人工智能的核心目标在于让机器能够执行通常需要人类智能的任务,例如语言理解、图像识别和复杂问题解决。其发展脉络清晰可循:
- 早期阶段:以规则为基础的专家系统,完全依赖预设的逻辑与规则。
- 机器学习时代:通过数据训练模型,让机器从数据中自行学习规律,模型参数规模在几十到几百个。
- 深度学习时代:利用更复杂的神经网络模拟人脑结构,处理更复杂的任务,参数量可达百万级别。
- 大模型时代:以海量数据和强大算力为基础,构建通用性强、性能卓越的AI模型,参数规模跃升至千亿甚至万亿级别(例如6710亿参数)。
从功能上,AI主要分为两大类:

- 生成式AI:专注于创造新内容,例如文本、图像、音频。典型代表包括大语言模型(如GPT、DeepSeek、通义千问),应用在客服咨询、内容创作等场景;以及文生图/视频模型(如Sora、DALL-E、Midjourney),用于产品设计、影视预览等领域。
- 分析式AI:也称为判别式AI,核心任务是对已有数据进行分类、预测或决策。例如,视觉识别模型(如YOLO、ResNet)用于智能制造、医疗影像分析;自动驾驶模型则属于复杂的复合模型,应用于无人配送、高级辅助驾驶等场景。
二、大语言模型是如何训练出来的?
大语言模型的训练是一个持续演进的过程。早期的监督学习直接告诉模型“香蕉是什么”;后来发展为让模型生成多个答案,人类通过排序优劣来训练奖励模型;如今,模型通过强化学习,结合人类反馈不断自我迭代进化。下图直观展示了这一流程:
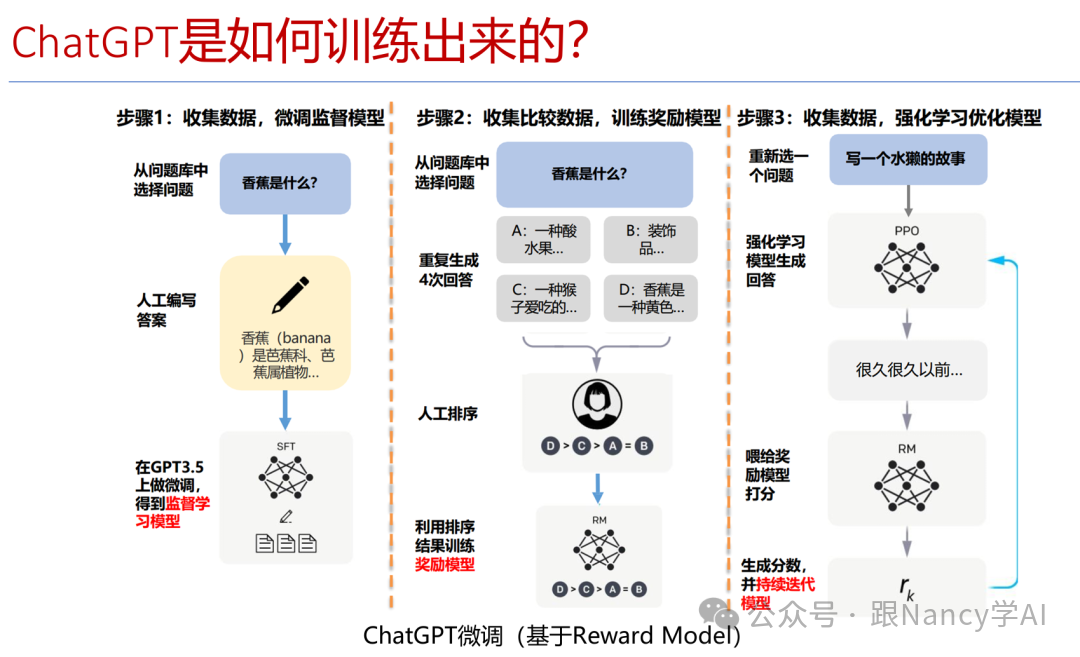
模型的规模也在飞速增长。2018年GPT的参数量约为1.17亿,训练数据量约5GB;到了2020年的GPT-3,参数暴涨至1750亿,数据量达45TB。据预测,未来的GPT-5参数量可能达到惊人的100万亿级别。这种演进使得模型能够更精准地理解用户意图、实现流畅的上下文衔接,并展现出强大的知识推理能力。
随着模型能力的增强,应用形态也在变革。如今功能繁多的APP,其有限的屏幕界面已难以承载所有复杂功能。未来,APP很可能演变为极简的对话形式。例如,在淘宝对话框里输入想要的穿搭风格,系统就能自动搜索并搭配好服装放入购物车。
三、理解LLM中的核心概念:Token
Token是大型语言模型处理文本的最小单位。由于模型无法直接理解文字,它需要先将文本切分成一个个Token,再将其转换为数字向量进行计算。
不同的模型使用不同的“分词器”来定义Token。这意味着,同一个词在不同模型中的编码可能不同。例如:
- 英文 “Hello World”:在GPT-4o中可能被切分为
["Hello", "World"],对应的Token ID为 [13225, 5922]。
- 中文 “人工智能你好啊”:在DeepSeek-R1中可能被切分为
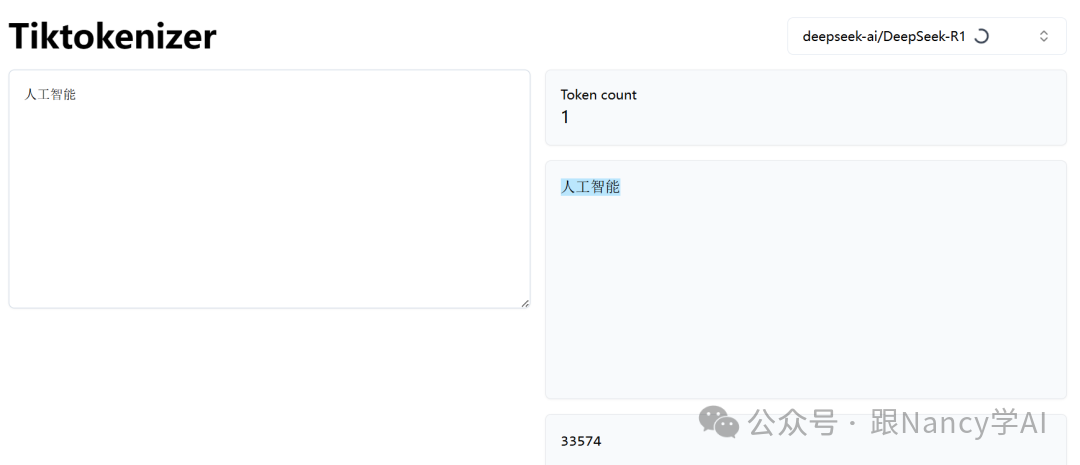
["人工智能", "你好", "啊"],对应的Token ID为 [33574, 30594, 3266]。
你可以在 https://tiktokenizer.vercel.app/ 这个工具中查看具体的Token映射。比如,“人工智能”这个词,在DeepSeek模型中通常只占1个Token,而在GPT-4o中则可能被分为“人工”和“智能”两个Token。需要注意的是,除了文本本身,对话中的分隔符、起始符和结束符也会占用Token。
