最近几周在研读 DeepSeek mHC 的相关论文并复现其经验,却得出了一个有趣的实验发现。
论文中一项关键的算法改进,是将残差混合矩阵 $H_l^{res}$ 通过 Sinkhorn-Knopp 算法约束到双随机矩阵流形上(manifold constraint),以此来稳定模型的前向与反向传播过程。
那么,这个“约束”真的是必需的吗?我们的实验表明:直接将 $H_l^{res}$ 替换为恒等矩阵(Identity),效果反而更优。
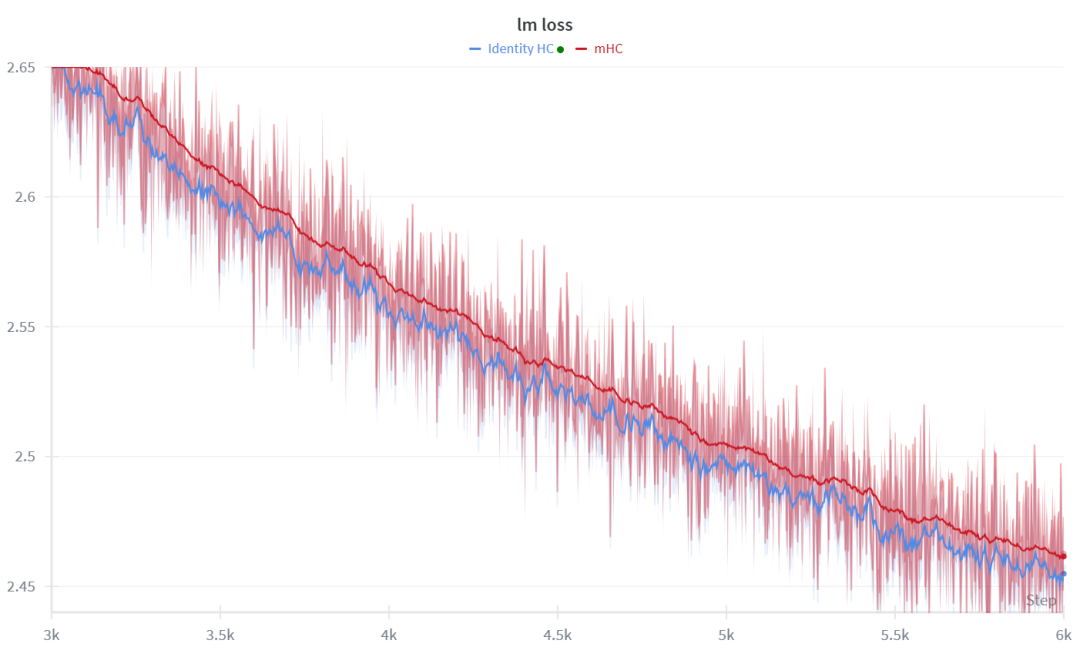
Qwen 1.7B 从头预训练(150B Tokens)局部曲线对比
当前的实验结论排序为:Identity HC > mHC > mHC lite > mHC orthogonal(例如使用 Cayley 变换的正交化)。实验在 Qwen3 1.7B 和 8B 的稠密模型上完成,训练了 150B tokens,以排除潜在框架Bug的影响。
恒等矩阵(对角线为1,其余为0),其行和与列和均为1,谱范数为1,本质上也是一种最简单的“流形约束”。直观上,$H_l^{res} = I$ 意味着各条残差流保留自身信息,不与其他流进行交换。
在实际训练的原版 mHC 模型中,我们观察到其学到的单层 $H_l^{res}$ 矩阵就接近这种模式:对角线元素约0.96,非对角线元素约0.01。然而,当这些矩阵进行多层累积连乘时,却会坍缩为一个全0.25的均匀混合矩阵。

mHC 模型的 $∏ H_l^{res}$ 矩阵可视化
这背后的数学原理在于:满足一致正性条件(所有元素有正的下界)的双随机矩阵,其 Dobrushin 遍历系数 $τ(H) < 1$。多层连乘后,其遍历系数以几何速率衰减 $τ(∏ H_l) ≤ ∏ τ(H_l)$,迫使所有行向量趋于一致,最终收敛到均匀矩阵。严格证明可参考 Dobrushin 遍历系数的次乘性。需要注意的是,如果矩阵序列是纯置换矩阵或可约的,则不满足此条件——但 Sinkhorn 算法输出的矩阵通常是严格正的,因此难以避免坍缩。
我们直接将 $H_l^{res}$ 设为恒等矩阵(Identity),相当于固定了其单层接近置换的行为,同时彻底消除了双随机矩阵连乘必然导致的 rank-1 均匀混合弊端。
一个值得探讨的问题是:$H_l^{res}$ 退化为置换矩阵(此处是恒等置换)究竟带来收益还是损害?实际上,mHC 中学到的 $H_l^{res}$ 在不同层可能是不同的近似置换矩阵(例如第一层是 $P_1$, 第五层是 $P_2$)。这些不同的置换连乘后,等价于一个新的置换。这意味着每一层都在对流进行重排,破坏了流在深度方向上的语义一致性(例如流1在第1层后变成流3,第5层后又变成流2)。$H_l^{pre}$ 和 $H_l^{post}$ 需要额外“追踪”每条流在被反复重排后的位置,增加了模型的学习难度。
相比之下,Identity 方案的优势在于所有层使用同一个恒等置换:
- 流0始终在位置0,流1始终在位置1,语义完全一致。
- $H_l^{pre}$ 和 $H_l^{post}$ 无需适应流重排,可直接学习“从哪条流读、往哪条流写”。
- 累积乘积 $∏ H_l^{res} = I$,既不会坍缩也不会引入混乱。
