作为一名技术从业者,你是否曾对RAG(检索增强生成)系统感到既好奇又困惑?它被广泛认为是连接大语言模型与私有知识的关键桥梁,但在实际落地时,从分块策略到效果调优,每一步都可能成为“拦路虎”。本文将系统性地梳理RAG领域最常遇到的25个关键问题,并附上实践建议与流程图解,助你从概念理解走向实战部署。
1、提示工程、RAG与微调:如何选择?
在构建基于大语言模型(LLM)的应用时,我们通常面临三种增强模型能力的路径:提示工程、RAG和微调。它们并非互斥,而是针对不同“短板”的解决方案。
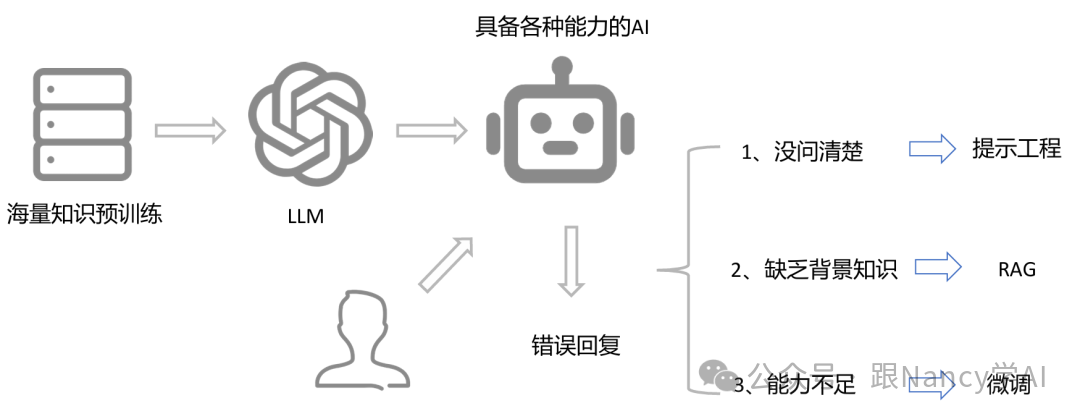
如图所示,当AI给出的回复不准确时,我们可以根据问题根源来选择技术方案:
- 提示工程:优化提问方式,引导模型更好地理解意图。
- RAG:当模型缺乏特定的背景知识时,通过检索外部知识库来补充信息。
- 微调:从根本上提升模型在特定任务或领域上的能力。
2、什么场景下应该选择RAG而不是微调?
RAG的核心优势在于其知识的“外部化”与“可更新性”。在以下场景中,RAG通常是比Fine-tuning(微调)更优的选择:
- 知识需要频繁更新:例如产品文档、FAQ,使用RAG只需更新向量数据库,而无需重新训练模型。
- 需要引用来源:在客服、法律咨询等场景,系统需要明确告知用户答案来源于哪个文档,RAG天生支持这一点。
- 数据量有限:微调通常需要大量高质量标注数据,而RAG对数据量的要求更低,启动门槛小。
- 需要实时信息:对于新闻、股票价格等实时性极强的信息,无法通过训练固化到模型权重中,RAG可以动态检索最新资料。
- 预算有限:RAG的实现与维护成本通常远低于大规模的模型微调。
当然,这三种模式可以组合使用。例如“RAG + 微调”,先微调模型让其更擅长理解和利用检索到的上下文;或者“RAG + 提示工程”,优化检索后构建提示词的模板。
3、文档分块策略有哪些?
文档分块(Chunking)是RAG系统的基石,其质量直接决定后续检索的效果。不合理的分块会导致信息割裂或噪声过多。常见的分块策略对比如下:
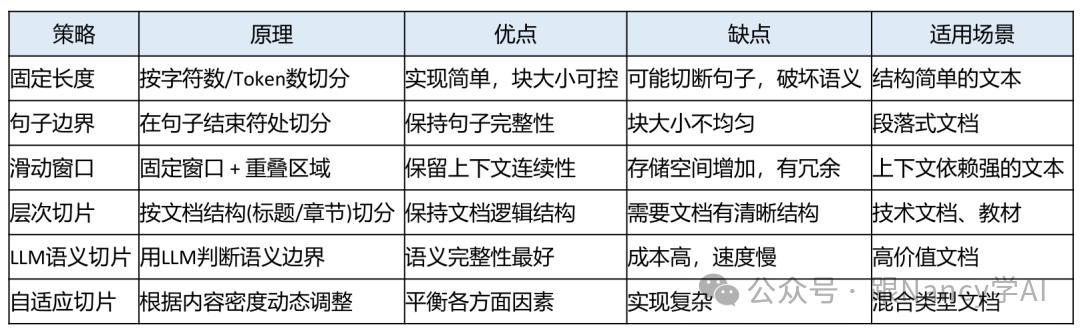
4、项目中用什么分块策略?为什么选它?