四、控制生成文本的“旋钮”:Temperature与Top P
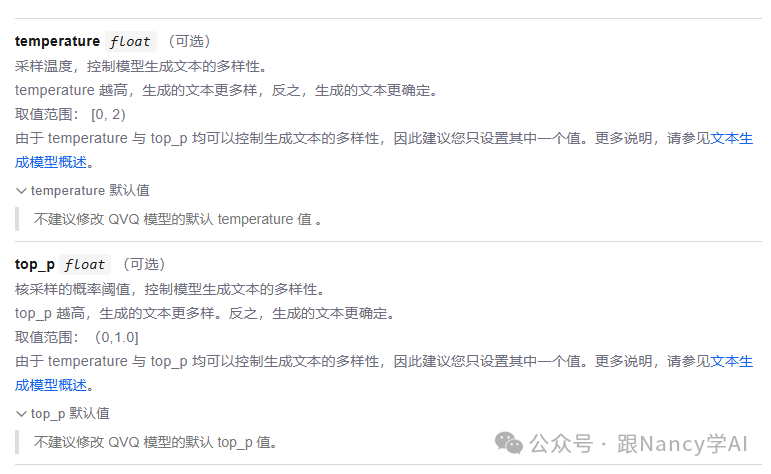
大模型生成文字本质上是一个概率预测过程。Temperature和Top P是两个关键的参数,通过调整模型选择不同概率Token的倾向,来控制生成文本的多样性,但它们的原理不同。
-
Temperature (温度):
- 原理:在模型计算出下一个Token所有可能的概率分布后,Temperature会调整这个分布的“平滑度”。
- 高温度 (如 1.0+):会让低概率的Token更容易被选中,使生成结果更具创造性和随机性,但也可能导致不连贯。
- 低温度 (如 0.2):会让高概率的Token权重更大,使生成结果更稳定、更符合常规,但也会显得保守和缺乏新意。
-
Top P (核采样):
- 原理:设定一个概率累计阈值P。模型会从概率最高的Token开始累加,直到总和超过P,然后仅从这个累积的“核心”词汇表中选择下一个Token。
- 高Top P (如0.9):候选词汇表较大,结果更具多样性。
- 低Top P (如 0.1):候选词汇表非常小,结果更具确定性和聚焦性。
举个例子:
假设模型要补全句子:“今天天气真...”,其预测的下一个词概率为:好(60%)、不错(30%)、糟(9%)、可乐(0.01%)。
- 使用高Temperature:会“熨平”概率分布,使得“可乐”这种极低概率的词也有机会被选中,可能导致离谱的输出。
- 使用Top P (设为0.9):模型会累加概率最高的词,直到总和超过90%。这里“好”(60%) + “不错”(30%) = 90%,因此模型只会从{“好”, “不错”}中做选择,直接排除了“可乐”。
在实际调用大模型API时,你通常可以设置这两个参数。例如,在阿里云的DashScope平台(https://dashscope.console.aliyun.com/)的模型API文档中,就能找到这些参数的详细说明。
五、AI对话产品的扩展能力:联网、读文件与记忆
为了弥补大模型的固有局限,现代AI对话产品集成了多种“超能力”。
1. 联网搜索
此功能旨在获取外部实时信息,以弥补大语言模型训练数据存在截止日期的限制。
- 当用户提问涉及最新事件(如“今天NBA比赛结果?”)时,系统会识别需求,自动将问题转化为搜索关键词。
- 程序调用搜索引擎API获取实时信息。
- 这些信息作为上下文提供给模型,由模型进行整合与总结,生成与时俱进的回答。
2. 读取文件
大模型单次会话的上下文窗口容量有限(例如32K Token,约3万多字)。为了处理更长的文档,采用了检索增强生成 (Retrieval-Augmented Generation, RAG) 技术。
- 上传文件(如PDF)后,系统会将其内容分割成较小的文本块。
- 通过Embedding技术将这些文本块转化为向量,并存入向量数据库。
- 当你提问时,问题也会被转化为向量,系统在数据库中快速检索出最相关的文本块。
- 这些相关文本块连同你的问题一起交给大模型,从而生成基于文档的精准答案。例如,上传公司财报后提问“第二季度的利润是多少?”,RAG系统能准确定位到相关段落供模型使用。
可以说,RAG是构建在LLM之上的一个应用,当LLM“看到”超长的文件时,会自动调用RAG能力来筛选和检索相关信息。
3. 记忆能力
