近日,来自字节跳动 Seed 团队和清华大学智能产业研究院(AIR)的研究人员提出了一项名为“CUDA Agent”的新研究,在AI编程领域引发了广泛关注。研究人员成功训练了一个能够编写真正快速CUDA内核的模型,而不仅仅是能写出正确代码的模型。
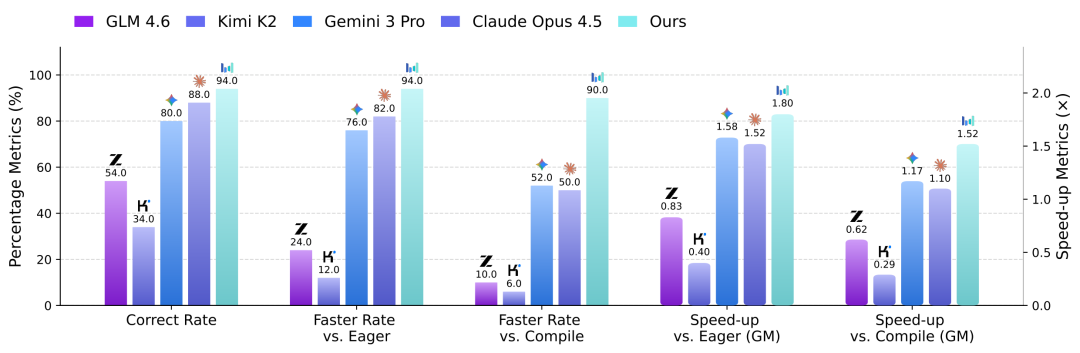
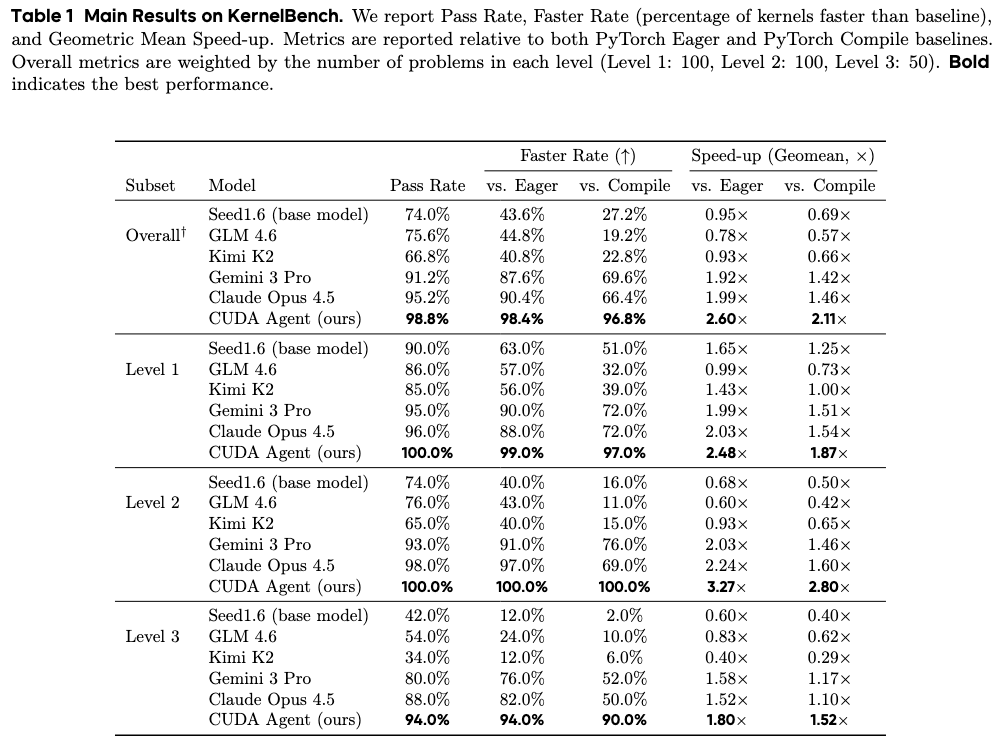
在简单和中等复杂度的内核任务上,其性能表现比 torch.compile 高出2倍;在复杂内核上,性能提升约92%;即使在最高难度的任务设置下,它的表现也比Claude Opus 4.5和Gemini 3 Pro等顶尖专有模型高出约40%。

此前,GPT、Claude等大模型已经能够生成语法正确的CUDA代码,并在一定程度上得到应用。然而,“能跑通”和“跑得快”是完全不同的概念。GPU内核优化是现代深度学习的基础,但这项工作高度专业化,需要深厚的硬件知识。现有的AI生成方案大多依赖于无训练的提示工程(Prompting)或多轮执行反馈微调。这种方法通常只能修复表面语法错误,难以触及底层的硬件逻辑,从而限制了其进行深度优化的内在能力。
真正极致的CUDA优化,需要处理的是性能分析器中才能看到的硬件级指标,比如线程束调度效率、内存带宽利用率和访存冲突。人们一直期待能出现一个像人类CUDA专家一样“思考”的AI。
针对这一矛盾,CUDA Agent的核心理念既简单又巧妙:CUDA代码的性能不取决于正确性,而取决于硬件执行效率。因此,研究人员不再仅仅奖励模型生成“可编译”的代码,而是直接奖励代码在GPU上的实际运行速度——使用真实的性能剖析数据,让强化学习算法基于性能提升进行训练。
这一思路带来了出乎预料的效果。在KernelBench基准测试中,CUDA Agent取得了当前最优的成绩:在Level-1、Level-2和Level-3三个难度划分上,相比torch.compile的加速比例(Faster Rate)分别达到了100%、100%和90%。
简而言之,CUDA Agent是一个大规模智能体强化学习系统,包含三个核心组成部分:一个可扩展的数据合成机制、一个集成了技能增强且具备可靠验证与性能分析能力的CUDA开发环境,以及用于稳定长上下文训练的强化学习算法。
此外,研究团队同步发布了CUDA-Agent-Ops-6K数据集。这是一个经过严格筛选与数据污染控制的高质量合成训练数据集,旨在支持基于强化学习的CUDA内核优化研究的复现与推进。
