引言与挑战
在量化交易领域,自动挖掘高质量的公式化Alpha因子是资产管理和量化策略开发的核心难题。Alpha因子本质上是一个将历史市场数据(如价格、成交量)映射为对未来收益预测的显式数学函数。传统的挖掘方法面临着巨大且复杂的函数形式空间挑战,导致搜索效率低下且产出大量无效或不可解释的因子。

现有的Alpha挖掘方法主要分为三类,各有其局限性:
- 启发式/专家驱动方法:依赖金融直觉(如市盈率、动量),虽然直观但扩展性有限,且策略易因广泛采用而失效。
- 数据驱动学习方法:包括回归、树模型和深度神经网络,能捕捉复杂非线性模式,但往往是“黑箱”,缺乏可解释性,存在过拟合风险。
- 公式化Alpha方法:强调由预定义算子组成的可读数学表达式,因其透明性和可解释性而备受重视,但计算成本高昂。
当前基于遗传规划(GP)或强化学习的公式化方法面临两大核心局限:
- 缺乏语言学特征描述:在无结构化、无界的空间中进行搜索,导致大量句法无效的表达式产生,效率低下。
- 语义冗余:许多句法不同的数学序列在语义上等价,现有方法将其视为独立个体,造成了表示学习和搜索过程中的系统性浪费。
AlphaCFG框架概述
为了系统性解决上述问题,研究者提出了AlphaCFG框架。该框架将Alpha挖掘重新定义为结构化语言生成与学习问题,而非非结构化的数学表达式搜索。其核心创新在于结合了形式化文法与强化学习,利用文法作为显式的归纳偏置,从三个层面重塑了挖掘过程:

- 文法约束:提出α-Syn(句法文法)和α-Sem(语义文法),结合金融领域知识,强制生成句法正确且语义有效的树状结构因子,并通过长度约束控制复杂度。
- 空间结构化:基于文法将挖掘过程建模为大型树结构语言马尔可夫决策过程(TSL-MDP),其中状态为部分表达式,奖励为真实市场数据的IC值。
- 语法感知学习:设计语法感知的蒙特卡洛树搜索(MCTS)算法,利用Tree-LSTM对部分表达式树进行编码,实现结构感知的价值评估与策略优化。
可解释Alpha因子的设计语言
公式化Alpha因子的空间随表达式长度呈组合级数增长。AlphaCFG引入了基于上下文无关文法(CFG)的形式化语言描述,将搜索空间限制为“良构”表达式,并天然支持树状搜索。
句法有效的Alpha语言(α-Syn)
首先定义确保句法有效性的文法。句法有效性要求生成的表达式必须是结构良构的可执行符号程序,具体包括:
- 前缀表示法(Prefix Notation):消除运算符优先级歧义。
- 算子元数(Arity)一致性:严格遵循算子所需的操作数数量。
生成规则如下:
Expr → Op(Expr,...) | TermSym
其中 Expr 是递归可扩展的非终结符,Op 是前缀算子(如一元、二元、滚动算子),TermSym 是终结符(特征或常数)。该规则强制每个有效推导拥有唯一的层次化表示,称为抽象语法表示(ASR)。
语义可解释的Alpha语言(α-Sem)
仅有句法有效性无法保证在量化交易中的语义合理性。α-Sem在α-Syn基础上嵌入了金融领域的语义约束:
- 滚动窗口约束:滚动算子的窗口大小参数必须是整数常数。
- 非平凡性:表达式不能仅由常数和算子组成。
- 数值有效性:操作数必须位于算子定义的有效域内。
- 时间序列一致性:配对滚动算子必须作用于两个时变特征,不允许常数操作数。
长度有界文法(α-Sem-k)
尽管α-Sem保证了语义有效性,但其递归规则仍可生成无限深度的表达式。为了使搜索空间可解,引入k-bounded约束。系统维护一个计数器k,上限为K。每个生产规则对应一个增量成本Δk。只有当 k + Δk ≤ K 时,规则才可应用。这一约束生成了有界语义文法α-Sem-k,产生一个有限但表达力强的假设空间。
Alpha空间结构
上述文法生成的Alpha语言空间呈现嵌套结构,约束越强,假设空间越小且结构化程度越高。在α-Sem-k定义下,Alpha挖掘转化为对一个大型推导树的探索。树的根节点是起始符号,边是生产规则,中间节点是部分推导出的表达式,叶节点是完全推导出的Alpha因子。
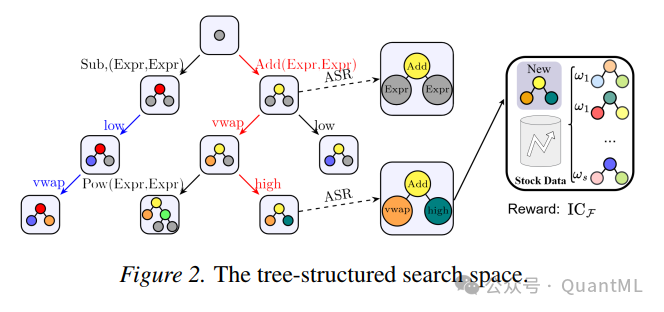
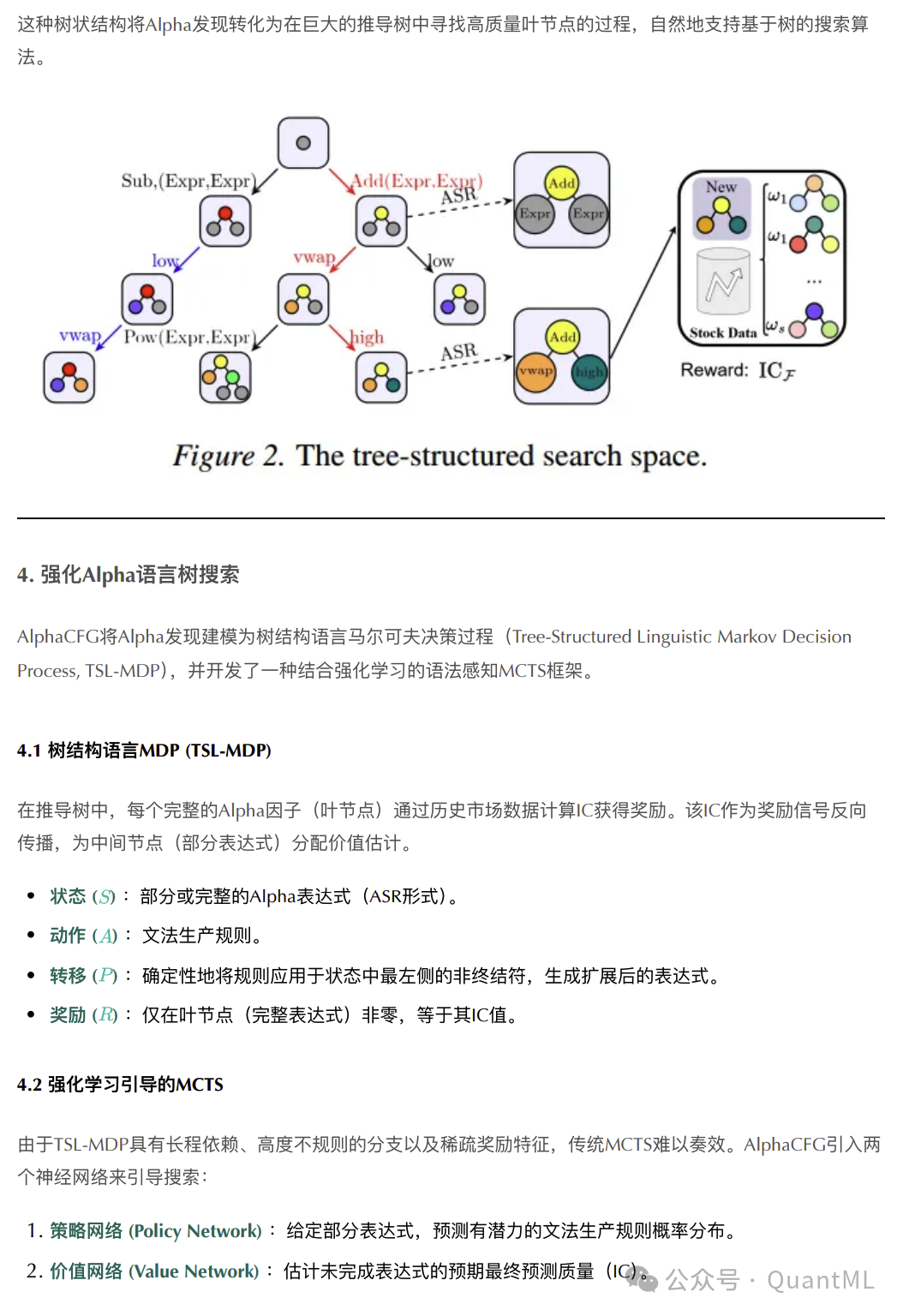
这种树状结构将Alpha发现转化为在巨大的推导树中寻找高质量叶节点的过程,自然地支持基于树的搜索算法。

强化Alpha语言树搜索
AlphaCFG将Alpha发现建模为树结构语言马尔可夫决策过程(TSL-MDP),并开发了一种结合强化学习的语法感知MCTS框架。