策略选择没有银弹,需结合具体数据形态。假设你的知识库是产品FAQ文档,推荐使用滑动窗口 + 句子边界的混合策略:
- 首先按句子边界切分:保证每个块的语义完整性。
- 然后应用滑动窗口:设置窗口大小(如512个token)和步长(如100个token),产生20%左右的重叠区域。
- 重叠的意义:确保答案信息不会因为恰好落在两个块的边界而丢失。
选择原因:
- FAQ的特性:问题与答案通常以段落形式存在,段落间可能存在上下文依赖。
- 用户提问的复杂性:用户可能提出涉及多个连续段落信息的复合问题。
- 平衡的艺术:20%的重叠在可接受的存储开销与检索质量间取得了良好平衡。
分块大小经验值:
- 一般推荐 256-1024个tokens。
- 小块(如256):检索精度高,但可能丢失必要的上下文。
- 大块(如1024):上下文完整,但会引入无关噪声,降低检索精度。
- 常见配置:
chunk_size=512, overlap=50-100。
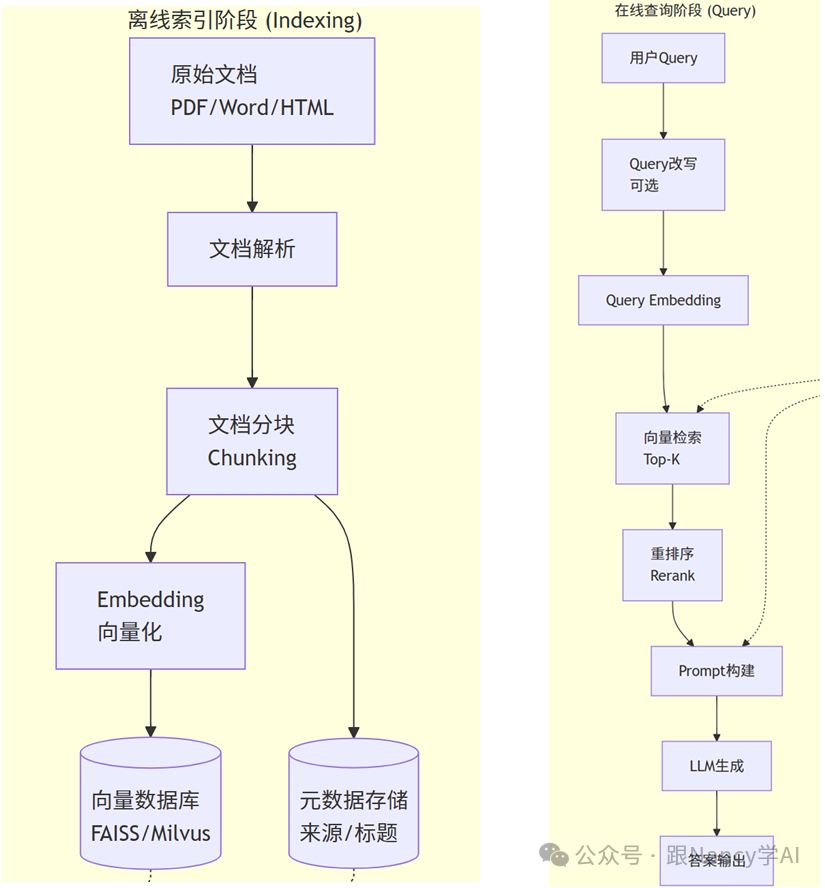
5、RAG系统的核心流程是什么?
一个典型的RAG系统可以抽象为三个核心阶段,这三个阶段看似简单,实则包含了众多工程细节:
- 索引(Indexing):如何高效、结构化地存储知识。这包括文档解析、分块、向量化并存入数据库。
- 检索(Retrieval):如何在庞大的知识库中,快速、准确地找到与用户问题最相关的一小部分内容。
- 生成(Generation):如何巧妙地将用户的原始问题和检索到的参考知识结合起来,让大语言模型生成准确、有用的答案。
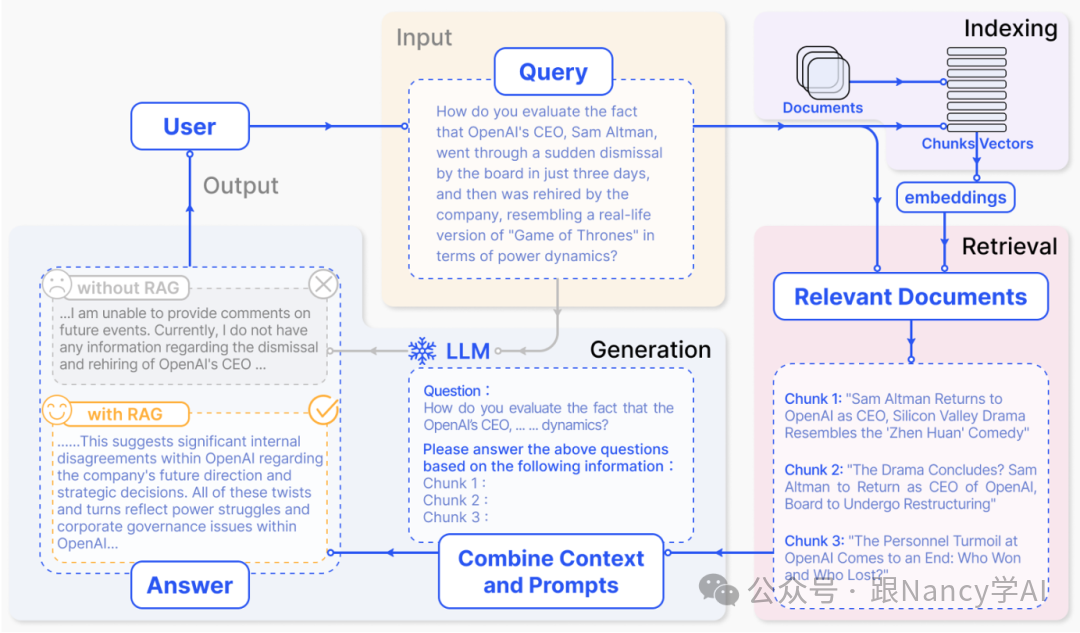
6、RAG系统详细的步骤都有哪些?
