最近,Meta AI 的两篇新论文揭示了大型语言模型自我改进的全新路径:它们不再仅仅依赖人类标注的数据,而是开始尝试自己当“老师”,通过自生成课程来教自己。一篇研究聚焦于微调阶段的 SOAR 框架,另一篇则关注预训练阶段的“自我净化”机制。这两项工作共同指向一个方向:模型或许能主动克服自身的学习瓶颈。
| 论文 |
核心问题 |
关键招数 |
| SOAR 《Teaching Models to Teach Themselves》 |
预训练模型在“完全不会”的数学难题上(0/128 成功率)无法获得 RL 训练信号 |
用「老师-学生」非对称自博弈 + 元强化学习,让老师自学生成垫脚石题目并以学生真实进步为奖励 |
| Self-Improving Pretraining |
传统“下一个 token”预训练无法纠正低质、不安全、幻觉数据,后训练也难彻底修复 |
把预训练改造成「前缀-后缀」序列生成任务;用已后训的强模型当「裁判+改稿人」,通过在线 RL 实时重写或筛选后缀 |

SOAR:模型自己当“出题老师”
痛点:稀疏奖励 = 零信号
当模型在 MATH、HARP 等竞赛级数学难题上表现极差时(例如 Llama-3.2-3B 模型对某个问题128 次采样全错),传统的强化学习微调方法(如 RLVR)将无法获得任何正向奖励信号,训练进程会直接停滞。
