
在量化投资领域,Alpha因子的挖掘长期依赖于人工经验、统计假设与反复试错。这一过程不仅效率低下,也难以应对快速变化的市场结构。
近期,来自香港科技大学与北京大学的研究团队提出了一套将大语言模型引入量化策略生成核心流程的完整框架 —— Automate Strategy Finding with LLM in Quant Investment。这项研究的雄心在于,尝试将“读研报、找逻辑、写公式、做回测、调权重”这一整套研究链条实现自动化。
与以往将LLM用作情绪分析或新闻摘要工具的方式不同,这项工作直接让LLM参与了公式化Alpha因子的生成、筛选与组合构建。更为关键的是,它通过一个多智能体系统,将风险约束与市场状态识别机制嵌入其中,最终形成可执行的投资策略。
核心目标是构建一个无需人工干预、可持续更新的Alpha工厂。
传统Alpha挖掘的局限性
随着量化因子研究的不断扩展,策略的稳定性与研究效率并未得到同步提升。核心问题正逐渐从“算力不足”转向“方法受限”。
第一,市场结构变化加快。 历史统计关系持续弱化,模型对市场状态切换的适应能力不足,导致因子的有效性容易衰减。
第二,数据形态高度异构。 价格数据、财报信息、文本新闻与图像信息分散处理,多源信息难以在一个统一框架中进行有效建模,从而限制了Alpha的表达能力。
第三,单因子有效不等于组合稳定。 不同市场环境下,因子的风格表现差异显著,而传统的权重分配往往缺乏动态调整机制。
研究者将问题归纳为三个连续的层面:
- 如何形式化地表达Alpha?
- 如何在市场变化中筛选出持续有效的因子?
- 以及如何在投资组合层面动态配置权重,以平衡收益与风险?
围绕这三点,论文构建了一个三阶段系统,将LLM的知识抽取能力、多智能体的情境评估能力与深度学习的权重优化能力整合为一个闭环流程,使得因子生成、筛选与组合构建能够实现自动化的无缝衔接。
核心方法
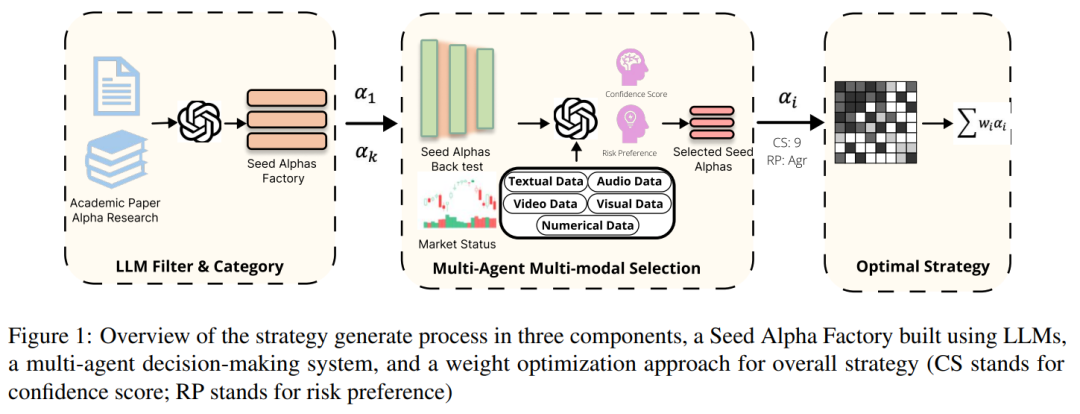
整个系统由三个核心模块构成。
1. LLM驱动的Seed Alpha生成