让我们将上述三大阶段拆解为可落地的具体步骤:
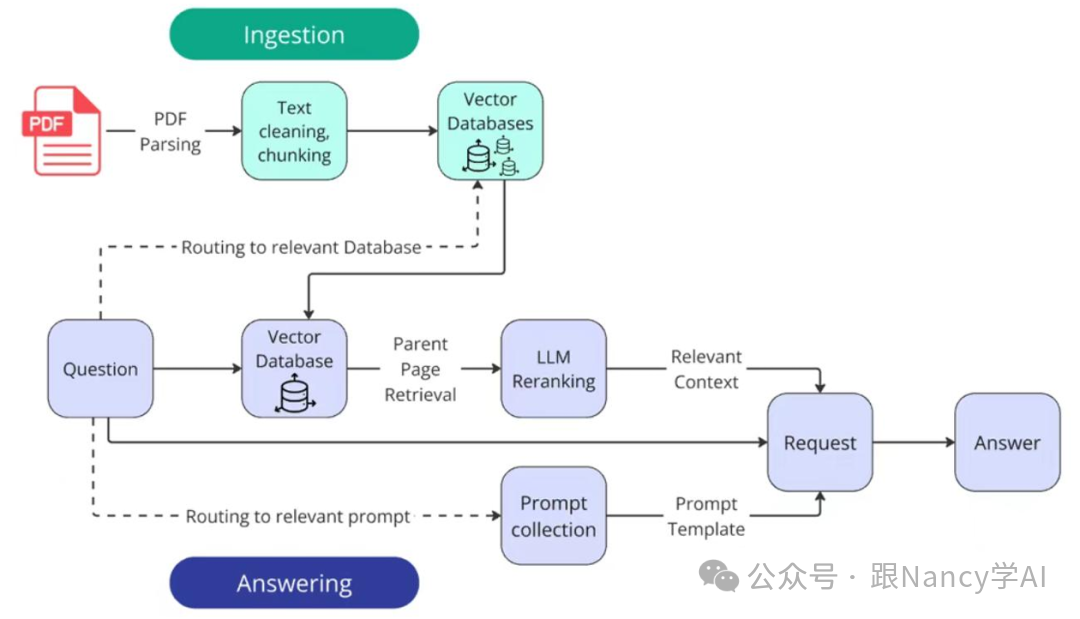
关键步骤详解:
-
Step 1: 文档解析
将PDF、Word、HTML等原始格式转换为纯文本。常用工具有PyPDF2、python-docx、BeautifulSoup。需特别注意处理表格、图片、复杂排版等非结构化内容。
-
Step 2: 文档分块
如第3、4点所述,根据文档类型选择合适的策略进行切分。
-
Step 3: 向量化
使用Embedding模型将文本块转换为高维向量。这是实现语义检索的关键。
-
Step 4: 向量存储
将向量及其元数据(来源、标题等)存入向量数据库。可选方案包括FAISS(本地轻量)、Milvus(分布式)、Pinecone(云服务)等。
-
Step 5: Query改写(可选但重要)
对于模糊、简短或依赖上文的问题,使用一个小型LLM对用户Query进行改写或扩展,以提升召回率。例如将“怎么退款?”扩展为“该产品的线上退款政策是什么?”。
-
Step 6: 向量检索
计算查询向量与库中所有向量的相似度(常用余弦相似度),返回最相似的Top-K个文档块。
-
Step 7: 重排序
使用更精细的Cross-Encoder模型对初步召回的Top-K个结果进行精排,筛选出最相关的Top-N个(如Top-3),这一步能显著提升最终答案质量。
-
Step 8: Prompt构建
将精排后的文档块作为上下文,与用户问题、系统指令一起构建成完整的Prompt,输入给LLM。需注意总长度不要超过模型的上下文限制。
-
Step 9: LLM生成
LLM基于提供的上下文生成最终答案。可以在Prompt中要求模型引用来源,增强可信度。
7、Embedding模型有哪些选择?
选择合适的Embedding模型至关重要。以下是一些主流模型的特点对比:
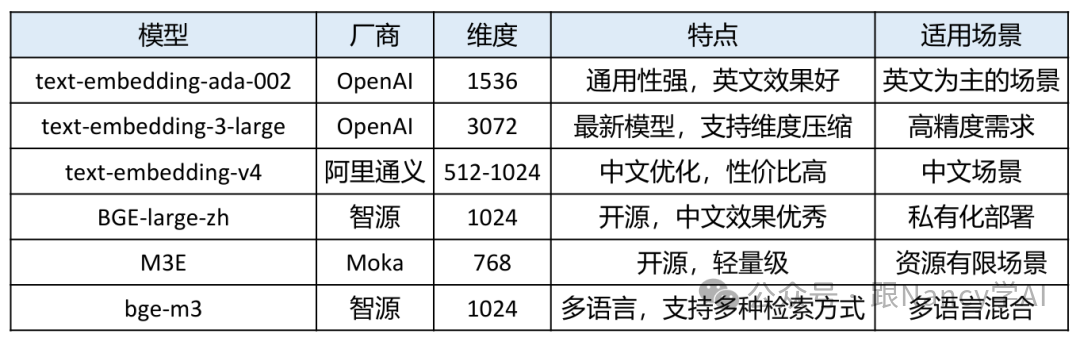
8、选择Embedding模型需要考虑哪些因素?
