
笔记整理:王浩,浙江大学硕士,研究方向为大模型智能体、AI for Science
论文链接:https://openreview.net/forum?id=po0eyoYFUa
发表会议:NeurIPS 2025
1. 动机
随着大语言模型(LLMs)在各类问答、推理与生成任务中大放异彩,检索增强生成(RAG)技术已成为减少模型“幻觉”、为其注入外部知识的利器。然而,传统的 RAG 系统多依赖向量数据库进行语义检索,而在许多真实应用场景中,我们需要同时处理更复杂的知识:
- 结构化关系(例如,作者、论文、机构之间的关联)
- 丰富的节点文本内容(例如,论文摘要或商品描述)
- 进行多步推理的能力
因此,融合了结构与语义信息的知识图谱成为了一个潜力巨大的外部知识源。不过,当前基于知识图谱的 RAG 方法存在几个明显的短板:
(1). 对复杂查询的检索准确度不足
对于简单的关联查询,例如“Alice 的父亲是谁?”,仅凭知识图谱的结构信息或许就能找到答案。但面对“列举某大学发表的与特定主题相关的所有论文”这类复杂查询时,模型需要同时理解作者关系、机构从属、论文内容及其与主题的相关性,现有方法往往难以高效地融合文本与结构信息。
(2). 检索结果缺乏多样性
许多复杂查询的答案并非唯一。现有模型很容易陷入“思维定式”,只找到一种或少数几种答案,而忽略了其他同样有效的可能性。
(3). 过程奖励模型(PRM)成本高昂
使用过程奖励模型可以提供逐步的推理指导,效果显著,但它依赖昂贵的过程级监督数据进行训练,而这种数据在知识图谱场景下几乎无法获得。
为了解决这些问题,并同时实现高准确性、高多样性、强泛化能力和高效率,作者提出了名为 GraphFlow 的新框架。
2. 贡献
(1) 提出了 GraphFlow 框架。该框架通过联合优化检索策略和流估计器,在无需显式过程级奖励监督的情况下,实现了对复杂查询的精准且多样的检索。
(2) 引入了局部探索策略与详细平衡目标。这有效减少了对低奖励区域的无效访问,不仅提升了训练效率,还能主动引导检索策略探索高价值区域。
(3) 在 STaRK 基准测试上的实验表明,GraphFlow 在检索准确率和多样性指标上全面超越了包括 GPT-4o 在内的强大基线模型,并且在未见过的知识图谱上展现了优异的跨领域泛化能力。
3. 方法
GraphFlow 的整体框架如图1所示。其核心思想是通过一个流估计器将整个推理轨迹的最终结果奖励分解到每一个中间步骤,从而为检索策略提供隐式的过程级监督信号,引导其学习。
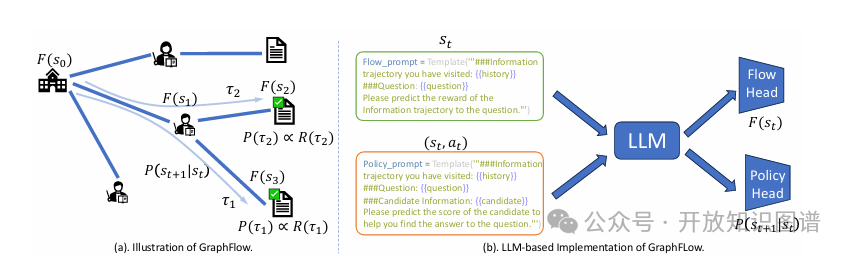
图1:GraphFlow 总体框架。(a) GraphFlow 示意图,展示了状态转移与奖励分解;(b) 基于LLM的实现结构,通过提示工程适配富含文本的知识图谱检索场景。
