在2026世界读书日:不荐书,只荐这一份「Agent智能体圣经」清单中提到一份博客清单,本篇为其中的一篇《Introducing Contextual Retrieval》。
本文是一篇译文,为中文读者提供一个了解Agent智能体系统底层设计逻辑的入口,从而能够更好的理解和使用诸如Claude Code这样的Agent产品,仍然建议英文好的同学直接查看英文原文。
原文地址:
https://www.anthropic.com/engineering/contextual-retrieval
要让 AI 模型在特定场景中发挥作用,通常需要为其补充背景知识。例如,客户支持聊天机器人需要了解企业的具体业务,法律分析机器人则需要掌握海量的过往案例。
开发者普遍采用检索增强生成 (Retrieval-Augmented Generation,RAG) 来扩充模型的知识。RAG 会从知识库中检索相关信息,并将其追加到用户提示中,从而显著提升模型的回答质量。然而,传统的 RAG 方案在对信息进行编码时,往往会丢失上下文,导致系统经常无法从知识库中检索到真正相关的信息。
本文介绍的方法能够大幅改善 RAG 的检索步骤,我们称之为“上下文检索” (Contextual Retrieval)。该方法包含两项子技术:上下文嵌入 (Contextual Embeddings) 与上下文 BM25 (Contextual BM25)。这种方法可以将检索失败率降低 49%,如果与重排序技术结合,更能降低 67%。这些改进显著提升了检索准确率,并直接转化为下游任务中更优秀的表现。
你可以通过我们的 cookbook ① 轻松部署自己的上下文检索方案。
关于直接使用更长提示的说明
有时,最简单的方案就是最好的方案。如果你的知识库小于 20 万token(大约 500 页资料),完全可以将整个知识库放入提示中,无需使用 RAG 等方案。
几周前,我们为 Claude 推出了提示缓存功能②,这使得长提示方案的速度和成本效益大幅提升。开发者现在可以在 API 调用之间缓存常用提示,将延迟降低一半以上,并节省高达 90% 的成本(你可以阅读我们的提示缓存cookbook ③ 来了解具体原理)。
然而,随着知识库规模的增长,终究需要更具可扩展性的方案。这正是上下文检索的用武之地。
RAG 入门:扩展至更大型知识库
对于超出上下文窗口限制的大型知识库,RAG 是常见的解决方案。其工作原理是按以下步骤对知识库进行预处理:
- 将知识库(文档“语料库”)切分为较小的文本块,每个通常不超过几百个 token;
- 使用嵌入模型(Embedding Model)将每个文本块转化为能够编码语义的向量嵌入;
- 将这些嵌入存储到支持语义相似度搜索的向量数据库中。
在运行时,当用户输入查询时,系统会利用向量数据库找到与查询语义最相似的文本块。随后,这些最相关的文本块会被追加到发送给生成模型的提示中。
尽管嵌入模型擅长捕捉语义关系,但它们可能会遗漏至关重要的精确匹配。幸运的是,有一种更早的技术可以弥补这一不足。
BM25(Best Matching 25,最佳匹配 25) 是一种基于词汇匹配来查找精确单词或短语的排序函数。它对包含唯一标识符或技术术语的查询尤为有效。BM25 建立在 TF-IDF(词频-逆文档频率)概念之上,通过引入文档长度因素以及对词频饱和函数的处理,进一步优化了 TF-IDF,避免了常见词主导结果的问题。