-
语言支持:
- 中文场景:优先考虑
BGE系列、阿里的text-embedding-v4。
- 英文场景:
OpenAI的系列模型效果稳定。
- 多语言混合:智源的
bge-m3是优秀的选择。
-
部署方式:
- API调用:快速启动,如OpenAI、通义千问的Embedding API。
- 私有化部署:保障数据安全与延迟,如
BGE、M3E,可部署在自有GPU服务器上。
-
性能指标:
- 延迟:本地部署通常远低于API调用(无网络开销)。
- 吞吐:取决于硬件配置和模型本身的计算效率。
- 精度:最可靠的评估方式是在自己的业务数据上进行测试。
-
成本考量:
- API按量付费:初期成本低,但随着调用量增长,费用可能上升。
- 私有部署:前期需要GPU硬件投入,长期来看可能更经济。
- 向量维度:更高的维度通常意味着更好的表达能力,但也会增加存储和计算成本。
9、如果RAG效果很差,可以从哪几个方面去调试?
当RAG系统表现不佳时,建议按照流程进行系统性排查。首要任务是定位问题发生在检索阶段还是生成阶段。
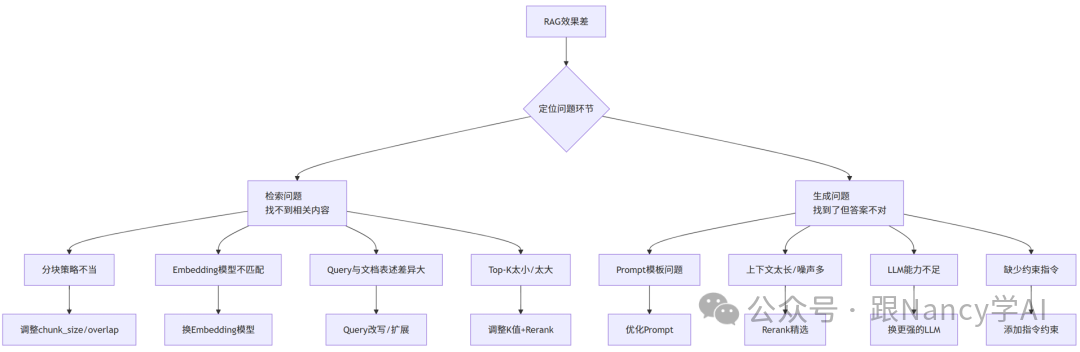
Step 1: 检索阶段调试
如果根本没能检索到相关文档,答案自然无从谈起。
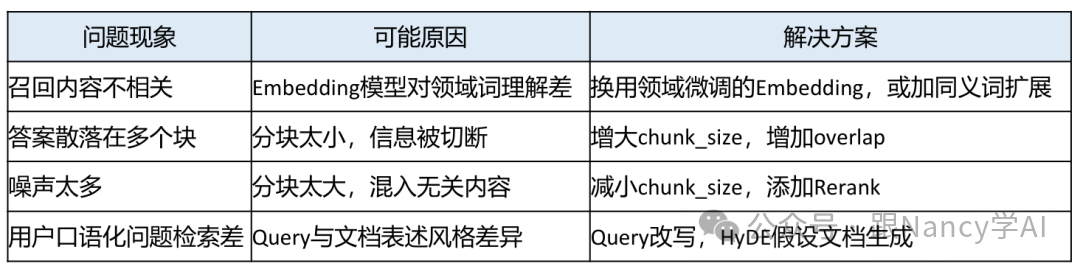
Step 2: 生成阶段调试
如果检索到了正确文档,但LLM生成的答案仍然有问题,则需聚焦于生成环节。
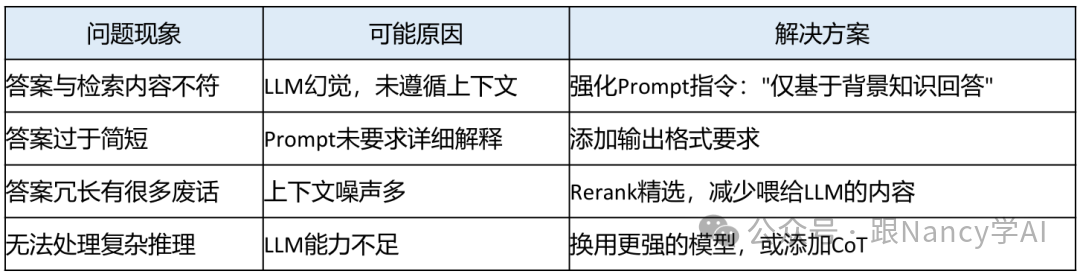
Step 3: 调试工具与方法
实战中,编写一个简单的调试函数来可视化检索结果非常有用。
# 调试检索效果的方法
def debug_retrieval(query, index, metadata, k=10):
"""打印检索详情,帮助调试"""
query_vec = get_embedding(query)
distances, indices = index.search(
np.array([query_vec]).astype('float32'), k
)
print(f"Query: {query}")
print("-" * 80)
for rank, (idx, dist) in enumerate(zip(indices[0], distances[0])):
if idx == -1:
continue
doc = metadata[idx]
similarity = 1 / (1 + dist) # L2距离转相似度
print(f"Rank {rank+1} | 相似度: {similarity:.4f} | 距离: {dist:.4f}")
print(f"来源: {doc.get('source', 'N/A')}")
print(f"内容: {doc['text'][:100]}...")
print("-" * 40)
return indices, distances
调试流程建议:
- 先检检索:使用
debug_retrieval函数检查Top-K个结果是否相关。如果相似度普遍很低,说明检索环节有问题。
- 再验生成:如果检索结果质量高但答案差,重点优化Prompt模板和指令。
- 记录与分析:系统性地收集Bad Case,建立一个评估数据集,用于持续迭代和改进系统。
10、当用户的问题很模糊,或者依赖上一轮对话时,RAG怎么优化?
