英伟达近日正式推出了其Nemotron系列AI模型的最新迭代——Nemotron 3系列,该系列包含Nano、Super和Ultra三个版本,旨在为下一代AI代理提供强大动力。其中,采用专家混合(MoE)技术的Nano模型现已上线,性能表现优异且完全开源。
译自:Nvidia’s Launches the Next Generation of Its Nemotron Models[1]
作者:Frederic Lardinois
英伟达此次不仅发布了新一代模型,还一并开放了包含三万亿token的预训练数据集以及一千八百万个样本的后训练数据集。开发者可以借助英伟达现有的训练环境(该公司为此新增了10个训练“健身房”环境)及其开源强化学习库,轻松获取这些模型并针对自己的具体用例进行训练。目前,Nano模型已经推出,而Super和Ultra模型预计将在2026年上半年面世。
Nemotron 3 模型家族
Nemotron 3系列是首个采用专家混合 (MoE)技术的Nemotron家族模型。MoE技术的关键在于,它能在任何给定时刻只激活模型参数的一个子集,从而将模型的总参数量与实际计算成本解耦。这意味着新模型的推理速度得到了显著提升。
英伟达表示,拥有300亿参数(其中30亿为活跃参数)的Nemotron 3 Nano模型,其性能比同等规模的上代Nemotron 2 Nano模型高出4倍。同时,它生成答案所需的推理token数量减少了60%,这将进一步降低实际使用成本。此外,它也是目前少数提供100万token上下文窗口的开源模型之一。
Nano模型尤其适合执行特定任务,现已登陆HuggingFace平台。
Nemotron 3 Super模型是一个拥有1000亿参数(活跃参数100亿)的模型,专为多智能体应用而设计。而Nemotron 3 Ultra模型则拥有5000亿参数和500亿活跃参数,这使其成为新系列中最智能的模型,非常适合处理更复杂的应用,当然其运行成本也最高。

图片来源:Nvidia。
在发布前,英伟达未向媒体提供详尽的基准测试数据。该公司仅引用了独立AI基准测试组织Artificial Analysis的评价:“该组织将Nemotron 3 Nano评为同等规模模型中‘最开放、最高效且具有领先准确性’的模型。”
从下方Artificial Analysis提供的图表中,我们可以获得更多关于Nano模型性能表现的信息。该图表显示,Nemotron 3 Nano在智能指数上与OpenAI的GPT-OSS-20B (高)、Qwen 3 30B和Qwen 3 VL 32B等模型大致处于同一水平,但其每秒输出的token数(即输出速度)要高得多。ServiceNow的April Thinking模型虽然智能指数略高于Nano,但其输出速度显著更慢。
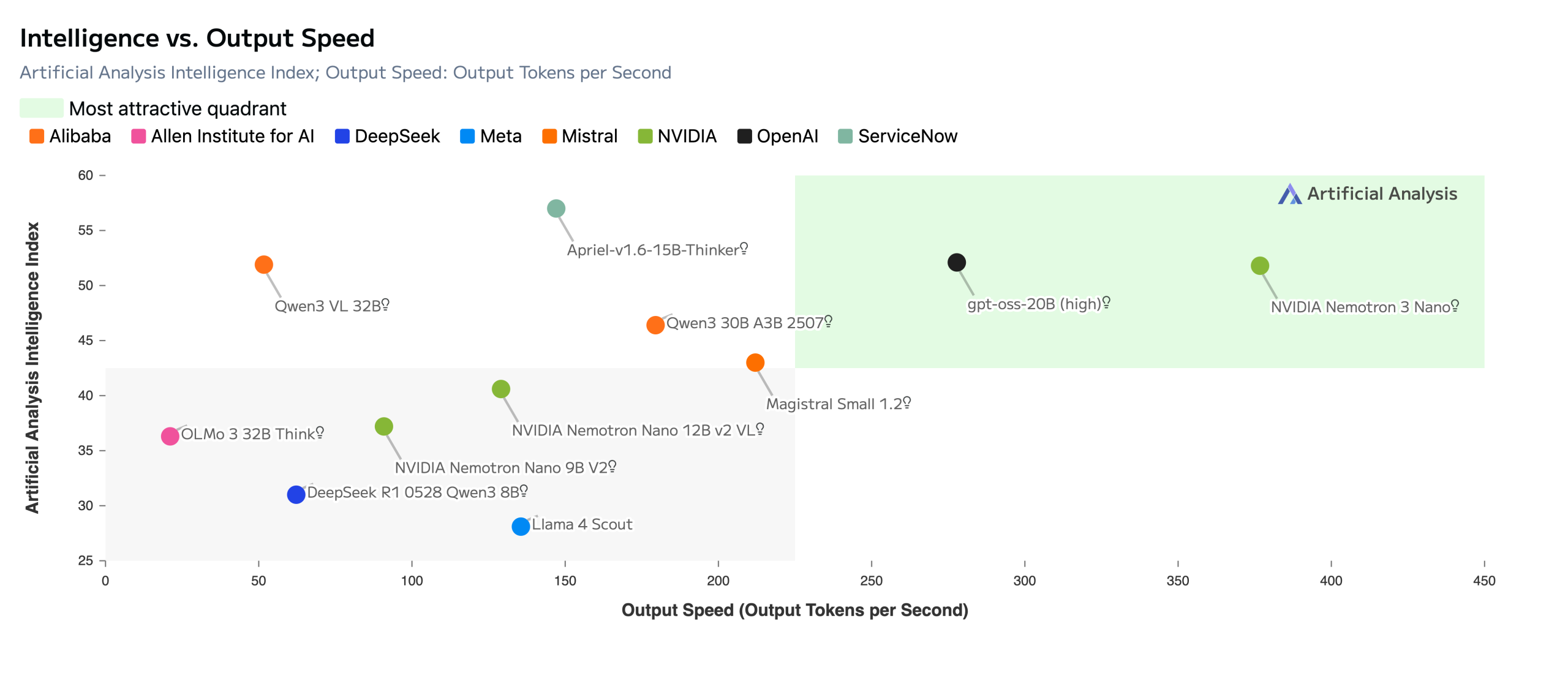
根据 Artificial Analysis 的 Nvidia Nemotron 3 Nano 基准测试。图片来源:Nvidia。
可用性
得益于开源模型的宽松许可,开发者若拥有必要的硬件,可以将其作为英伟达NIM微服务自行部署运行。同时,这些模型也将通过商业云提供商和其他平台提供服务,包括Amazon Bedrock(无服务器)等公有云,并很快登陆Google Cloud、Coreweave、Nebius、Nscale和Yotta。