图 1:直接训练 vs SOAR 自生成课程
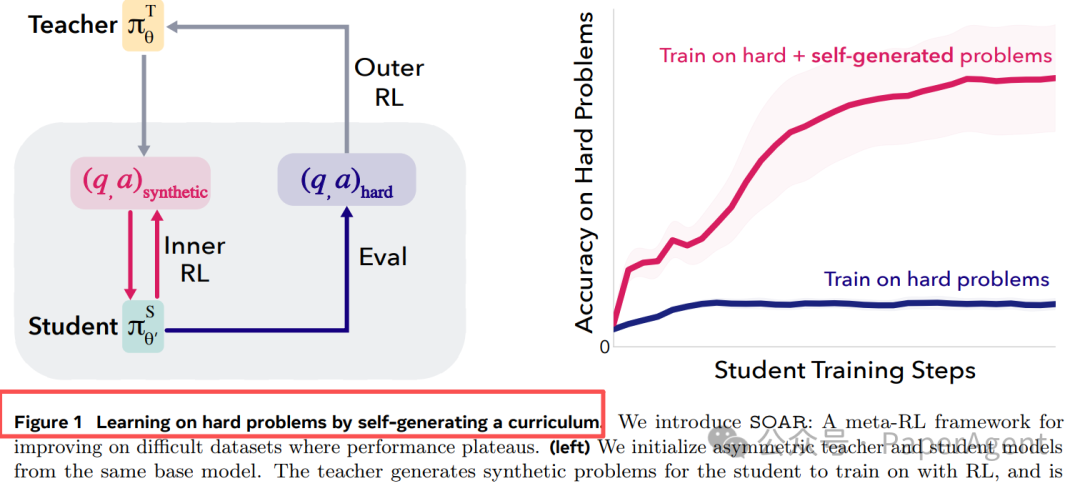
解法:双层元 RL 把「学生进步」当奖励
SOAR 的核心是设计了一个非对称的自博弈框架:一个“老师”模型负责生成题目,一个“学生”模型负责解题,并通过元强化学习将学生的真实进步作为老师的奖励。
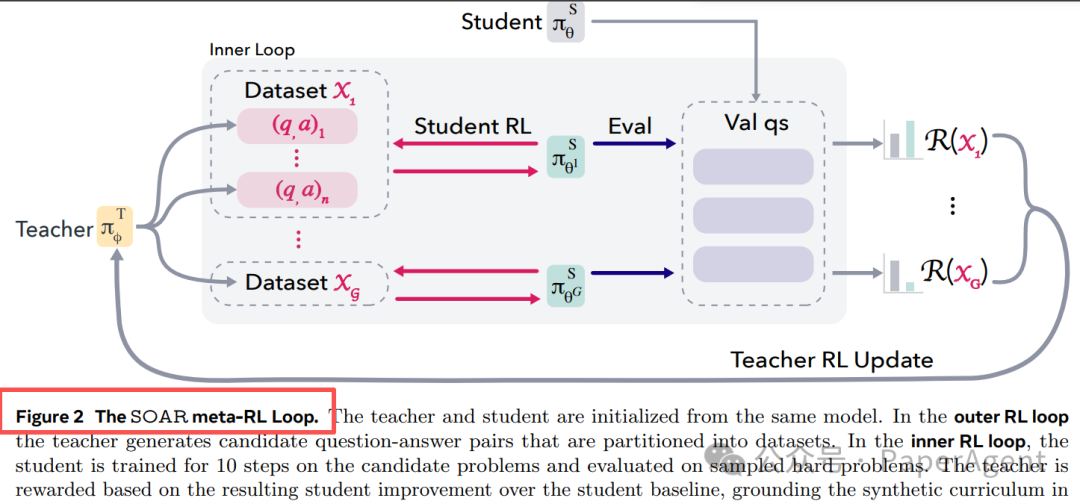
| 角色 |
任务 |
奖励来源 |
| Teacher π^T_φ |
生成 (question, answer) 对 |
学生在真实难题上的准确率增量 |
| Student π^S_θ |
解答老师生成的题 |
标准 RLVR(用 math-verify 判题) |
外层循环用 RL 更新老师;内层循环用 RL 更新学生。关键在于,老师看不到原始难题,只能观察“学生解答真实难题时有没有进步”,从而迫使老师学会生成对学生真正有帮助的“垫脚石”题目。
关键发现
- “会出题”≠“会做题”:老师模型自己依然解不出那些原始难题,但它能成功产出可学习的中间题目。
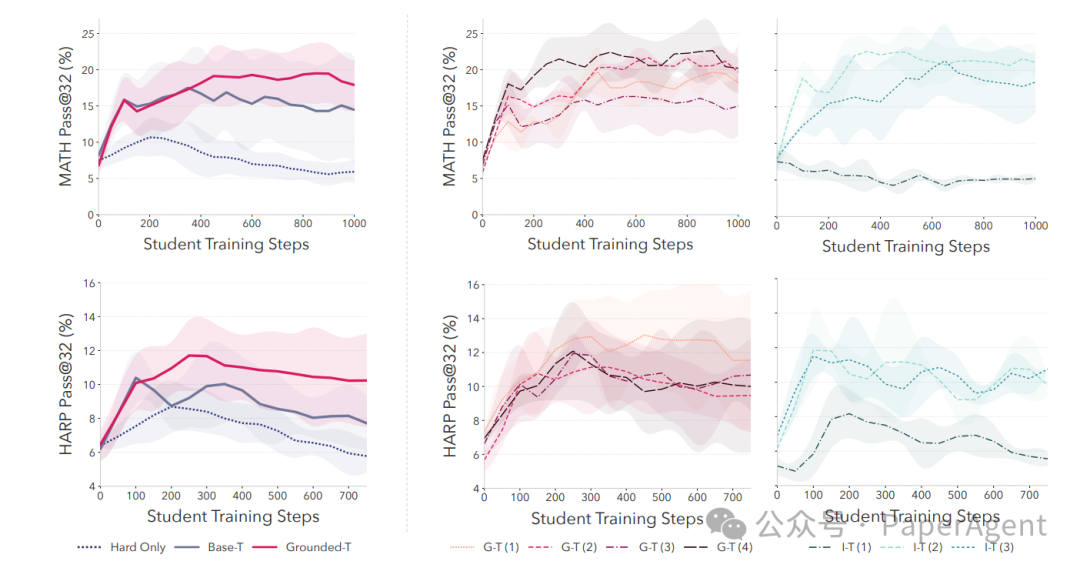
- Grounded Reward >> Intrinsic Reward:
