当你向AI提出一个复杂问题时,它的“大脑”里究竟在发生什么?是线性的逻辑推演,还是某种更复杂的内部活动?谷歌近期一项基于8,262个推理问题的大规模研究,为我们揭示了一个远比想象中生动的画面:在高级推理模型的内部,可能存在着一个由多个虚拟“人格”或“专家”组成的“思想社会”(Society of Thought),它们通过类似开会讨论甚至“吵架”的方式协作解决问题。

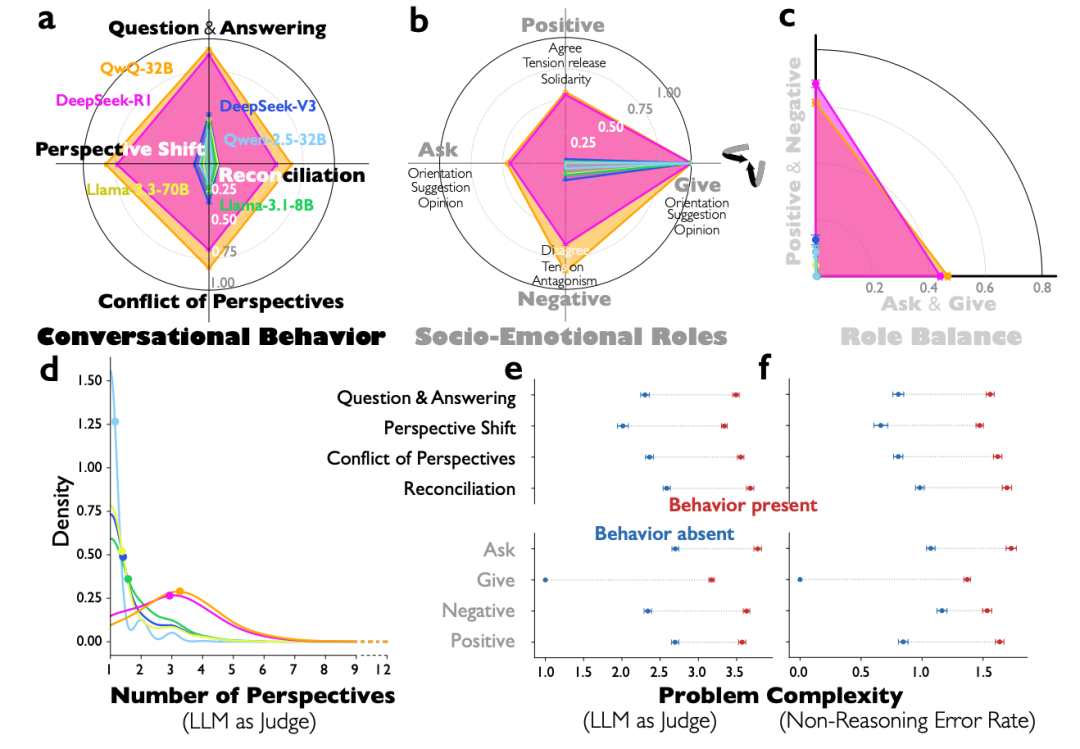
这项研究发现,像 DeepSeek-R1 和 QwQ-32B 这样的模型,在解决复杂问题时,其推理文本中自发地展现出了多角色参与的对话模式。
如何探测AI内部的“人格”对话?