Identity 理应是最直观、最朴素的 $H_l^{res}$ 实现方式。考虑到该矩阵在 Transformer 架构中的关键性,对其进行充分的消融实验分析极具价值。
技术背景简述:从标准残差连接到 mHC
标准残差连接下的 Transformer 层更新公式为:
$x_{i+1} = x_i + f(x_i, W_i)$
Hyper-Connections (HC) 将残差流从1条扩展为 $n$ 条(默认 $n=4$),更新公式变为:
$x_{i+1} = H_l^{res} · x_l + H_l^{post} · f(H_l^{pre} · x_l, W_l)$
其中 $x_l$ 是 $n$ 条并行的残差流,三个可学习映射的作用如下:
| 映射 |
维度 |
作用 |
| $H^{pre}$ |
$n$ 流 → $1$ 流 |
从 $n$ 条流中读入信息并聚合 |
| $H^{post}$ |
$1$ 流 → $n$ 流 |
将变换后的信息写回到 $n$ 条流 |
| $H^{res}$ |
$n$ 流 → $n$ 流 |
负责流间的信息混合 |
DeepSeek mHC 的核心创新在于,将 $H_l^{res}$ 通过动态映射和 Sinkhorn-Knopp 算法约束到双随机矩阵流形上,以实现范数保持(norm preserving),确保多层 $H$ 连乘不会导致信号爆炸(但未保证信号不消失)。实验中 mHC 的谱范数大致在1附近。
mHC 论文中将计算过程表述得非常清晰(原HC论文表述相对晦涩),并将激活函数从 tanh 换为值域非负的 sigmoid,这是一个很好的改进。

mHC 核心计算过程
为什么 Sinkhorn 约束可能“弊大于利”?
论文中的 Sinkhorn 迭代计算开销不菲,但关键在于:$H_l^{res}$ 的双随机约束真的那么重要吗?实际上,跨流信息混合的关键机制在于投影(Projection)本身。
模型先将 $n$ 条残差流展平,然后全部投影到一个融合张量中,再拆分出 $H^{pre}$, $H^{post}$, $H^{res}$。即使 $H_l^{res} = I$,生成的 $H^{pre}$ 和 $H^{post}$ 也是 input-dependent 的,跨流信息融合已在投影步骤中发生。
以下是 Identity 模式下的简化计算流程示意:
输入: x_l = [s, b, n*C] (4 条流 flatten)
Step 1: φ 投影(跨流信息融合已在此发生)
x̂' · φ → [s, b, 2n] (identity 模式下只投影 2n=8 维)
φ 的输入包含了全部 4 条流的信息
Step 2: 激活
h_pre = sigmoid(α_pre · proj[:n] + b[:n]) ← 动态聚合权重
h_post = 2·sigmoid(α_post · proj[n:2n] + b[n:2n]) ← 动态扩展权重
Step 3: 聚合(跨流融合的显式体现)
aggregated = Σ h_pre_i · x_stream_i ← [s, b, C]
Step 4: 变换
output = f(aggregated) ← Attention 或 MLP
Step 5: 恒等残差 + 动态写回
x_{l+1} = I · x_l + diag(h_post) · f(...)