- 使用“可学习性”或“多数投票”等内在指标作为奖励的方法(Intrinsic-T)会迅速导致生成的题目多样性崩塌(Vendi Score 从 34 骤降至 10)。
- 而使用“学生进步”作为接地奖励的 Grounded-T 方法,不仅能保持题目多样性,训练曲线也更稳定。
- 题目结构 > 答案正确:SOAR 生成的题目中,仅 32.8% 的答案完全正确,但 63% 的题目在“数学结构上是良构的”。这说明,提供有效学习梯度的关键在于题目的结构,而非完美的答案。
图 5:Grounded 奖励带来更稳定、高方差的学生提升曲线
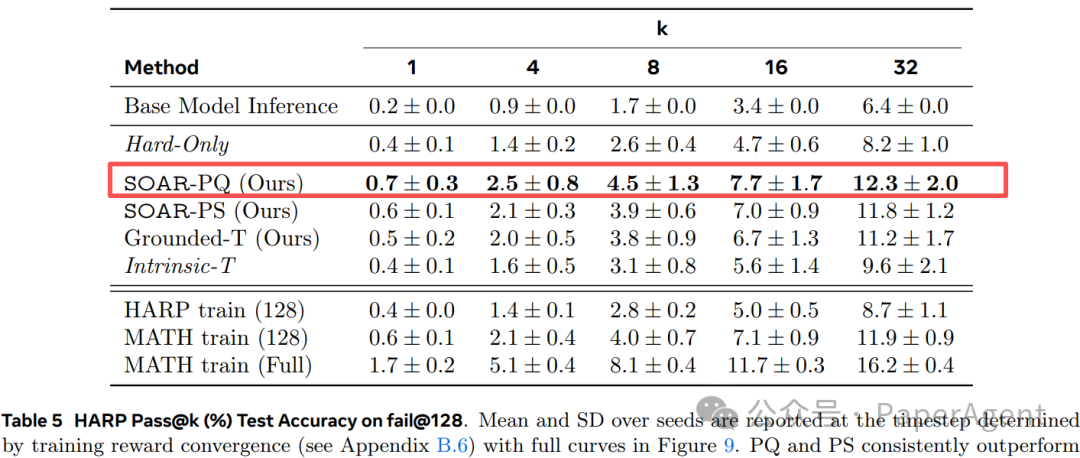
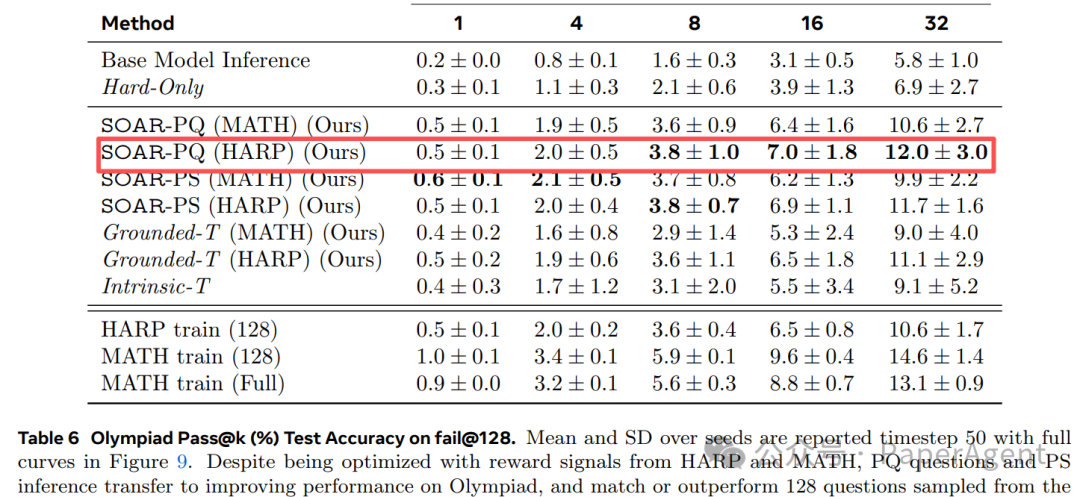
数据结果
| 数据集 |
方法 |
pass@32 提升(vs Hard-Only) |
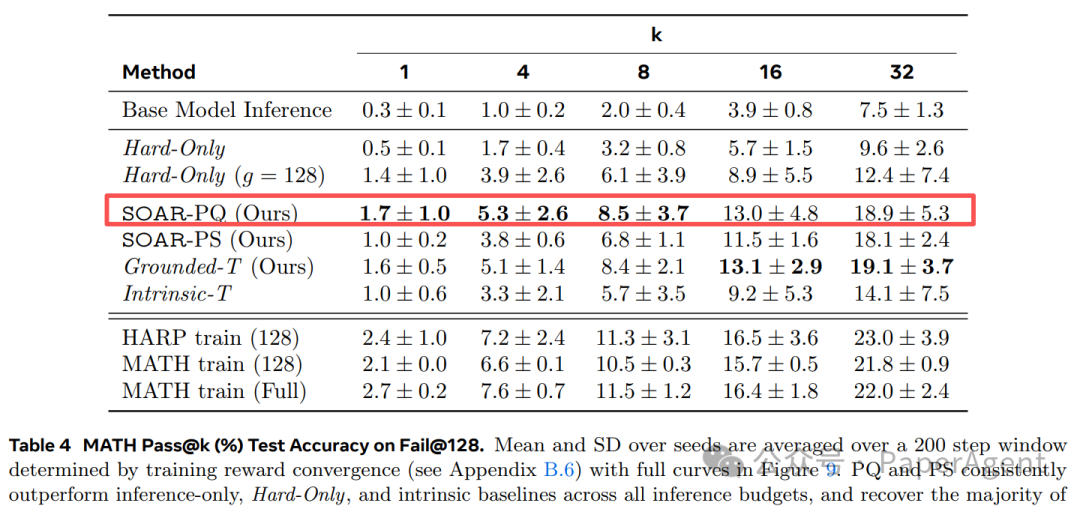
| MATH fail@128 |
SOAR-PQ |
+9.3% (绝对 18.9%) |
| HARP fail@128 |
SOAR-PQ |
+4.2% (绝对 12.3%) |
| OlympiadBench (OOD) |
PQ-MATH |