树结构语言MDP (TSL-MDP)
在推导树中,每个完整的Alpha因子(叶节点)通过历史市场数据计算IC获得奖励。该IC作为奖励信号反向传播,为中间节点分配价值估计。
- 状态 (S):部分或完整的Alpha表达式(ASR形式)。
- 动作 (A):文法生产规则。
- 转移 (T):确定性地将规则应用于状态中最左侧的非终结符,生成扩展后的表达式。
- 奖励 (R):仅在叶节点(完整表达式)非零,等于其IC值。
强化学习引导的MCTS
由于TSL-MDP具有长程依赖、高度不规则的分支以及稀疏奖励特征,传统MCTS难以奏效。AlphaCFG引入两个神经网络来引导搜索:
- 策略网络:给定部分表达式,预测有潜力的文法生产规则概率分布。
- 价值网络:估计未完成表达式的预期最终预测质量(IC)。
MCTS组件详解
算法在每个根状态执行以下步骤:
-
选择(Selection):
采用分支自适应的PUCT规则。由于不同非终结符对应的生产规则数量差异极大,标准PUCT效率低下。改进后的规则引入自适应项 b/b_ref,其中 b 是当前分支数,b_ref 是最大分支数。该机制在分支较少时强调整利用,分支较多时鼓励探索:
a* = argmax_a ( Q(s,a) + c_puct * sqrt( b / b_ref * P(s,a) ) * sqrt( Σ_b N(s,b) / (1 + N(s,a)) ) )
-
扩展(Expansion)与评估(Evaluation):
