在机器学习的实际应用中,我们常常会遇到充满噪声、存在异常点以及呈现复杂非线性关系的数据。面对这些挑战,传统的回归模型有时会显得力不从心。那么,有没有一种方法能够在追求模型平滑性的同时,对“捣乱”的异常点保持一定的容忍度呢?
支持向量回归(SVR) 就是这样一类基于支持向量机思想的强大工具。它的核心思路非常直观:想象你在一条散点云(即样本点)上,想要拟合一条平滑的趋势线。但你并不希望这条线去盲目地“追逐”每一个点,尤其是那些可能是噪声的异常点。
于是,你可以画两条平行的“安全带”,这两条带子之间形成一个允许误差的容忍区间,我们称之为 ε-管(epsilon-tube)。SVR的目标就是找到一条函数曲线,让它尽量“夹在”这两个带子中间。它允许一些样本点落在带子之外,但对于这些“违规”行为会施加一定的惩罚。与此同时,这条拟合曲线本身也不能太过“弯曲”,以避免过拟合。
因此,SVR 的优化目标可以概括为:
- 让预测函数在大多数数据点上与真实值的偏差不超过 ε;
- 保持模型本身的复杂度尽可能小(通常通过最小化权重的范数来实现);
- 对于偏差超过 ε 的点,允许存在“松弛”(slack),并通过惩罚系数 C 来控制惩罚的强度。
最终,只有那些“紧贴着管子边缘”或者“越界”的点,才会真正影响模型参数的确定,这些点就被称为 “支持向量”。
理解了基本思想,我们就可以抓住SVR调参的三个关键点:
- ε:控制“容忍区间”的宽窄。ε 越大,模型越宽容、更平滑,支持向量数量通常越少;ε 越小,模型越严格,支持向量可能更多。
- C:控制对“违规”(超出ε管)的惩罚力度。C 越大,模型越倾向于减少训练误差(但可能增加过拟合风险);C 越小,模型更偏向于保持结构简单。
- 核函数:为了处理非线性关系,SVR可以运用核技巧,将数据映射到高维特征空间,再在那个空间中进行线性拟合。
数学表述
经典的 ε-SVR 原始优化问题可以表述为:
$$\min_{w,b,\xi_i,\xi_i^*} \frac{1}{2}||w||^2 + C\sum_{i=1}^{n}(\xi_i + \xi_i^*)$$
$$s.t.\quad y_i - (w^T x_i + b) \le \epsilon + \xi_i$$
$$(w^T x_i + b) - y_i \le \epsilon + \xi_i^*$$
$$\xi_i, \xi_i^* \ge 0$$
其等价的无约束形式(使用 ε-不敏感损失)为:
$$\min_{w,b} \frac{1}{2}||w||^2 + C\sum_{i=1}^{n}L_\epsilon(y_i - (w^T x_i + b))$$
其中 $L_\epsilon(r) = \max(0, |r| - \epsilon)$,被称为 ε-不敏感损失。这个损失函数的特点是:当误差绝对值小于 ε 时不施加任何惩罚(损失为0);只有当误差超过 ε 时,才对超出部分进行线性惩罚。
对于复杂的非线性场景,我们可以使用核技巧,通过一个映射函数 $\phi(x)$ 将数据投射到高维空间,然后在该空间执行线性SVR。另一种高效的近似方法是使用随机傅里叶特征(RFF),它能将RBF核近似为一个显式的特征映射,从而让我们可以用标准的线性模型(甚至神经网络)来进行训练。
实战案例
我们的目标是使用一组具有明显非线性趋势并叠加了噪声的数据,来比较两种SVR实现方式的效果:
- 线性 SVR:直接在原始一维特征上训练,使用 ε-不敏感损失和 L2 正则化。
- RFF-SVR:首先使用随机傅里叶特征来近似RBF核,将数据映射到高维特征空间,然后再进行线性SVR拟合。
我们将通过完整的代码和可视化图表,深入分析模型的拟合效果、支持向量的分布以及残差情况。许多开发者会在像 云栈社区 这样的技术论坛上交流类似的机器学习实战心得。
生成数据(非线性 + 异方差噪声)
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import seaborn as sns
torch.manual_seed(42)
np.random.seed(42)
# 生成一维输入,目标是一个非线性函数(例如:sin + polynomial)
n = 300
x = np.linspace(-3, 3, n)
# 真实函数
y_true = np.sin(1.5 * x) + 0.3 * x**2
# 添加异方差噪声(噪声随 x 变化)
noise = 0.3 * (1 + 0.5 * np.abs(x)) * np.random.randn(n)
y = y_true + noise
# 转成 PyTorch 张量
X = torch.tensor(x.reshape(-1,1), dtype=torch.float32)
