笔记整理:张婷,东南大学硕士,研究方向为自然语言处理
论文链接:https://arxiv.org/abs/2410.20724
发表会议:ICLR 2025
动机
如今,大语言模型虽然在复杂推理任务上表现出色,但仍然受制于信息不准确和知识过时的困扰。为了应对这一挑战,基于知识图谱的检索增强生成方法逐渐成为一种主流策略。它通过从结构化的外部知识库中精准查找相关信息,来为LLM的推理提供可靠的事实支撑。
然而,现有的KG-based RAG框架往往面临一个两难境地:要么为了保证检索质量而牺牲效率,要么为了追求速度而损害了多跳推理所必需的结构信息捕捉能力。怎样才能在不影响性能的前提下,实现高效、精准的子图检索呢?
针对这一问题,来自乔治亚理工学院的研究者在ICLR2025论文中提出了 SubgraphRAG 框架。它巧妙地结合了轻量级多层感知机和并行三元组评分机制,实现了高效的子图检索。同时,该方法引入了方向性结构距离编码来增强对图谱结构信息的感知,从而在多跳推理任务中表现优异。更值得一提的是,SubgraphRAG允许灵活调整检索子图的大小,以适应不同规模下游LLM的推理能力,整个过程无需微调,展现出了出色的灵活性与适应性。
贡献
本文的主要贡献可以概括为以下三点:
- 高效且结构感知的检索器:通过结合MLP与并行三元组评分,显著提升了子图检索的效率,同时保留了进行结构化推理所必需的关键信息。
- 创新的结构编码方法:提出了方向性结构距离编码,能够有效建模实体与主题实体之间的结构关系,显著增强了方法在复杂多跳问题上的处理能力。
- 灵活可调的检索机制:框架可以动态调整检索子图的规模,以适应不同能力LLM的上下文窗口和推理需求,在保证性能的同时避免了信息冗余或丢失,且整个过程是零样本的,无需额外训练。
方法
SubgraphRAG的整体框架由三个核心模块组成:主题实体提取、子图检索、LLM推理,其工作流程如下图所示:
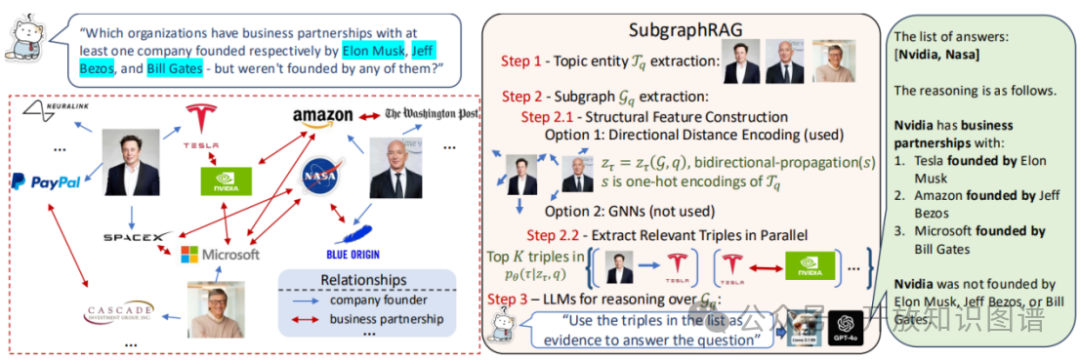
图1:SubgraphRAG整体框架图
第一步:主题实体提取
首先,系统从用户输入的查询问题中提取出相关的主题实体。这些实体是后续从庞大的知识图谱中进行精准检索的“锚点”。
第二步:子图检索
这是本方法的创新核心。系统以主题实体为起点,从一个大型知识图谱G中检索出与问题最相关的一个子图G_q。检索过程被形式化为一个优化问题,目标是通过训练一个参数化模型,使其检索出的子图能够最大程度地帮助LLM回答问题A_q。其优化目标函数如下:
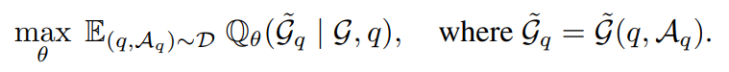
为了实现高效检索,作者将子图的分布按三元组进行独立因子分解。这意味着模型可以并行地对知识图谱中的每个候选三元组τ,独立地计算其被选中进入相关子图的概率p_θ(τ | z_τ, q)。最终,通过并行排序,选出概率最高的K个三元组,组合成检索子图G_q。其概率公式如下:

这里的打分器p_θ是一个轻量级的MLP模型,它从语义和结构两个维度对三元组进行评分。
- 语义特征:将问题文本、三元组中的头实体、关系和尾实体的文本描述分别编码成向量,计算它们在语义空间中的匹配程度。
- 结构特征:这是本工作的亮点。为了捕捉多跳推理中至关重要的路径信息,作者提出了方向性结构距离编码。其核心思想是为每个实体计算一个“签名”,这个签名编码了该实体相对于问题中所有主题实体的有向距离关系。具体通过多轮双向均值扩散(Bidirectional Mean Diffusion)来计算:

通过这种方式,模型能够感知到“Nvidia通过合作连接到Tesla(Elon Musk创立)”这样的多跳关系,而不仅仅是“Nvidia是一个公司”这样的孤立事实。
第三步:LLM推理
最后,将检索到的子图G_q线性化(例如,转换为一系列三元组文本描述),与原始问题q一起填充到一个设计好的提示模板中,形成“问题+证据”的上下文,输入给下游的大语言模型进行最终推理并生成答案。
实验
为了全面评估SubgraphRAG,作者设计了实验来回答以下四个核心研究问题:
- Q1(效率与效果):SubgraphRAG能否在低延迟条件下有效检索相关信息?