+6.0% |
表 4-6 详细结果
论文链接:
https://arxiv.org/pdf/2601.18778
Teaching Models to Teach Themselves: Reasoning at the Edge of Learnability
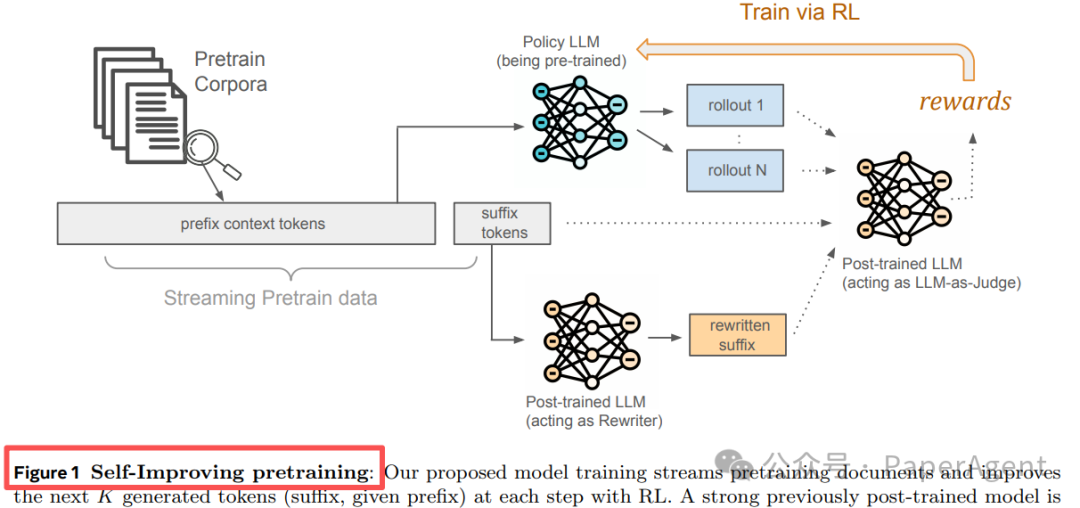
预训练阶段就自我净化

思路:把“下一个 token”换成“下一段序列”
传统预训练的目标是预测下一个 token,这难以纠正已习得的低质量或有害模式。新范式将其扩展为生成一小段连续的 token 序列(后缀),并引入一个已后训练的强模型作为“裁判”和“改稿人”进行实时质量干预。
图 1:Self-Improving Pretraining 流水线
训练配方
| 组件 |
做法 |
| Judge |
Llama-3.1-8B-Instruct 微调 或 GPT-OSS-120B 直接 prompt |
| Rewriter |
同上,专门练“安全复制”或“去幻觉” |
| Policy 更新 |
Online DPO(16 rollouts)或 RF-NLL |
| 数据 |
SlimPajama(高质量)/ RedPajama(含风险) |
结果速览
| 指标 |