Y = torch.tensor(y.reshape(-1,1), dtype=torch.float32)
定义 ε-不敏感损失(支持向量回归的核心损失)
class EpsilonInsensitiveLoss(nn.Module):
def __init__(self, epsilon=0.1):
super().__init__()
self.epsilon = epsilon
def forward(self, y_pred, y_true):
# |r| - eps 取正部分
residual = torch.abs(y_true - y_pred) - self.epsilon
# ReLU 相当于 max(0, residual)
loss = torch.mean(torch.relu(residual))
return loss
线性 SVR 模型(原始特征)
class LinearSVR(nn.Module):
def __init__(self, in_dim=1):
super().__init__()
self.linear = nn.Linear(in_dim, 1)
def forward(self, x):
return self.linear(x)
RFF(随机傅里叶特征)用于近似 RBF 核
class RandomFourierFeatures(nn.Module):
def __init__(self, input_dim=1, n_features=500, gamma=1.0):
super().__init__()
self.n_features = n_features
# 权重采样,RBF kernel: p(w) ~ N(0, 2*gamma I)
self.W = nn.Parameter(torch.randn(input_dim, n_features) * np.sqrt(2*gamma), requires_grad=False)
self.b = nn.Parameter(torch.rand(n_features) * 2 * np.pi, requires_grad=False)
self.scale = np.sqrt(2.0 / n_features)
def forward(self, x):
# x: (n, input_dim)
projection = x @ self.W + self.b # (n, n_features)
return self.scale * torch.cos(projection)
RFF-SVR 模型(RFF映射 + 线性层)
class RFF_SVR(nn.Module):
def __init__(self, input_dim=1, rff_features=500, gamma=1.0):
super().__init__()
self.rff = RandomFourierFeatures(input_dim, rff_features, gamma)
self.linear = nn.Linear(rff_features, 1)
def forward(self, x):
z = self.rff(x)
return self.linear(z)
训练函数(包含 L2 正则项)
def train_svr(model, X, Y, epochs=1000, lr=1e-2, C=1.0, epsilon=0.1):
opt = optim.Adam(model.parameters(), lr=lr)
loss_fn = EpsilonInsensitiveLoss(epsilon)
history = []
for ep in range(epochs):
model.train()
opt.zero_grad()
y_pred = model(X)
loss_epsilon = loss_fn(y_pred, Y)
# L2 正则(we only regularize weights, not bias)
l2 = 0.0
for name, param in model.named_parameters():
if "bias" in name:
continue
l2 = l2 + torch.sum(param ** 2)
# SVR 目标: 1/2 ||w||^2 + C * sum L_eps
loss = 0.5 * l2 + C * loss_epsilon * X.shape[0] # 注意损失平均/求和尺度
loss.backward()
opt.step()
history.append(loss.item())
return history