- Q2(复杂问题处理):对于需要多跳推理的复杂问题,SubgraphRAG能否有效利用结构信息?
- Q3(整体性能):在知识图谱问答任务上,SubgraphRAG的整体表现如何?受哪些因素影响?
- Q4(可解释性与抗幻觉):框架能否提供可靠的解释,从而减少LLM的幻觉?
实验在两个具有挑战性的多跳知识图谱问答数据集上进行:WebQSP和CWQ。同时,为了专门评估抗幻觉能力,还创建了它们的子集(WebQSP-sub和CWQ-sub),滤除了答案不在知识图谱中的样本。
检索性能(回答Q1,Q2)
下表展示了SubgraphRAG在检索任务上的表现。在“Triples”(检索三元组的召回率)和“Entities”(检索实体的召回率)等多个关键指标上,SubgraphRAG均显著优于所有基线模型。在效率方面,其速度仅比最简单的基于余弦相似度的基线稍慢,但比其他复杂的检索方法(如GNN-RAG, Retrieve-Rewrite-Answer)快了一到两个数量级,完美平衡了效果与效率。

表1:检索性能实验结果
问答性能(回答Q3,Q4)
下表展示了将SubgraphRAG与不同大语言模型结合后在问答任务上的性能。可以看到,SubgraphRAG + GPT-4o-mini (500) 在WebQSP数据集上达到了91.22%的Hit@1分数,创造了新的SOTA性能。即使在抗幻觉的子集上(如下表所示),SubgraphRAG配合强大的LLM也取得了极具竞争力的结果,表明其检索的证据能有效支撑LLM生成基于事实的答案,减少胡编乱造。