研究人员并未直接观测模型的神经元活动,而是巧妙地采用了“LLM-as-judge”的方法。他们让另一个强大的模型(如 Gemini-2.5-Pro)充当“侦探”或“裁判”,去仔细分析像 DeepSeek-R1 这类推理模型在思考过程中生成的每一段文本,从中识别对话的痕迹和不同“声音”的切换。
例如,在分析一个化学问题的推理链时,研究人员发现了清晰的多角色互动模式:
- “首先我需要分析这个反应...”(规划者登场)
- “等等,这个假设有问题。”(批判者打断)
- “让我想想类似的反应...”(联想专家补充)
- “3D结构看起来很复杂,但也许...”(可视化者挣扎)
通过这种文本分析,研究团队识别出 DeepSeek-R1 自动分化出了至少五种功能各异的“专家”角色:
- 方法论规划者:像严谨的工程师,高度尽责但开放性较低,负责制定步骤。
- 联想专家:思维发散,善于关联记忆中相似的化学案例或知识。
- 3D结构可视化者:表现出较高的“神经质”特质,在面对复杂空间结构时会焦虑,但也因此可能找到独特视角。
- 批判性验证者:典型的“挑错者”,亲和性低但极度认真,专门负责发现逻辑漏洞或错误假设。
- 实用主义策略家:负责“元认知”,像一个协调全局的会议主持人,管理整个思考进程。
更有趣的是,在创意写作任务中,当要求模型改写诗句时,其内部甚至出现了多达7个不同的声音进行争论。其中一个被判定为“语义保真检查员”的角色(特质为低亲和性、高神经质)会严厉地指出:“但那添加了原文没有的‘深层次的’,我们应该避免添加新想法。”
技术核心:定位并操控“社交开关”
