近期,腾讯混元(Hunyuan)团队与复旦大学联合发布了一项针对大语言模型上下文学习能力的新基准测试——CL-Bench(Context Learning Benchmark)。这项研究获得了新近加入腾讯并出任首席AI科学家的姚顺雨(Shunyu Yao)的全面审阅与反馈。
姚顺雨在2025年底正式加入腾讯,担任首席AI科学家等职务。在公开演讲中,他曾强调构建强大应用不仅需要模型能力,也离不开长上下文(Long Context)的支持。此次他与团队共同署名的CL-Bench论文,正是对这一方向的一次深刻实践与检验。

论文标题页,显示了腾讯混元与复旦大学的联合署名,姚顺雨(Shunyu Yao)为作者之一
一、CL-Bench的核心价值:为什么需要“现学现卖”能力?
当前主流的大模型评测通常聚焦于静态知识记忆或长文档理解。但CL-Bench提出了一个新的核心评估维度:模型能否从一段全新的、复杂的上下文中即时学习新知识,并应用这些知识解决问题。
-
| 现有评测的痛点: |
现有评测 |
痛点 |
| 静态知识问答(MMLU、C-Eval) |
模型依赖预训练的“旧知识” |
| 长文档理解(LongBench、L-Eval) |
考查“信息检索”,而非“知识学习” |
| 上下文学习(In-Context Learning) |
仅学习“输出格式”,而非“领域新知” |
CL-Bench 首次将“现学现卖”能力单独作为考核重点。它为模型提供一段全新、复杂且领域性强的上下文(最长可达65k token),然后提出1到12道必须依赖这段新知识才能解答的题目。如果模型试图偷懒,使用预训练中的旧知识来回答,几乎必定失败(消融实验显示任务通过率 <1%)。
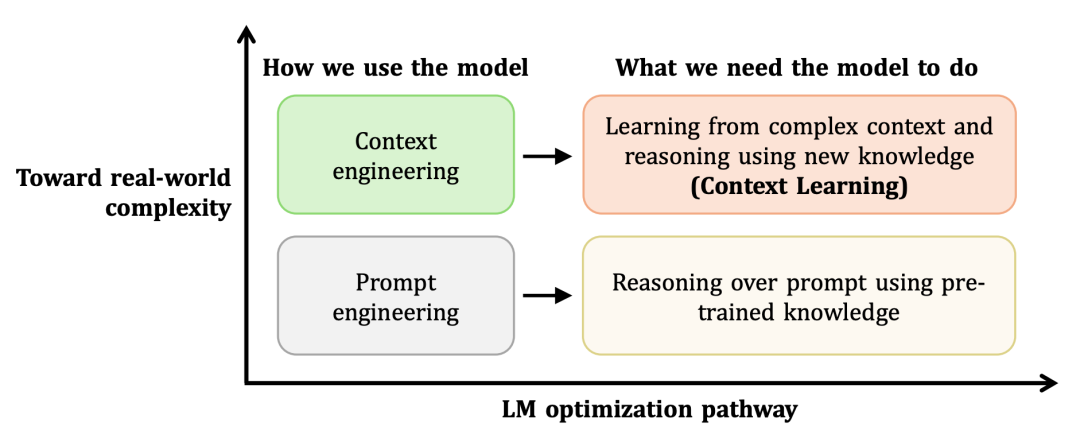
图1:从利用预训练知识进行提示工程(Prompt Engineering),到从复杂上下文中学习新知识并进行推理(Context Learning),是模型能力演进的一个重要方向。