系统管线设计
数据合成
研究团队通过一个三阶段的管线来构建训练任务:种子问题爬取、基于LLM的组合式合成,以及基于执行结果的筛选。
- 种子问题爬取:从
torch 和 transformers 库中挖掘基础算子。每个算子都以一个Python类的形式表示,包含初始化和前向传播方法。
- 组合式合成:在此阶段,最多采样5个PyTorch算子,并将它们按顺序组合,构造成融合任务。
- 执行结果筛选:仅保留那些在Eager模式和Compile模式下都能正常运行的任务,并移除包含随机性的算子。为防止模型“投机取巧”,还剔除了在不同输入下输出为常数或无法区分的任务。同时,将Eager模式下的运行时间限制在1ms–100ms区间内,并移除与评估基准KernelBench高度相似的样本。
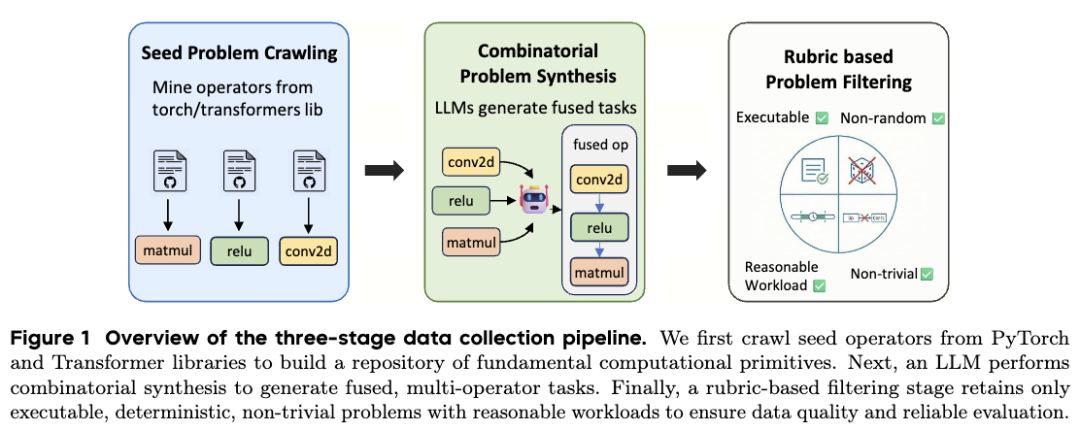
最终,团队整理得到了6000条训练样本,构建了CUDA-Agent-Ops-6K数据集。该数据集专为可扩展的强化学习训练设计,兼具广泛的任务多样性和较低的数据污染风险。
智能体环境
智能体循环管线遵循一种ReAct风格的工作流,它结合了代码工具与CUDA Skill规范(SKILL.md),支持迭代式的编码-编译-调试循环,以及基于性能分析器的优化过程。
- 标准工作流:对原生PyTorch实现进行性能分析,编写CUDA内核及其C++绑定代码,在GPU沙盒环境中完成编译与测试,并不断迭代优化。
- 目标要求:生成的内核必须通过正确性检查,并且性能需要相对于
torch.compile实现至少5%的加速。
- 稳健的奖励机制:采用基于里程碑的离散奖励设计,根据正确性达标情况和性能提升幅度分别给予奖励。
- 防作弊控制:采取了多项措施确保训练可靠性,包括对验证与性能分析脚本进行保护、禁止回退调用、使用5组不同输入进行正确性检查、在同步预热后进行性能分析,以及禁止网络检索。
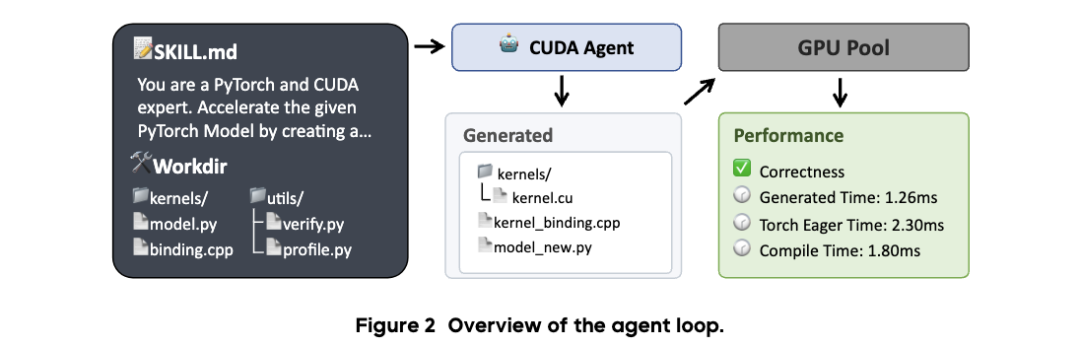
这些约束共同构建了一个可靠的、基于真实执行结果的反馈机制,使得策略学习能够聚焦于内核质量的实质性提升,而非依赖取巧或捷径行为。
训练流程
训练过程采用分阶段设计,以稳定CUDA代码生成这一长时序、高难度的强化学习任务。首先进行单轮PPO预热训练,随后分别初始化执行者(Actor)和评判者(Critic)模型,最后进入完整的多轮智能体强化学习阶段。
- 单轮预热阶段:旨在提升基础的CUDA代码生成能力,为后续的交互式智能体训练打下基础。