下面是 BM25 在语义嵌入失效时如何发挥作用的一个例子:假设用户在技术支持数据库中查询 “Error code TS-999”。嵌入模型可能会找到一些关于错误代码的通用内容,但会遗漏 “TS-999” 这个精确匹配项。而 BM25 则专门查找这一特定文本字符串,从而精准识别出相关文档。
通过结合嵌入与 BM25 技术,RAG 方案可以更准确地检索到最合适的文本块,步骤如下:
- 将知识库(文档“语料库”)切分为较小的文本块,每个通常不超过几百个 token;
- 为这些文本块创建 TF-IDF 编码和语义嵌入;
- 使用 BM25 基于精确匹配找到最靠前的文本块;
- 使用嵌入基于语义相似度找到最靠前的文本块;
- 使用排序融合技术合并并去重上述两步的结果;
- 将 Top-K 个文本块加入提示中以生成响应。
通过同时运用 BM25 和嵌入模型,传统 RAG 系统能提供更全面且准确的结果,在精确术语匹配与广泛语义理解之间取得平衡。
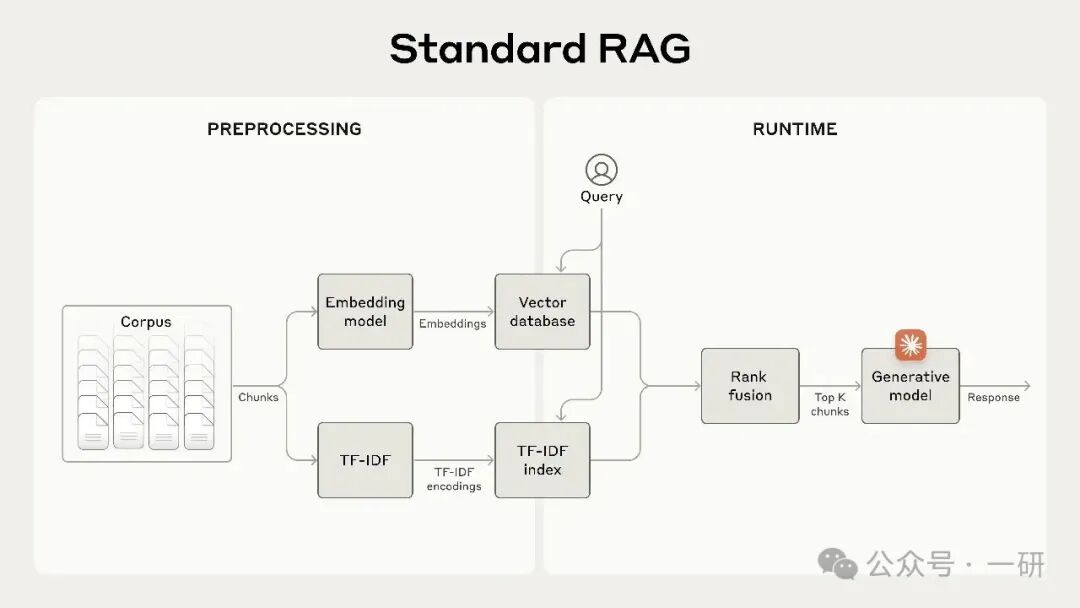
一种标准检索增强生成(RAG)系统,它同时使用词嵌入和最佳匹配25(BM25)算法来检索信息。TF-IDF(词频-逆文档频率)用于衡量词语的重要性,是BM25算法的基础。
这种方法让你能够以经济高效的方式扩展到超大型知识库,远远超出单个提示所能容纳的范围。
但传统 RAG 系统有一个显著的局限性:它们常常破坏上下文。
传统 RAG 中的上下文难题
在传统 RAG 中,为提高检索效率,文档通常被切分成较小的文本块。虽然这种方法适用于许多应用,但当单个文本块本身缺乏足够的上下文时,问题就出现了。
例如,假设你的知识库中嵌入了一系列财务信息(比如美国证券交易委员会 SEC 备案文件),随后收到查询:“What was the revenue growth for ACME Corp in Q2 2023?(ACME 公司 2023 年第二季度的收入增长是多少?)” 一个相关的文本块内容可能是:“The company's revenue grew by 3% over the previous quarter.(该公司营收较上一季度增长了3%。)” 然而,这个文本块本身并未指明其所属的公司或相关时间段,这使得检索正确信息或有效利用信息变得非常困难。
上下文检索方法介绍
上下文检索解决了上述问题。它在每个文本块编码之前,为其预先添加特定于该块的解释性上下文(即“上下文嵌入”),并在创建 BM25 索引时同步添加上下文(即“上下文 BM25”)。
让我们回到 SEC 备案文件集的例子。以下是一个文本块如何被转换的示例:
原始文本块 = "The company's revenue grew by 3% over the previous quarter."
添加上下文后的文本块 = "This chunk is from an SEC filing on ACME corp's performance in Q2 2023; the previous quarter's revenue was $314 million. The company's revenue grew by 3% over the previous quarter."