= x_l + diag(h_post) · f(...) ← 每条流独立保持残差
因此,对 $H_l^{res}$ 施加双随机约束可能不仅收益有限,甚至有害,因为双随机矩阵的累积乘积必然发生坍缩。根据 Perron-Frobenius 定理,双随机矩阵(非可约置换矩阵)的最大特征值 $\lambda_1 = 1$,其余特征值 $|\lambda| < 1$。$L$ 层累积乘积的最小奇异值满足:
$σ_min(∏_{l=1}^L H_l) ≤ ∏_{l=1}^L |λ_min(H_l)|$
当 $|λ_min(H_l)| < 1$ 时,该乘积会指数衰减至零。在 Qwen3-1.7B(28层,共56个HC模块)上的实验测得,Sinkhorn 版本 $H_l^{res}$ 的最小特征值均值约为0.49。粗略估算:
$σ_min ~ 0.49^56 ≈ 10^{-17}$
实测值与估算吻合。这意味着浅层信号经过数十个HC模块后,除均值方向外的信号很可能衰减殆尽。观察第一张累积 $H_res$ 热力图也可发现:大约10层之后,4条流的信息已完全同质化为均匀混合。
此外,使用20步 Sinkhorn-Knopp 迭代来近似投影到双随机流形,并不保证完全收敛。我们实测其行和的标准差约为0.12,该误差会在多层传播中累积。mHC-lite 论文也指出,约27.9%的 Sinkhorn 输入相对范围 $r > 4$,此时20步迭代后的列和偏差可达100%。
Identity 与 Sinkhorn 的简要对比
| 指标 |
Sinkhorn |
Identity |
| 累积乘积 |
rank-1 坍缩($κ ≈ 10^{12}$) |
$I$($κ = 1$) |
| 近似误差 |
行和 std = 0.12 |
精确 |
| 额外计算 |
20 步迭代 + 反向 recompute |
零 |
| 额外参数 |
$nC \times n^2$ 投影权重 |
无 |
| 信号传递 |
浅层信号指数衰减 |
无损传递 |
起初我们尝试了各种 mHC-lite 变体(如凸组合精确双随机、softmax加权等),但效果均不及原版 mHC。受启发后直接尝试 Identity 方案,结果出乎意料地好。我们也测试过正交化(Cayley变换、Givens旋转)以保证谱范数恒为1,但实验发现 $α_l^{res}$ 几乎不增长,且正交化允许负值,可能导致某些流信息被取反,引发模型容量坍缩和内部指标异常。
