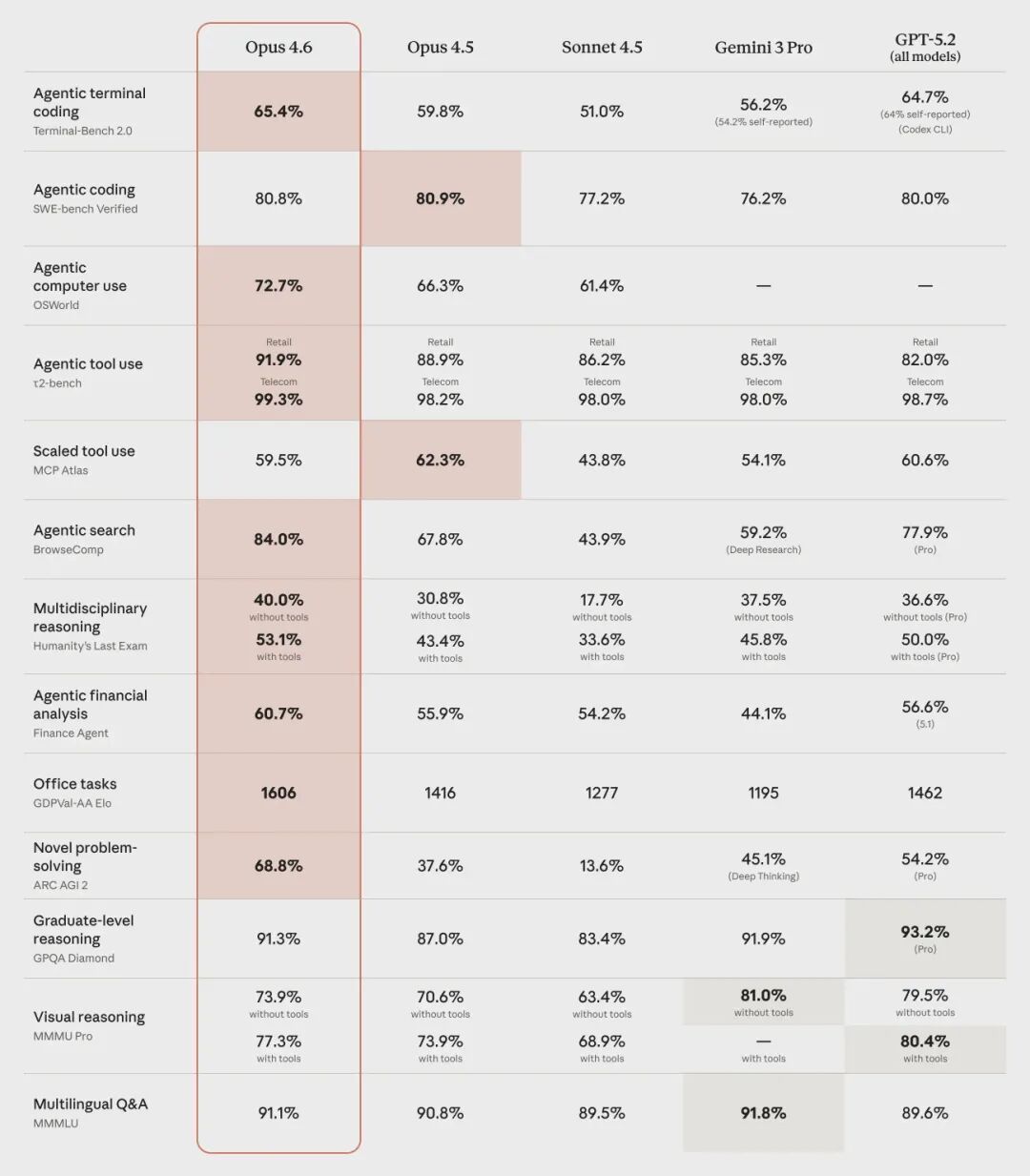
Anthropic 刚刚发布了其旗舰模型 Claude Opus 的最新版本——4.6。这次升级被认为是其“最智能模型”的一次重要迭代,新模型在多个关键基准测试中都展现了卓越的性能,尤其是在衡量抽象推理能力的 ARC-AGI 2 测试中取得了 68% 的成绩,显著超越了当前的其他主流竞争对手。
核心能力提升
Opus 4.6 在编程能力上有了实质性的进步。它能够更周密地规划任务,在大型代码库中的操作也更加可靠,代码审查和调试的技能也得到了增强。对于开发者而言,这些改进意味着更高效的生产力工具。
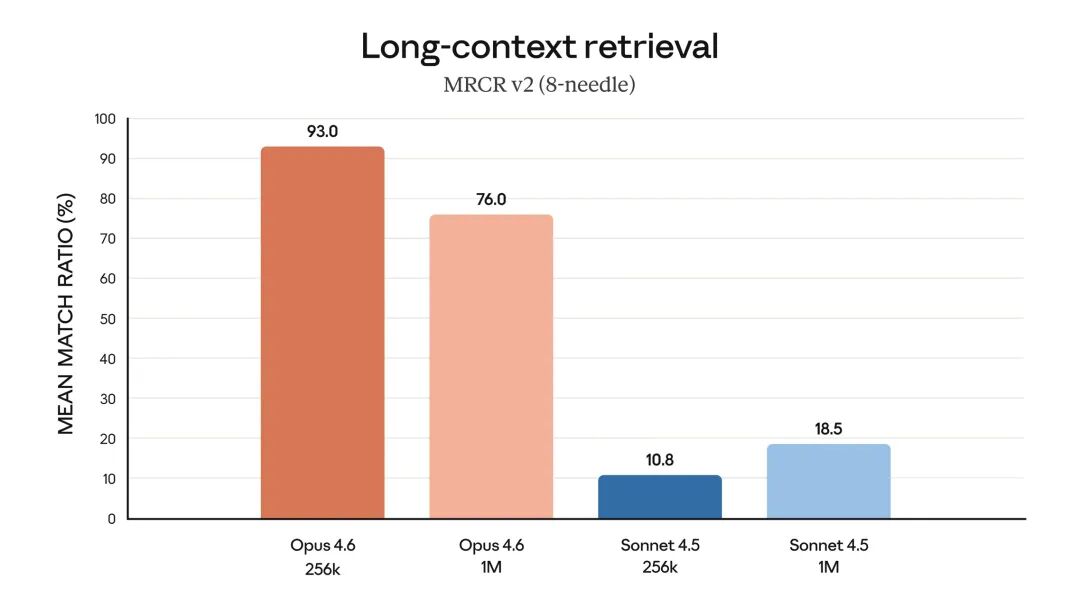
值得一提的是,这是 Opus 系列首个提供 100 万 token(测试版)上下文窗口的模型。这意味着它能处理更长的文档和更复杂的多轮对话,在需要超长信息关联的任务中潜力巨大。