当到达未完全展开的“前沿”节点时,应用所有有效的α-CFG规则生成子状态。利用价值网络 V(s) 评估新状态的预期收益,利用策略网络 P(s, a) 提供先验概率。这一步避免了昂贵的基于模拟的评估,直接利用学习到的句法特征进行推断。
-
回溯(Backpropagation):
将评估结果 V(s) 沿选择路径反向传播,更新Q值和访问计数 N(s, a)。
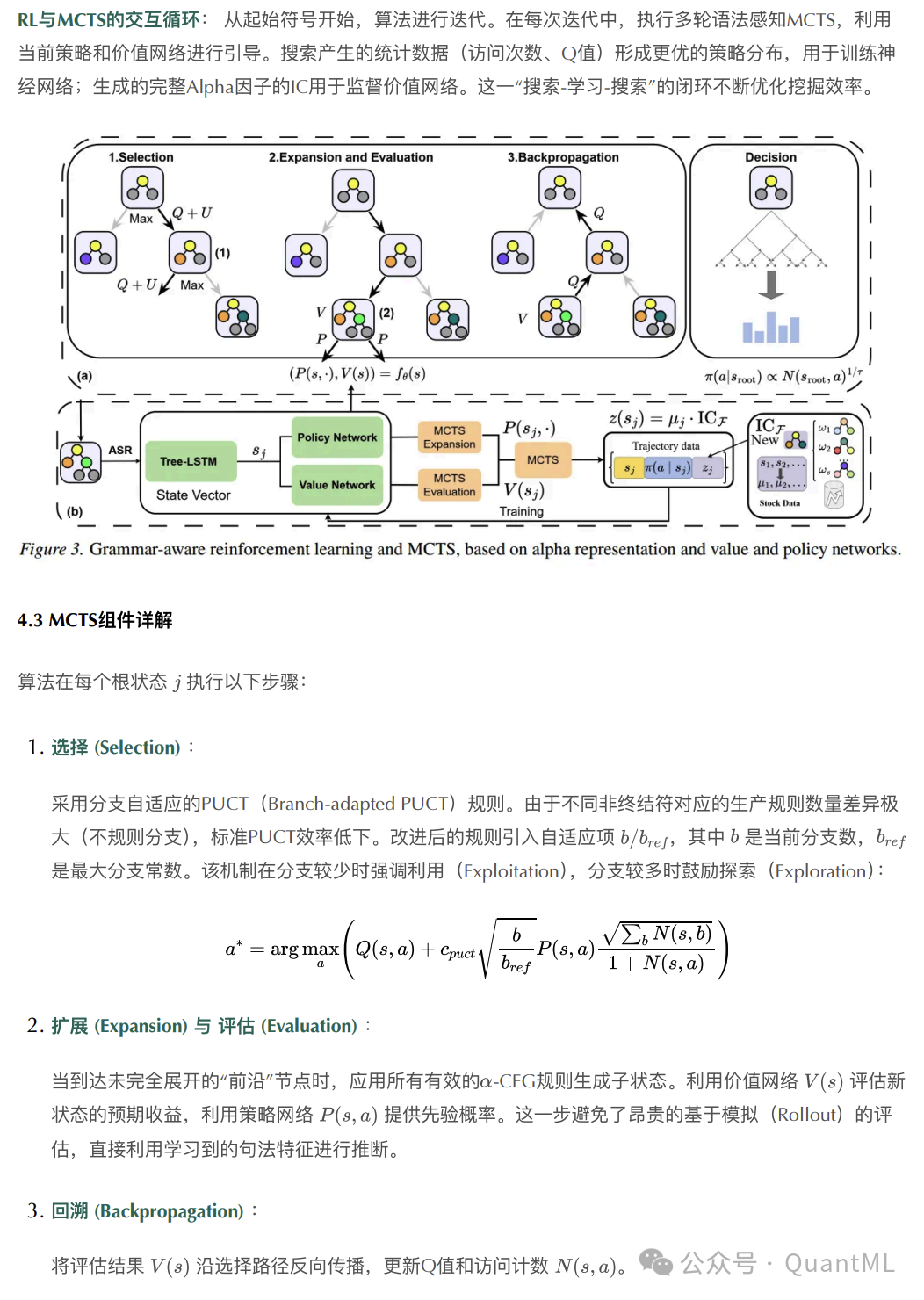
RL与MCTS形成交互循环:从起始符号开始,算法进行迭代。在每次迭代中,执行多轮语法感知MCTS,利用当前策略和价值网络进行引导。搜索产生的统计数据形成更优的策略分布,用于训练神经网络;生成的完整Alpha因子的IC用于监督价值网络。这一“搜索-学习-搜索”的闭环不断优化挖掘效率。
语法表示学习
TSL-MDP的核心挑战在于状态空间的巨大和冗余。由于算子的对称性,存在大量同构因子。AlphaCFG采用Tree-LSTM编码器直接对抽象语法树进行编码,而非线性序列。
- 网络设计:Tree-LSTM递归地聚合子节点的隐藏状态。
- 处理同构冗余:
- 对于对称算子(如Add, Mul),采用Child-Sum Tree-LSTM(求和聚合),忽略子节点顺序,从而为语义相同的不同句法排列生成相同的嵌入向量。
- 对于非对称算子(如Div, Sub),采用N-ary Tree-LSTM(位置敏感聚合),保留顺序信息。
多样性感知价值目标
