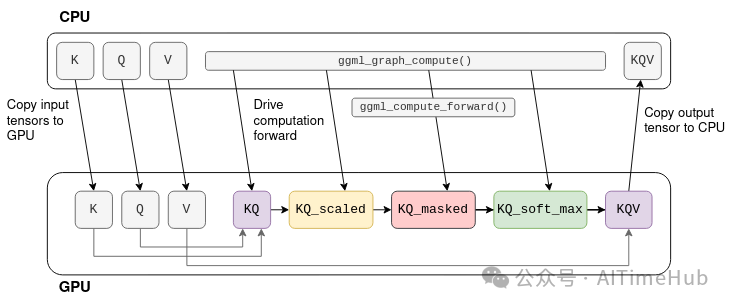
注:在实际的Transformer中,K、Q、V并非固定张量,KQV也并非最终输出,后续将详细讲解。
掌握了张量的相关知识后,我们回到LLaMA的推理流程继续解析。
Tokenization
推理的第一步是Tokenization(tokenization),即把提示词拆分为一系列短字符串(称为token)的过程,这些token必须属于模型的词汇表——也就是LLM在训练阶段所使用的token集合。例如,LLaMA的词汇表包含32k个token,该词汇表会随模型一同发布。
以本文的示例提示词为例,Tokenization后会得到11个token(空格会被替换为特殊元符号▁(U+2581)):
|Quant|um|▁mechan|ics|▁is|▁a|▁fundamental|▁theory|▁in|▁physics|▁that|
LLaMA采用SentencePiece Tokenization器,并结合字节对编码(byte-pair-encoding,BPE)算法实现Tokenization。该Tokenization器的核心特点是基于子词(subword),即单个单词可能会被拆分为多个token。在上述示例中,单词Quantum被拆分为Quant和um两个token。在模型训练的词汇表构建阶段,BPE算法会确保常用单词作为单个token被纳入词汇表,而生僻单词则会被拆分为子词。上述示例中,Quantum未被纳入词汇表,但Quant和um作为两个独立的token存在于词汇表中。空格不会被特殊处理,若其出现频率足够高,会以元符号的形式被包含在token中。
基于子词的Tokenization方式具备诸多优势:
- 既能让LLM学习生僻单词(如
Quantum)的语义,又能通过将常见的词缀表示为独立token,控制词汇表的大小。
- 无需设计针对特定语言的
Tokenization规则,即可让模型学习到语言的专属特征。
- 该
Tokenization方式同样适用于代码解析。例如,变量名model_size会被Tokenization为model|_|size,让LLM能够“理解”该变量的含义。
在llama.cpp中,Tokenization功能由llama_tokenize()函数实现,该函数接收提示词字符串作为输入,返回由整数表示的token序列:
// llama.h
typedef int llama_token;
// common.h
std::vector<llama_token> llama_tokenize(
struct llama_context * ctx,
// 提示词
const std::string & text,
bool add_bos);
Tokenization的执行流程为:首先将提示词拆分为单个字符的token,然后迭代尝试将相邻的两个token合并为一个更大的token,只要合并后的token存在于词汇表中,该过程就会持续进行,最终得到尽可能长的token序列。本文示例提示词的Tokenization步骤如下:
Q|u|a|n|t|u|m|▁|m|e|c|h|a|n|i|c|s|▁|i|s|▁a|▁|f|u|n|d|a|m|e|n|t|a|l|
Qu|an|t|um|▁m|e|ch|an|ic|s|▁|is|▁a|▁f|u|nd|am|en|t|al|