在日常办公场景下,新模型能够运行财务分析、进行深度研究,并熟练地创建和编辑文档、电子表格及演示文稿。在 Anthropic 的 Cowork 协作环境中,Opus 4.6 可以自主运用这些技能为用户提供服务,向真正的“智能助手”又迈进了一步。
基准测试表现
除了 ARC-AGI 的突出表现外,Opus 4.6 在一系列前沿评估中均达到了行业领先水平:
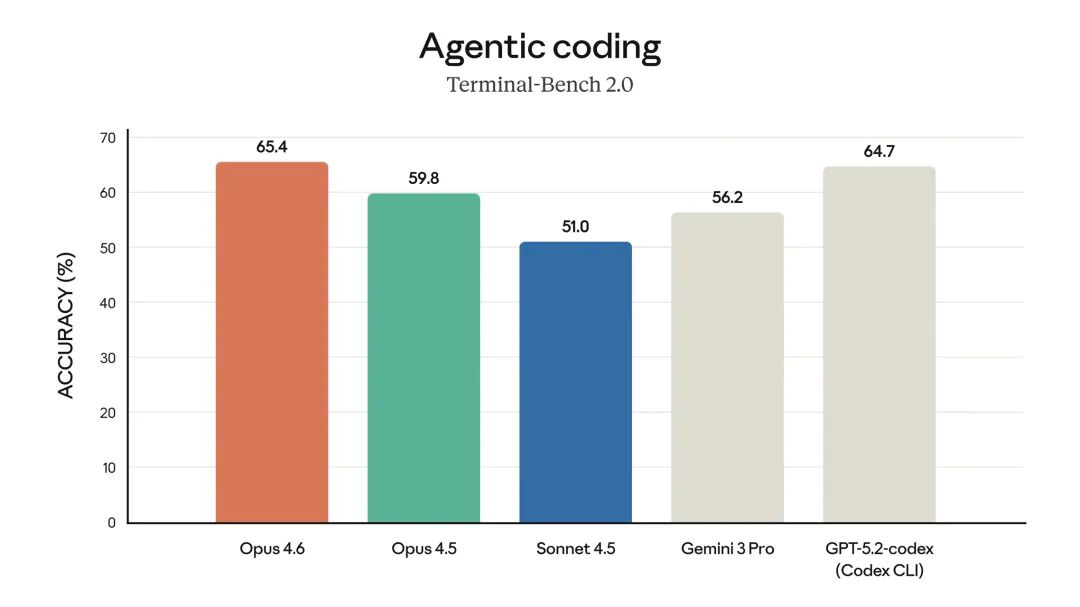
- 在 Terminal-Bench 2.0 代理编码 评估中取得了最高分。
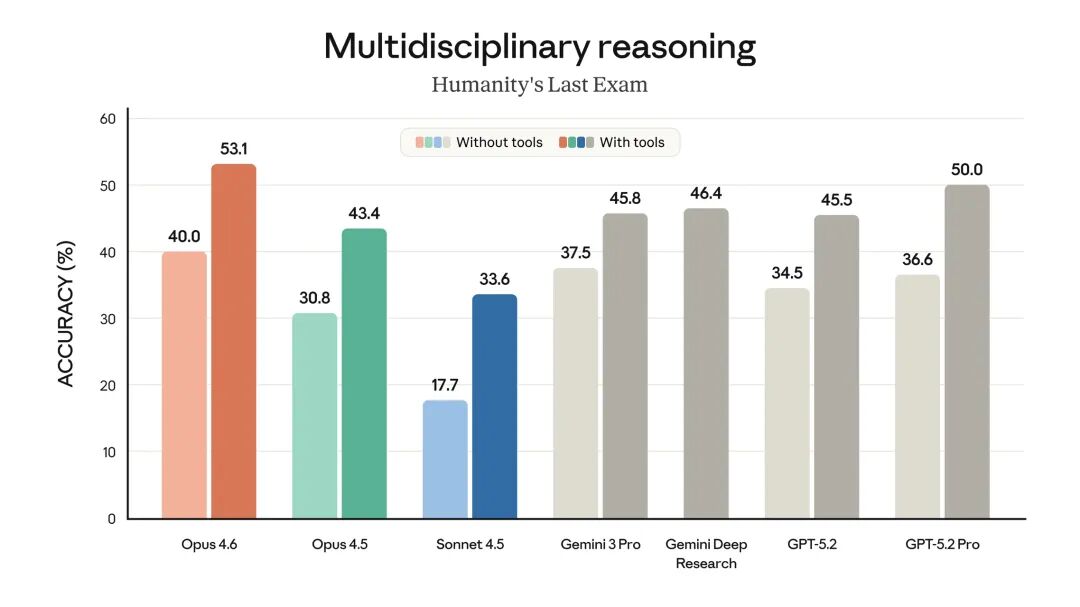
- 在 Humanity‘s Last Exam 这类复杂的多学科推理测试中,领先于所有其他前沿模型。