为了构建高效的因子组合,必须避免生成结构高度相似的因子。AlphaCFG在价值目标中引入了结构相似性惩罚。定义归一化的结构相似度度量 sim(·,·)。对于新生成的因子 f_j,其修正后的价值目标 z(s_j) 为:
z(s_j) = (1 - max(0, max_{f_t ∈ F} sim(f_t, f_j))) · IC_F
其中 F 是现有因子池。该机制惩罚与现有因子结构重叠度高的状态,鼓励探索结构多样的Alpha因子。
实验验证
实验设置
- 数据集:中国A股CSI 300成分股和美股S&P 500成分股。
- 时间划分:训练集(2010-2017),验证集(2018-2019),测试集(2021-2024)。排除2020年以避免疫情极端数据干扰。
- 基准方法:
- 公式化挖掘:AlphaGen, AlphaQCM, GPlearn。
- 机器学习模型:XGBoost, LightGBM, LSTM, ALSTM, TCN, Transformer。
- 评估指标:Rank IC, IC, Rank ICIR, Sharpe Ratio, Max Drawdown。
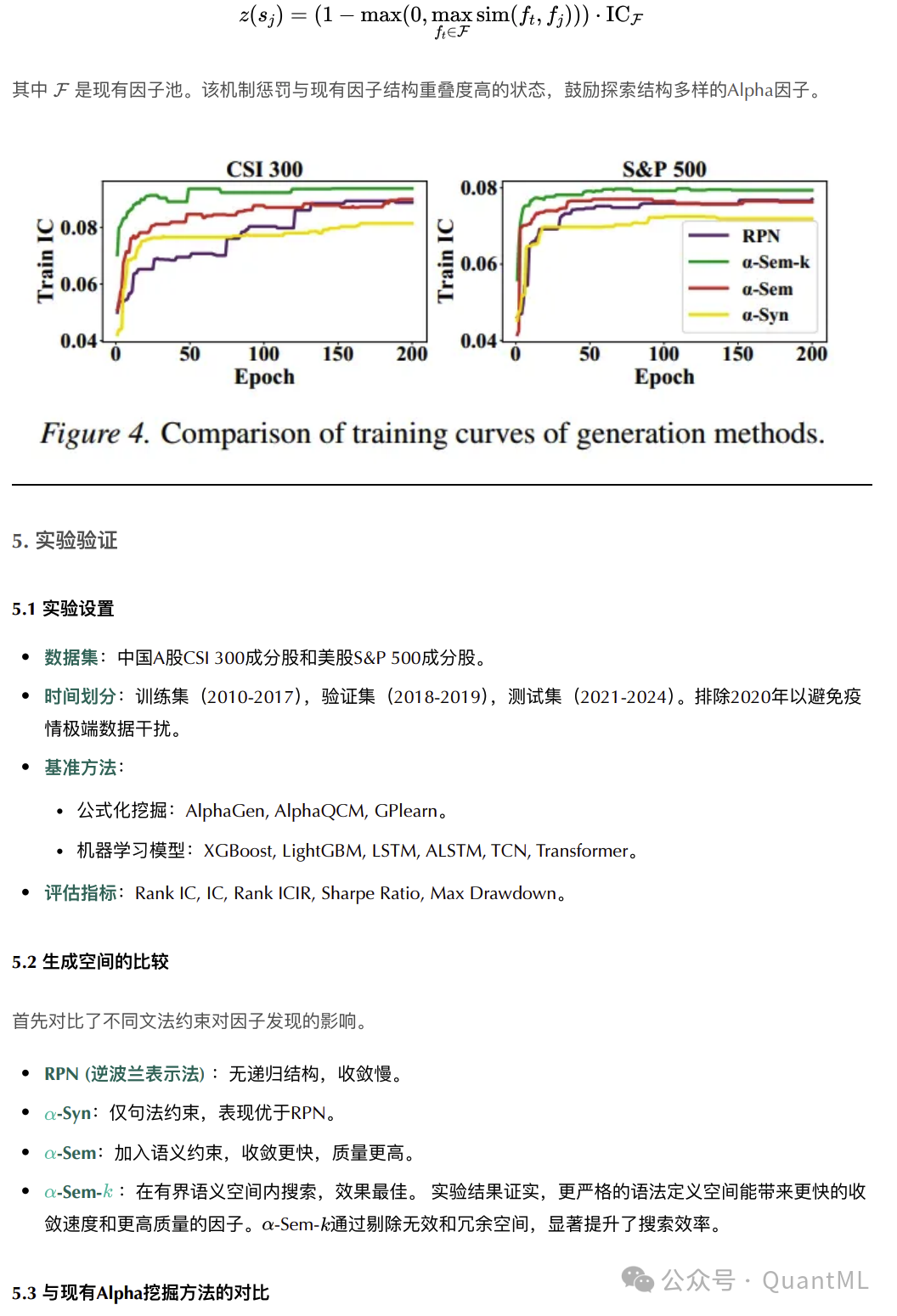
生成空间的比较
首先对比了不同文法约束对因子发现的影响。
- RPN:无递归结构,收敛慢。
- α-Syn:仅句法约束,表现优于RPN。
- α-Sem:加入语义约束,收敛更快,质量更高。
- α-Sem-k:在有界语义空间内搜索,效果最佳。