在上式中,我们使用了原始目标函数的一个近似形式:$\frac{1}{2}||w||^2 + C \sum L_\epsilon$。为了确保与批次大小无关,我们将平均后的损失 $L_\epsilon$ 乘回了样本数 $N$ 来进行平衡。
训练两个模型并获取预测结果
# 超参数
epsilon = 0.2
C = 10.0
epochs = 1200
lr = 5e-3
# 线性 SVR
lin_model = LinearSVR()
hist_lin = train_svr(lin_model, X, Y, epochs=epochs, lr=lr, C=C, epsilon=epsilon)
with torch.no_grad():
y_pred_lin = lin_model(X).numpy()
# RFF-SVR(近似 RBF)
rff_model = RFF_SVR(input_dim=1, rff_features=800, gamma=0.8)
hist_rff = train_svr(rff_model, X, Y, epochs=epochs, lr=lr, C=C, epsilon=epsilon)
with torch.no_grad():
y_pred_rff = rff_model(X).numpy()
识别支持向量
在我们的原始形式实现中,支持向量是那些预测偏差大于或等于(接近) ε 容忍带的点。
with torch.no_grad():
err_lin = np.abs(Y.numpy().flatten() - y_pred_lin.flatten())
sv_mask_lin = err_lin >= (epsilon - 1e-6) # 接近或超出管子
err_rff = np.abs(Y.numpy().flatten() - y_pred_rff.flatten())
sv_mask_rff = err_rff >= (epsilon - 1e-6)
可视化与分析
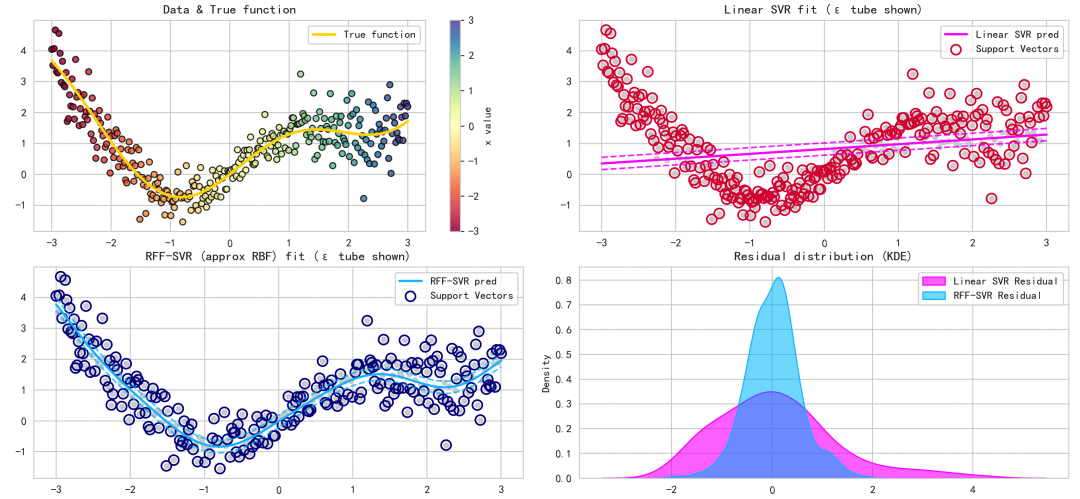
接下来,我们通过一组可视化图表来对比分析两个模型的性能。
xx = x
ytrue = y_true
plt.figure(figsize=(12,8))
# 图1: 原始数据 + 真实函数
plt.subplot(2,2,1)
plt.scatter(xx, y, c=xx, cmap='Spectral', s=30, edgecolor='k', alpha=0.8)
plt.plot(xx, ytrue, color='gold', linewidth=2.5, label='True function')
plt.title('Data & True function')
plt.colorbar(label='x value')
plt.legend()
# 图2: 线性 SVR 拟合与 epsilon tube 和支持向量
plt.subplot(2,2,2)
plt.scatter(xx, y, c='lightgray', s=20)
plt.plot(xx, y_pred_lin, color='magenta', linewidth=2, label='Linear SVR pred')
plt.plot(xx, y_pred_lin + epsilon, color='magenta', linestyle='--', alpha=0.7)
plt.plot(xx, y_pred_lin - epsilon, color='magenta', linestyle='--', alpha=0.7)
# 支持向量
plt.scatter(xx[sv_mask_lin], y[sv_mask_lin], facecolors='none', edgecolors='crimson', s=80, linewidths=1.5, label='Support Vectors')
plt.title('Linear SVR fit (ε tube shown)')
plt.legend()
# 图3: RFF-SVR 拟合与 epsilon tube 和支持向量
plt.subplot(2,2,3)
plt.scatter(xx, y, c='lightgray', s=20)
plt.plot(xx, y_pred_rff, color='deepskyblue', linewidth=2, label='RFF-SVR pred')
plt.plot(xx, y_pred_rff + epsilon, color='deepskyblue', linestyle='--', alpha=0.7)