LLM本质上是无状态的,每次对话都是全新的开始。为了实现“记忆”,系统采用了不同策略:
- 短期记忆:将最近几轮对话拼接起来,作为上下文一起发送给模型,这受限于上下文窗口的大小(如32K)。
- 长期记忆:对于用户明确提供的、需要长期记住的关键信息(如姓名、偏好),系统会通过算法提取并存储到用户专属数据库中。在后续对话中,系统会优先读取这些信息,为模型提供个性化背景。例如,告诉AI“我喜欢简洁的回答”,这一偏好会被记录,并在后续对话中影响其回复风格。
六、全球AI发展现状与格局
当前,全球AI大模型的发展呈现出中美双雄主导的格局:
- 美国:由OpenAI、Anthropic、Google、Meta等公司引领前沿,代表模型如GPT-4o、Claude 3.5 Sonnet、Gemini系列。
- 中国:以DeepSeek(如R1、V3)、阿里巴巴(通义千问Qwen系列)、月之暗面(Kimi)等公司为代表快速追赶。部分模型在推理能力和长上下文处理上已接近甚至达到世界先进水平。
- 关键趋势:2024年以来,中国模型在多方面显著缩小了与美国的差距,尤其在开源模型和垂直领域应用上表现活跃。
- 其他地区:法国(Mistral)、加拿大(Cohere)等地也有优秀模型,但整体影响力和规模仍不及中美。
七、出口限制与硬件影响
美国对华技术限制深刻影响着中国AI的算力基础:
- 时间线:自2022年10月起,美方多次升级对高性能AI芯片(如H100、A100,及后续的H800、A800)的出口管制。
- 当前状态:仅允许向中国出口H20、L20等性能大幅阉割的芯片,且未来可能进一步收紧。
- 影响:中国AI公司不得不更依赖国产芯片(如华为昇腾)或性能降级的英伟达芯片(如H20,其算力据称仅为H100的15%左右)。
硬件性能简要对比如下:
- NVIDIA H100:989 TFLOPs(峰值算力),3.35 TB/s内存带宽。
- NVIDIA H20:148 TFLOPs,4 TB/s带宽(专为中国市场设计的合规版本)。
- AMD MI300X:1307 TFLOPs,5.3 TB/s带宽(目前未受相同限制)。
八、中国主要AI公司及模型一览
-
互联网大厂:
- 阿里巴巴:通义千问(Qwen)系列,如Qwen2.5。
- 百度:文心一言(Ernie)系列,如Ernie 4.0 Turbo。
- 腾讯:混元大模型(HunyuanLarge)。
- 字节跳动:豆包(Doubao)大模型。
- 华为:盘古大模型(Pangu 5.0)。
-
明星初创公司:
- DeepSeek:以R1、V3等开源和推理模型著称,性能卓越。
- 月之暗面(Moonshot):Kimi Chat及其K2模型,以超长上下文处理能力闻名。
- MiniMax:Text-01等模型,在多模态能力上表现突出。
- 其他:智谱AI(ChatGLM)、百川智能(Baichuan)等也在持续发力。
对AI大模型的技术原理、关键参数和产业生态有了基本了解后,如果你希望深入研究某个特定模型的技术细节、微调方法或是检索增强生成(RAG) 的实战案例,可以关注云栈社区的人工智能与技术文档板块,那里有更多开发者分享的开源实战经验和深度解析。
 发表于 2026-4-17 00:57:16
|
查看: 207|
回复: 0
发表于 2026-4-17 00:57:16
|
查看: 207|
回复: 0