值得注意的是,过去也曾有其他利用上下文改进检索的方法被提出,例如:向文本块添加通用文档摘要④(我们试验后发现提升有限)、假设性文档嵌入⑤以及基于摘要的索引⑥(在我们的评估中性能表现较差)。这些方法与本文所提出的方案存在差异。
实现上下文检索
当然,指望人工为知识库中成千上万甚至数百万个文本块进行标注是完全不现实的。为了实现上下文检索,我们借助了 Claude。我们编写了一个提示,指示模型结合整个文档的上下文,为每个文本块生成简明且特定于该块的上下文说明。
我们使用以下 Claude 3 Haiku 提示来为每个文本块生成上下文:
{{WHOLE_DOCUMENT}}
Here is the chunk we want to situate within the whole document
{{CHUNK_CONTENT}}
Please give a short succinct context to situate this chunk within the overall document for the purposes of improving search retrieval of the chunk. Answer only with the succinct context and nothing else.
生成的上下文文本通常为 50–100 个 token,会被预先添加到文本块中,然后再进行嵌入和创建 BM25 索引。
以下是预处理流程的实践示意图:
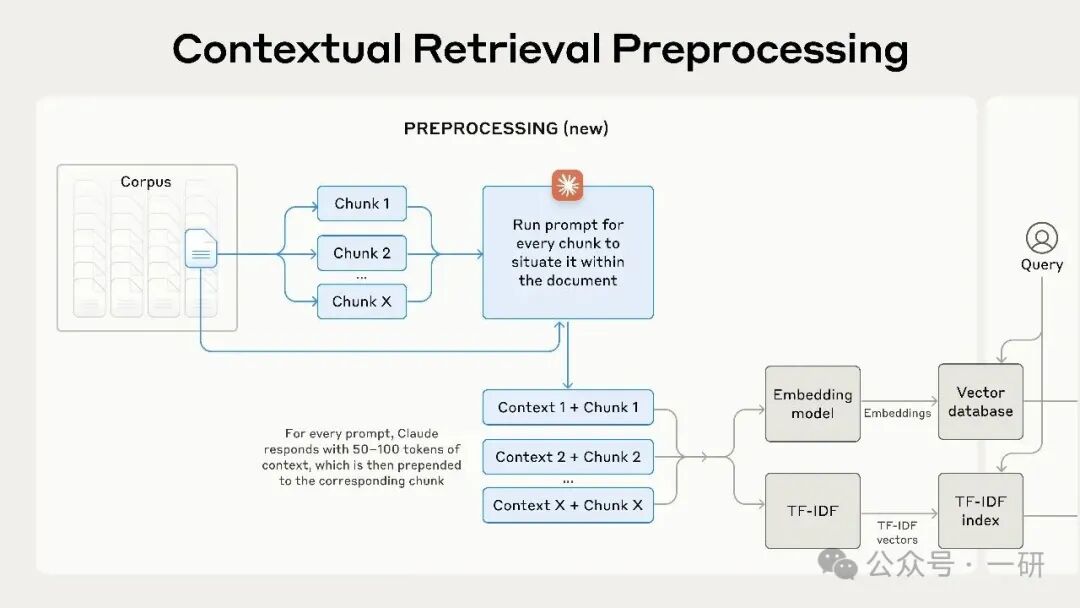
上下文检索是一种预处理技术,可以提高检索准确率。
如果你有兴趣尝试上下文检索,可以从我们的 cookbook ①开始。
利用提示缓存降低上下文检索成本
得益于我们上文提到的特殊提示缓存功能,使用 Claude 实现上下文检索的独特之处在于其低成本。借助提示缓存,你无需为每个文本块重复传入参考文档。只需将文档加载到缓存中一次,然后引用之前缓存的内容即可。
