扩散语言模型(Diffusion Language Models, DLLMs)因其并行生成、直接编辑和数据增强等潜力而备受关注。然而,其模型能力往往落后于同等规模的强力自回归模型。
近日,华中科技大学和字节跳动联合推出了Stable-DiffCoder。这不仅仅是一个新的扩散代码模型,更是一次对“扩散训练能否提升模型能力上限”的深度探索。

Stable-DiffCoder 在完全复用 Seed-Coder 架构与数据的条件下,通过引入 Block Diffusion 持续预训练及一系列稳定性优化策略,成功实现了性能反超。在多个主流代码榜单上,它不仅击败了其自回归原型,更在 8B 规模下超越了 Qwen2.5-Coder、Qwen3、DeepSeek-Coder 等一众强力开源模型,证明了扩散训练范式本身就是一种强大的数据增强手段。
扩散过程难以高效学习样本知识
扩散过程虽然能扩充数据,作为一种数据增强手段,但实际上也会引入噪声甚至导致模型学习错误知识。
例如下面的例子:
a = 1, b = 2, a + b = 3; a = 3, b = 4, a + b = 7
将其部分内容掩码(mask)后可能变成:
a = 1, b = 2, [MASK₁] … [MASK₂] a + b = [MASKₙ]
可以发现,对于最后一个掩码 [MASKₙ],模型只能在看见 a=1,b=2 的情况下去学习 a+b=7,这会形成错误的知识映射。最后模型充其量只能学到 “a=3,b=4” 在 “a+b =” 这个语境下的共现概率更大,而无法学到明确的加法规则。
知识学习与流程设计的理论建模
论文通过建模知识的学习来解释这一现象。假设 c 是当前可见的上下文,根据真实数据分布,通过这些上下文能推理出的下一个有效 token 集合为 C(c),其大小为 K(c)。可以理解,上下文 c 提供的信息越充分、越干净,K(c) 就越小。
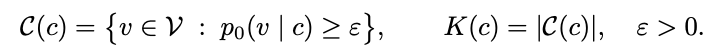
模型最终希望学习的是条件分布 p_θ(C(c) | c) ≈ p_0(C(c) | c)。要学好这个过程需要满足两个条件:1)K(c) 比较小;2)从数据中采样的 c 要尽可能多样且充足。
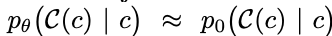