Qu|ant|um|▁me|chan|ics|▁is|▁a|▁f|und|am|ent|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|ament|al|
Quant|um|▁mechan|ics|▁is|▁a|▁fund|amental|
Quant|um|▁mechan|ics|▁is|▁a|▁fundamental|
注:上述每一个中间步骤的结果,都是符合模型词汇表的有效Tokenization结果,但只有最后一步的结果会被作为LLM的输入。
Embedding
Tokenization得到的token会作为LLaMA的输入,用于预测下一个token,核心实现函数为llm_build_llama():
// llama.cpp (做了简化处理)
static struct ggml_cgraph * llm_build_llama(
llama_context & lctx,
const llama_token * tokens,
int n_tokens,
int n_past);
该函数接收tokens(token序列)和n_tokens(token数量)作为输入,构建LLaMA完整的张量计算图,并将其以ggml_cgraph结构体的形式返回,此阶段不会执行任何实际计算。n_past参数目前被设为0,暂时可忽略,后续讲解KV缓存时会重新介绍该参数。
除了token序列,该函数还会使用模型权重(model weights)(也称为模型参数,model parameters),这些是模型在训练阶段学习到的固定张量,会随模型一同发布。在推理开始前,模型参数会被提前加载至lctx中。
接下来我们开始解析计算图的结构,计算图的第一部分是将token转换为Embedding向量(embedding)。
Embedding向量是每个token的固定维度向量表示,相比纯整数形式,其更适合深度学习模型进行计算,因为Embedding向量能够捕捉单词的语义信息。Embedding向量的维度被称为模型维度(model dimension),不同模型的模型维度不同,例如LLaMA-7B的模型维度为n_embd=4096。
模型参数中包含一个token Embedding矩阵(token-embedding matrix),用于将token转换为Embedding向量。由于LLaMA的词汇表大小为n_vocab=32000,因此该矩阵的维度为32000×4096,矩阵的每一行对应一个token的Embedding向量:
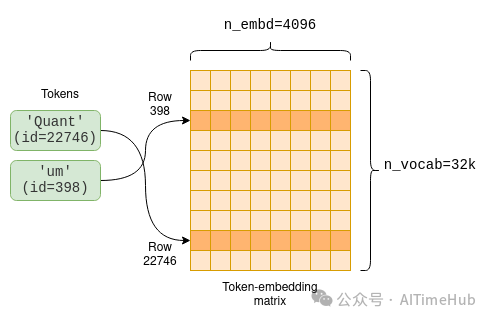
每个token的Embedding向量都是在模型训练阶段学习得到的,可通过token Embedding矩阵直接获取。
计算图的第一部分,会从token Embedding矩阵中提取每个输入token对应的行,生成新的矩阵:
// llama.cpp (做了简化处理)
static struct ggml_cgraph * llm_build_llama(/* ... */) {
// ...
struct ggml_tensor * inp_tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, n_tokens);
memcpy(
inp_tokens->data,
tokens,
n_tokens * ggml_element_size(inp_tokens)
