腾讯混元团队近期发布了名为“混元无相架构”(HY-WU)的研究成果,这项技术为大模型引入了一种名为“功能记忆”(Functional Memory)的全新范式。其核心在于,模型能在推理的瞬间,根据具体任务实时生成专属的参数权重,实现所谓的“秒级换脑”,从而打破了传统静态权重的局限。

这种能力从根本上解决了大模型在持续学习时面临的“灾难性遗忘”难题。你可以想象一位精通中餐的顶级大厨,在苦练法式甜点后,突然发现自己连中餐的火候都掌握不准了——传统微调或参数高效微调(PEFT)技术就有点像这种“肌肉记忆”的覆盖式擦写,极易导致新旧知识在参数空间内发生冲突。
不仅如此,静态权重在处理高度个性化、差异化的任务时也显得力不从心。例如,在图像编辑领域,增强去噪能力往往会损害艺术风格的保留;用一个共享参数去拟合所有用户需求,最终结果往往是各方妥协的平庸产物。现有的主流解决方案,如固定的LoRA适配器、检索增强生成(RAG)或混合专家模型(MoE),都触及了静态范式自身的天花板。
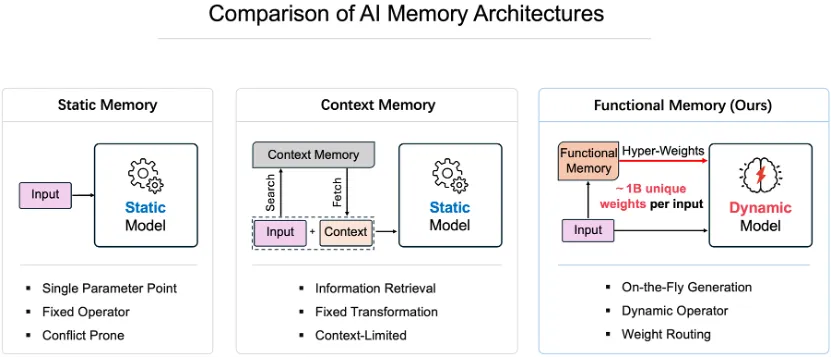
腾讯混元团队洞察到,问题的核心在于记忆接口的底层设计。为此,他们提出了HY-WU范式,不再寻找一个通用的固定参数点,而是训练一个强大的参数生成器。整个适配过程转变为根据输入条件实时合成特定算子权重的流水线,模型能够实现动态的权重路由,彻底避免了在共享参数上的反复擦写与干扰。
图像编辑验证范式跃升
研究团队选择了文本引导的图像编辑作为首个验证场景,因为它天然暴露了静态权重的各种局限。例如,修复老照片和给新照片做旧,这两个任务在参数空间里代表着几乎互斥的变换方向。