- 在衡量经济价值的实际工作任务评估 GDPval-AA 中,其得分比行业次优模型(OpenAI GPT-5.2)高出约 144 个 Elo 点。
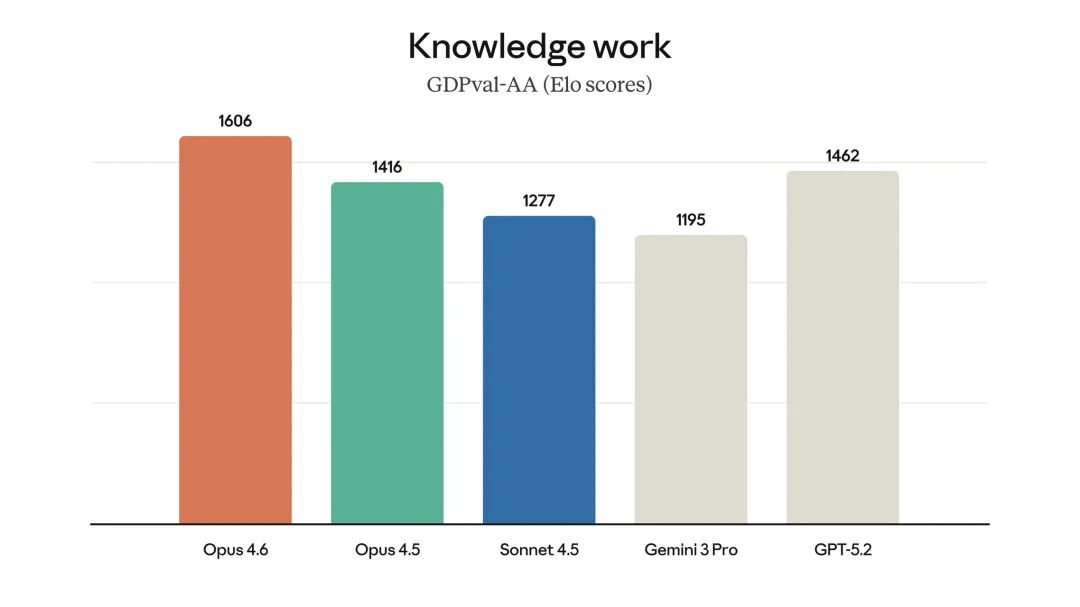
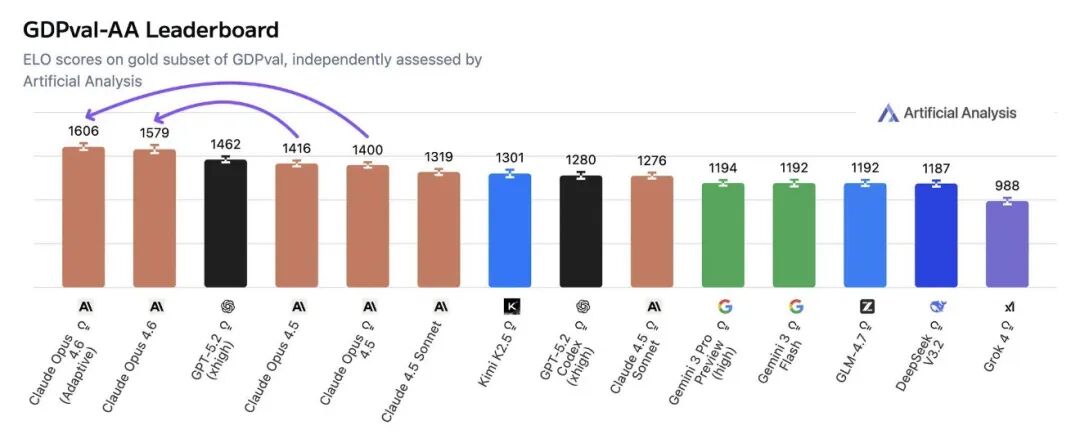
对于这样的成绩,社区反应不一。有评论惊叹:“ARC-AGI 2 的得分太疯狂了,几个月内这个领域就会饱和。”同时也有声音质疑,这些基准测试究竟能在多大程度上衡量模型解决实际、复杂问题的“有意义的能力”。关于大模型能力的评估体系,一直是人工智能领域的热门讨论话题。
实际应用反馈
从早期测试合作伙伴的反馈来看,评价颇为积极。Notion 称其为“Anthropic 发布的最强模型”,GitHub 指出它在“复杂的多步骤编码工作”上表现出色,Replit 则评价其在代理规划方面实现了“巨大飞跃”。这些来自一线应用方的声音,或许比单纯的基准分数更能说明其实际价值。