因此,如果使用纯双向的扩散过程,在掩码比例较大时,当前 token 能看到的上下文 c 变小,其信息不完整的概率变大,导致 K(c) 变大,模型难以映射到清晰的规则。同时,这个过程会产生各种各样的 c,平均每个 c 被学习到的次数减少。此外,还必须保证训练时采样的 c 与推理时使用的 c 分布一致,才能更好地利用训练中学到的知识。
为了进一步阐释并证明这个结论,论文设计了一个在 2.5B 模型上的实验,探索三种训练方式:
- AR→BiDLLM:用自回归方式继续训练,在 10万步时转换成双向 DLLM。
- ARDLLM→BiDLLM:使用自回归模型结构,但用纯双向采样的扩散目标训练,然后在 10万步时转换成 BiDLLM。
- BiDLLM:直接使用纯双向的 DLLM 训练。
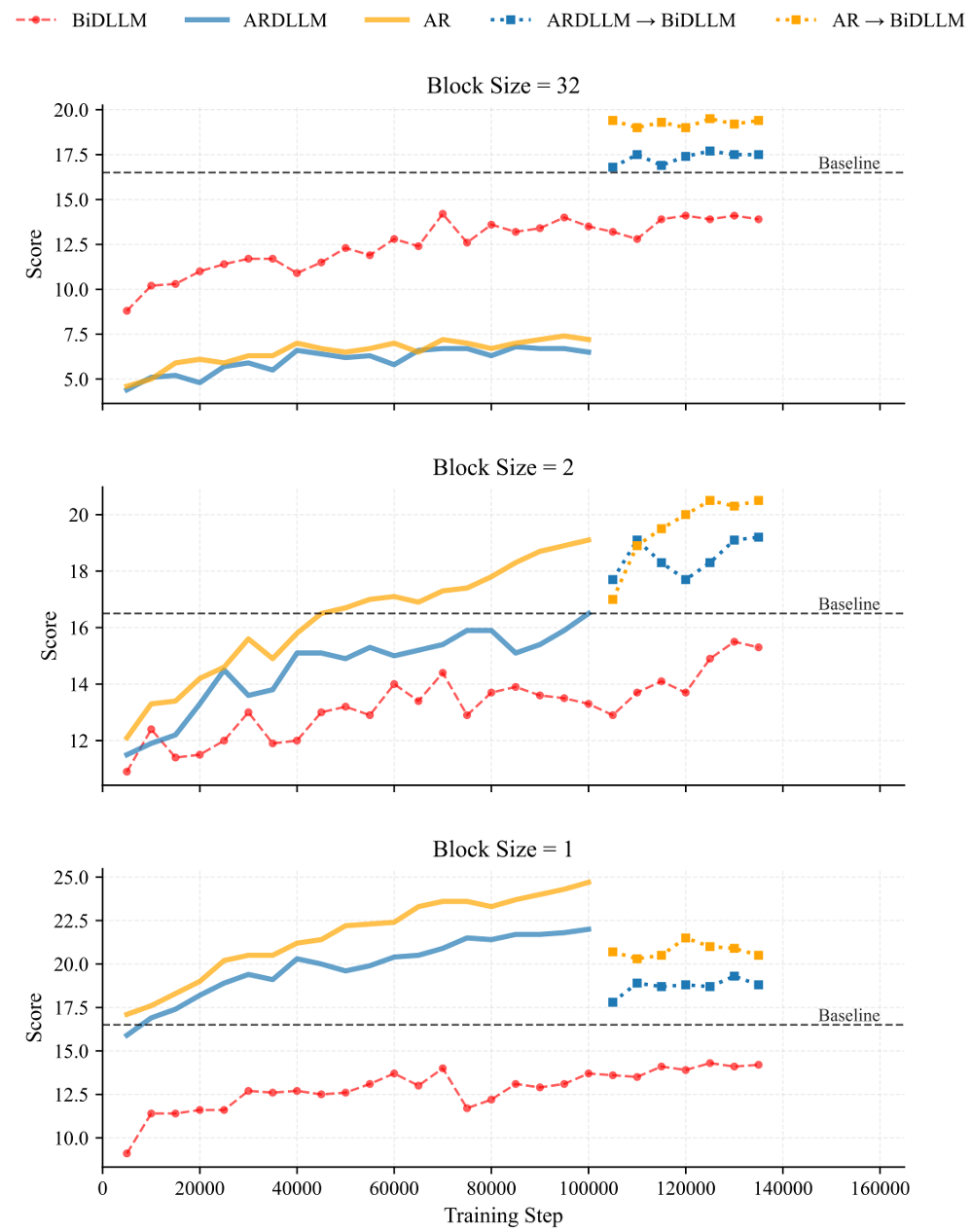
实验结果显示,最终效果是(1)>(2)>(3),这与前面的理论相符。不使用随机掩码的方案(1)对于新知识有更快的“压缩”速度,并且转换成 BiDLLM 后也保持着最佳性能。这证明,要高效地训练好一个 DLLM,可以先使用自回归或小分块(block)的扩散方式进行知识压缩。