第一阶段是LLM驱动的Seed Alpha生成。研究使用GPT-4o对金融研究文献进行解析与归类。他们从11份理论与实证研究文档中,提取并组织出9个因子类别、共计100个可执行的Seed Alpha,覆盖了动量、均值回归、波动率、基本面等多个维度,并形成了结构化的公式表达。
Alpha的表达形式被统一写成截面算子与时间序列算子的组合。其预测能力用信息系数来衡量,即因子值与未来收益的相关系数。
2. 多模态多智能体评估系统
第二阶段是多模态多智能体评估系统。该系统能够同时处理文本、数值、图像等多种模态的信息,并由两个核心智能体分工协作:
- 置信度评分智能体(CSA):负责评估因子的统计稳定性与预测置信度。
- 风险偏好智能体(RPA):负责评估因子在不同风险环境下的表现。
筛选的目标函数综合了置信度评分与风险偏好评分,并引入了类别均衡机制,以避免选出的因子过度集中在某一类别。
3. 动态权重优化
第三阶段是动态权重优化。研究采用了一个三层的多层感知机模型,将历史的Alpha因子数据与未来的收益进行映射,从而自动学习在不同市场状态下各个因子的最优配置权重。
实验结果
因子筛选质量验证
在五大类Alpha因子上,经过LLM生成并由多智能体系统筛选后的因子,其平均信息系数全面高于原始的种子因子集。
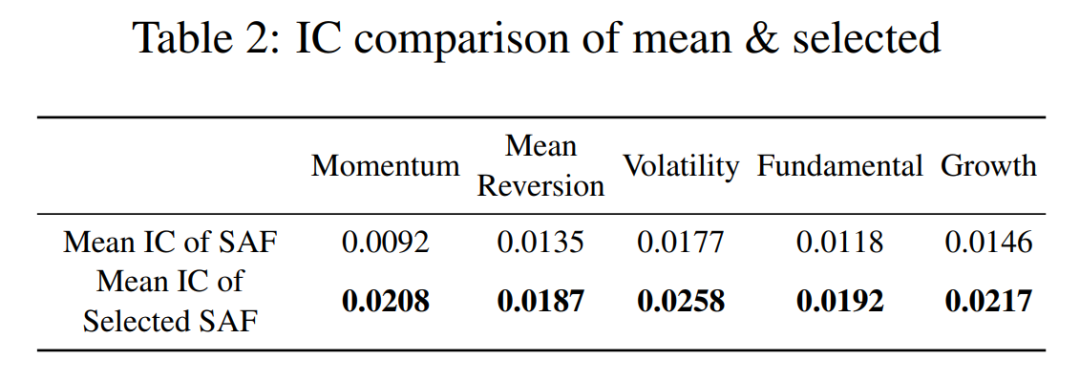
可以看到,在波动率与基本面维度,筛选后的提升尤为明显。这说明LLM在结构化金融知识抽取方面所展现的能力,具备转化为有效交易信号的潜力。
SSE50回测结果
在2023年1月至2024年1月对SSE50指数的回测中,该框架构建的投资组合实现了53.17%的累计收益,而同期的指数表现为-13.22%。
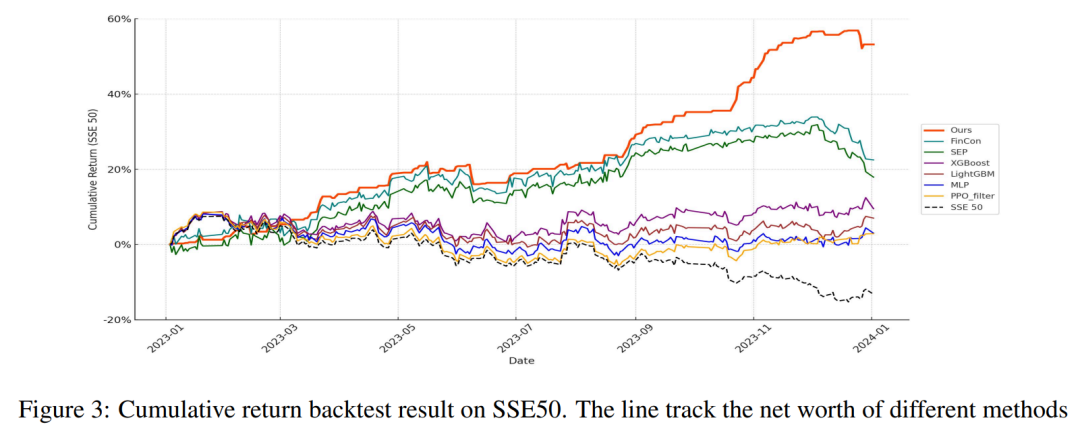
从风险收益指标来看:
- 夏普比率 0.287
- 索提诺比率 0.208
- 卡尔玛比率 1.052
- 波动率 0.762%
这些指标均显著优于XGBoost、LightGBM、MLP、PPO以及另外两种基于LLM多智能体的方法FinCon和SEP。

跨市场与跨周期稳健性
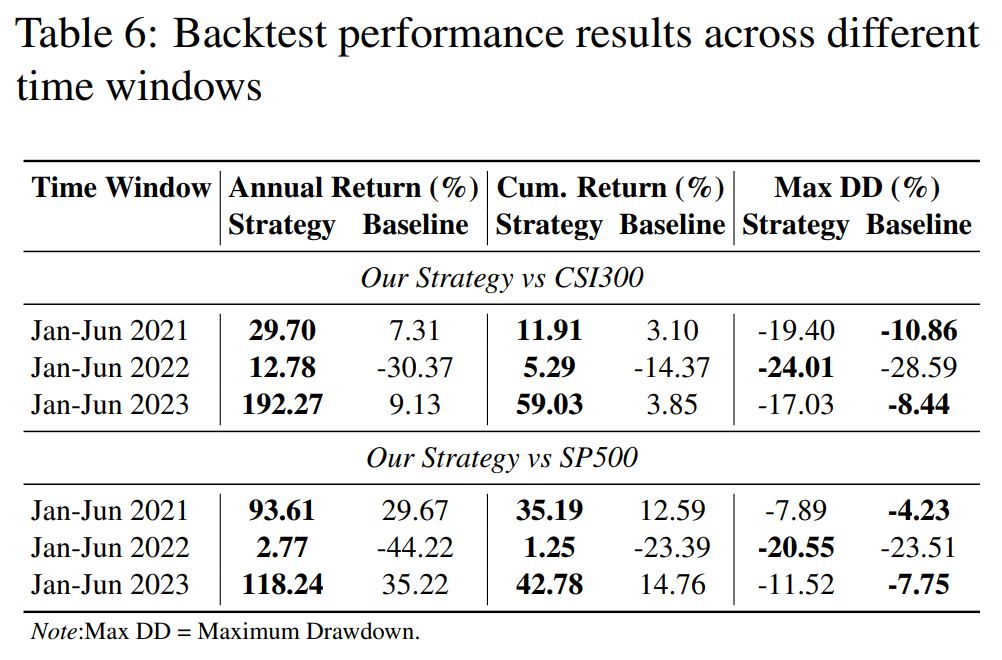