3.1 问题建模
知识图谱被形式化地定义为 G = (V, E, D),其中 V 是实体节点集合,E 是关系边集合,D 是与节点关联的文本文档集合。检索的目标是从 G 中高效地找出 K 个目标节点及其相关文档,以支撑对复杂查询的回答。
3.2 多步决策过程设计
- 状态:初始状态
s_0 = (q, d_0),q 是用户查询,d_0 是初始节点的关联文档。第 t 步的状态 s_t = (q, D_t) 包含了截至目前累积收集到的文档集合 D_t。
- 动作:从当前节点
v_t 移动到其相邻节点 v_{t+1},并获取该节点对应的文档 d_{t+1}。
- 转移:执行动作后,状态更新为
s_{t+1} = (q, D_t ∪ {d_{t+1}})。此过程持续进行,直到收集的文档足以回答查询或达到预设的最大步数。
- 奖励:在推理轨迹
τ 终止时,根据最终收集到的文档是否有效支持查询,为其分配一个结果奖励 R(τ)。
3.3 核心组件
- 流估计器 (Flow Estimator):为每一个中间状态
s 分配一个非负的流值 F(s)。它的作用是将最终的轨迹奖励 R(τ) “逆向”分解到路径上的各个中间步骤,从而为策略学习提供宝贵的隐式监督。
- 检索策略 (Retrieval Policy):通过与流估计器联合训练,学习生成高奖励轨迹。其训练遵循“详细平衡”原则,目标是使生成轨迹的概率与轨迹的最终奖励成正比,即满足公式:
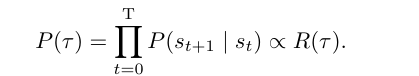
其中,τ 为检索轨迹,P(s_{t+1} | s_t) 是策略决定的状态转移概率。
- 局部探索 (Local Exploration):在训练时,对每个非终止状态,策略会生成
k 个候选探索动作。这种聚焦于当前状态邻域的探索方式,避免了对整个图谱的盲目搜索,极大地提升了训练效率,并使优化集中在高价值区域。
3.4 损失函数与训练配置
模型采用结合了详细平衡与局部探索的目标函数(DBLE Loss)进行训练:

边界条件设定为 F(s_T) = R(τ)。在实现上,作者使用 LoRA 适配器对大语言模型主干进行轻量化优化,并联合训练“流估计头”和“策略头”。
4. 实验
4.1 数据集
实验采用 STaRK 基准测试,它涵盖了三个不同领域、富含文本内容的知识图谱:
- STaRK-AMAZON:电商领域,包含产品信息及“一同购买”关系,用于测试商品推荐类查询的检索。
- STaRK-MAG:学术领域,包含作者、机构、出版物等信息,用于测试学术论文检索等查询。
- STaRK-PRIME:生物医学领域,包含药物、疾病、基因等实体及复杂关系,用于测试生物医学领域的复杂查询。
