输入一张胸部X光片,模型能准确描述肺部情况;输入一例病理切片,模型能准确分类组织来源;输入一段病历和皮肤照片,模型还能写出一份结构化的诊断报告。
这就是此前介绍过的MedGemma 医疗多模态大模型。该模型基于 Gemma 3 架构打造,专为医学图像理解和临床推理任务而设计。
最近,谷歌团队将其升级迭代到 MedGemma 1.5,不仅显著提升了性能,还扩展了对多个新医学影像和数据处理应用的支持。

其中一个关键突破在于,它从二维图像处理过渡到了 高维医学成像。这意味着模型不再局限于平面的X光或超声图像,而是能够直接处理3D的CT和MRI体数据,甚至可以解读海量的全切片数字病理图像(WSI),实现了从静态二维图像到动态三维数据分析的能力跃迁。
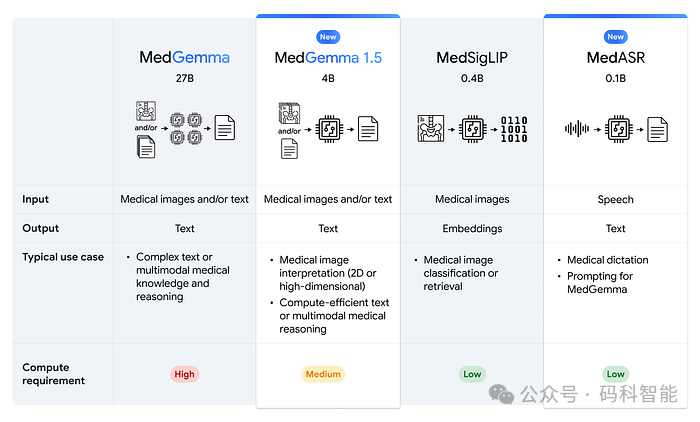
目前,谷歌已经开源了整个 MedGemma 系列模型,包括 MedGemma 1.5、MedASR 以及 MedSigLIP 图像编码器。这些模型可免费用于研究、教学以及商业产品开发,为人工智能在医疗领域的应用降低了门槛。
- MedGemma 1.5 (4B 参数量):一个可以在本地部署的轻量化医疗多模态模型,能够读取并分析文本及图像格式的医疗非结构化数据,并进行推理。
- MedSigLIP (0.4B 参数量):一个专注于医疗领域的图像编码器,适用于不涉及文本生成的任务,例如零样本分类或基于语义的图像检索。
- MedASR (0.1B 参数量):一个专注于医疗术语的语音识别模型,在Whisper large-v3的基准测试中,词错误率(WER)仅为5.2%,转录准确率更高。
# Paper
MedGemma Technical Report
# Arxiv
https://arxiv.org/pdf/2507.05201
# Model
https://huggingface.co/google/medgemma-1.5-4b-it
MedGemma 1.5 有何亮点?
与第一代的 27B 大模型相比,MedGemma 1.5 4B 是一个参数量更小、可在普通显卡上运行的轻量化模型,更适合本地部署和研究。
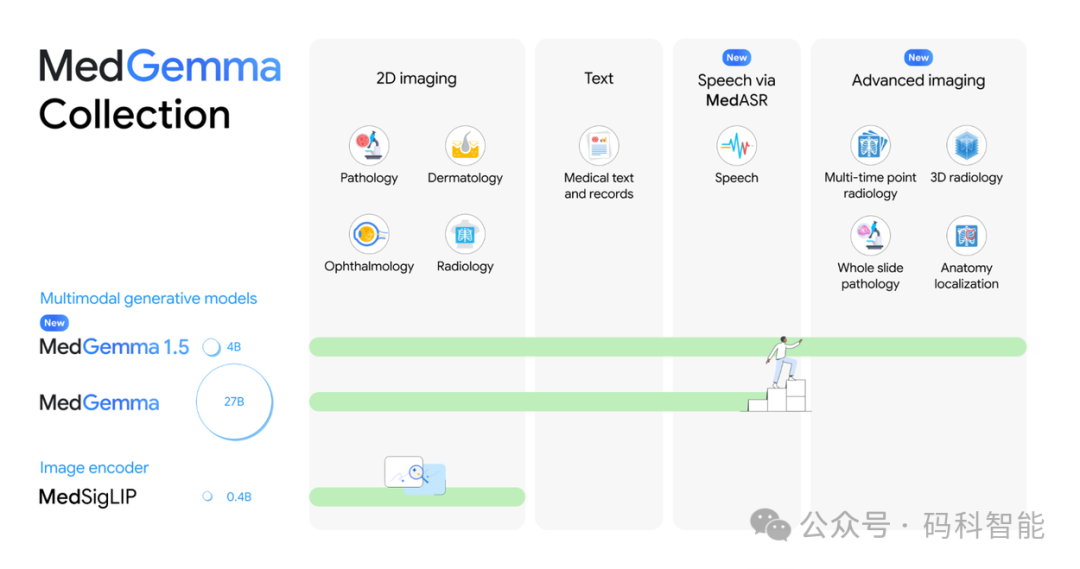
相较于通用模型,MedGemma 1.5 的核心亮点在于其对复杂医学场景的强大支持:
- 原生支持高维医学影像:除了传统的X光和超声,它能直接处理CT、MRI的3D体数据,并支持全切片病理图像。医生甚至可以上传包含数百张切片的整套肺部CT,模型能自动识别病灶分布、体积变化与组织结构异常。
- 强大的纵向分析与解剖定位能力:模型可以追踪患者数月甚至数年的胸部X光变化,自动标注关键指标的演变趋势。在解剖定位方面,其交并比(IoU)从上一代的约3%大幅提升至38%,能精准锁定肋骨、膈肌等关键结构。
- 结构化数据提取:它能够从杂乱的实验室报告中自动提取并结构化关键数据,如白细胞计数、肝功能指标等,大幅减轻临床数据录入的工作量。

性能表现如何?