实验分析:层间通信模式
最后分享一些基于实验的分析图,揭示了模型内部有趣的信道通信模式。例如,mHC 中任意两层 $i$, $j$ 之间的有效信道大小 $c_{ij}$,用于衡量层 $i$ 的变换输出有多少信号能传递到层 $j$ 的变换输入。
$c_{ij} = h_j^{pre} · (Π_{k=i+1}^{j-1} H_k^{res}) · h_i^{post T}$
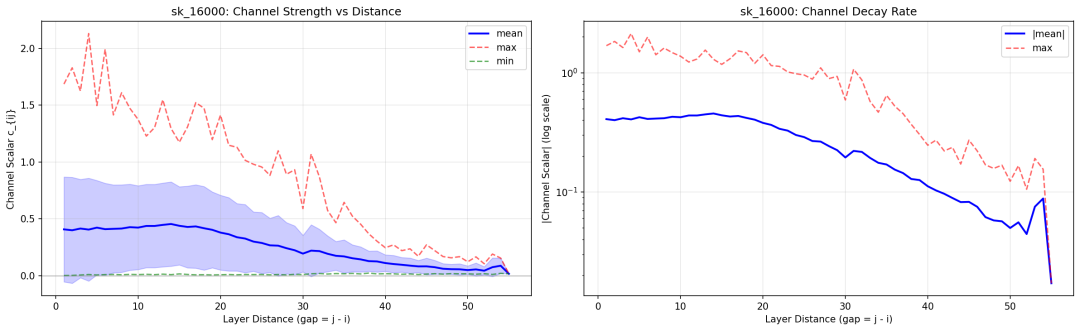
Layer gap 在 1-15 时,信道强度维持在 0.3~0.5;gap > 20 后明显衰减;在 log scale 下呈近似线性衰减
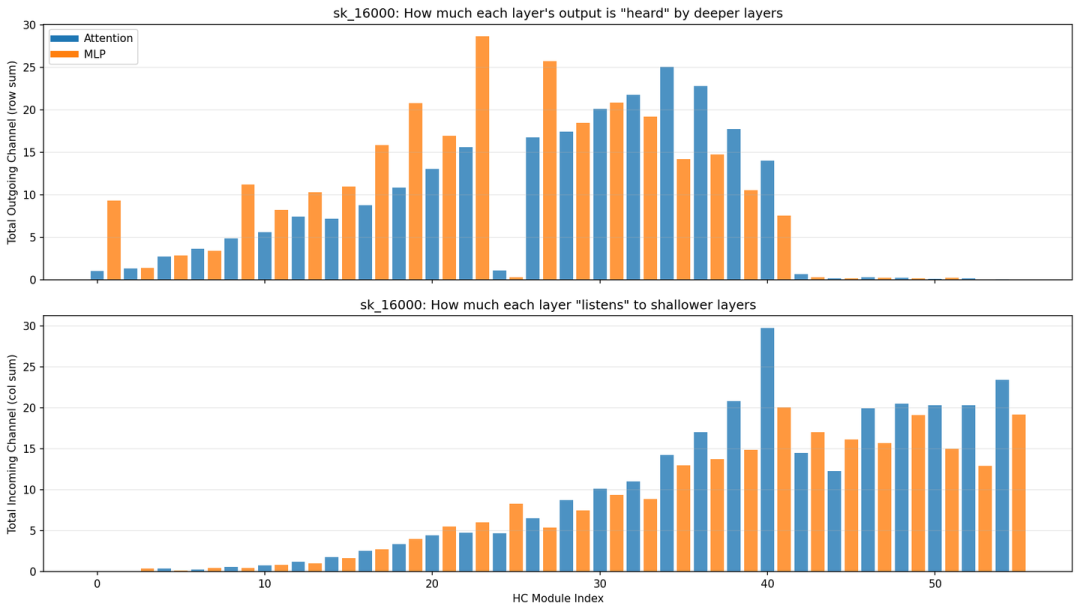
呈现“中间层辐射、深层汇聚”模式:模块 20-40 是核心信息枢纽,最后几层几乎不发射但大量接收,浅层信号较弱
当 $H_l^{res} = I$ 时,信道公式简化为:
$c_{ij} = h_j^{pre} · I · h_i^{post T} = h_j^{pre} · h_i^{post T}$
此时,任意两层间的直达通信强度仅取决于它们各自的 $h^{pre}$ 和 $h^{post}$,完全不受中间层 $H^{res}$ 累积衰减的影响。
结论
综上所述,将 DeepSeek mHC 中的“流形约束”(m)替换为古朴的恒等矩阵(Identity),在150B tokens的实测中取得了更优的效果。这一发现不仅简化了模型结构,降低了对底层计算基础设施的要求,也为理解超连接(Hyper-Connections)的工作机制提供了新的视角。对于热衷于模型底层优化和实验的开发者而言,这无疑是一个值得深入探讨和验证的切入点。更多前沿的模型训练技巧和开源项目实战分析,也欢迎在云栈社区交流讨论。
 发表于 2026-3-4 04:03:18
|
查看: 186|
回复: 0
发表于 2026-3-4 04:03:18
|
查看: 186|
回复: 0