);
inpL = ggml_get_rows(ctx0, model.tok_embeddings, inp_tokens);
}
//
上述代码的执行流程:
- 创建一个一维的整型张量
inp_tokens,用于存储数字形式的token序列;
- 将token值复制到该张量的
data指针指向的内存;
- 创建一个标识为
GGML_OP_GET_ROWS的张量运算,将token Embedding矩阵model.tok_embeddings与输入token序列结合。
该运算在实际执行时,会从token Embedding矩阵中提取对应行,生成一个新的n_tokens × n_embd维度的矩阵,该矩阵仅包含输入token的Embedding向量,且向量顺序与输入token的顺序一致:
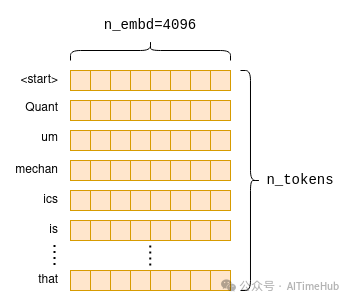
Embedding过程会为每个原始token生成一个固定维度的Embedding向量,这些向量按顺序堆叠后,就构成了提示词对应的Embedding矩阵。
变换器
计算图的核心部分是变换器(Transformer),这是一种神经网络架构,作为LLM的核心负责执行主要的推理逻辑。在本节中,我们将从工程视角解析Transformer的核心特性,重点讲解自注意力机制。
自注意力机制
先聚焦解析自注意力机制(self-attention)的核心逻辑,再从整体视角解析其在Transformer架构中的位置。
自注意力机制的作用是,接收一个token序列,生成该序列的紧凑向量表示,并在生成过程中考虑token之间的关联关系。这是LLM架构中唯一计算token间关联关系的模块,因此是模型实现语言理解的核心(语言理解的本质是理解单词间的关联)。由于该机制涉及跨token的计算,从工程视角来看也是最具研究价值的模块——尤其是当输入序列较长时,计算量会大幅增加。
自注意力机制的输入是n_tokens × n_embd维度的Embedding矩阵,矩阵的每一行(即每个向量)代表一个独立的token。每个Embedding向量会被进一步转换为三个不同的向量,分别称为键向量(key)、查询向量(query)和值向量(value)。该转换过程通过将每个token的Embedding向量,与模型参数中的固定矩阵wk、wq、wv分别相乘实现:
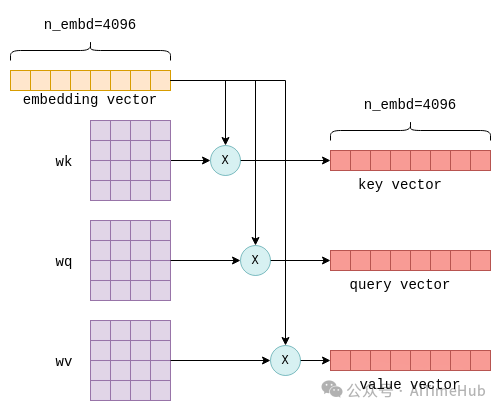
上述转换过程会对所有token执行(共n_tokens次),为提升效率,实际实现中不会通过循环逐一枚举token,而是通过矩阵乘法一次性完成所有行的转换,核心代码如下:
// llama.cpp (做了简化,忽略缓存的使用)
// `cur`为自注意力机制的输入
struct ggml_tensor * K = ggml_mul_mat(ctx0,
model.layers[il].wk, cur);
struct ggml_tensor * Q = ggml_mul_mat(ctx0,
model.layers[il].wq, cur);
struct ggml_tensor * V = ggml_mul_mat(ctx0,
model.layers[il].wv, cur);
执行完成后,会得到三个维度均为n_tokens × n_embd的矩阵K、Q、V,分别由所有token的键向量、查询向量、值向量按顺序堆叠而成。