另一个有趣的现象是,在分块大小(Block Size)为 32 时,(1)和(2)在转换前表现比(3)差,但在转换后表现更好。这说明自回归采样得到的上下文 c 与 Block Size=32 的推理过程不太匹配,但由于自回归过程压缩了大量有用的知识,只需稍作持续预训练就能适配新的推理过程。这也暗示,自回归结构的先验,可能更适合代码生成中“提示(prompt)+响应(response)”这种从左到右的推理过程。
因此,Stable-DiffCoder 将训练流程设计为:先用自回归方式压缩一遍知识,然后用自回归训练退火后的检查点(checkpoint)作为起点,继续预训练(CPT)成小分块的 Block Diffusion 模型,以此来探索扩散过程的数据增强能力。
稳定的 DLLM 预热策略与持续预训练设计
扩散模型的持续预训练通常对超参数(如学习率)非常敏感,容易出现梯度范数异常升高的问题。为了保持训练稳定并减少繁琐的调参,研究团队设计了一种适配的预热策略。
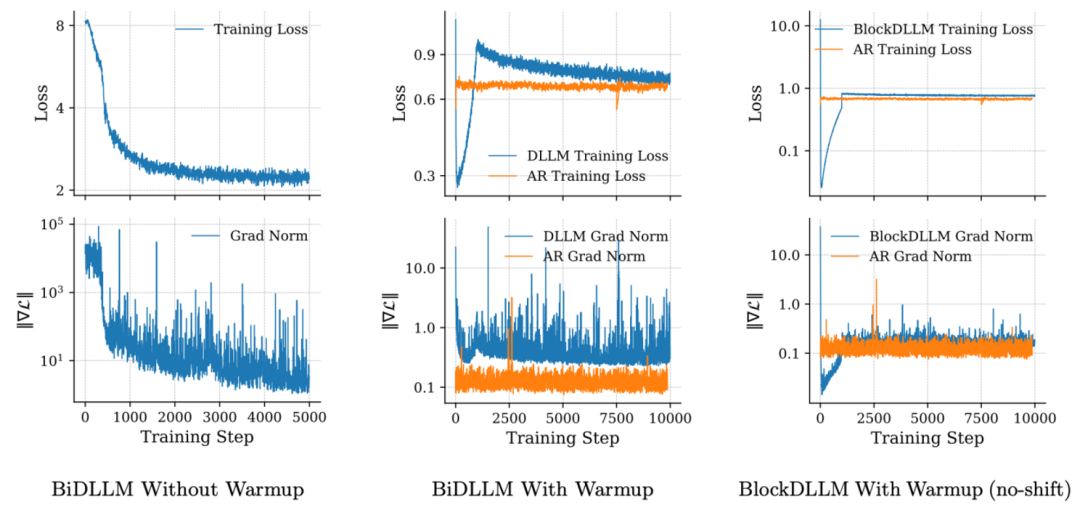