在权威基准测试中,MedGemma 1.5 的表现相当出色,在多类任务上均有显著提升:
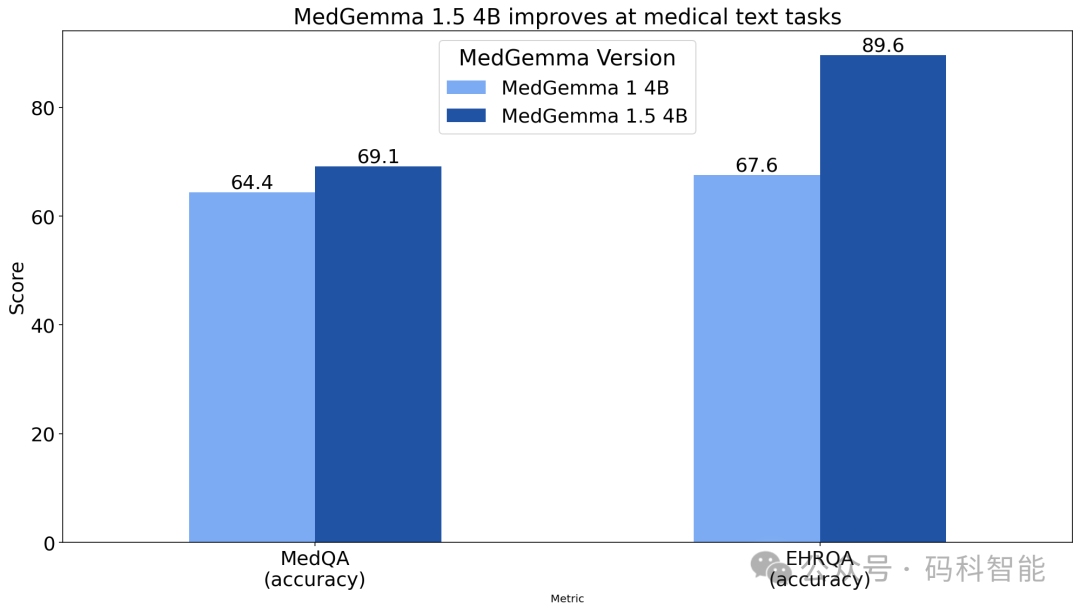
- CT 疾病分类准确率提升至61%(+3%)
- MRI分类准确率从51%飙升至65%(+14%)
- 胸部X光解剖定位交并比达38%(原为3%)
- 时间序列分析宏观准确率提升至66%(+5%)
- 实验室报告数据提取F1分数达78%(+18%),接近人类专业录入水平
这些改进不仅体现在公开数据集(如MIMIC-CXR、BraTS)上,也在多家三甲医院的脱敏临床数据中得到了验证,显示出强大的泛化能力。
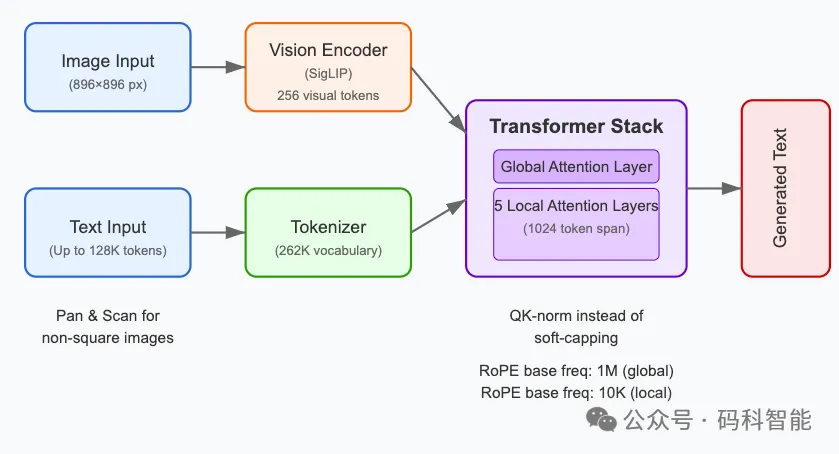
模型架构是怎样的?
MedGemma 1.5 采用了先进的多模态架构设计:
- 自监督图像编码器:使用了在大规模医学图像上预训练的 SigLIP 编码器,能够有效捕捉图像的语义特征,无需依赖大量人工标注。
- 多模态融合机制:在4B版本中,图像与文本通过统一的 Transformer 架构进行深度融合与交互,使得模型能够在图文混合的上下文中进行连贯推理。
基于 Gemma 的强大基座,MedGemma 系列模型还具备易于微调的特点。目前,在社区的努力下,基于该系列已衍生出超过500款衍生模型,展示了其在开源实战中的活跃生态和灵活性。
展望未来,MedGemma 系列还有望支持超声动态视频分析、病理切片细胞级分割等更前沿的功能。医疗AI正在从单纯的“能看图”向更深层的“能思考”和“会分析”演进。
对于医疗AI和开源模型的开发者而言,MedGemma 1.5 的开源提供了一个强大的、可直接上手的研究与开发工具。更多关于模型部署与应用的讨论,欢迎到 云栈社区 的相关板块交流。 |  发表于 2026-1-31 22:00:43
|
查看: 180|
回复: 0
发表于 2026-1-31 22:00:43
|
查看: 180|
回复: 0