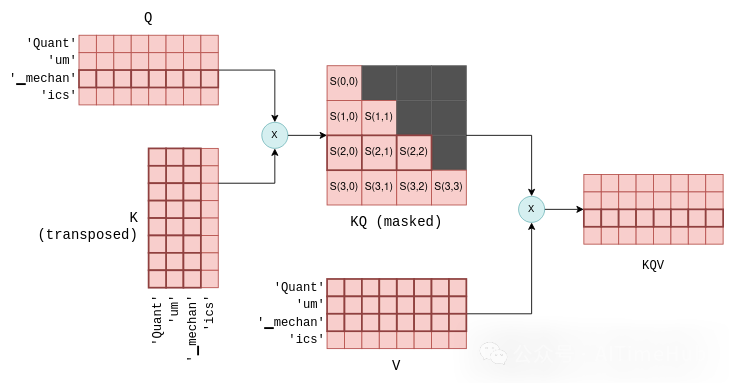
自注意力机制的下一步,是将存储查询向量的Q矩阵,与存储键向量的K矩阵的转置矩阵相乘。对于不熟悉矩阵运算的读者,该操作的本质是为每一对查询向量和键向量计算一个联合得分(joint score),我们用S(i,j)表示第i个查询向量与第j个键向量的得分。
该操作会生成n_tokens²个得分,所有得分会被整合为一个矩阵,称为KQ。随后,该矩阵会被掩码(mask)处理,移除对角线上方的所有元素:
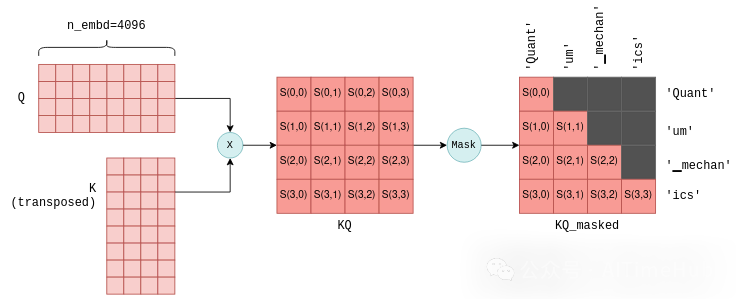
掩码操作是自注意力机制中的关键步骤,其作用是让每个token仅保留与前置token的得分。在模型训练阶段,该约束能确保LLM仅基于过往token预测下一个token,而非未来的token。此外,后续将详细讲解,该操作能为未来token的预测带来显著的优化空间。
自注意力机制的最后一步,是将掩码后的得分矩阵KQ_masked与之前得到的值向量矩阵V相乘。该矩阵乘法操作会生成所有前置token值向量的加权和,权重即为对应的得分S(i,j)。例如,对于第四个tokenics,该操作会生成Quant、um、▁mechan、ics这四个token值向量的加权和,权重为S(3,0)至S(3,3)——这些得分由ics的查询向量与所有前置token的键向量计算得到。
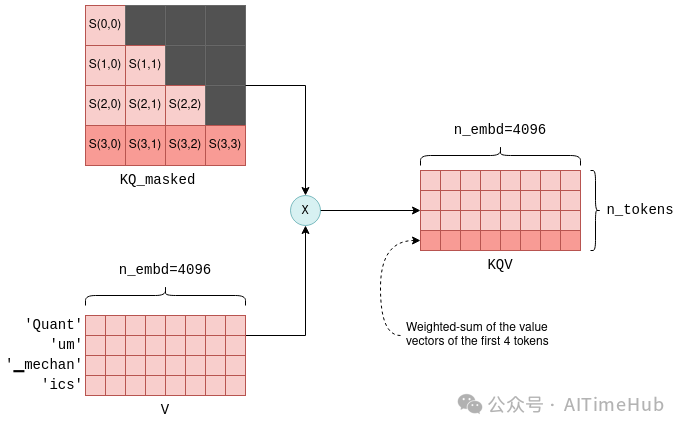
KQV矩阵的生成,标志着自注意力机制的计算完成。
自注意力机制是Transformer layer中的一个组件,除自注意力机制外,每个Transformer层还包含多个其他张量运算,其中大部分是前馈神经网络(feed-forward neural network)中的矩阵加法、乘法和激活函数运算。本文不会对这些运算做深入解析,仅需掌握以下核心要点:
- 前馈神经网络中会使用大型的固定参数矩阵,例如LLaMA-7B中,参数矩阵的维度为
n_embd × n_ff = 4096 × 11008。
- 除自注意力机制外,所有其他运算均为按行/按token执行的运算,如前文所述,只有自注意力机制涉及跨token的计算——这一点在后续讲解KV缓存时至关重要。
- 每个Transformer层的输入和输出维度均为
n_tokens × n_embd:一行对应一个token,每列对应模型维度的一个维度。
为保证内容的完整性,本文附上LLaMA-7B中单个Transformer层的结构示意图,需注意的是,未来的模型可能会对该架构做小幅调整。
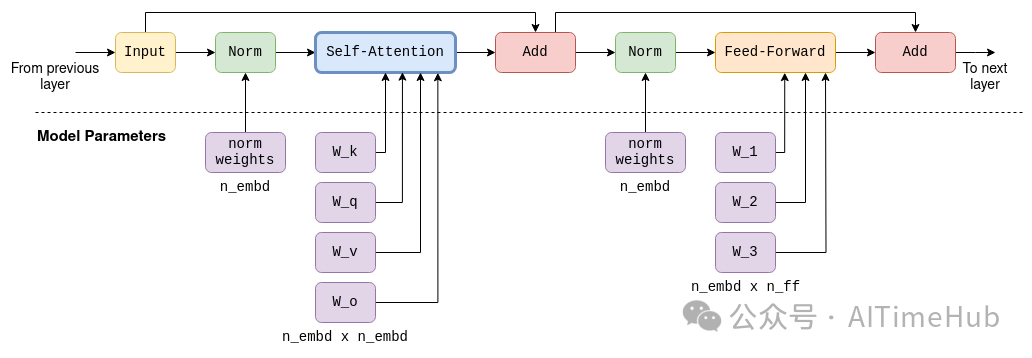
Transformer架构由多个层级串联组成,例如LLaMA-7B包含n_layers=32个层。所有层的结构完全相同,唯一的区别是每层拥有独立的参数矩阵(例如,每层的自注意力机制都有专属的wk、wq、wv矩阵)。第一层的输入为前文所述的Embedding矩阵,第一层的输出作为第二层的输入,依此类推。可以理解为,每层都会生成一个新的Embedding向量序列,只是此时的Embedding向量不再与单个token直接绑定,而是对token间关联关系的更复杂表示。
logits计算
Transformer的最后一步是计算对数几率(logits)。logit是一个浮点数值,代表某个token作为“正确”后续token的概率,logit值越高,该token成为正确后续token的概率越大。