这是多轮对话场景下的核心挑战。优化方案主要围绕理解用户真实意图和补充对话上下文展开。
Step 1: 问题类型分析
首先需要识别模糊问题的类型。

Step 2: Query改写技术
针对识别出的问题类型,采用不同的改写策略。
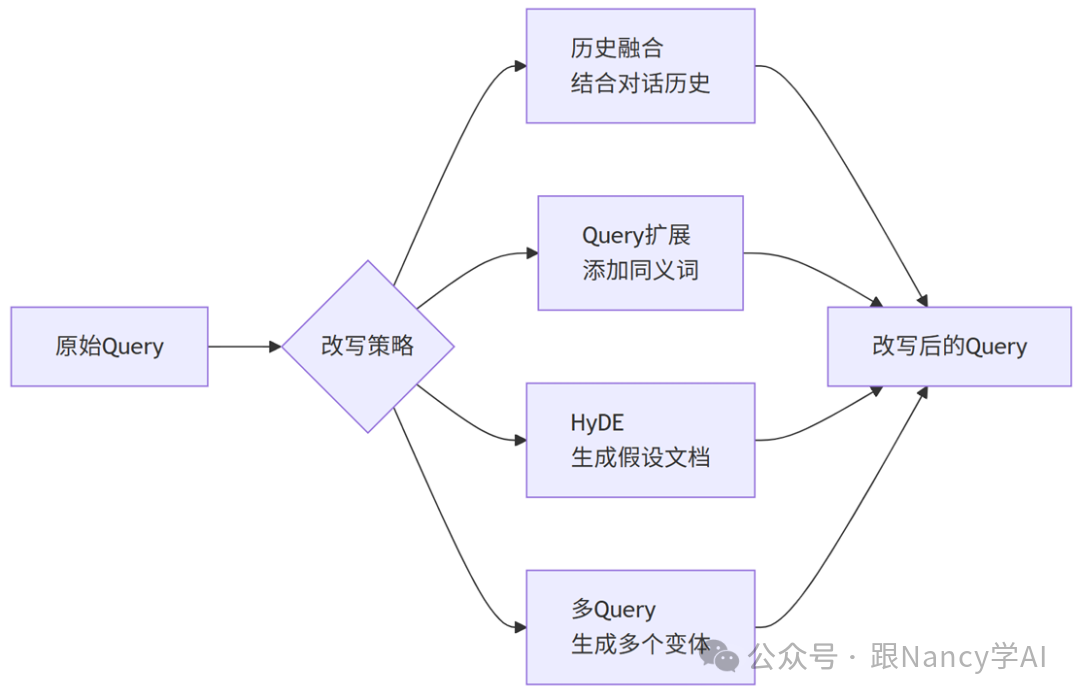
Step 3: 多轮对话RAG架构
将对话历史管理和Query改写模块集成到标准RAG流程中。
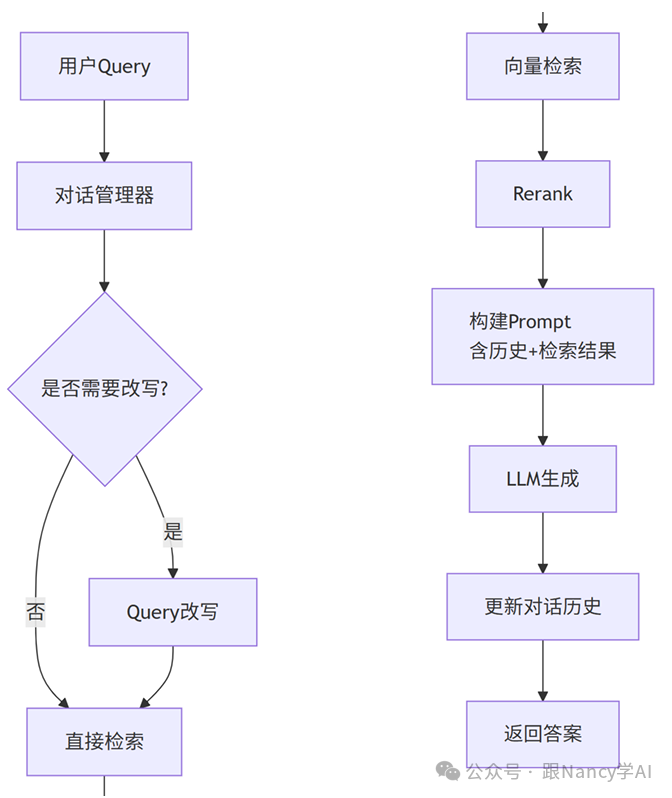
实践建议:
- 历史长度:对话历史不宜过长,一般保留最近3-5轮即可,避免噪声积累。
- 按需改写:可以用一个轻量级分类器或规则判断当前Query是否依赖历史,避免不必要的改写开销。
- 模型选择:改写任务可以使用较小的模型(如7B参数),以降低延迟和成本。
- 记录日志:记录改写前后的Query,便于后续分析和调试。
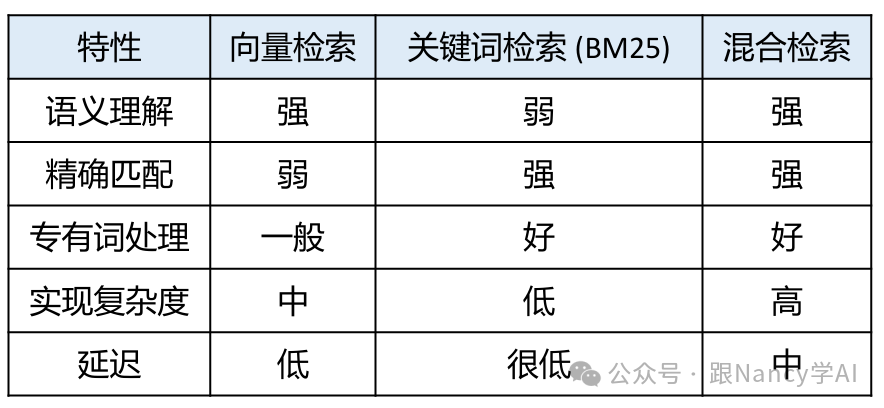
11、只用向量检索吗?它有什么缺点?什么是混合检索?