二、严格的设计原则:自包含与强依赖
CL-Bench 围绕一个简单而严格的原则构建:每个任务都必须要求从提供的上下文(Context)中学习新知识。每个上下文都是完全自包含(Self-contained)的,解决任务所需的全部信息都明确地包含在上下文中,不需要外部检索,也不允许任何隐藏假设。
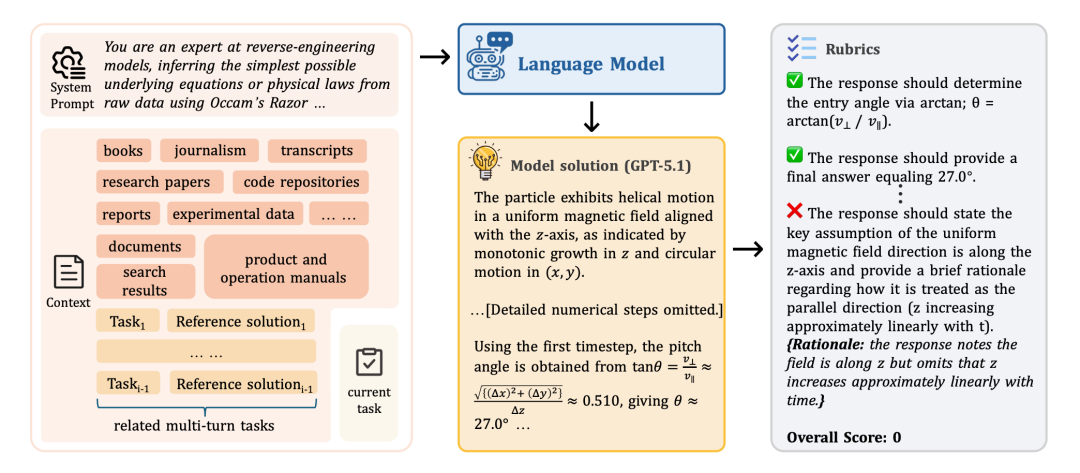
图2:CL-Bench中的一个任务示例。模型需要从系统提示(左侧)提供的复杂上下文中学习新知识,并生成解答(中间),最终根据详尽的评分标准(右侧)进行严格评估。
三、四大题型,覆盖18个子类
CL-Bench构建了一个大规模的测试集,旨在全面评估模型从不同类型上下文中学习的能力。
| 指标 |
数量 |
| 上下文(Contexts) |
500 |
| 任务(Tasks) |
1,899 |
| 细项评分(Rubrics) |
31,607 |
| 平均输入长度 |
10.4 k tokens |
| 最长输入 |
65 k tokens |
这些任务被系统地划分为四大核心类型,共包含18个子类,以模拟现实世界中复杂多样的知识学习场景:

图3:四大任务类型的具体示例。从上到下,从左到右依次为:领域知识推理、规则系统应用、程序性任务执行、经验发现与模拟。
- 领域知识推理:学习一个虚构或小众领域的完整知识体系(如一部新的法律、一个冷门医学分支),并像该领域专家一样进行推理和解答。
- 规则系统应用:理解一套全新的规则系统(如新编程语言的语法、桌游规则、数学形式体系),并依据规则正确执行任务。
- 程序性任务执行:遵循一份详细的操作手册或流程指南(如产品说明书、实验SOP),一步步零差错地完成任务。
- 经验发现与模拟:从提供的观测数据、实验结果或模拟环境中,自主归纳出潜在的规律或公式,并进行预测。
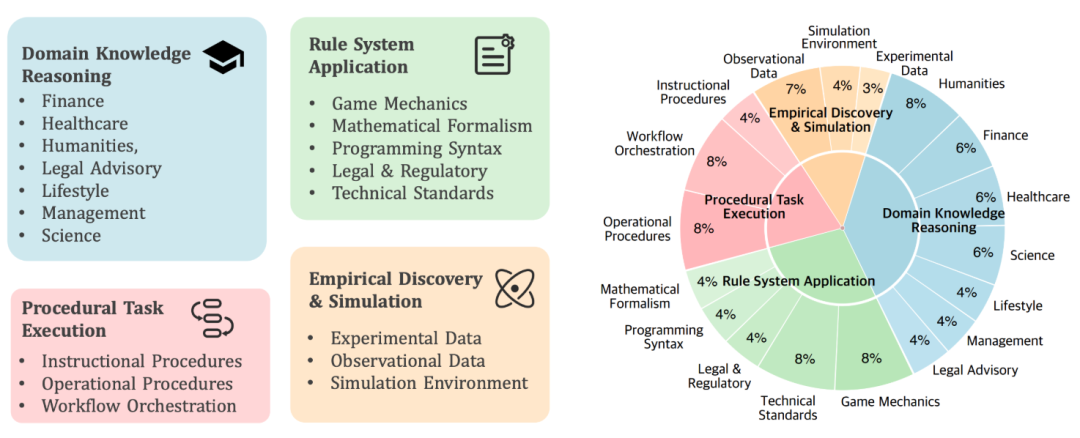
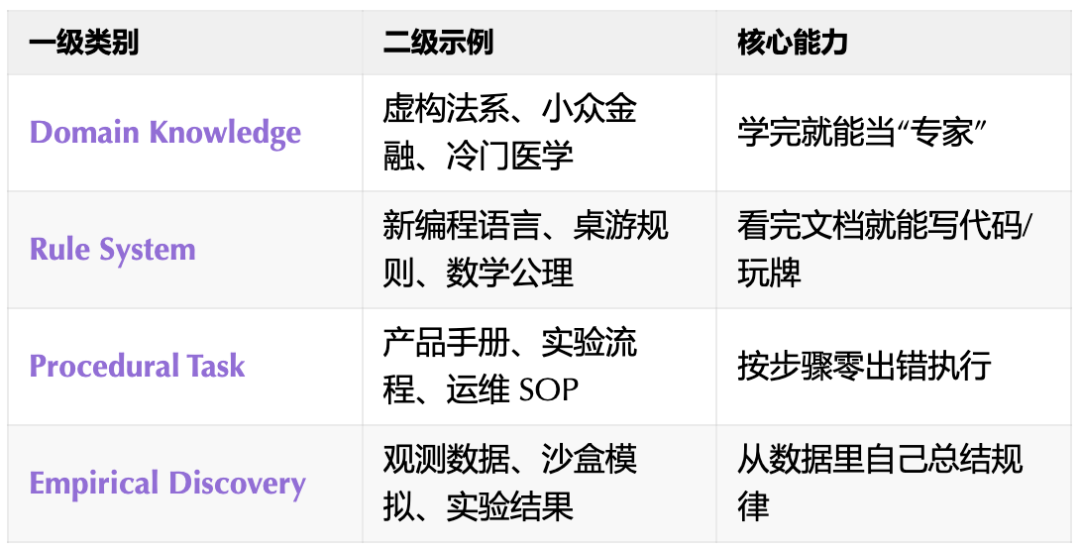