logit的计算方式为:将Transformer最后一层的输出,与一个固定的n_embd × n_vocab维度的参数矩阵(在llama.cpp中也称为output矩阵)相乘,该操作会为词汇表中的每个token生成一个对应的logit值。例如,LLaMA的词汇表包含32000个token,因此会生成32000个logit值:
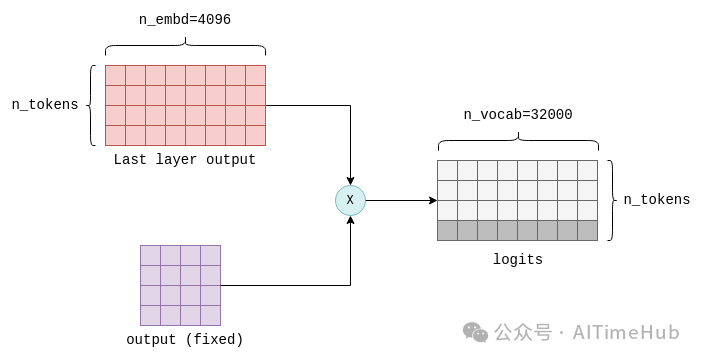
logits是Transformer的最终输出,其值反映了各个token作为下一个token的可能性。至此,所有张量计算均完成。以下是llm_build_llama()函数的简化注释版本,汇总了本节讲解的所有步骤:
// llama.cpp (做了简化和注释)
static struct ggml_cgraph * llm_build_llama(
llama_context & lctx,
const llama_token * tokens,
int n_tokens,
int n_past) {
ggml_cgraph * gf = ggml_new_graph(ctx0);
struct ggml_tensor * cur;
struct ggml_tensor * inpL;
// 创建存储token序列的张量
struct ggml_tensor * inp_tokens = ggml_new_tensor_1d(ctx0, GGML_TYPE_I32, N);
// 将token序列复制到张量中
memcpy(
inp_tokens->data,
tokens,
n_tokens * ggml_element_size(inp_tokens)
);
// 生成`Embedding`矩阵
inpL = ggml_get_rows(ctx0,
model.tok_embeddings,
inp_tokens);
// 迭代执行所有Transformer层的计算
for (int il = 0; il < n_layer; ++il) {
struct ggml_tensor * K = ggml_mul_mat(ctx0, model.layers[il].wk, cur);
struct ggml_tensor * Q = ggml_mul_mat(ctx0, model.layers[il].wq, cur);
struct ggml_tensor * V = ggml_mul_mat(ctx0, model.layers[il].wv, cur);
struct ggml_tensor * KQ = ggml_mul_mat(ctx0, K, Q);
struct ggml_tensor * KQ_scaled = ggml_scale_inplace(ctx0, KQ, KQ_scale);
struct ggml_tensor * KQ_masked = ggml_diag_mask_inf_inplace(ctx0,
KQ_scaled, n_past);
struct ggml_tensor * KQ_soft_max = ggml_soft_max_inplace(ctx0, KQ_masked);
struct ggml_tensor * KQV = ggml_mul_mat(ctx0, V, KQ_soft_max);
// 执行前馈网络计算
// 生成cur张量
// ...