plt.plot(xx, y_pred_rff - epsilon, color='deepskyblue', linestyle='--', alpha=0.7)
plt.scatter(xx[sv_mask_rff], y[sv_mask_rff], facecolors='none', edgecolors='darkblue', s=80, linewidths=1.5, label='Support Vectors')
plt.title('RFF-SVR (approx RBF) fit (ε tube shown)')
plt.legend()
# 图4: 残差分布比较
plt.subplot(2,2,4)
res_lin = (Y.numpy().flatten() - y_pred_lin.flatten())
res_rff = (Y.numpy().flatten() - y_pred_rff.flatten())
sns.kdeplot(res_lin, fill=True, label='Linear SVR Residual', color='magenta', alpha=0.5)
sns.kdeplot(res_rff, fill=True, label='RFF-SVR Residual', color='deepskyblue', alpha=0.5)
plt.title('Residual distribution (KDE)')
plt.legend()
plt.tight_layout()
plt.show()
结果解读
-
原始数据与真实函数: 数据清晰地呈现出非线性趋势(正弦叠加二次项),并且噪声的幅度随 x 增大而增加(异方差性)。这为线性模型设置了不小的挑战。
-
线性 SVR: 正如所料,线性SVR的拟合结果是一条直线。它完全无法捕捉数据的弯曲形态,在曲线的峰值和谷值区域误差非常大。
- ε-容忍带(紫色虚线)是两条平行线。
- 支持向量(红色圆圈)广泛分布在误差较大的区域以及ε边界上。由于模型表达能力有限,相当多的样本点都成为了影响模型的支持向量。
-
RFF-SVR: 通过随机傅里叶特征映射,RFF-SVR成功拟合了数据的非线性结构,其预测曲线(深蓝色实线)非常贴近真实的黄金曲线。
- ε-容忍带(浅蓝色虚线)能够跟随预测曲线的形状弯曲。
- 支持向量(深蓝色圆圈)数量相对较少,主要集中分布在函数变化剧烈或噪声异常明显的区域,这体现了SVR的稀疏性特点。
-
残差分布: 从核密度估计(KDE)图可以直观看出:
- RFF-SVR的残差分布(蓝色)更窄、峰更高,意味着其预测误差更小且更集中。
- 线性SVR的残差分布(粉色)更宽,存在较多较大的预测误差。
调参建议
- 选择 ε: ε 是模型稀疏性的主要控制器。增大 ε 会得到更平滑的模型和更少的支持向量,但可能引入更大的偏差。减小 ε 会使模型尝试拟合更多细节,支持向量增多,过拟合风险上升。
- 选择 C: C 是模型复杂度和训练误差之间的权衡参数。较大的 C 意味着对误差的惩罚更重,模型会努力减小训练误差(可能牺牲泛化能力)。较小的 C 则允许更多误差,模型倾向于更简单的解。
- 核函数选择: RBF(高斯)核在大多数非线性问题上表现优异,但其性能对核宽度参数 γ 非常敏感。使用随机傅里叶特征(RFF) 是一种将非线性核方法“线性化”的有效策略,它不仅便于利用像PyTorch这样的深度学习框架进行训练,还能轻松扩展到海量数据集。
- 数据标准化: 对于RBF等基于距离的核函数,输入特征的尺度至关重要。在训练前对数据进行标准化或归一化处理通常是一个好习惯。
- 解读支持向量: 支持向量是构成最终模型的关键样本。分析它们的分布位置,可以帮助我们理解数据中哪些部分对模型来说是最具挑战性或信息量最大的。这正是支持向量机模型可解释性的一个体现。
总结
支持向量回归(SVR)通过其独特的 ε-不敏感损失函数 和 权重正则化 机制,完美地实现了“在容忍带内寻找最平滑拟合”的理念。它不仅拥有坚实的理论根基,还具备良好的稀疏性(仅依赖少量支持向量),并对数据中的噪声和异常点表现出较强的鲁棒性。
面对非线性关系,我们可以灵活运用核技巧或 RFF近似 将问题转换到高维线性空间求解。结合现代深度学习工具(如 PyTorch),SVR 的实现和扩展变得异常便捷。
在实际应用中,成功调参的关键在于理解 ε、C 以及核参数(如RBF的 γ)之间的相互作用,并通过交叉验证等方法来找到它们的最佳组合。希望本文的讲解和实战案例能帮助你更好地掌握这一强大的回归工具。如果你对这类机器学习算法的原理与实现有更浓厚的兴趣,欢迎在技术社区中进行更深入的讨论与交流。
 发表于 2026-3-5 10:17:44
|
查看: 105|
回复: 0
发表于 2026-3-5 10:17:44
|
查看: 105|
回复: 0