尽管向量检索在语义理解上表现出色,但它并非完美:
- 对精确匹配不敏感:例如产品型号“iPhone 15 Pro Max”、特定人名或代码函数名,向量检索可能无法精确命中。
- 领域专有词理解偏差:Embedding模型在训练时可能未充分接触某些垂直领域的术语,导致语义表示不准。
- 字面匹配缺失:对于需要完全一致的关键词匹配场景,向量检索可能失败。
混合检索正是为了弥补这些缺陷而生。它结合了向量检索(语义理解)和关键词检索(如BM25算法,擅长精确字面匹配),取长补短。
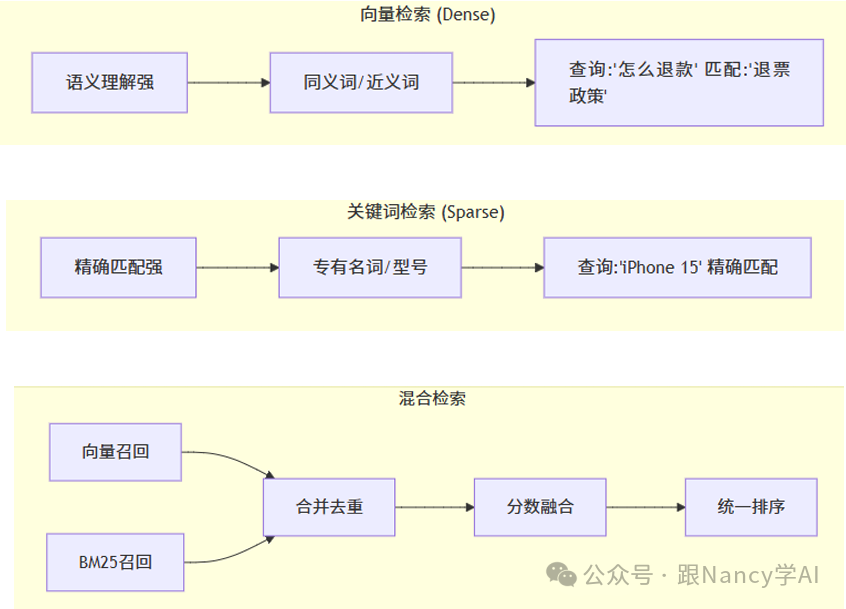
12、检索召回了20条文档,怎么确保喂给LLM的是最好的3条?
答案是使用重排序模块。初步的向量检索(使用Bi-Encoder)追求速度,负责从海量数据中快速召回一个较大的候选集(如Top-20)。随后,Rerank模型(通常是Cross-Encoder) 对这个候选集进行精细化的打分和排序,选出最相关的少数几条(如Top-3)喂给LLM。

两者区别:
- Bi-Encoder(向量检索):Query和Document分别编码为向量,通过计算向量相似度得到分数。速度快,适合海量召回;但Query和Doc之间没有交互,精度相对较低。
- Cross-Encoder(Rerank):将Query和Document的文本拼接在一起,输入模型直接输出相关性分数。精度高,能捕捉细粒度语义交互;但计算代价大,只能处理少量候选。
实践建议:
- 召回数量:通常,初步召回数量(recall_k)设置为最终需要数量(如3条)的5-10倍(即15-30条)。
- 模型选择:中文场景可选用
bge-reranker,多语言场景可考虑Cohere的Rerank API。
- 权衡延迟:Rerank会增加系统延迟,需根据业务对响应速度的要求进行调整。
- 分数过滤:可以设置一个相关性分数阈值,过滤掉分数过低的结果,即使它排在前面。
13、系统上线后,怎么维护和迭代知识库?
RAG系统不是“一劳永逸”的工程,知识库的维护是持续的过程。

14、能否通过Agent/RL自动化维护知识库?
理论上可以,核心思路是让智能体从用户反馈或环境信号中学习如何优化系统(如调整分块参数、改写策略等)。关键在于定义好状态、动作和奖励函数。

对于大多数企业场景,方案A(基于反馈迭代Prompt)结合选择性的微调是更务实且高效的组合。
维护最佳实践:
- 定期审核:建立机制,每周/月审核收集到的Bad Case,识别系统性缺陷。
- 增量更新:知识更新时,避免全量重建索引,采用增量更新方式以降低开销。
- 版本控制:对向量索引和相关的配置(如分块参数、Prompt模板)进行版本管理,支持快速回滚。
- 生命周期管理:为文档设置有效期或版本属性,自动标记或清理过时内容。
- 监控告警:设定关键指标(如检索空结果率、用户负反馈率)的阈值,超出时触发告警。
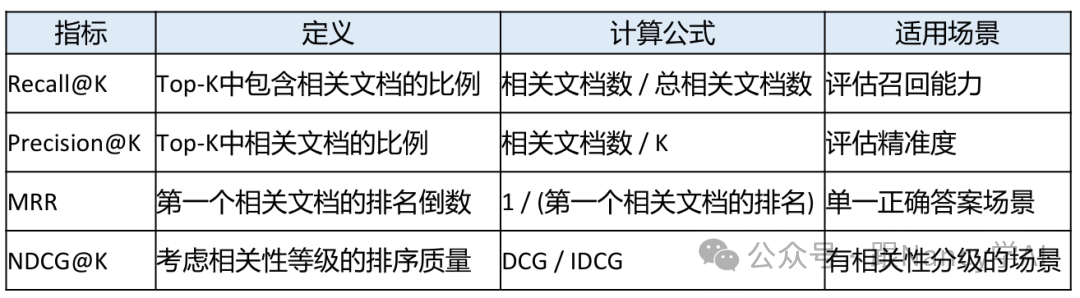
15、如何评估一个RAG系统的好坏?