// 将cur作为下一层的输入
inpL = cur;
}
cur = inpL;
// 根据最后一层的输出计算logits
cur = ggml_mul_mat(ctx0, model.output, cur);
// 构建并返回计算图
ggml_build_forward_expand(gf, cur);
return gf;
}
要执行实际的推理,需通过前文所述的ggml_graph_compute()函数,运行该函数返回的计算图。计算完成后,logits值会从最终张量的data指针中复制到浮点数组中,为下一步采样(sampling)做准备。
采样
得到所有logits值后,下一步是基于这些值选择下一个token,该过程被称为采样。目前有多种采样方法可供选择,适用于不同的使用场景。本节将讲解两种基础的采样方法,语法采样(grammar sampling)等更进阶的方法将在后续文章中介绍。
贪心采样
贪心采样(greedy sampling)是一种简单直接的采样方法,其逻辑为选择logit值最高的token。
以本文的示例提示词为例,logit值最高的几个token如下表所示:
| token |
logit |
| ▁describes |
18.990 |
| ▁provides |
17.871 |
| ▁explains |
17.403 |
| ▁de |
16.361 |
| ▁gives |
15.007 |
因此,贪心采样会确定性地选择▁describes作为下一个token。当需要对相同的提示词生成确定性的输出时,贪心采样是最佳选择。
温度采样
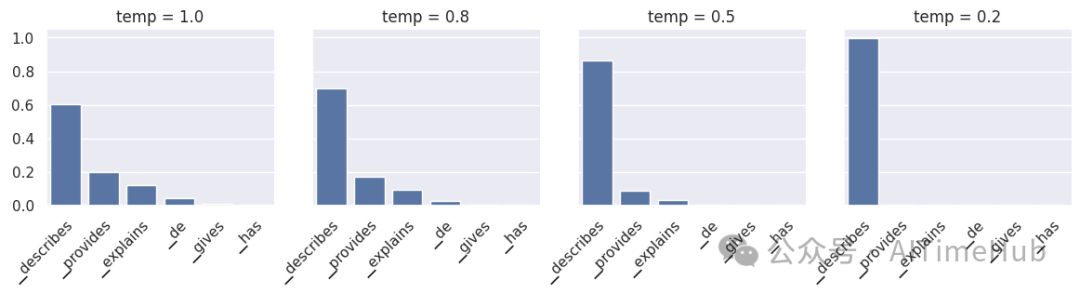
温度采样(temperature sampling)是一种概率性的采样方法,即对相同的提示词重新推理时,模型可能会生成不同的输出。该方法引入了一个名为温度(temperature)的参数,该参数为0到1之间的浮点数,用于调节输出的随机性,具体执行流程如下:
- 将所有logits值从高到低排序,并通过softmax函数做归一化处理,确保所有logits值的和为1——该转换会将每个logit值转换为对应的概率。
- 设置一个阈值(默认值为0.95),仅保留累计概率低于该阈值的top-k个token,该步骤会有效移除低概率token,避免采样到“无效”或“错误”的token。
- 将剩余token的logits值除以温度参数,再次做归一化处理,确保其和为1,得到最终的概率分布。
- 基于该概率分布随机采样一个token。例如,在本文的示例提示词中,token
▁describes的概率为0.6,意味着其被选中的概率约为60%,重新推理时可能会选中其他token。
步骤3中的温度参数,是调节输出随机性的核心:
- 低温度值:会抑制低概率token的选中概率,让模型在重新推理时更易选中相同的token,因此随机性更低;
- 高温度值:会“拉平”概率分布,提升低概率token的选中概率,让模型在重新推理时更易生成不同的token,因此随机性更高。
完成一个token的采样,标志着LLM一次完整迭代的结束。将采样得到的token追加至原token序列后,重新执行整个推理流程,模型的输出会不断作为新的输入,让token序列的长度每次增加1。
从理论上讲,后续的迭代过程可以完全复用初始流程,但随着token序列的不断变长,模型的推理性能会显著下降,因此需要引入特定的优化技术,下文将详细讲解。
推理过程的优化
当LLM的输入token序列变长时,Transformer的自注意力计算阶段会成为性能瓶颈:token序列越长,参与矩阵乘法的矩阵规模越大,而每次矩阵乘法都包含大量的数值运算,其运算量受限于GPU的浮点运算能力(flops)。解决该瓶颈最常用的优化技术是KV缓存(KV cache)。
KV缓存
回顾前文内容,每个token的Embedding向量会通过与参数矩阵wk、wv相乘,分别转换为键向量和值向量。KV缓存就是对这些键向量和值向量的缓存,通过缓存这些向量,可避免在每次迭代中重复计算,从而节省大量的浮点运算。
KV缓存的工作逻辑如下:
- 首次迭代:按前文所述的方式,计算所有输入token的键向量和值向量,并将其存入KV缓存。