假设文本块为 800 token,文档为 8k token,上下文指令为 50 token,每个文本块生成的上下文为 100 token,则生成添加上下文的文本块的一次性成本为每百万文档 token 1.02 美元。
方法论
我们在多种知识领域(代码库、小说、ArXiv 论文、科学论文)、多种嵌入模型、检索策略和评估指标上进行了实验。我们在附录 II⑦ 中提供了每个领域所使用的问题与答案示例。
下图展示的是在使用性能最佳的嵌入模型配置(Gemini Text 004)且检索前 20 个文本块的条件下,所有知识领域的平均表现。我们使用 1 减去 recall@20 作为评估指标,该指标衡量的是在前 20 个文本块中未能检索到的相关文档百分比。完整结果可在附录中查看——添加上下文能够提升我们所评估的每一种嵌入来源组合的性能。
性能提升
我们的实验表明:
- 上下文嵌入将前 20 个文本块的检索失败率降低了 35%(从 5.7% 降至 3.7%)。
- 结合上下文嵌入和上下文 BM25,将前 20 个文本块的检索失败率降低了 49%(从 5.7% 降至 2.9%)。
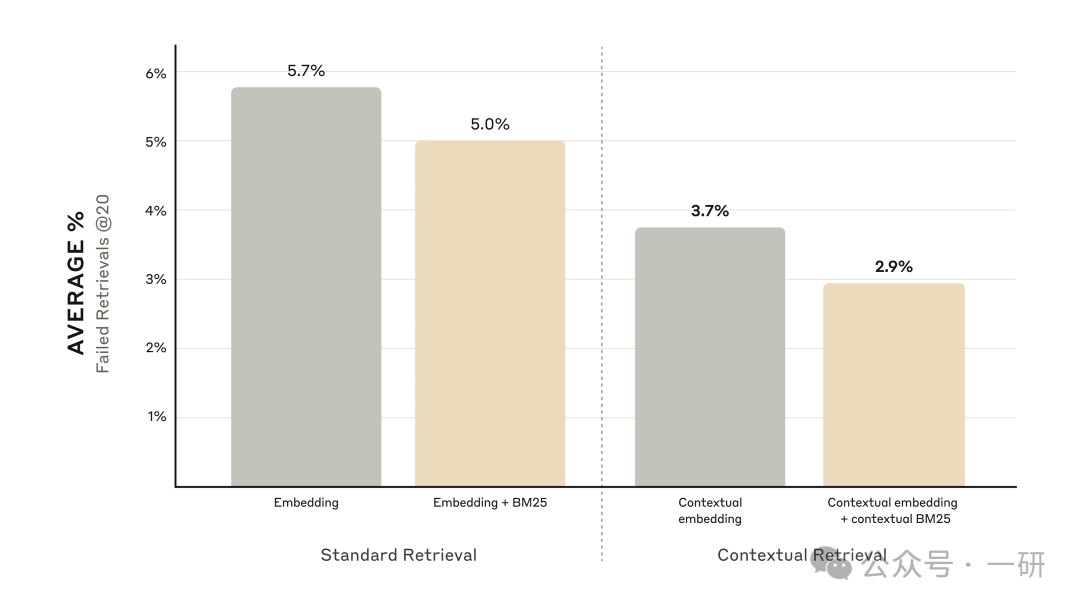
结合上下文嵌入和上下文 BM25,可将前 20 个数据块检索失败率降低 49%。
实现注意事项
在实现上下文检索时,需要注意以下几点:
- 文本块边界:仔细考虑如何将文档切分为文本块。文本块的大小、边界以及重叠部分的选择都会影响检索性能。
- 嵌入模型:虽然上下文检索能提升我们测试的所有嵌入模型的性能,但某些模型的提升效果可能更显著。我们发现 Gemini ⑧ 和 Voyage ⑨ 的嵌入效果尤其出色。
- 自定义上下文化提示:虽然我们提供的通用提示效果良好,但你或许可以通过为特定领域或用例定制提示来获得更佳效果(例如,加入一份仅在其他知识库文档中定义的关键术语词汇表)。
- 文本块数量:向上下文窗口添加更多文本块,可以提高包含相关信息的概率。然而,过多信息可能会分散模型注意力,因此存在上限。我们尝试了提供 5 个、10 个和 20 个文本块,发现使用 20 个是这些选项中性能最优的(对比见附录),但建议根据你的具体用例进行实验。