评估需要从检索质量和生成质量两个维度进行,既有自动指标也需要人工检查。

16、什么是RAGAS?
RAGAS是一个专门用于自动化评估RAG系统的开源框架。其核心优势在于无需人工标注,利用LLM自身的能力来评估各项指标。
核心特点:
- 无需标注:大幅降低评估成本。
- 端到端:同时评估检索和生成环节。
- 指标全面:提供多个核心评估维度。
- 易于集成:可与LangChain、LlamaIndex等框架配合使用。
安装:pip install ragas
GitHub:https://github.com/explodinggradients/ragas
RAGAS主要生成质量指标:
- 忠实度:答案是否严格基于提供的上下文,而非模型“幻觉”。(最重要指标之一)
- 答案相关性:生成的答案是否直接回答了用户的问题。
- 上下文相关性:检索到的上下文是否与问题高度相关,剔除无关噪声。
- 上下文召回率:检索是否找齐了回答问题所需的全部关键信息。
评估建议:
- 构建评估集:创建一个包含50-100个样本的测试集,覆盖各种问题类型。
- 定期运行:将评估流程自动化,定期运行以监控系统质量变化。
- 聚焦核心:尤其关注忠实度,这是RAG解决幻觉问题的核心价值所在。
- 人机结合:定量指标与人工随机抽检相结合,确保评估的可靠性。
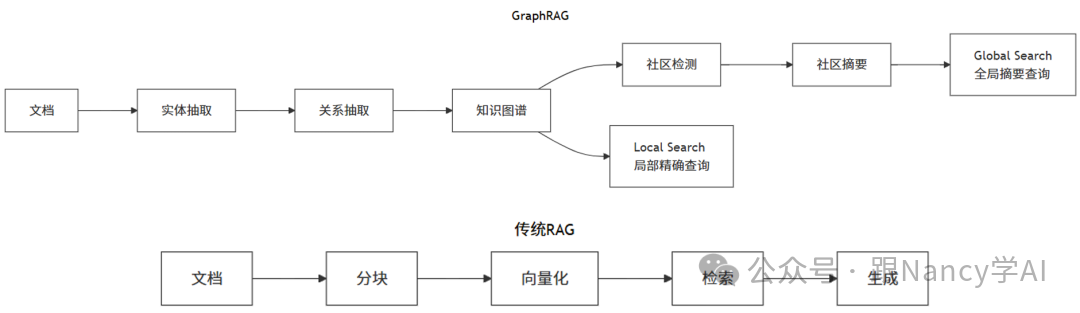
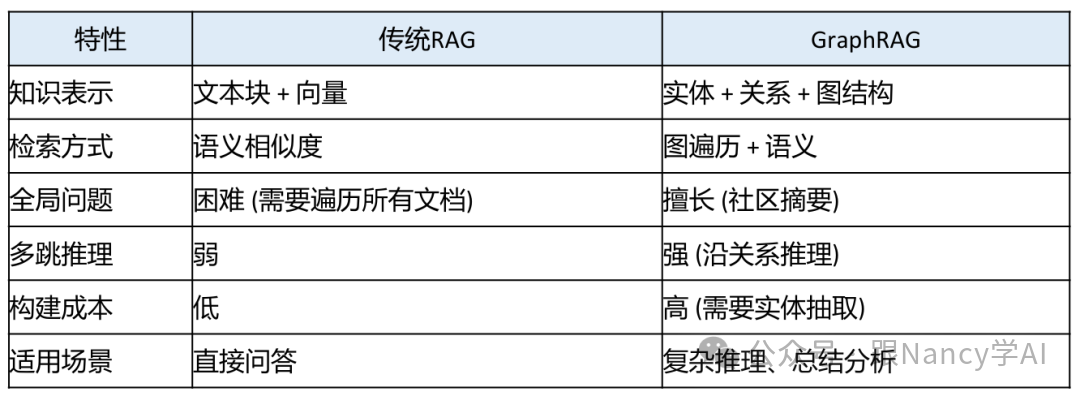
17、什么是GraphRAG,与传统RAG的区别?
GraphRAG是微软提出的一种增强型RAG架构。其核心创新在于引入知识图谱作为知识表示和组织的中间层,从而解决传统RAG在处理复杂推理、全局性问题时的局限。
GraphRAG使用建议:
- 成本考量:构建知识图谱成本较高,适用于高价值、结构复杂、需要深度推理的知识库。
- 按需选择:对于简单的问答和FAQ,传统RAG已足够高效。
- 混合架构:可以设计路由机制,简单问题走传统RAG通道,复杂推理和总结性问题走GraphRAG通道。
18、GraphRAG中的核心概念是什么?