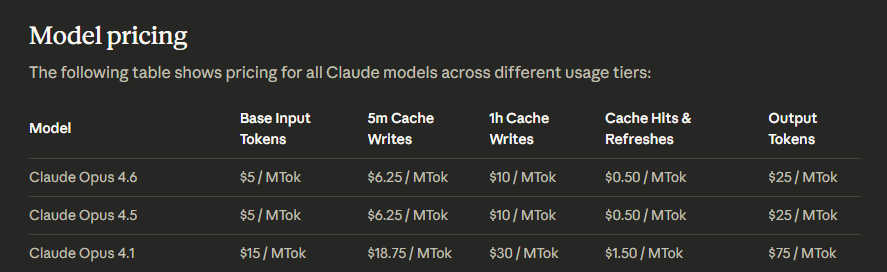
定价保持不变
尽管性能提升显著,但 Anthropic 保持了 Opus 模型的定价策略:每百万 token 输入 5 美元,输出 25 美元。这一决定让部分期待因性能提升而获得降价或“加量不加价”福利的用户感到些许失望。
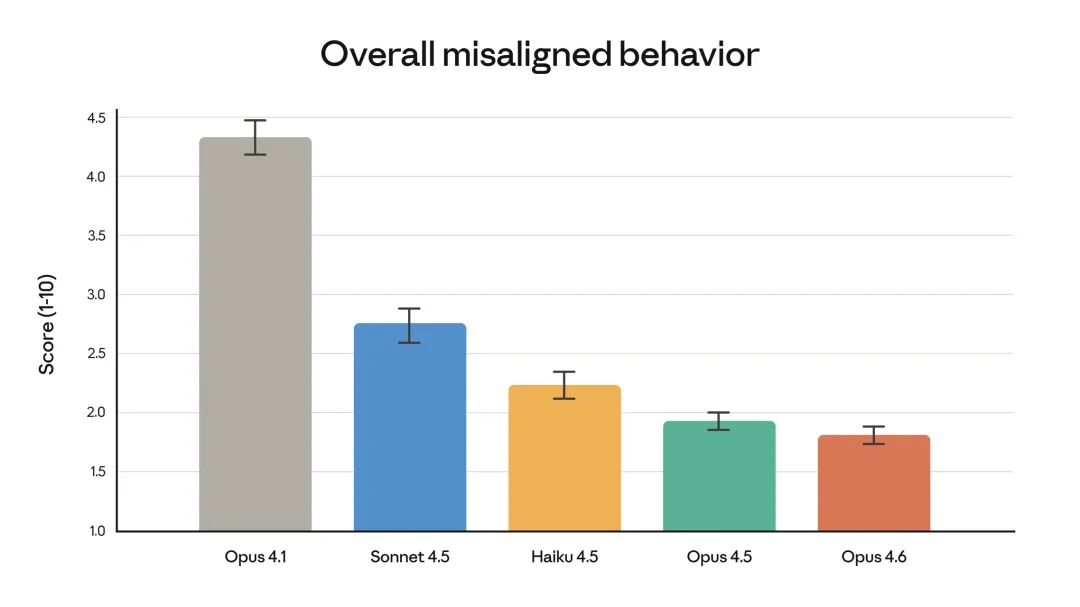
安全性能
Anthropic 特别强调,此次智能的提升并未以牺牲安全性为代价。在自动化的行为审计中,Opus 4.6 显示出较低的错误对齐行为发生率,例如欺骗、不当奉承、鼓励用户妄想或合作滥用等。
开发者新功能
对于通过 API 集成的开发者,本次更新也带来了几项实用的新功能:
- 自适应思考:模型可以自行判断何时需要进行深度、缓慢的推理,以应对复杂问题。
- 努力控制:提供四个可调节的智能水平选项,让开发者能在速度、成本和推理深度之间取得平衡。
- 上下文压缩:模型可以自动总结和替换上下文中较旧的部分,这对于管理超长对话和降低成本很有帮助。
- 128k 输出 token 支持:单次生成长文本的能力得到进一步增强。
目前,Claude Opus 4.6 已通过 claude.ai 网站、API 及所有主要云平台提供。对于那些需要处理复杂任务、依赖长期记忆和代理工作流程的用户和开发者来说,这次升级无疑值得重点关注和测试。技术的快速迭代总是能带来新的可能性,也促使我们不断思考工具与工作的未来形态。 |  发表于 2026-2-7 04:12:16
|
查看: 333|
回复: 0
发表于 2026-2-7 04:12:16
|
查看: 333|
回复: 0