持续预训练提升(vs 下一 token 基线) |
| Generation Quality Win-Rate |
86.3 % |
| Factuality(平均) |
+36.2 % |
| Safety(平均) |
+18.5 % |
| 标准基准(MMLU 等) |
不降反升,最高 +3.4 pts |
Table-1 详细结果
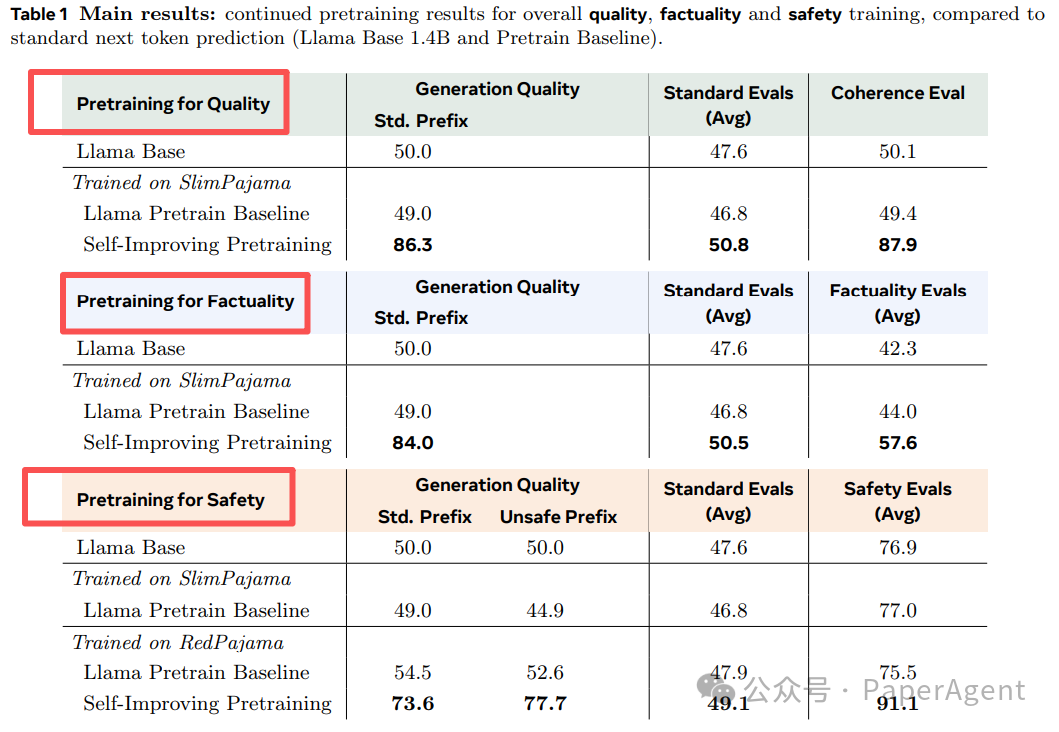
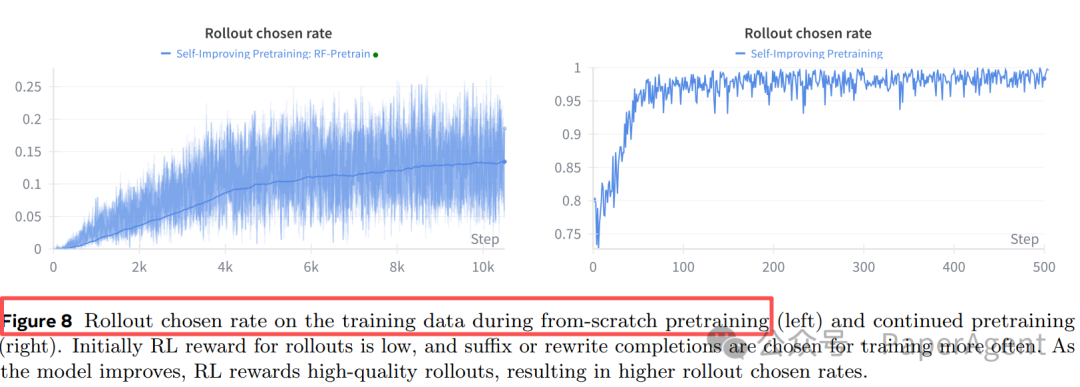
图 8:训练初期依赖“重写”,后期越来越多地选中自己 rollout 的高质量后缀
论文链接:
https://arxiv.org/pdf/2601.21343
Self-Improving Pretraining:using post-trained models to pretrain better models
两篇文章的共同启示
| 维度 |
SOAR |
Self-Improving Pretraining |
| 信号来源 |
学生在真实难题上的进步 |
强模型对质量/安全/事实的判断 |
| 自举方式 |
老师自学生成课程数据 |
强模型重写或筛选预训练序列 |
| 关键机制 |
双层元强化学习 + 非对称自博弈 |