图4(左):CL-Bench中各类任务的分布情况。图5(右):四大题型、示例及其考察的核心能力总结。
四、严苛的“全或无”评分机制
为了确保评估的客观性和严格性,CL-Bench为每道题目配备了10到20条可自动判定的细项评分标准,覆盖格式、事实、计算、逻辑等各个方面。
评分采用 “全或无” 的二元制:
- Score = 1:学生答案必须完美满足评分标准中每一条要求。
- Score = 0:只要有1条不满足。
这种机制彻底杜绝了“差不多”式的评判,要求模型必须精确遵循指令并准确应用所学知识。评估过程通常由经过精心设计的基于大模型的裁判(LM-as-Judge) 自动执行。
Score = 1:学生答案必须**完美**满足 rubric 中**每一条**要求
Score = 0:只要有 1 条不满足

表4:用于自动评分的LM-as-Judge的系统提示节选,展示了其严格的评分流程与输出格式要求。
五、主流模型表现:高难度下的集体“翻车”
在CL-Bench的严苛考验下,包括GPT-5.1、Claude 3.5 Opus、腾讯混元HY 2.0等在内的10款前沿大模型集体表现不佳。

表2:10款主流大模型在CL-Bench总体及各个子类上的平均通过率(%)。表现最佳的模型总体通过率也仅略高于23%。
关键发现:
- 归纳能力远弱于演绎能力:需要“从数据中归纳规律”的“经验发现与模拟”类任务平均通过率仅为11.8%,比其他三类任务低了约6个百分点。
- 上下文长度是主要瓶颈:当输入文本长度超过32k token时,所有模型的得分出现“腰斩”式下降。
- 强化推理模式并非万能:例如,GPT-5.2开启“High”推理模式后,整体得分反而比“Low”模式下降了5.6%,暴露出在长上下文、复杂逻辑与严格指令跟随之间的平衡难题。
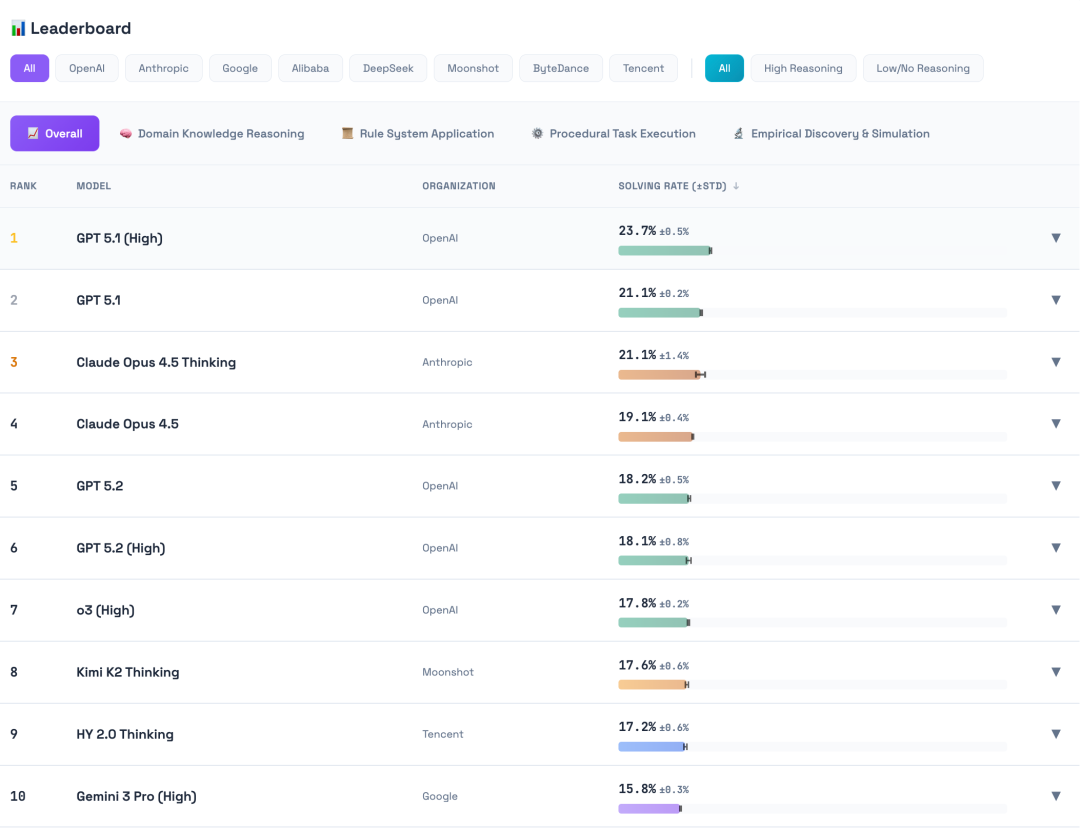
图6:CL-Bench官网上的模型排行榜,直观展示了各模型在解决任务上的表现排名。
六、错误分析:模型为何失败?