- 务必运行评估:在传递添加上下文的文本块时,明确区分哪些是上下文内容、哪些是原始文本块内容,可能有助于提高响应生成的质量。
文本块拆分策略,包括边界和大小,是需要独立进行详细分析的话题,本文不深入探讨。本实验中的所有测试均采用相同的文本块拆分策略。
通过重排序进一步提升性能
在最后一步,我们可以将上下文检索与另一项技术结合,以获得更大的性能提升。
在传统 RAG 中,AI 系统会搜索知识库以找到潜在相关的信息块。对于大型知识库,这一初始检索通常返回大量文本块——有时多达数百个——其相关性和重要性各不相同。
重排序是一种常用的过滤技术,能确保只将最相关的文本块传递给模型。重排序能提供更优质的响应,并因模型需要处理的信息量减少而降低成本和延迟。关键步骤如下:
- 执行初始检索,获取最相关的前 N 个文本块(我们使用了前 150 个);
- 将前 N 个文本块连同用户查询一起传递给重排序模型;
- 利用重排序模型,根据每个文本块与提示的相关性和重要性进行评分,然后选出前 K 个文本块(我们使用了前 20 个);
- 将前 K 个文本块作为上下文传递给模型,以生成最终结果。
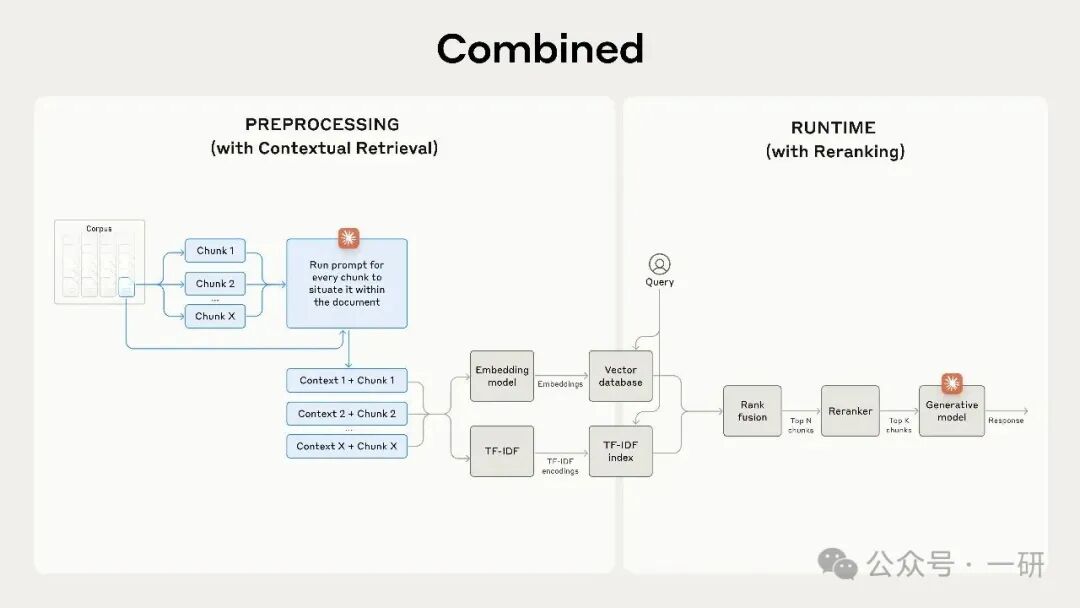
结合上下文检索和重排序,最大限度地提高检索准确率。
性能提升
市场上有多种重排序模型可供选择。我们使用 Cohere 重排序器进行了测试。Voyage 也提供重排序器⑩,但我们尚未对其进行测试。
我们的实验表明,在多个领域中,加入重排序步骤能进一步优化检索。具体而言,我们发现经过重排序的上下文嵌入和上下文 BM25,将前 20 个文本块的检索失败率降低了 67%(从 5.7% 降至 1.9%)。
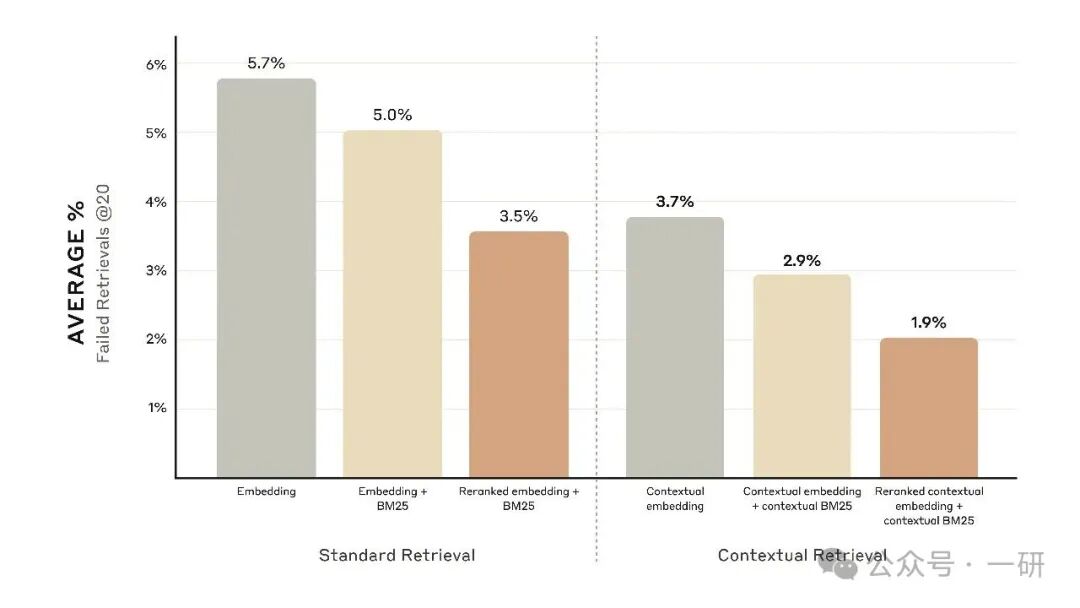
重新排序的上下文嵌入和上下文 BM25 将前 20 个数据块检索失败率降低了 67%。
成本与延迟方面的考量