此外,Baseten、Deepinfra、Fireworks、FriendliAI、OpenRouter和Together AI等推理服务提供商,以及Couchbase、DataRobot、H2O.ai、JFrog、Lambda和UiPath等平台也将集成这些模型。
英伟达为何要构建自己的模型?
尽管英伟达以制造支撑绝大多数大语言模型的硬件加速器而闻名,但其自研模型的旅程早在2019年的Megatron-LM模型时就已开始。首个以Nemotron品牌发布的模型于2024年问世,是一个基于Meta Llama 3.1的推理模型。此后,英伟达发布了多种不同规模、针对特定用例调整的Nemotron模型,均采用相对宽松的许可,允许像ServiceNow这样的公司根据自身需求进行定制。
在发布会前的简报中,当被问及英伟达为何要自研模型、是否意图成为前沿模型构建者时,英伟达企业级生成式AI副总裁Kari Briski指出,部分原因是为了在训练和模型推理方面,将公司自家的硬件性能推向极限。
她解释道:“我不需要去问‘它是否构成竞争?’它是为我们自己构建的,我们将其提供给整个生态系统,让开发者可以信任并在其之上进行构建。”
Briski认为,这也是英伟达致力于围绕其模型构建开放生态系统的原因。“如果我们相信生成式AI和大语言模型是未来的开发平台——我们确实相信——那么我会将这些LLM视为一个代码库。我们如何处理代码库?我们发布它们,供开发者检查代码,这样你就能理解它、在其上构建、我们能修复漏洞、改进它,然后再次发布。因此,我们发布得越多,开发者的参与度就越高。”
对于希望深入了解大模型技术动向和参与讨论的开发者,可以关注云栈社区上的相关板块,获取更多前沿资讯与技术交流。
引用链接
[1] Nvidia’s Launches the Next Generation of Its Nemotron Models: https://thenewstack.io/nvidias-launches-the-next-generation-of-its-nemotron-models/
[2] Nemotron 系列: https://www.nvidia.com/en-us/ai-data-science/foundation-models/nemotron/
[3] 专家混合 (MoE): https://www.ibm.com/think/topics/mixture-of-experts
[4] Amazon: https://aws.amazon.com/?utm_content=inline+mention
[5] Couchbase: https://www.couchbase.com/products/capella?utm_content=inline+mention
[6] Megatron-LM 模型: https://nv-adlr.github.io/MegatronLM
[7] ServiceNow 等公司: https://thenewstack.io/servicenow-launches-a-control-tower-for-agents/
 发表于 2026-2-7 04:21:45
|
查看: 265|
回复: 0
发表于 2026-2-7 04:21:45
|
查看: 265|
回复: 0