- 后续迭代:仅需计算最新追加token的键向量和值向量,将缓存中的键/值向量与新计算的键/值向量拼接,即可得到当前迭代所需的
K矩阵和V矩阵。该方式避免了对所有历史token的键/值向量的重复计算,能带来显著的性能提升。
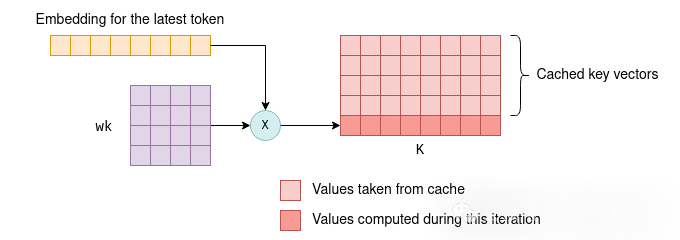
KV缓存的可行性,源于键/值向量在各次迭代中保持不变这一特性。例如,首次迭代处理4个token,第二次迭代处理5个token(新增1个),由于前4个token未发生变化,其对应的键/值向量在两次迭代中完全相同,因此第二次迭代无需重新计算前4个token的键/值向量。
该特性适用于Transformer的所有层级,而非仅第一层:在所有层级中,每个token的键/值向量仅依赖于其前置token,因此当新token被追加至序列后,历史token的键/值向量不会发生变化。
对于第一层,该特性很容易验证:token的键向量由其固定的Embedding向量与固定的wk矩阵相乘得到,因此无论后续追加多少token,历史token的键向量都不会改变,值向量同理。
对于第二层及之后的层级,该特性的逻辑稍复杂,但依然成立。要理解这一点,需回顾第一层自注意力机制的输出KQV矩阵:KQV矩阵的每一行都是一个加权和,其计算仅依赖于:
- 前置token的值向量;
- 由前置token的键向量计算得到的得分。
因此,KQV矩阵的每一行仅依赖于前置token,该矩阵经过若干按行执行的运算后,会作为第二层的输入。这意味着,后续迭代中,第二层的输入仅会新增对应新token的行,历史行保持不变。以此类推,该特性适用于Transformer的所有层级。
后续迭代的进一步优化
读者可能会疑惑,既然能缓存键/值向量,为何不同时缓存查询向量?答案是,在后续迭代中,除最新token的查询向量外,历史token的查询向量均无使用价值。结合KV缓存,自注意力机制实际仅需接收最新token的查询向量即可完成计算:
- 将该查询向量与缓存中的
K矩阵相乘,计算最新token与所有历史token的联合得分;
- 将得分结果与缓存中的
V矩阵相乘,仅计算KQV矩阵的最后一行。
事实上,在所有Transformer层中,后续迭代仅需传递1 × n_embd维度的向量,而非首次迭代中n_token × n_embd维度的矩阵。通过下方的示意图(后续迭代)与前文的首次迭代示意图对比,可更直观地理解这一点:
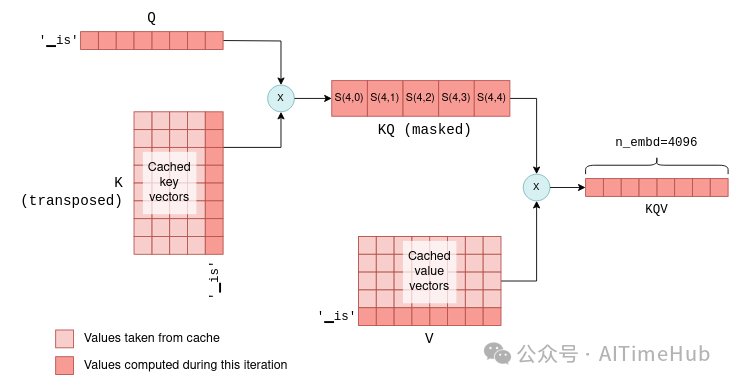
该计算过程会在Transformer的所有层级中重复,且每层都会使用其专属的KV缓存。最终,Transformer的输出为一个包含n_vocab个logit值的一维向量,用于预测下一个token。
该优化方式避免了计算KQ和KQV矩阵中无需使用的行,随着token序列的变长,能节省大量的浮点运算。
KV缓存的实际实现
我们可以通过llama.cpp的源码,解析KV缓存的实际实现方式。不出意外,KV缓存同样基于张量实现,分别用一个张量存储键向量,一个张量存储值向量:
// llama.cpp (做了简化处理)
struct llama_kv_cache {
// 存储键向量的缓存
struct ggml_tensor * k = NULL;
// 存储值向量的缓存
struct ggml_tensor * v = NULL;
int n; // 缓存中当前存储的token数量
};
初始化KV缓存时,会为每层分配足够的内存,用于存储512个键/值向量:
// llama.cpp (做了简化处理)
// n_ctx = 512 为默认值
static bool llama_kv_cache_init(
struct llama_kv_cache & cache,
ggml_type wtype,
int n_ctx) {
// 为每层分配可存储n_ctx个向量的元素空间
const int64_t n_elements = n_embd*n_layer*n_ctx;
cache.k = ggml_new_tensor_1d(cache.ctx, wtype, n_elements);
cache.v = ggml_new_tensor_1d(cache.ctx, wtype, n_elements);
// ...