- Actor初始化:采用基于正向结果轨迹采样的拒绝式微调(RFT)。RFT过滤机制会剔除包含低效循环以及无效工具调用模式的轨迹,从而降低策略崩溃的风险。
- Critic初始化:通过价值函数预训练,使得从训练早期开始,对优势函数的估计就具备较高的可靠性。
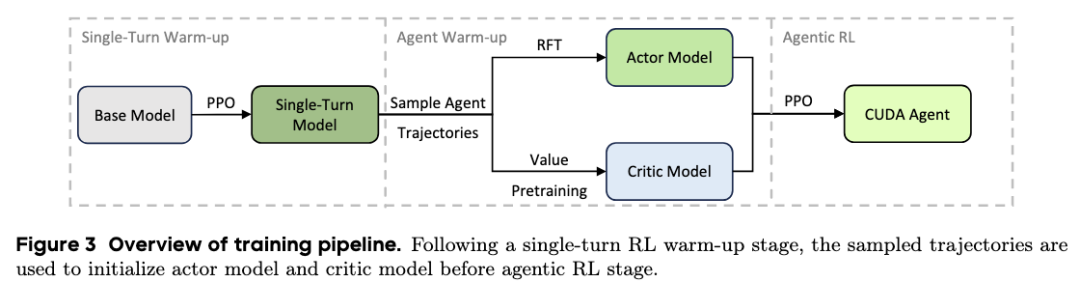
借助这一多阶段训练设计,系统在长上下文设定下(最长128K上下文,训练阶段最多150轮,评估阶段最多200轮)依然能保持稳定,从而实现持续且显著的奖励增长。
核心实验结果
研究团队在KernelBench基准上报告了整体和最高难度(Level-3)的完整指标,包括通过率(Pass Rate)、相对于PyTorch Eager和Compile的加速比例(Faster Rate),以及几何平均加速比(Speed-up)。

与强大的专有基线模型相比,CUDA Agent在性能优化上展现出显著优势:
- 整体性能:在KernelBench上,相对于
torch.compile的加速达成率(Faster Rate vs. Compile)高达96.8%,几何平均加速比达到2.11倍。
- 高难度任务优势:在最高难度的Level-3任务上,其相对于Compile的加速达成率达到90%,相比最强的专有基线(Claude Opus 4.5)高出约40个百分点。
- 中等难度任务表现:在Level-2的算子序列任务上,其加速达成率达到惊人的100%,几何平均加速比高达2.80倍。
这项研究也指出了两个主要局限。首先,目前尚未将CUDA Agent与更复杂的编译器框架(如TVM)进行对比。其次,训练流程依赖于大规模GPU资源池以及进程级隔离机制,带来了可观的计算与工程成本。探索更加资源高效的训练策略,将是未来的重要研究方向。
CUDA Agent等技术的出现,预示着传统编译器(如torch.compile或Triton)的优化瓶颈可能被打破。它证明了大型语言模型不仅可以学习人类自然语言和高级编程语言,还能够通过基于硬件反馈的强化学习,内化出极高门槛的“硬件直觉”。一条通向全自动、高性能计算基础设施的道路正在变得清晰。对这类前沿AI与系统优化交叉领域感兴趣的朋友,可以在云栈社区的智能&数据&云板块找到更多深度讨论和资源。
 发表于 2026-3-4 04:00:07
|
查看: 261|
回复: 0
发表于 2026-3-4 04:00:07
|
查看: 261|
回复: 0
