
1. 动机
图表示学习近年来在电商推荐、知识图谱、分子发现等领域取得了显著进展。随着大型语言模型(LLM)的兴起,图基础模型通过大规模预训练,将跨域泛化与多任务统一推理能力引入图领域。
然而,Graph Foundation Models (GFMs) 在实际部署中面临两大核心瓶颈:
- 知识更新成本高昂。图数据具有动态演化特性:新增用户-商品交互、社交网络关系或分子结构时有发生。传统方案需对 GFMs 进行全量或参数高效微调(如 GraphLoRA、G-Adapter),仍需反向传播与梯度存储,耗时数小时至数天,且易引发灾难性遗忘。
- 推理忠实度不足。GFMs 在复杂拓扑上与 LLM 耦合时,常出现“幻觉”:生成虚假节点特征、臆造不存在的边,导致与真实图结构背离,降低业务可信度。
自然语言处理领域的 检索增强生成 (RAG) 通过“推理时检索”而非“训练时微调”实现知识即时更新,并显著抑制幻觉。但图数据具有拓扑异构、模态混合(文本+结构)等特点,直接将文本 RAG 迁移到图域将面临以下挑战:
- 如何构建兼顾语义与结构保真度的图索引?
- 如何针对节点级、边级、图级等不同任务设计异构检索策略?
- 如何在特征与拓扑双重空间合理融合检索证据?
RAG4GFM 由此提出,旨在为 GFMs 提供即插即用、无需梯度计算的知识更新与推理增强能力。
2. 贡献
- 首次系统性地将 RAG 范式扩展到图基础模型,提出端到端框架 RAG4GFM,实现“零梯度更新、毫秒级检索、分钟级部署”。
- 多级混合图索引:统一编码节点文本语义、Laplacian 位置信号、边角色特征与图全局统计,构建基于 HNSW 的四级层次索引,理论检索复杂度 O(logN)。
- 任务感知检索器:利用轻量级 LLM 对“自然语言查询+图上下文”进行任务类型判别(节点/边/图),自适应选择特征子空间与检索算子,并采用倒数排序融合(RRF)多路结果,显著降低噪声。
- 双路图融合增强:
- 特征层——基于语义相似度动态计算注意力权重,过滤低相关检索子图;
- 拓扑层——通过稀疏矩阵运算将高价值邻接信息加权合并至查询图,兼顾可扩展性与结构一致性。
- 大规模实验验证:在 9 个跨领域数据集、6 类任务(节点分类/回归、边分类/预测、图分类/回归)上与 7 个代表性 GFMs 组合测试,平均提升 4–7%,推理耗时降至参数高效微调方案的 1/7,GPU 显存节省 60% 以上。
3. 方法
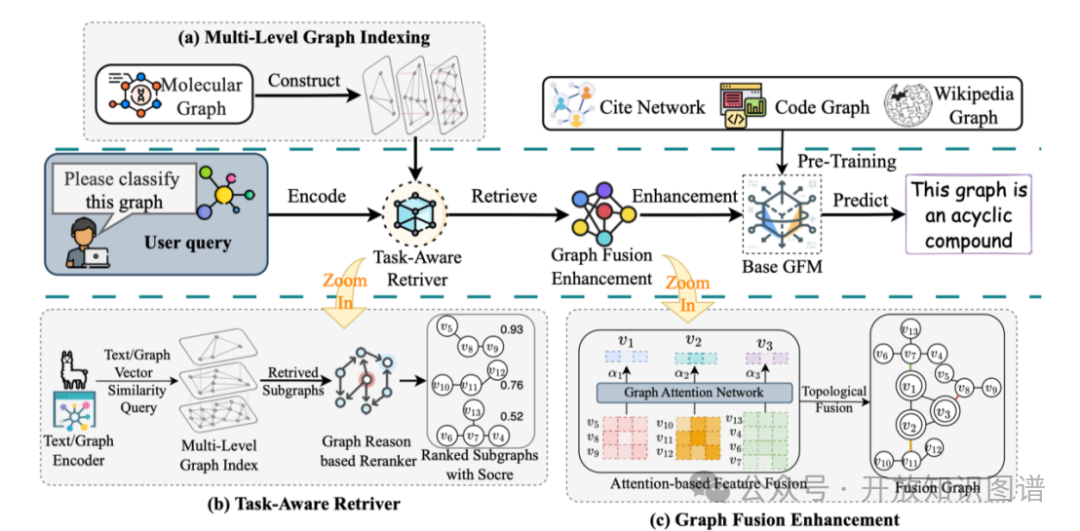
3.1 多级图索引 (Multi-Level Graph Indexing)