- 实体:从文档中抽取的关键对象,如人名、公司名、技术术语。
- 关系:实体之间的连接,如“就职于”、“生产”、“位于”。
- 社区:在知识图谱中,通过算法检测出的、内部连接紧密的实体子图。一个社区通常代表一个主题或事件。
- 社区摘要:使用LLM为每个社区生成一段文字摘要,用于高效回答宏观、全局性问题。
19、GraphRAG中的两种查询模式是什么?
-
局部搜索
- 适合:具体的、事实型问题。例如:“苹果公司的CEO是谁?”
- 流程:在知识图谱中找到相关实体 -> 沿着关系边扩展探索 -> 收集相关的子图信息 -> 生成答案。
-
全局搜索
- 适合:宏观的、总结型问题。例如:“这篇长达百页的行业报告主要讲了哪几个趋势?”
- 流程:将用户问题与所有社区摘要进行匹配 -> 找出相关社区 -> 对相关社区的信息进行“Map-Reduce”式聚合 -> 生成综合性答案。
20、RAG和微调到底怎么选?回顾与总结
这是一个终极选择题,答案依然取决于你的需求:
- 选择RAG:当你的核心需求是注入频繁更新的、外部的、可追溯来源的知识,并且数据量有限或预算紧张时。
- 选择微调:当你需要改变模型固有的行为风格、输出格式,或者领域术语极其复杂、需要模型内化深层模式,且对推理速度有极致要求时。
- 组合使用:这是高级玩法。例如,先对模型进行微调,让它更“听话”,更擅长遵循检索到的上下文进行回答;然后结合RAG为其提供动态知识。这正是利用了Transformer架构模型的强大能力。
21、如何处理知识库中的矛盾信息?
- 元数据标记:为每个文档块添加“时间戳”和“权威度”(如官方文档 > 用户手册 > 社区帖子)元数据。
- 检索策略:检索时,可以按时间倒序或权威度加权进行排序,优先返回更新、更权威的信息。
- 透明化处理:在Prompt中明确告诉LLM:“如果检索到的信息之间存在冲突,请指出冲突点,并优先依据[最新/最权威]的来源进行回答。”
- 返回多源:可以同时返回多个来源的片段,让用户或后续流程自行判断。
22、RAG系统的延迟优化有哪些方法?
- 检索层:使用近似最近邻索引(如HNSW, IVF),用少量精度换取大幅速度提升。
- Embedding层:采用更小的本地Embedding模型,或对文档向量进行异步预计算和缓存。
- 重排序层:减少送入Rerank模型的候选数量(如从20减到10),或使用蒸馏得到的轻量级Rerank模型。
- LLM层:启用流式输出(边生成边返回),或选用推理速度更快的模型。
- 系统层:对频繁出现的相似Query的检索结果进行缓存。
23、如何处理超长文档(如书籍、长报告)?
- 分层索引:先为整个文档生成摘要并建立索引;用户提问时,先检索摘要,再定位到摘要对应的详细章节进行二次检索。
- 优化分块:采用带有重叠的滑动窗口分块法,确保上下文连贯。
- 利用长上下文模型:直接使用支持超长上下文(如128K、200K tokens)的LLM,一次性输入更多内容。但需注意成本与效果平衡。
- 迭代检索:先检索一部分内容,让LLM判断是否已足够回答,若不够,再根据LLM的反馈检索更多相关内容。
24、如何防止LLM幻觉?
- 强化Prompt指令:使用强约束性指令,如:“你必须严格依据以下背景信息回答问题。如果信息不足以回答,请明确说‘根据已知信息无法回答’。”
- 要求引用来源:指令中要求模型在答案中标注引用的文档编号或片段。
- 降低随机性:将生成温度(
temperature)调低(如0.1),减少模型自由发挥的空间。
- 答案交叉验证:用另一个LLM(或同一模型)对生成的答案进行审查,判断其是否能在上下文中找到支持。
- 保障上下文质量:如前所述,通过Rerank确保喂给LLM的上下文高度相关,从源头上减少幻觉诱因。
25、多模态RAG怎么做?
让RAG系统能够理解图像、表格等内容。
- 图片:使用多模态Embedding模型(如CLIP、通义千问VL)将图片转换为向量,与文本向量一起存入数据库,支持“以图搜图”或“以文搜图”。
- 表格:将表格内容转换为结构化的Markdown或JSON格式,保留行列关系,再进行向量化或作为结构化数据单独处理。
- PDF/扫描件:结合OCR技术提取文字,同时单独处理其中的图表区域。
- 视频/音频:通过抽帧和语音识别(ASR)分别提取视觉和文本信息,建立多模态索引。
- 统一检索:最终目标是使用统一的Embedding空间,实现跨模态的联合检索。
26、如何保证RAG系统的安全性?
- 输入防护:对用户输入进行清洗和过滤,防止Prompt注入攻击,避免用户输入恶意指令操控系统。
- 权限控制:在检索层实现基于角色的访问控制,确保用户只能检索其有权访问的文档。
- 数据脱敏:在知识库构建阶段,对敏感信息(如身份证号、电话)进行脱敏处理,或标记敏感等级。
- 输出过滤:对LLM生成的内容进行安全审查,过滤掉可能存在的敏感、有害信息。
- 全面审计:记录所有用户查询、检索到的文档、生成的答案以及系统操作日志,便于事后追溯和分析。
希望这份覆盖了RAG从理论到实践、从构建到维护的“百科全书”式解答,能为你提供切实的帮助。技术实践的道路总是充满细节与挑战,持续学习、动手实验并与社区交流是成长的最佳途径。欢迎在云栈社区分享你的RAG实践经验与思考。
 发表于 2026-4-17 00:53:32
|
查看: 175|
回复: 0
发表于 2026-4-17 00:53:32
|
查看: 175|
回复: 0