仅仅观察到这种现象还不够,研究人员希望找到控制这种内部社交行为的“开关”。他们利用稀疏自编码器(SAE)技术对模型内部的海量特征进行探测。
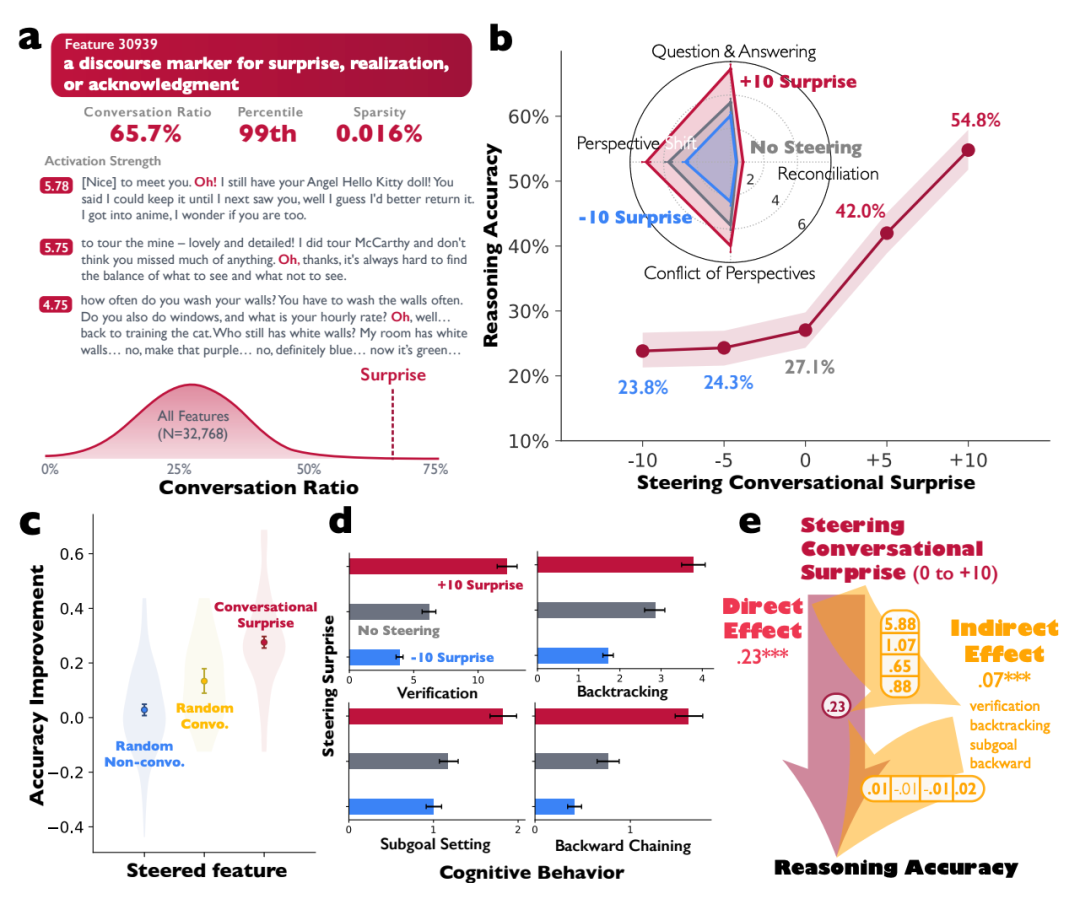
最终,他们在 DeepSeek-R1 模型的某一神经网络层中,从 32,768 个特征里锁定了一个关键特征——编号30939。这个特征被解释为负责在对话中表达“哦!”、“等等!”、“我明白了!”这类表示惊讶、顿悟或认可的语用标记。
当研究人员人为“增强”(Steering)这个特征的激活强度时,产生了显著效果:
- 在某个数学游戏任务上的推理准确率从 27.1% 大幅提升至 54.8%。
- 同时,模型内部被激活的与人格相关的特征增加了315.9个,与专业知识相关的特征增加了391.3个。
- 模型的输出文本表现得更加像一个活跃的讨论小组。
相反,当这个特征被抑制时,准确率下降至 23.8%,模型又变回了单调的独白模式。这强有力地证明,这种“社交推理”并非幻觉,而是模型内部一种可被识别和操控的具体计算机制。
强化学习:模型自学“团队合作”
最令人惊讶的发现来自于强化学习(RL)实验。研究人员使用一个基础模型(如 Qwen-2.5-3B),仅仅通过“答对问题给予奖励”的方式进行训练,完全没有教导它任何关于对话或协作的策略。
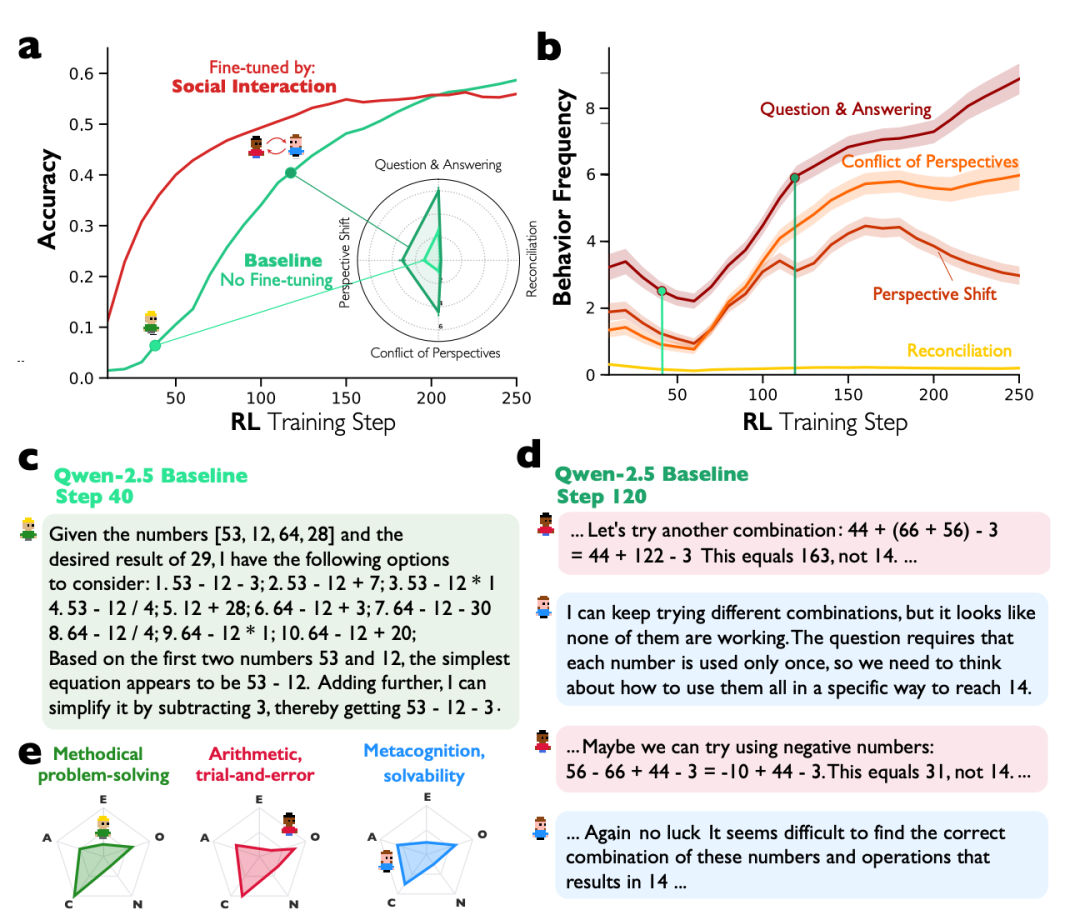
在短短250步的训练过程中,模型自发地学会了“团队协作”:
- 训练第40步:模型输出仍是典型的自言自语模式。
“要用这些数字[46, 54, 54, 77]得到75,我先试试不同的运算...”