DLLM 的 CPT 过程不稳定主要受三个因素影响:
- 注意力机制从单向变为双向。
- 掩码增多导致任务变难。
- 为了对齐证据下界(ELBO),损失函数中的交叉熵项会被加权。例如,如果只掩码了一个token,则等价于只计算这个token的损失,这会大幅增加该token对梯度的贡献,进而影响梯度范数和损失值。
由于动态调整注意力掩码的方式难以灵活适配 Flash Attention 等高效计算架构,团队针对(2)和(3)设计了预热过程。具体来说:
- 在预热阶段,将掩码比例的上限逐渐从低增加到目标最大值,使得任务难度从易到难平滑过渡。
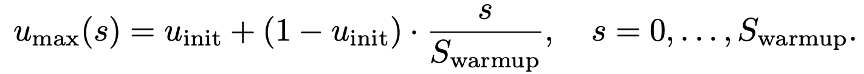
- 在预热阶段,去掉交叉熵损失中的加权系数,让每个token对损失的贡献更平稳。
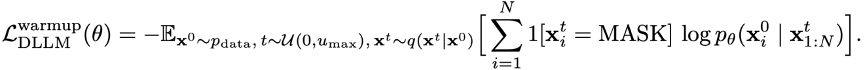
分块截断的噪声调度
在使用分块扩散时,由于通过交叉注意力机制拼接了干净的上下文前缀,可以确保每个被掩码的 token 都能产生有用的损失信号。然而,如果使用传统的噪声调度,可能会使得某些分块完全不产生损失信号。通过求解积分可以算出,一个包含 B 个 token 的分块完全不产生损失信号的概率为:
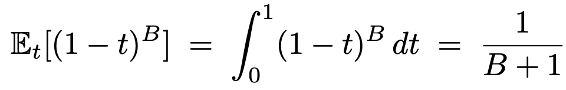
这在分块较小时尤其明显。
因此,团队做了两项设计:
- 强制每个分块都至少采样一个 token 进行掩码。
- 将噪声时间步的下界设置为 1/B。这样可以确保期望上每个分块至少有一个 token 被采样。同时,这也能避免强制采样后,由于对应的噪声时间步
t 过小,导致交叉熵损失加权过大的问题。
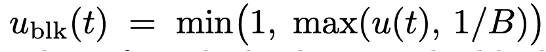
实验结果:在多项代码基准测试中保持领先
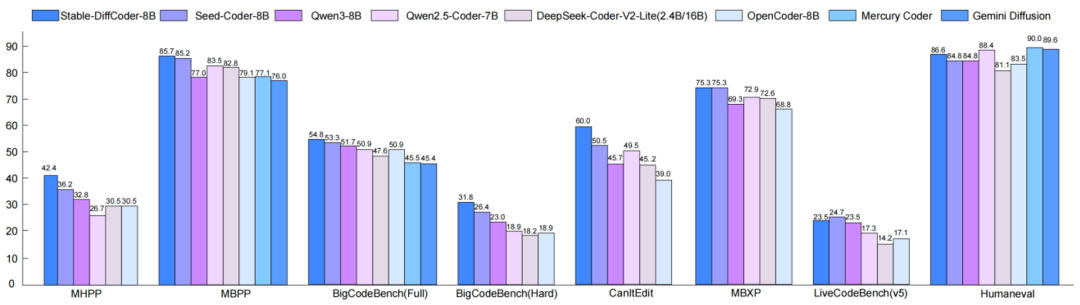
Base 模型表现
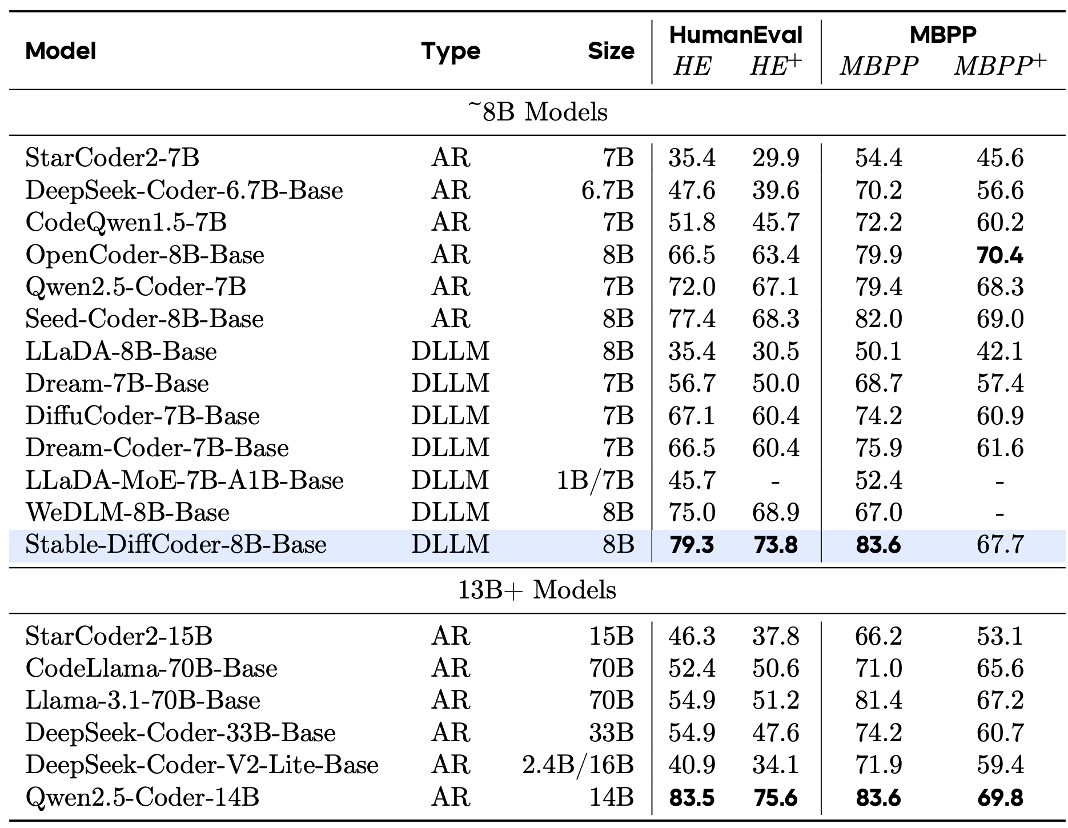
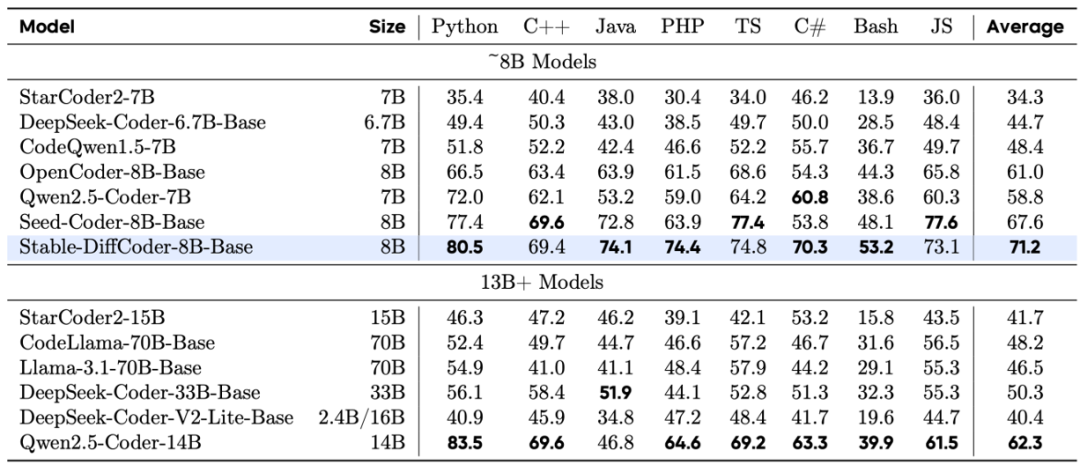
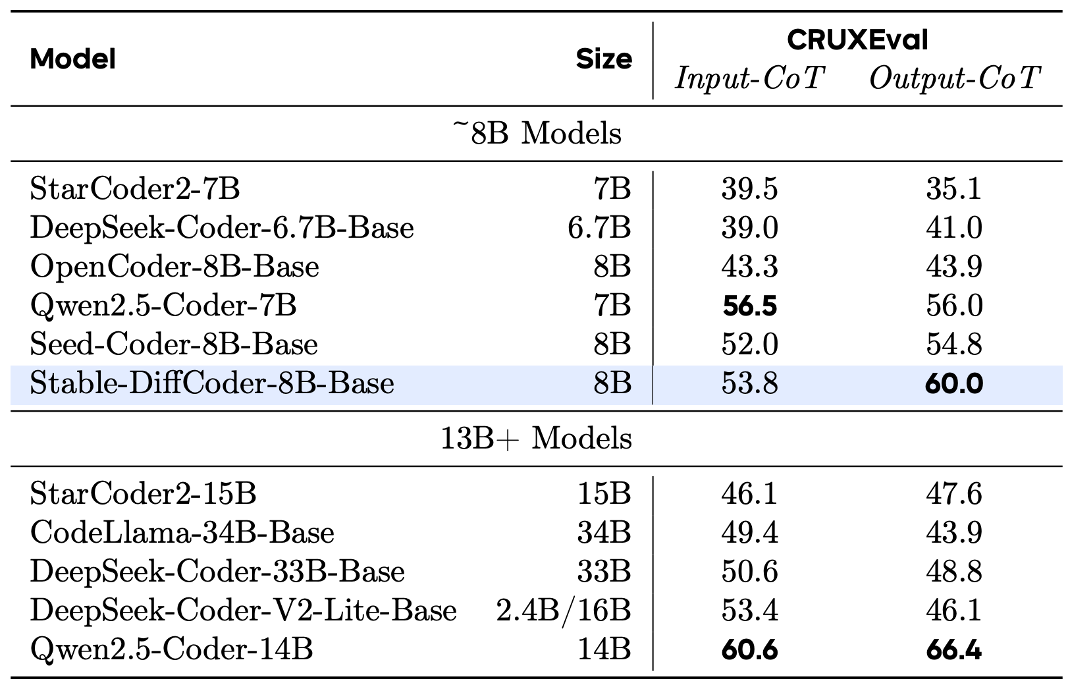