实验结果证实,更严格的语义定义空间能带来更快的收敛速度和更高质量的因子。α-Sem-k通过剔除无效和冗余空间,显著提升了搜索效率。
与现有方法的对比
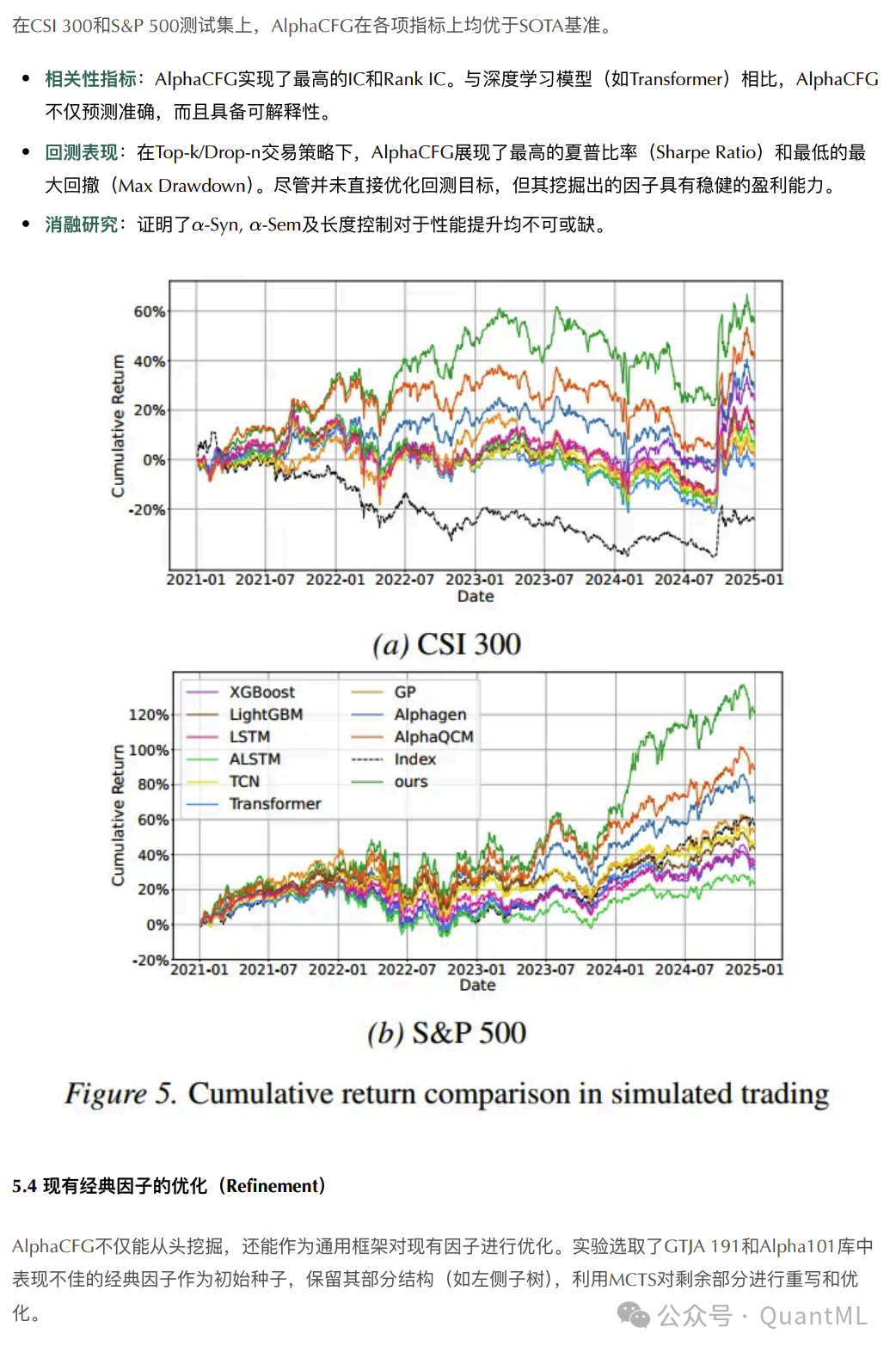
在CSI 300和S&P 500测试集上,AlphaCFG在各项指标上均优于基线模型。
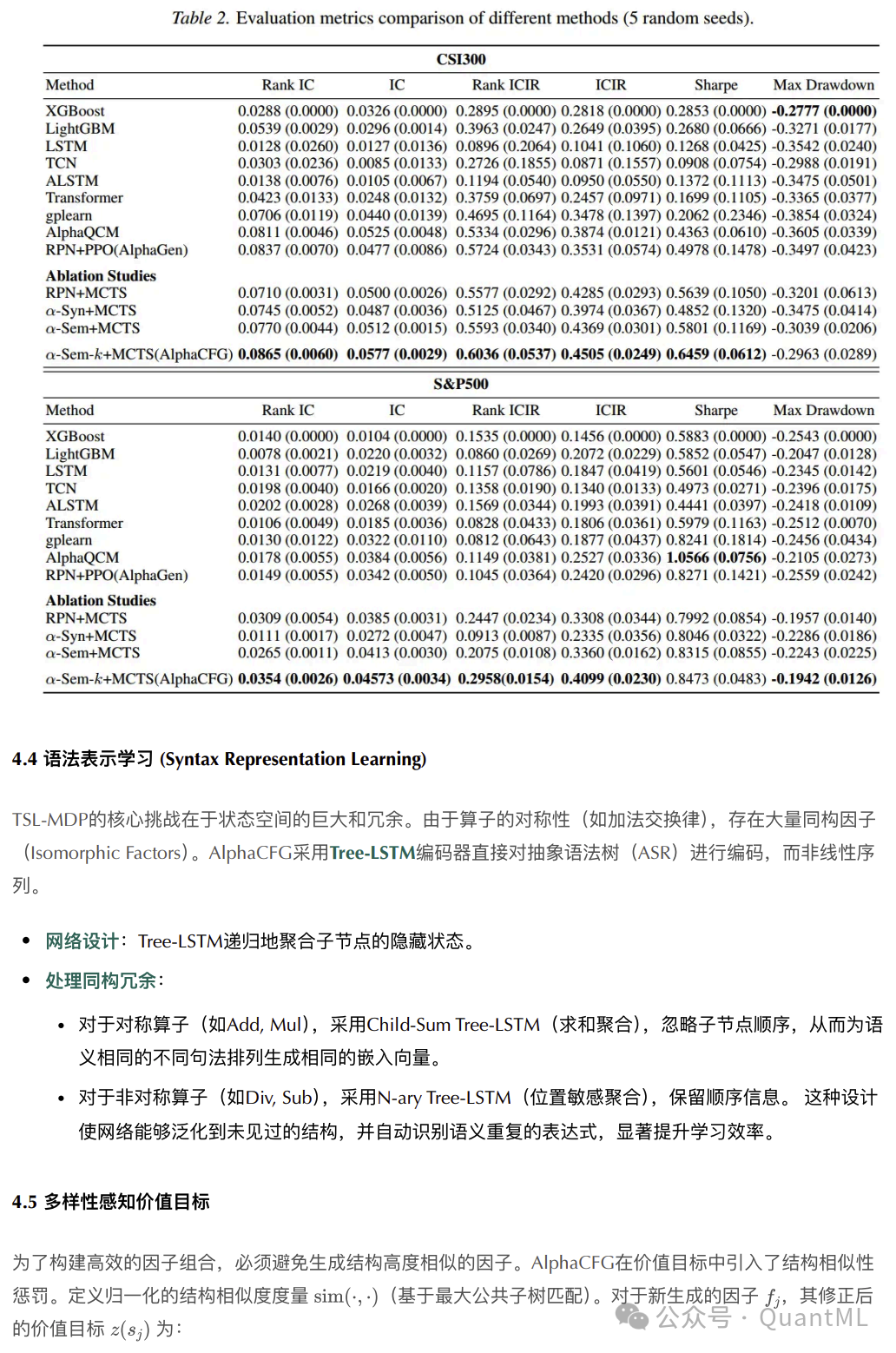
- 预测指标:AlphaCFG实现了最高的IC和Rank IC。与深度学习模型相比,它不仅预测准确,而且具备可解释性。
- 回测表现:在模拟交易中,AlphaCFG展现了最高的夏普比率和最低的最大回撤。尽管并未直接优化回测目标,但其挖掘出的因子具有稳健的盈利能力。
- 消融研究:证明了α-Syn, α-Sem及长度控制对于性能提升不可或缺。
现有经典因子的优化
AlphaCFG不仅能从头挖掘,还能作为通用框架对现有因子进行优化。实验选取了GTJA 191和Alpha101库中表现不佳的经典因子作为初始种子,保留其部分结构,利用MCTS对剩余部分进行重写和优化。
结果:经过α-Sem-k+MCTS框架的微调,许多失效因子的IC值在测试集上显著提升。这证明了AlphaCFG在因子增强和存量因子维护方面的实用价值。

可解释性案例研究
AlphaCFG挖掘出的因子具有清晰的金融逻辑。例如:
- 因子
Log(|Std(C(0.05-volume),40)|) 捕捉了过去40天逆向交易量的波动率,衡量了非流动性的时间变化,可能预示市场压力或价格冲击。