使用重排序时,一个重要的考虑因素是对延迟和成本的影响,尤其是在对大量文本块进行重排序时。由于重排序在运行时增加了一个额外步骤,即便重排序器是并行处理所有文本块,也难免会引入少量延迟。在重排序更多文本块以获得更好性能,与重排序更少文本块以降低延迟和成本之间,存在固有的权衡。我们建议根据你的具体用例,尝试不同的配置以找到最佳平衡点。
结论
我们进行了大量测试,比较了上述所有技术的不同组合(嵌入模型、BM25 的使用、上下文检索的使用、重排序器的使用,以及检索的 Top-K 结果总数),涵盖了多种不同类型的数据集。以下是我们的主要发现:
- 嵌入 + BM25 优于单独使用嵌入;
- Voyage 和 Gemini 是我们测试中嵌入效果最佳的模型;
- 向模型传递前 20 个文本块比仅传递前 10 个或前 5 个更有效;
- 为文本块添加上下文能显著提升检索准确率;
- 重排序优于不进行重排序;
- 所有这些优势叠加后效果更佳:为最大化性能提升,我们可以将上下文嵌入(来自 Voyage 或 Gemini)与上下文 BM25 相结合,再加上重排序步骤,并将 20 个文本块添加到提示中。
我们鼓励所有在知识库方面开展工作的开发者,使用我们的 cookbook ①尝试这些方法,解锁性能的新高度。你可以在云栈社区与更多开发者交流关于大模型应用与 RAG 优化的实践经验。
附录 I
以下是针对不同数据集、不同嵌入提供商、嵌入之外是否使用 BM25、是否使用上下文检索、以及是否使用重排序,在检索@20 条件下的结果细分。
关于检索@10 和@5 条件下的结果细分,以及每个数据集的示例问题与答案,请参见附录 II⑦。
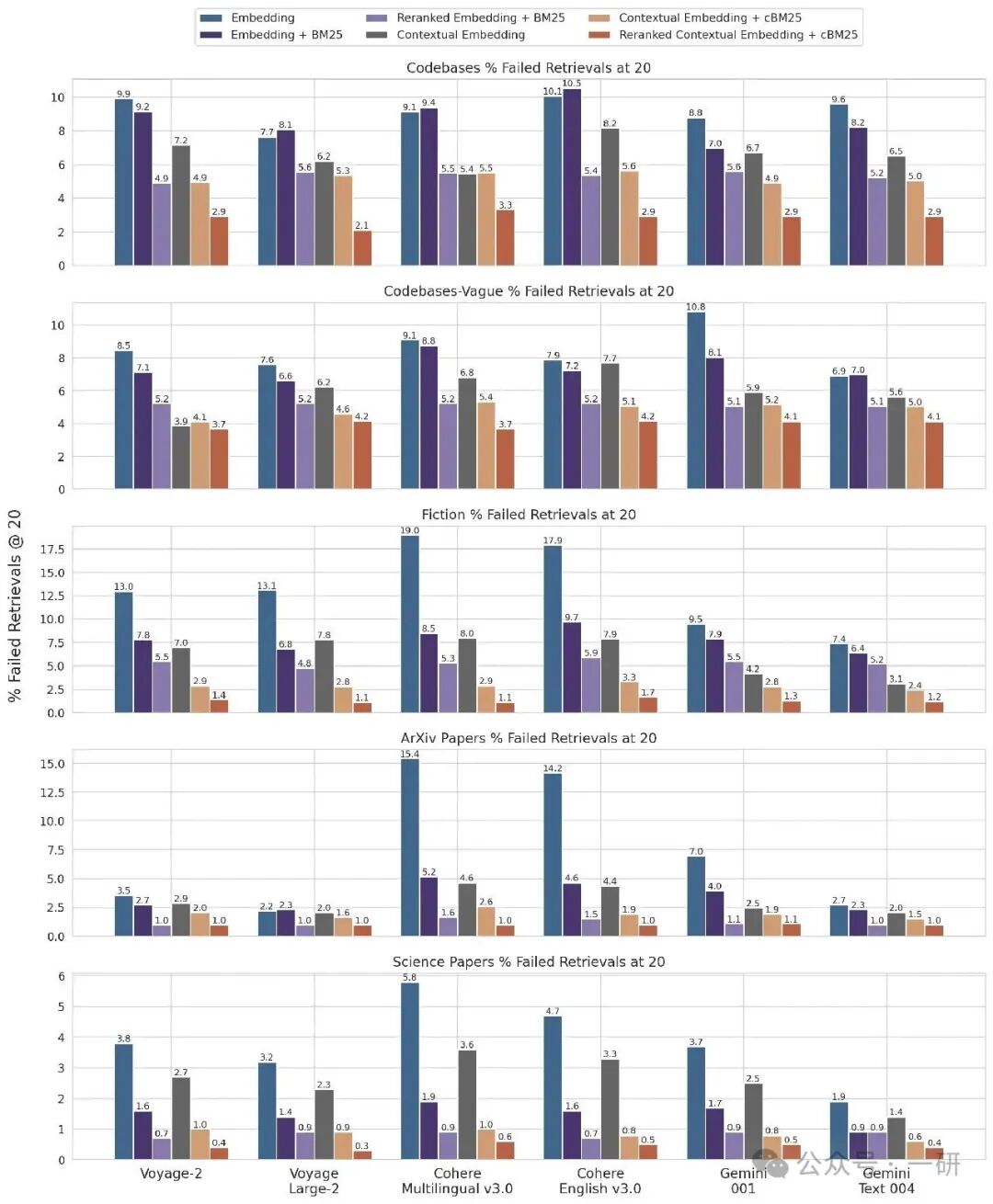
1 减去跨数据集和嵌入提供商的 20 个结果的召回率。
致谢
本文由 Daniel Ford 完成研究与撰文。感谢 Orowa Sikder、Gautam Mittal 与 Kenneth Lien 提供重要反馈,感谢 Samuel Flamini 实现实用手册,感谢 Lauren Polansky 协调项目,同时感谢 Alex Albert、Susan Payne、Stuart Ritchie 与 Brad Abrams 为本文构思提供建议。