}
回顾前文,推理过程中的计算图由llm_build_llama()函数构建,该函数有一个我们之前忽略的参数n_past,其作用如下:
- 首次迭代:
n_tokens为输入token的数量,n_past设为0;
- 后续迭代:
n_tokens设为1(仅处理最新的一个token),n_past为历史token的数量。
n_past参数的核心作用是,从KV缓存中提取对应数量的历史键/值向量。
以下是该函数中利用KV缓存计算K矩阵的核心代码,为便于理解,本文做了简化(忽略多头注意力)并添加了注释:
// llama.cpp (做了简化和注释)
static struct ggml_cgraph * llm_build_llama(
llama_context & lctx,
const llama_token * tokens,
int n_tokens,
int n_past) {
// ...
// 迭代执行所有Transformer层的计算
for (int il = 0; il < n_layer; ++il) {
// 计算最新token的键向量
struct ggml_tensor * Kcur = ggml_mul_mat(ctx0, model.layers[il].wk, cur);
// 在缓存的空闲位置,创建一个n_embd维度的视图
struct ggml_tensor * k = ggml_view_1d(
ctx0,
kv_cache.k,
// 视图大小
n_tokens*n_embd,
// 视图偏移量
(ggml_element_size(kv_cache.k)*n_embd) * (il*n_ctx + n_past)
);
// 将最新token的键向量复制到缓存的空闲位置
ggml_cpy(ctx0, Kcur, k);
// 通过缓存创建视图,生成当前迭代的K矩阵
struct ggml_tensor * K =
ggml_view_2d(ctx0,
kv_self.k,
// 行大小
n_embd,
// 行数
n_past + n_tokens,
// 步长
ggml_element_size(kv_self.k) * n_embd,
// 缓存偏移量
ggml_element_size(kv_self.k) * n_embd * n_ctx * il);
}
}
上述代码的执行流程:
- 计算最新token的键向量
Kcur;
- 根据
n_past参数找到KV缓存中的下一个空闲位置,创建对应的张量视图;
- 将新计算的键向量复制到该空闲位置;
- 从缓存中创建一个包含
n_past + n_tokens行的视图,作为当前迭代的K矩阵。
KV缓存是LLM推理优化的基础,需要注意的是,本文讲解的llama.cpp中的KV缓存实现版本(截至本文撰写时)并非最优版本。例如,该实现会提前分配大量内存,用于存储最大支持数量的键/值向量(本文中为512个)。vLLM等更先进的实现方案,会优化内存的使用效率,带来进一步的性能提升,这些进阶技术将在后续文章中介绍。此外,LLM领域的发展速度极快,未来大概率会出现更多更优的推理优化技术。
脚注
- ggml还提供了
ggml_build_backward()函数,该函数会从输出到输入反向计算梯度,仅用于模型训练阶段的反向传播,推理阶段不会使用。
- 该文章讲解的是编码器-解码器(encoder-decoder)模型,而LLaMA是纯解码器(decoder-only)模型——因其每次仅预测一个token,但二者的核心概念完全相同。
- 为简化说明,本文讲解的是单头自注意力机制,而LLaMA实际使用的是多头自注意力机制。该区别仅会让张量运算的实现更复杂,不会影响本文讲解的核心思想。
- 准确来说,
Embedding向量在输入自注意力机制前,会先经过一次归一化运算,对其值做缩放处理。为简化核心思想的讲解,本文省略了该步骤。
- 得分在与值向量矩阵相乘前,还会经过一次softmax运算,对得分做缩放处理,确保每一行的得分和为1。
参考
希望这篇通过llama.cpp源码进行的剖析,能帮助你更直观地理解大语言模型(LLM)推理过程的核心机制与关键优化。如果在实践中遇到问题,欢迎在云栈社区的技术论坛与更多开发者交流探讨。
 发表于 2026-3-10 20:40:40
|
查看: 327|
回复: 0
发表于 2026-3-10 20:40:40
|
查看: 327|
回复: 0