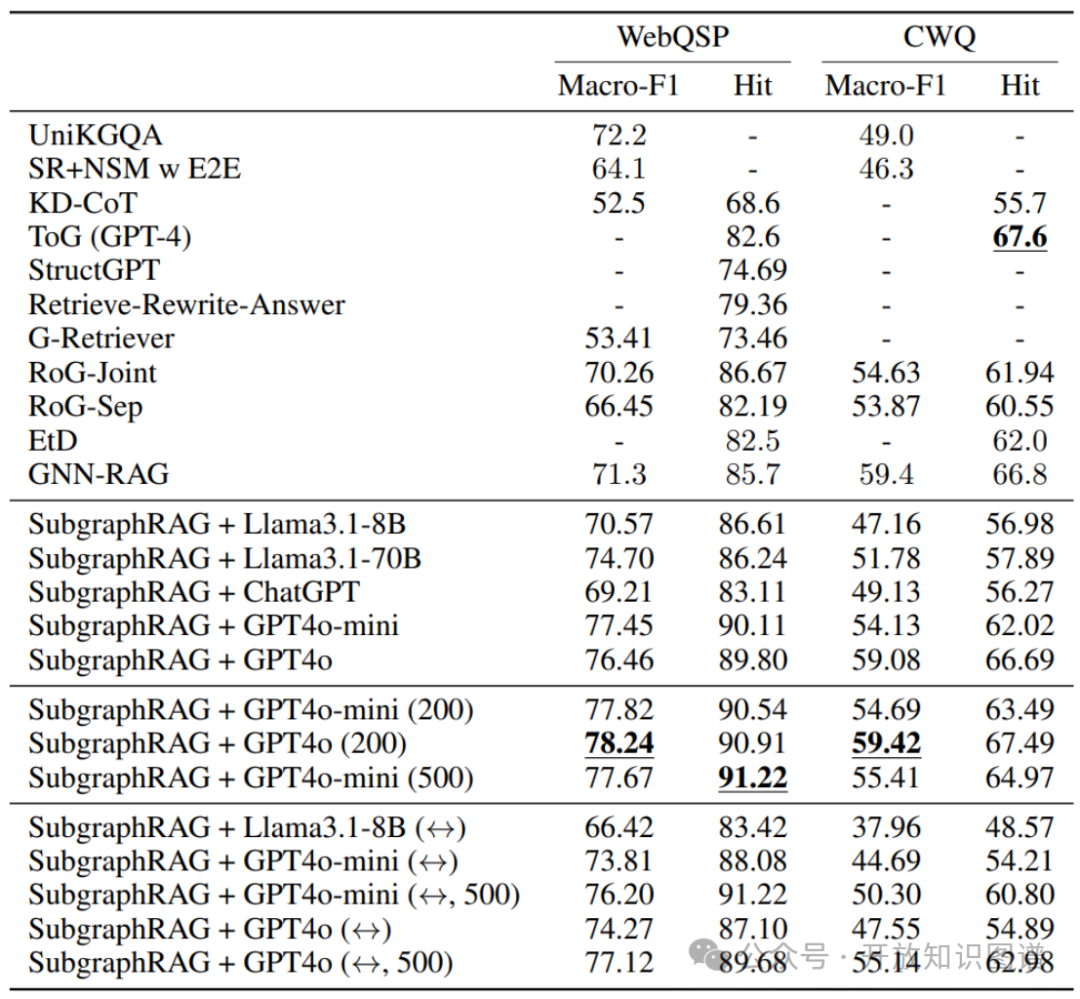
表2:问答实验结果
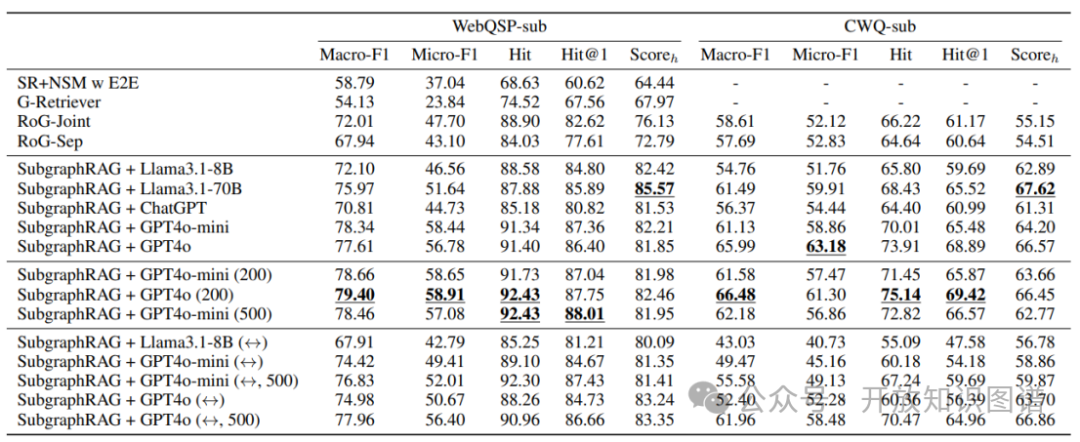
表3:在抗幻觉子集上的问答实验结果
此外,通过跳数分析等消融实验,论文进一步证实了DDE结构编码在处理多跳问题时的关键作用,并对检索结果进行了解释性分析,验证了其可靠性。
总结
本文提出的SubgraphRAG框架,为知识图谱与大语言模型的结合提供了一种新颖、高效且强大的解决方案。它通过轻量化的并行检索机制和创新性的结构编码,成功解决了传统方法在效率与深度推理能力之间的权衡难题。
实验证明,SubgraphRAG不仅在WebQSP和CWQ等多个权威基准上取得了领先的精度,更在推理效率上大幅优于传统方法。其无需微调、即插即用的特性,使得即使像Llama3.1-8B这样的中等规模模型,在获得高质量检索子图后,也能激发出媲美甚至超越GPT-4o的问答能力。这为在资源受限环境下部署高效可靠的知识图谱问答系统打开了新的可能性。
SubgraphRAG所展现出的优异性能、强大泛化能力和高可解释性,标志着基于知识图谱的检索增强生成技术向前迈出了坚实的一步,具有很高的理论研究价值与实际应用潜力。对RAG技术栈感兴趣的朋友,不妨深入研究这篇论文,或许能为你自己的项目带来新的启发。欢迎在云栈社区的人工智能板块交流探讨。
 发表于 2026-3-17 04:11:54
|
查看: 216|
回复: 0
发表于 2026-3-17 04:11:54
|
查看: 216|
回复: 0