4.2 实验任务与基线
- 任务:评估模型在复杂查询下的检索准确率(Hit@1, Hit@5, MRR)和检索多样性(R@20, D-R@20)。
- 基线模型:
- 检索式方法:DenseRetriever, G-Retriever, SubgraphRAG。
- 智能体方法:ToG+LLaMA3, ToG+GPT4o, SFT, PRM。
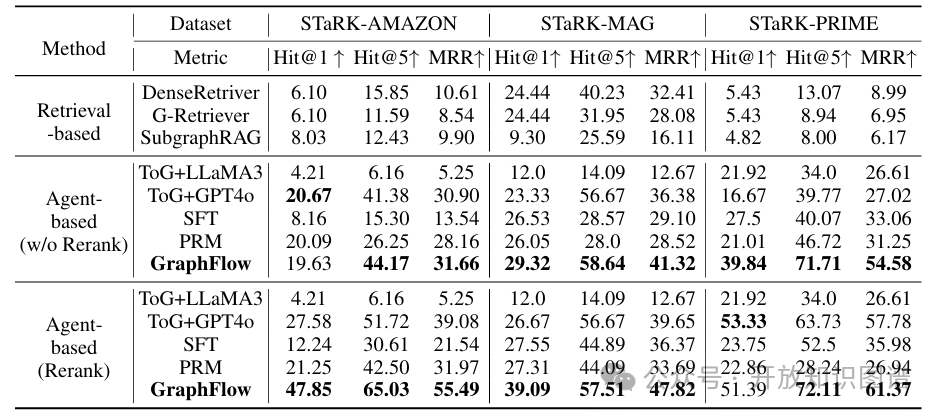
表1:各方法在三个数据集上的检索准确性表现(Hit@1, Hit@5, MRR)
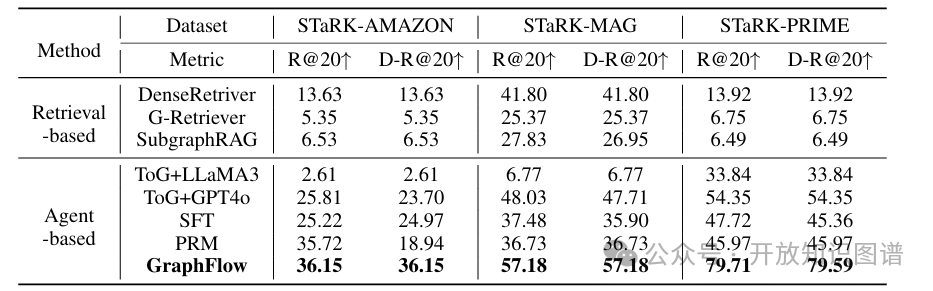
表2:各方法在三个数据集上的检索多样性表现(R@20, D-R@20)
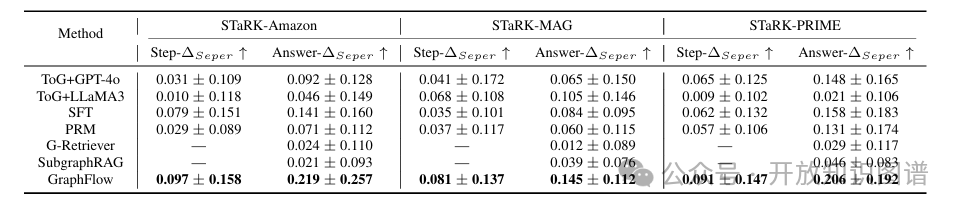
表3:各方法的定量检索质量分析(Step-ΔSeper, Answer-ΔSeper)
4.3 实验结果
-
准确率:GraphFlow 在所有三个数据集上均显著优于所有基线模型。与强大的 ToG+GPT4o 基线相比,平均性能提升约 10%。尤其在 STaRK-PRIME 数据集上,其 Hit@1 达到 39.84%,MRR 达到 54.58%,优势明显。
-
多样性:在衡量多样性的 R@20 和 D-R@20 指标上,GraphFlow 同样取得了最优结果。在 STaRK-PRIME 数据集上,其 D-R@20 高达 79.59%,表明它能够避免检索冗余信息,更广泛地覆盖不同的正确答案。
-
泛化能力:在跨领域检索任务中,GraphFlow 表现出了卓越的泛化性能。特别是在引入重排序机制后,其在 Hit@5 等指标上的领先优势进一步扩大。
5. 总结
本文提出的 GraphFlow 框架,创新性地通过流估计器分解奖励信号,并结合局部探索策略,有效解决了当前知识图谱驱动RAG在应对复杂查询时面临的精准性与多样性难题。实验充分证明,该框架无需依赖难以获取的过程级监督数据,即可在权威的 STaRK 基准上超越包括 GPT-4o 在内的强劲对手,并具备出色的跨领域泛化能力。未来,将此类方法与因果推理等更高级的推理技术结合,有望进一步提升大语言模型在科学发现等复杂领域的应用潜力。
对于这类前沿的 AI 研究与技术实践,持续的关注和深入的社区交流至关重要。如果你想了解更多关于大模型、知识图谱与 RAG 的实战经验与最新动态,欢迎关注云栈社区的相关技术板块,与众多开发者一同探索。
 发表于 2026-3-17 04:09:32
|
查看: 247|
回复: 0
发表于 2026-3-17 04:09:32
|
查看: 247|
回复: 0