扩展阅读:
①、上下文嵌入指南/实用手册,
https://platform.claude.com/cookbook/capabilities-contextual-embeddings-guide
②、提示缓存功能,
https://docs.anthropic.com/en/docs/build-with-claude/prompt-caching
③、提示缓存使用手册,
https://platform.claude.com/cookbook/misc-prompt-caching
④、在文档中添加摘要文档,
https://aclanthology.org/W02-0405.pdf
⑤、假设文档嵌入,
https://arxiv.org/abs/2212.10496
⑥、基于摘要的索引,
https://www.llamaindex.ai/blog/a-new-document-summary-index-for-llm-powered-qa-systems-9a32ece2f9ec
⑦、附录Ⅱ,
https://assets.anthropic.com/m/1632cded0a125333/original/Contextual-Retrieval-Appendix-2.pdf
⑧、Gemini嵌入,
https://ai.google.dev/gemini-api/docs/embeddings
⑨、Voyage嵌入
https://www.voyageai.com/
⑩、Cohere重排序器
https://cohere.com/rerank
Voyage重排序器
https://docs.voyageai.com/docs/reranker
 发表于 2026-4-29 02:09:48
|
查看: 238|
回复: 0
发表于 2026-4-29 02:09:48
|
查看: 238|
回复: 0