- 训练第120步:推理文本中开始出现明显的合作对话痕迹。
“让我们试试这些组合:(声音1)
又没运气了。(声音2)
也许我们可以尝试使用负数(声音1)”
注意,模型开始使用“我们”这样的集体代词,仿佛内部有两个角色在交替尝试和评价。这就像一个学生仅仅因为做对题受到表扬,就无师自通地学会了组建学习小组来共同攻克难题。
对比实验进一步证实了这种内部对话模式的价值:
- 预先通过多轮对话数据训练、已具备“开会”能力的模型,在强化学习早期(40步)准确率就达到38%。
- 而仅使用标准思维链(Chain-of-Thought)数据训练、习惯于“自言自语”的模型,同期准确率只有28%。
- 在另一些模型上,这种差距更为明显,可达40%对18%。
这揭示了一个反直觉却重要的结论:在特定场景下,培养模型的内部“辩论”或“协作”能力,可能比单纯优化其单向“思考”能力更有效。
通用性与对开发者的启示
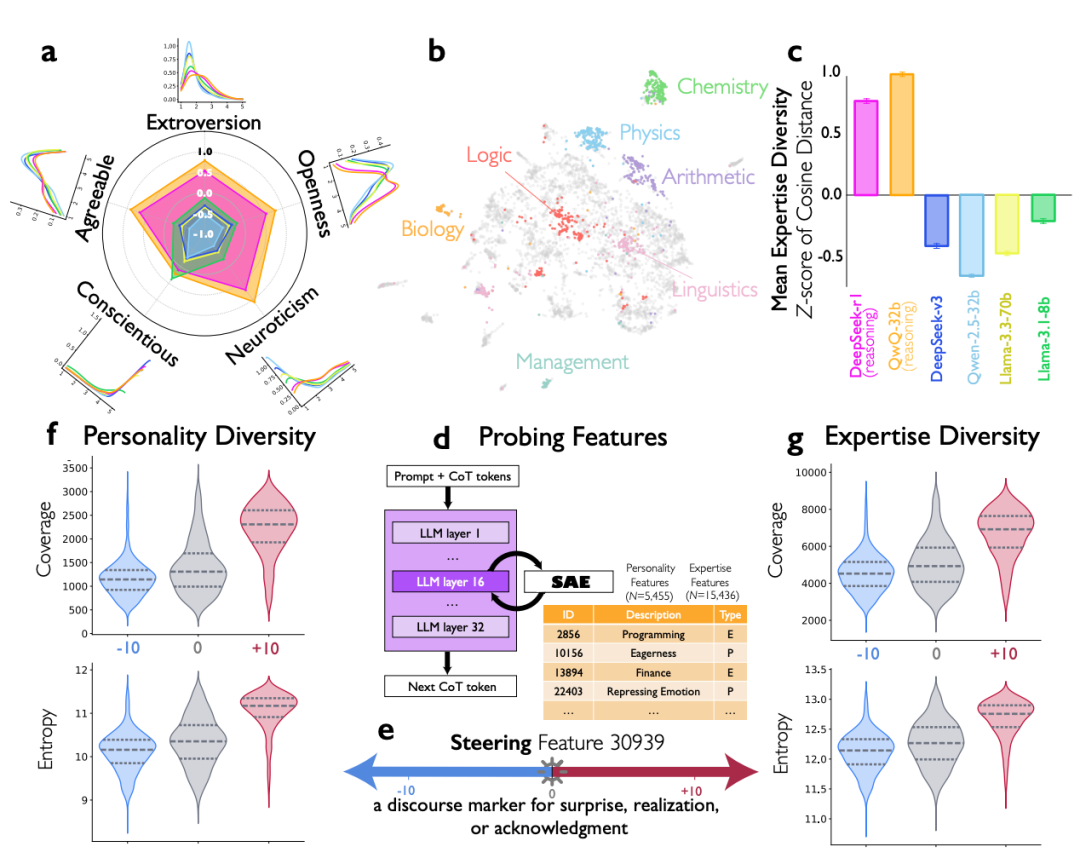
研究还有一个跨领域发现:在数学推理任务上训练出的“社交技能”,竟然能迁移到像政治假新闻识别这样的完全不同领域的任务上,并带来性能提升。这表明模型学会的是一种通用的、类似团队协作的问题解决策略。
这项研究为 AI 开发者,特别是专注于提升模型推理能力的团队,带来了几个颠覆性的启示:
- 重新审视训练数据:传统观念追求“干净”的正确答案数据。但研究表明,包含错误尝试、辩论和修正过程的对话数据,其训练效果可能与仅含标准答案的数据一样好,甚至更好。因为模型学习的重点是探索和验证的过程本身。
- 设计“有益的认知冲突”:不必追求模型内部思维的绝对和谐。数据显示,在人格特质维度上(如外向性、开放性、神经质),较高的多样性对推理有益;而在任务导向的维度(如尽责性)上则需要保持一致。这类似于一个高效的人类团队:成员背景和思维角度多样,但对完成目标的责任感高度统一。