Stable-DiffCoder-8B-Base 在代码生成、多语言代码生成以及代码推理任务上表现出色,超越了一系列自回归和基于扩散的模型。值得注意的是,模型在预训练数据较少的稀疏编程语言上(如 C#、PHP 等),相比自回归基线模型得到了大幅增强,这证明了 DLLM 的训练过程起到了数据增强的效果。同时,其代码推理能力也得到了提升。
Instruct 模型表现
Stable-DiffCoder-8B-Instruct 在代码生成、代码编辑、代码推理等任务上进行了综合评测,并展现出优越性能。
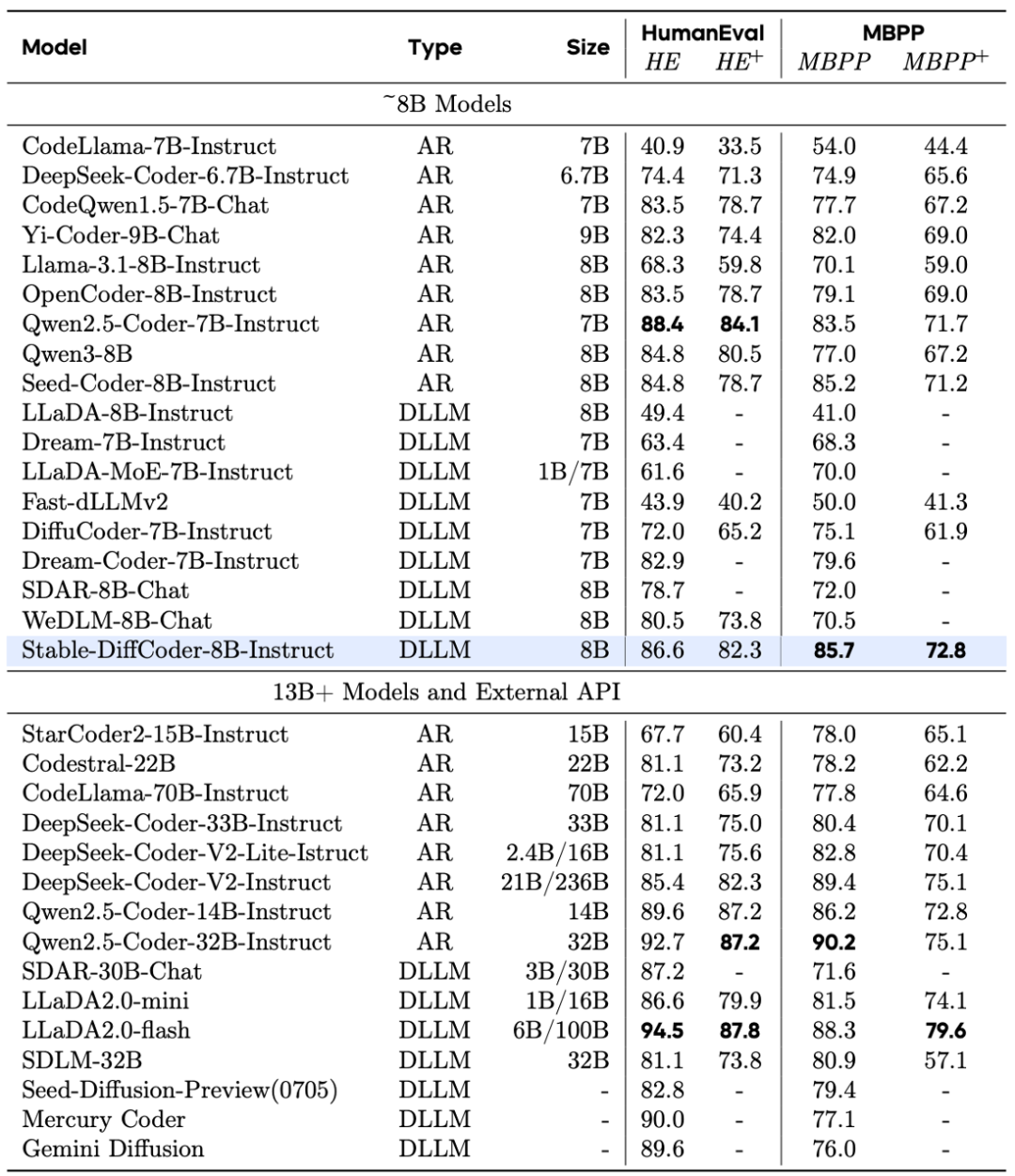
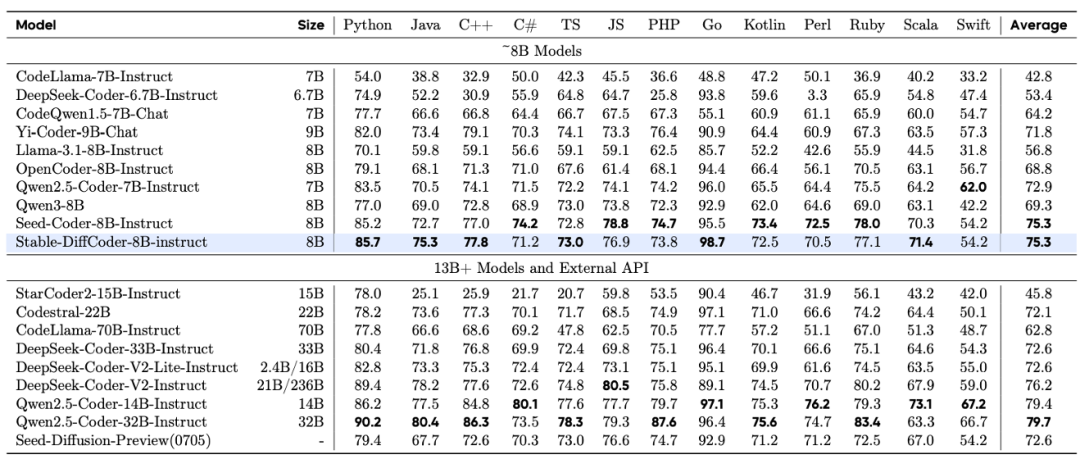
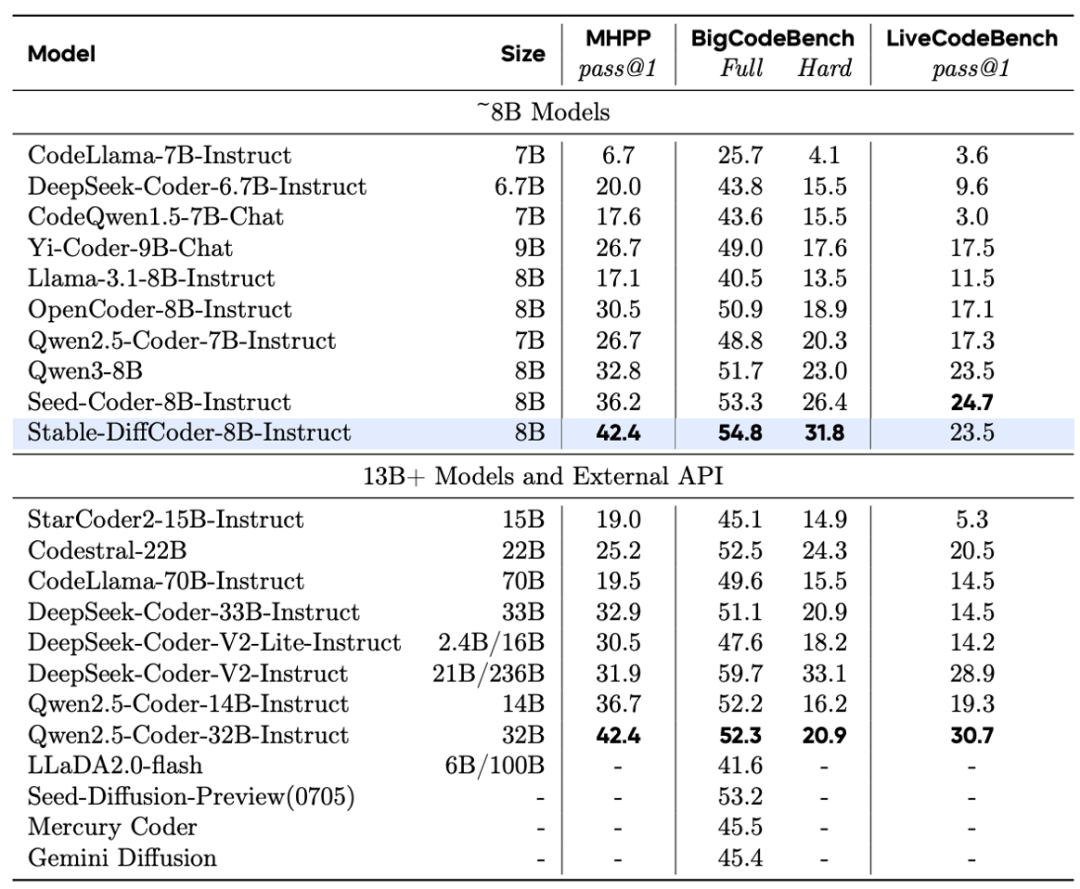
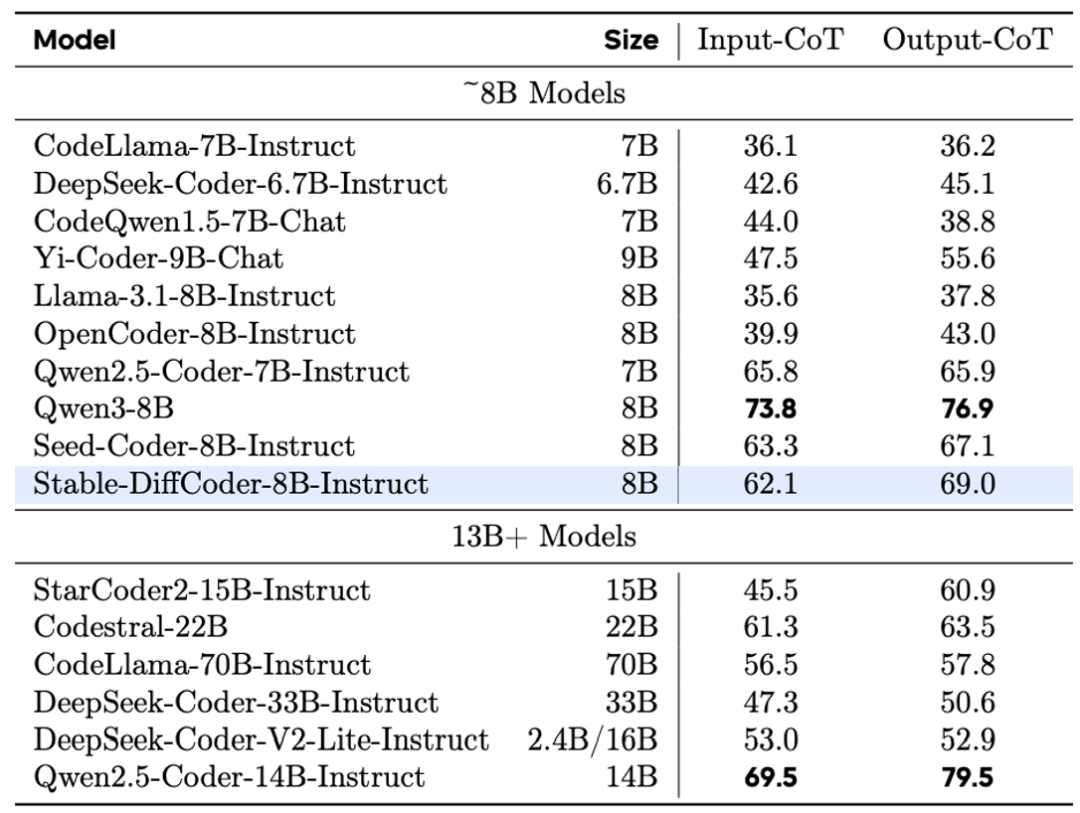
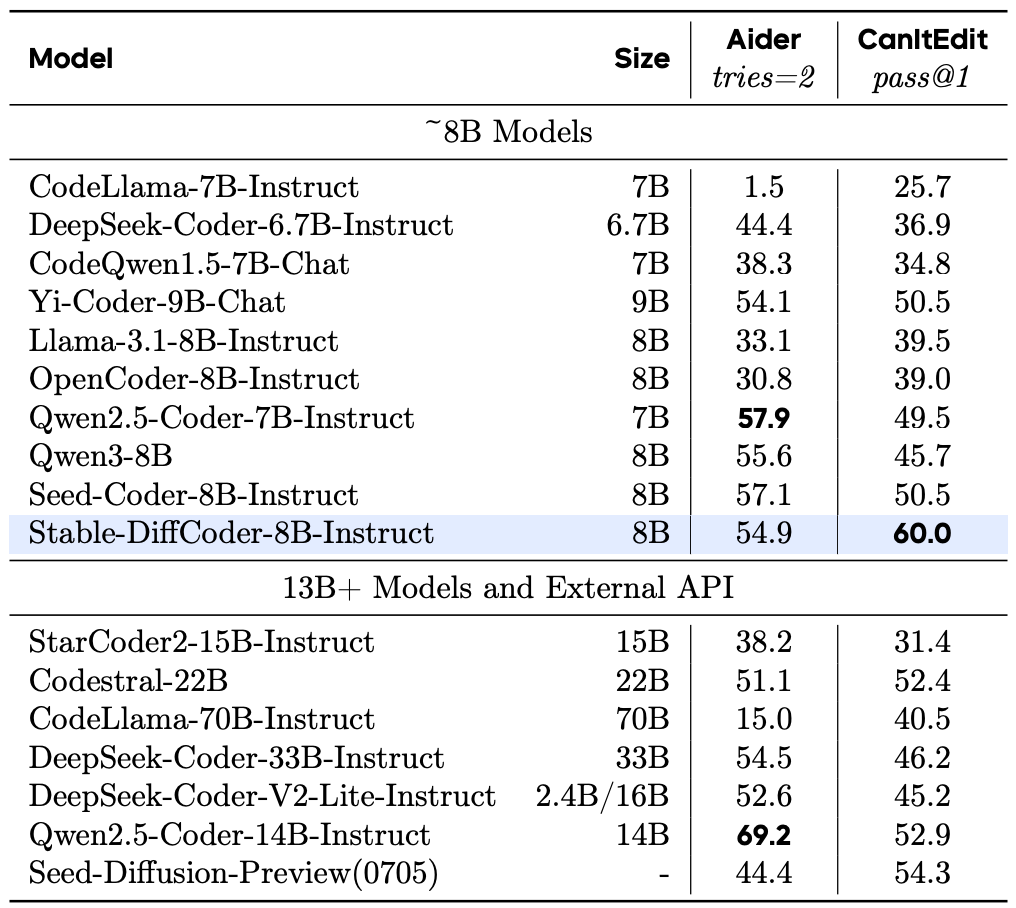