研究还在沪深300与标普500的成分股上进行了滚动时间窗口的验证。
以2023年上半年为例:
- 在沪深300上,策略年化收益达192.27%,而基准仅为9.13%。
- 在标普500上,策略年化收益为118.24%,基准为35.22%。
即使在2022年的下行市场阶段,该策略依然保持了正收益:
- 在沪深300上收益为12.78%,远超基准的-30.37%。
- 在标普500上收益为2.77%,而基准为-44.22%。
这表现出了明显的逆周期特征和抗风险能力。
多智能体结构的贡献度
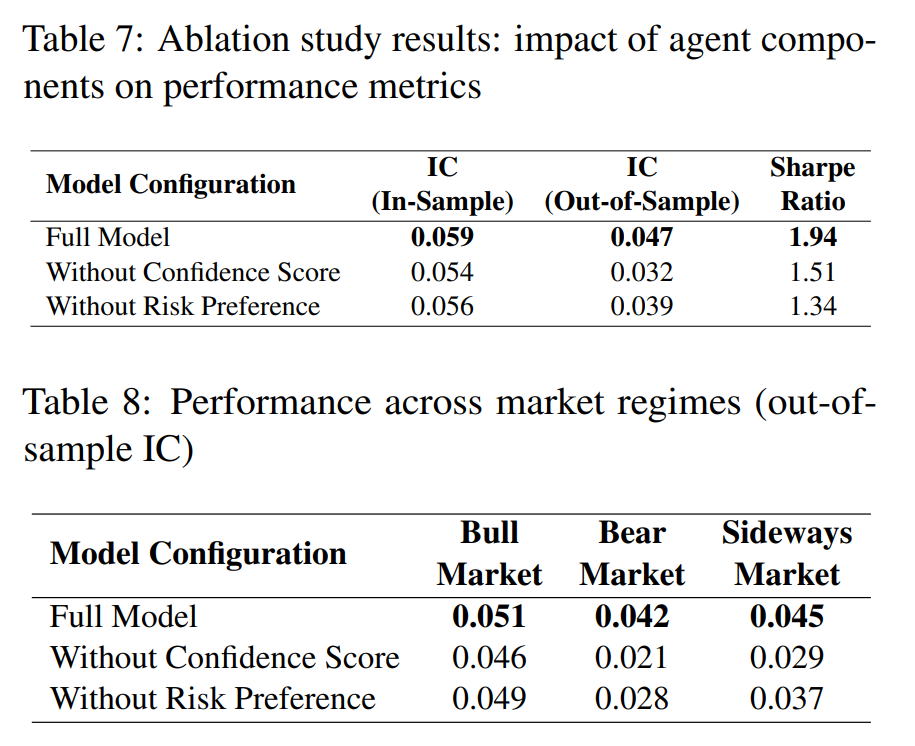
消融实验的结果清晰地展示了多智能体组件的重要性:
- 完整模型的样本外IC为0.047,夏普比率为1.94。
- 移除置信度评分智能体(CSA)后,样本外IC降至0.032,夏普比率降至1.51。
- 移除风险偏好智能体(RPA)后,夏普比率进一步下降至1.34。
特别是在熊市环境中,没有CSA的模型IC仅为0.021,而完整模型为0.042。实验结果表明,CSA对于保持预测的稳定性贡献最为关键,而RPA则提升了策略在复杂风险环境下的收益质量。对于如何处理海量的金融数据并从中提取稳定信号,这一框架提供了新的思路。
方法定位与局限
作者将该框架定位为连接LLM强大推理能力与量化投资实务的中间层架构。其优势在于实现了跨模态知识的整合与策略的持续更新能力。当然,研究也存在一定的局限性,例如对输入文献质量的依赖、部分生成的Alpha因子可能缺乏实际交易可行性,以及在极端市场制度变迁下,基于历史关系的模型可能失效。
结语
这项研究展示了大语言模型在量化投资领域角色演变的清晰路径:从一个辅助分析工具,向策略生成的核心组件转变。通过Seed Alpha工厂、多智能体风险评估与深度学习权重优化三者的紧密结合,该系统在多个市场、多个周期中都验证了其良好的可迁移性与稳健性。这为未来完全自动化的量化研究流程提供了一个颇具启发性的蓝本。
 发表于 2026-1-31 09:34:31
|
查看: 295|
回复: 0
发表于 2026-1-31 09:34:31
|
查看: 295|
回复: 0