给定外部图语料库 G,RAG4GFM 首先进行混合特征编码:
- 节点文本特征 h_t(v) = LM(v),采用冻结的预训练语言模型(如 DeBERTa-v3-base)。
- 结构特征 h_s(v) = LapPE(v) ⊕ Deg_IN(v) ⊕ Deg_OUT(v),其中 LapPE 为基于图拉普拉斯特征分解的位置编码,拼接出入度以捕捉局部连接模式。
- 边特征 h_e(u,v) 通过将原图转换为线图后再次计算 LapPE,刻画边在全局拓扑中的角色。
- 图级特征 h_g(G) 聚合节点、边特征均值与图统计量 [|V|, |E|, ρ(G)],形成全局摘要。
将上述四级向量构建为 HNSW 层次索引,保证对节点级、边级、图级检索均可在 O(logN) 时间内完成。
3.2 任务感知检索 (Task-Aware Retrieval)
对用户输入的自然语言查询 q 与伴随图上下文 G_q,采用小型 LLM(如 3B 参数的 Flan-T5)进行联合编码,输出任务类型 τ(q) ∈ {NODE, EDGE, GRAPH}。依据任务类型,检索器仅在对应特征子空间执行最近邻搜索:
- 节点任务:检索 {h_t(v), h_s(v)};
- 边任务:检索 {h_t(u), h_t(v), h_e(u,v)};
- 图任务:检索 {h_t(v), h_g(G)}。
通过 RRF 融合多通道排名,最终返回 Top-k 子图及其特征、邻接矩阵。
3.3 图融合增强 (Graph Fusion Enhancement)
- 特征融合:对每条检索子图 G_i 计算全局-查询相似度 α_i^F = softmax(cos(h_q, h_i^g)),仅当 α_i^F > γ(默认 0.5)时将其节点特征加权聚合至查询图,实现噪声过滤。
- 拓扑融合:将检索子图邻接矩阵 A_i 按 α_i^T 加权,稀疏加到原图 A 上,并通过阈值 δ(默认 0.5)二值化,得到增强邻接 A′。
最终,GFM 在增强后的图上执行下游推理,全程无需更新参数。
4. 实验
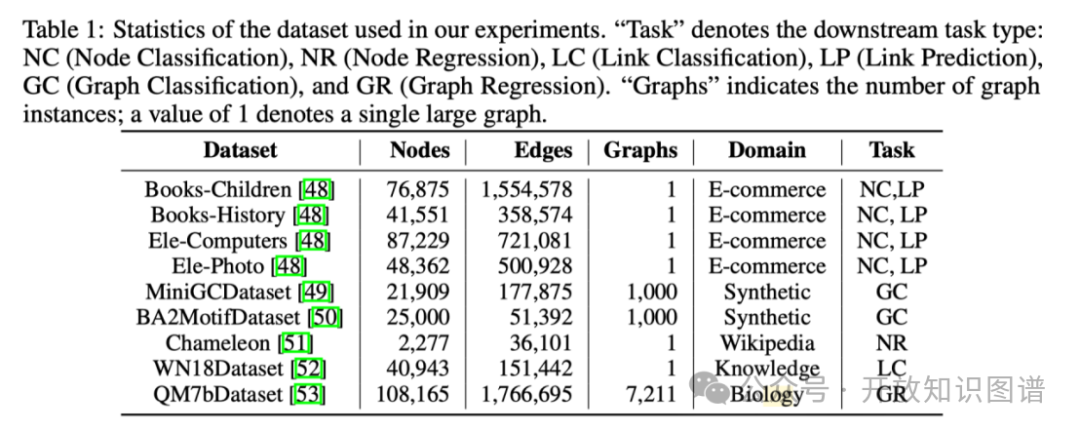
4.1 数据集与基准
涵盖电商共购网络(Books-Children、Books-History、Ele-Computers、Ele-Photo)、知识图谱(WN18)、分子属性预测(QM7b)、维基链接网络(Chameleon)及合成图(MiniGC、BA2Motif),共 9 个数据集,涉及 6 类任务。所有测试均在零样本(zero-shot)条件下进行,以避免预训练数据泄露。
4.2 主实验
与三大类基线对比:
- Prompt Engineering:Few-shot Learning、Chain-of-Thought、IR-augmented CoT
- Retrieval-Augmented:VanillaRAG、GraphRAG、G-Retriever
- 图分布外泛化:Prototype、GNNSafe
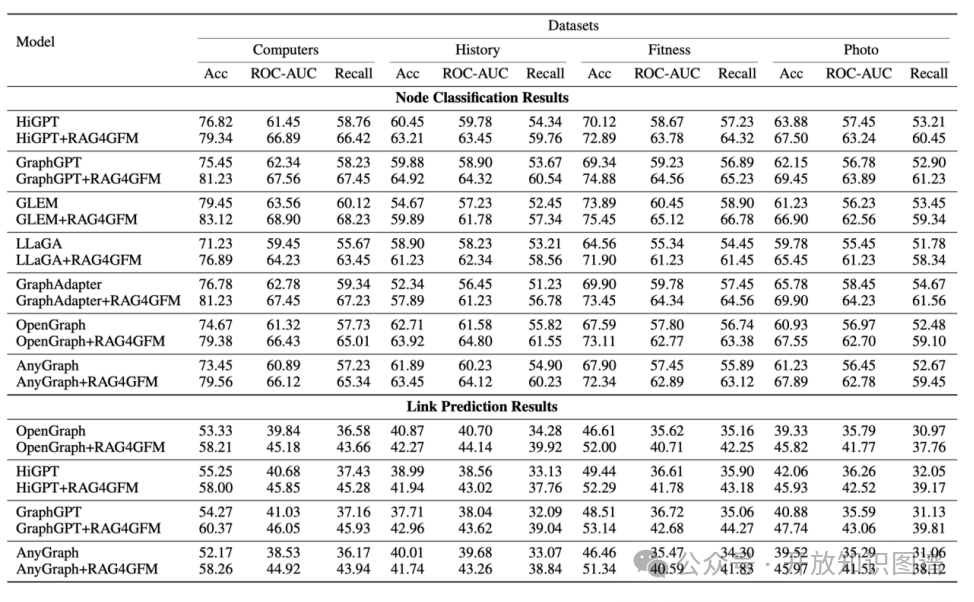
结果(表2)显示,RAG4GFM 在节点分类、链路预测、图分类等任务上均取得一致提升。例如:
- Computers 节点分类:AnyGraph 基线 74.67% → RAG4GFM 79.38%,提升 4.7%;
- History 链路预测:GraphGPT 基线 54.27% → 60.37%,提升 6.1%;
- MiniGC 图分类:GraphGPT 60.98% → 67.61%,提升 6.6%。
4.3 消融实验
- 去除检索(w/o RAG):平均下降 6–9%,验证外部知识必要性;
- 去除图融合(w/o GF):改用朴素特征拼接,下降 2–4%,说明结构-语义对齐有效;
- 去除层次索引(w/o GI):退化为纯文本向量检索,下降 3–5%,凸显结构保真重要性;
- 特征编码消融:仅用 LapPE 或仅用节点度均显著低于联合编码,表明全局-局部结构信息互补。
4.4 效率对比
与代表方法 GraphLoRA 在同等准确率(78%)约束下比较:
- GraphLoRA:7.32 h,峰值显存 25.2 GB;
- RAG4GFM:63 min,峰值显存 9.9 GB。
运行时间压缩 7×,显存节省 60%,且无需反向传播,适合高频更新场景。
4.5 鲁棒性分析
- 检索子图数量 K:1→3 性能稳步提升,K>3 趋于饱和,默认 K=3;
- 融合阈值 γ, δ:在 0.3–0.9 区间扫描,0.5 附近取得最佳,表明对超参数不敏感,易于部署。
5. 总结
RAG4GFM 通过“多级索引 + 任务感知检索 + 双路图融合”的闭环框架,首次将 RAG 的即插即用优势引入图基础模型,显著降低知识更新成本并提升推理忠实度。实验表明,该框架在跨领域、跨任务场景下均能带来稳定且显著的性能增益,同时保持计算与内存的高效性。这项研究为图基础模型的实际应用,尤其是在需要处理动态知识图谱和复杂图数据的场景下,提供了新的思路和高效的解决方案。如果你对类似的前沿图神经网络技术讨论感兴趣,欢迎访问 云栈社区,与更多开发者一起交流学习。 |  发表于 2026-3-17 04:14:39
|
查看: 193|
回复: 0
发表于 2026-3-17 04:14:39
|
查看: 193|
回复: 0