在常用代码生成任务上,它大幅超过了原有的自回归基线和其他 8B 规模的 DLLM 模型。在测试集未公开的 MHPP 基准上达到了与更大模型相当的水平,在 BigCodeBench 上的表现更是超过一系列模型。尤其在代码编辑任务上展现出了惊艳的效果。
总结与展望
Stable-DiffCoder 的发布,打破了“扩散模型只能做并行加速”的刻板印象。它证明了:扩散训练范式本身就是一种极佳的表征学习手段。通过合理的课程设计及稳定性优化,扩散模型完全可以在代码理解和生成质量上超越传统的自回归模型。
对于未来大模型的演进,Stable-DiffCoder 提示了一条新路径:我们或许不需要抛弃自回归范式,而是可以将其作为高效的“知识压缩器”,再利用扩散训练作为“强化剂”,两者结合,进一步推高模型的智能上限。这种结合了Transformer两大主流范式的思路,为开源项目的未来发展提供了新的灵感。对于关注人工智能前沿进展的开发者而言,这无疑是一个值得深入研究和讨论的方向。你如何看待这种混合训练范式?欢迎在技术社区分享你的见解。
 发表于 2026-2-7 04:25:05
|
查看: 156|
回复: 0
发表于 2026-2-7 04:25:05
|
查看: 156|
回复: 0