- 因子
Cov(volume, vwap, 40) 捕捉了成交量与成交均价的协动性,反映了市场趋势的一致性。
这些不仅是数学公式,更对应了具体的微观市场结构理论。
结论
AlphaCFG建立了一个基于语法的通用框架,系统地解决了公式化Alpha因子挖掘中的搜索空间无界、无效表达式泛滥及语义冗余等核心问题。

- 方法论创新:通过上下文无关文法将无结构的符号搜索转化为树结构语言MDP,利用句法和语义约束严格界定了搜索边界。
- 算法创新:提出了语法感知的MCTS算法,结合Tree-LSTM网络和分支自适应PUCT规则,实现了在庞大且不规则的树空间中的高效搜索与策略学习。
- 实践性能:在中美股市数据上,AlphaCFG在搜索效率和交易收益方面均超越了现有的强化学习和进化算法基准。
- 通用性:该框架不仅限于从零数据挖掘,还展示了对现有经典因子进行符号化优化和增强的能力。
AlphaCFG展示了将领域知识编码进搜索空间(而非仅从数据中隐式学习)在符号回归任务中的巨大潜力。未来的工作方向包括集成为大规模预训练模型作为先验,进一步加速结构化推理问题的泛化求解。
拓展阅读:对量化金融、机器学习与强化学习的交叉应用感兴趣?欢迎到云栈社区的智能与数据板块,与更多开发者和研究者交流前沿技术与实战心得。
 发表于 2026-2-2 07:13:12
|
查看: 242|
回复: 0
发表于 2026-2-2 07:13:12
|
查看: 242|
回复: 0