研究进一步对模型的错误进行了归因分析,揭示了当前大模型在上下文学习中的主要短板。
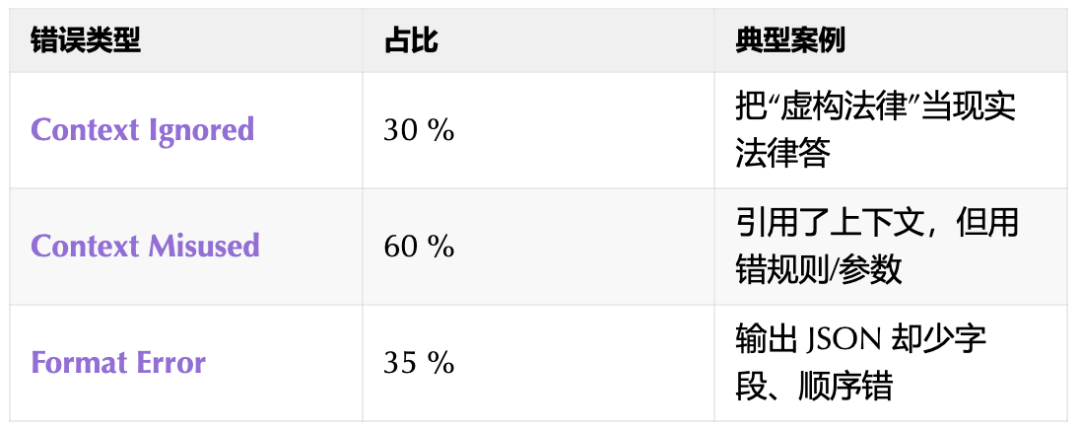
图7:模型在CL-Bench上失败的三大主因及其典型案例。
- 忽略上下文(占30%):模型完全无视提供的全新知识,转而依赖有冲突的预训练知识作答(例如,把上下文中的“虚构法律”当作现实法律来回答)。
- 误用上下文(占60%):模型虽然引用了上下文,但在应用时出现了关键错误,如用错规则、参数或逻辑。
- 格式错误(占35%):模型未能严格遵守输出格式要求(例如,要求输出JSON却缺少字段或顺序错误)。值得注意的是,单一失败案例可能同时属于多种错误类型。

表3:不同模型在错误类型上的分布情况,表明“忽略上下文”和“误用上下文”是普遍性难题。
总结与资源
CL-Bench 像一场“闭卷速读 + 现场实操”的残酷考试,它清晰地指出:“现学现卖”仍是当前乃至下一代大模型最亟待提升的通用能力之一。这项研究不仅提供了一个评估工具,更为未来提升模型动态知识获取与应用能力指明了方向。
目前,CL-Bench的论文、数据、代码均已开源,鼓励社区共同推进相关研究:
对于想要深入了解大模型评测前沿、上下文学习技术细节的开发者,这份研究无疑是一份极具价值的技术白皮书。它揭示了当前技术的边界,并为我们描绘了通往更智能、更适应性的人工智能代理的路径。正如姚顺雨在团队致谢中所被认可的那样,高质量的审阅与反馈对提升此类基础研究工作的质量至关重要。这项开源项目的发布,也体现了顶尖团队通过开放协作推动领域进步的趋势。
 发表于 2026-2-6 02:52:40
|
查看: 240|
回复: 0
发表于 2026-2-6 02:52:40
|
查看: 240|
回复: 0