- 直接干预模型的“社交大脑”:通过 SAE 等可解释性工具,开发者现在有了更精细的手段。研究发现,在数万个特征中,有 5,455 个与人格相关,15,436 个与专业知识相关。这为直接调节模型的“社交活跃度”和“专家多样性”提供了巨大的参数空间。
论文作者之一 James Evans 点明了核心:“仅仅‘让AI辩论’是不够的,你需要真正不同的观点和倾向,让辩论变得不可避免。”
总结与思考
实际上,这一发现与人类自身的思考方式有异曲同工之妙。当我们在深思一个复杂问题时,大脑中往往也有多个“声音”在交织博弈——理性的计算、感性的顾虑、冒险的冲动、谨慎的评估等。这与爱德华·德博诺提出的“六顶思考帽”思维方法在逻辑上相通。如今,我们发现先进的大语言模型似乎也无师自通地掌握了这套“内心辩论法”,通过让不同的内部思维角色分工、协作甚至冲突,最终得到更稳健、更可靠的答案。
这项研究也提示我们,对于企业而言,那些看似“低效”的头脑风暴会议记录、技术评审中的争论过程、产品方向的反复探讨,可能正是训练下一代具备更强推理能力AI的珍贵素材。因为连AI都向我们证明了一个道理:真正的智慧往往并非源于毫无争议的共识,而是来自于懂得如何开展并管理一场有建设性的“争议”。
本研究的相关论文可在 arXiv 上查阅:https://arxiv.org/pdf/2601.10825v1
对人工智能模型内部工作机制和推理能力优化感兴趣?欢迎在 云栈社区 的人工智能板块与更多开发者和研究者交流探讨。
 发表于 2026-2-1 19:40:48
|
查看: 217|
回复: 0
发表于 2026-2-1 19:40:48
|
查看: 217|
回复: 0