序列生成 RL + 在线 Judge/Rewriter |
| 避免崩塌 |
Grounded Reward 替代 Intrinsic |
用强模型监督,拒绝“自嗨” |
| 能力解耦 |
出题能力 ≠ 解题能力 |
裁判能力 ≠ 生成能力 |
未来可期
- SOAR 已在实验中观察到学生模型性能“晋级”的现象,未来能否在更大规模的模型或更复杂的领域(如代码生成、科学推理)中持续“爬坡”?
- Self-Improving Pretraining 目前实验基于 1.4B 模型,将其扩展至 70B+ 级别后,是否仍能保持如此显著的质量胜率?
- 将两者结合:让 SOAR 框架生成的“高质量自课程”作为 Self-Improving Pretraining 的高质量后缀数据源,或许能形成一个“自生成-自净化”的强化闭环,为突破人类标注数据的天花板开辟新路径。
这两篇论文所探索的方向,标志着模型训练正从被动接受数据向主动构建学习路径演进。对于从事人工智能与模型研发的社区而言,此类强化学习与自监督结合的工作极具启发性。技术的发展离不开交流与碰撞,欢迎大家在云栈社区继续探讨模型自我演进的更多可能性。 |  发表于 2026-2-9 01:38:54
|
查看: 288|
回复: 0
发表于 2026-2-9 01:38:54
|
查看: 288|
回复: 0