HY-WU走了一条新路:存算子映射,而非存固定数据。功能记忆演变为一种动态的条件映射机制。
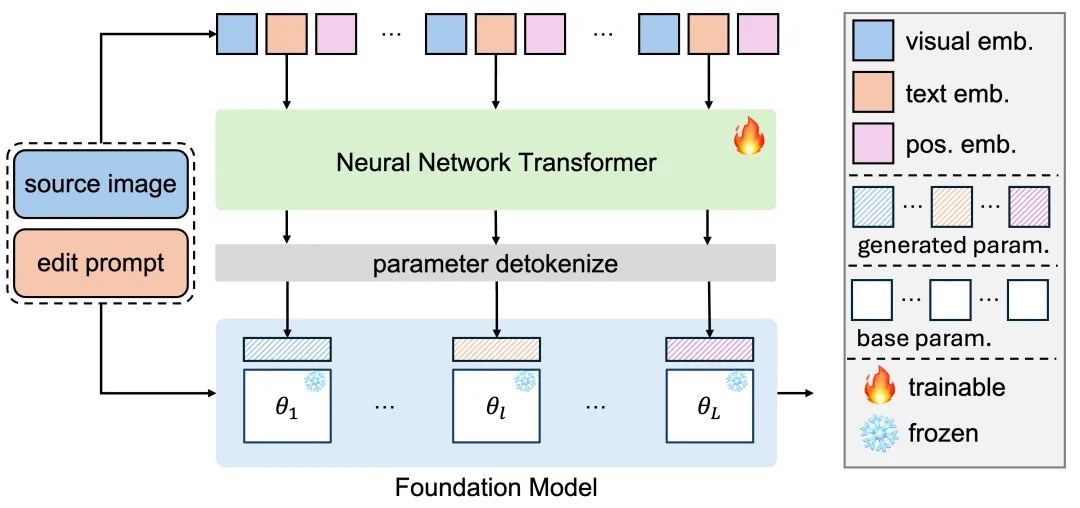
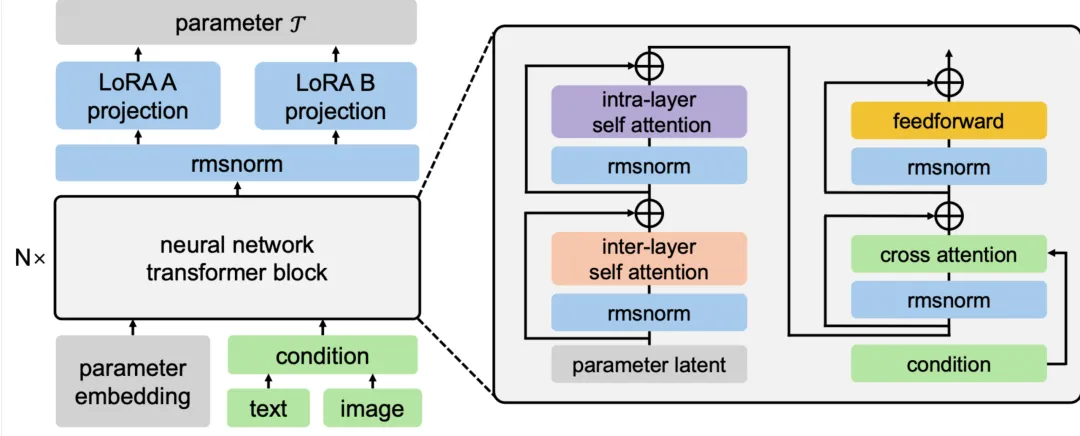
框架内置了一个基于Transformer架构的参数生成器。它不记忆固定的权重数值,而是学习如何针对特定输入实例生成最合适的算子权重。在推理时,模型感知输入图片和编辑指令,生成器在几秒钟内实时计算出一组专属的LoRA参数,随即注入到冻结的基座模型中,完成一次精准的编辑变换。
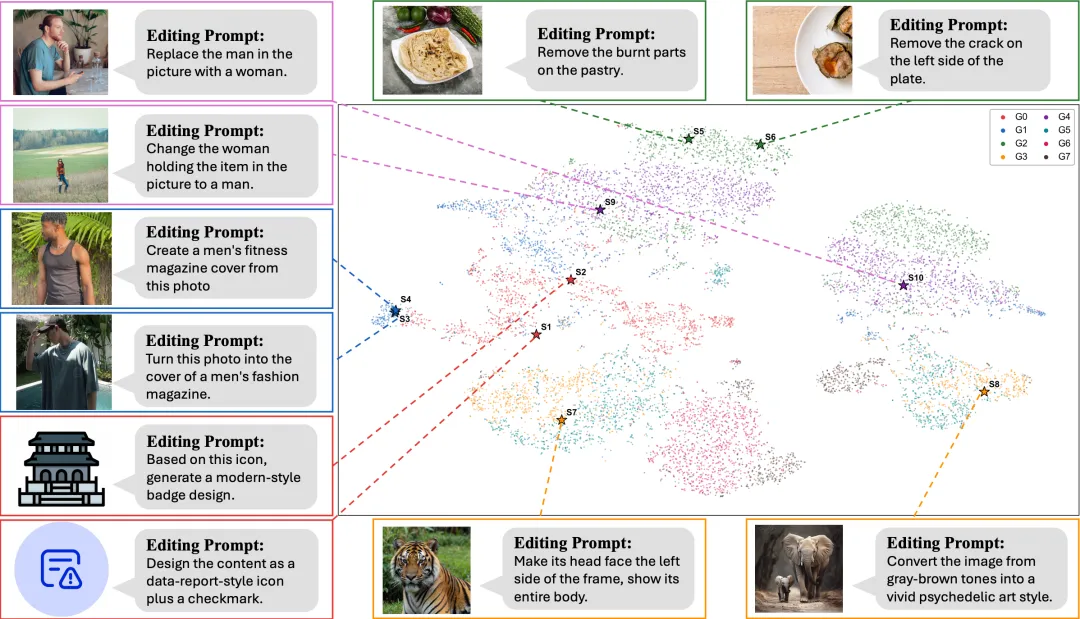
这种方法诱导出了一个结构化的“条件更新族”,生成的参数在权重空间中呈现出有语义的几何结构——功能相似的操作(如风格迁移)会自动聚集在邻近区域。这种特性让系统在面对冲突任务时,可以通过路由到不同区域来化解干涉,无需进行性能妥协。在工程部署上,也无需存储海量的静态LoRA权重,实现了极致的存储轻量化。
评测数据印证技术实力
研究人员将HY-WU应用于一个800亿参数的原生多模态基座模型HY-Image-3.0-Instruct,并引入了一个81.1亿参数的Transformer参数生成器,能为所有线性模块生成7.2亿参数的16秩LoRA权重。
在实际的个性化场景中,如虚拟试穿、高保真换脸等,HY-WU展现出了惊人的特征一致性和细节保留能力。






在严苛的评测中,研究团队构建了涵盖单图/多图、60个子任务、中英双语指令的测试集,并对标了包括OpenAI GPT-Image-1.5、Google Nano Banana Pro在内的顶尖模型。
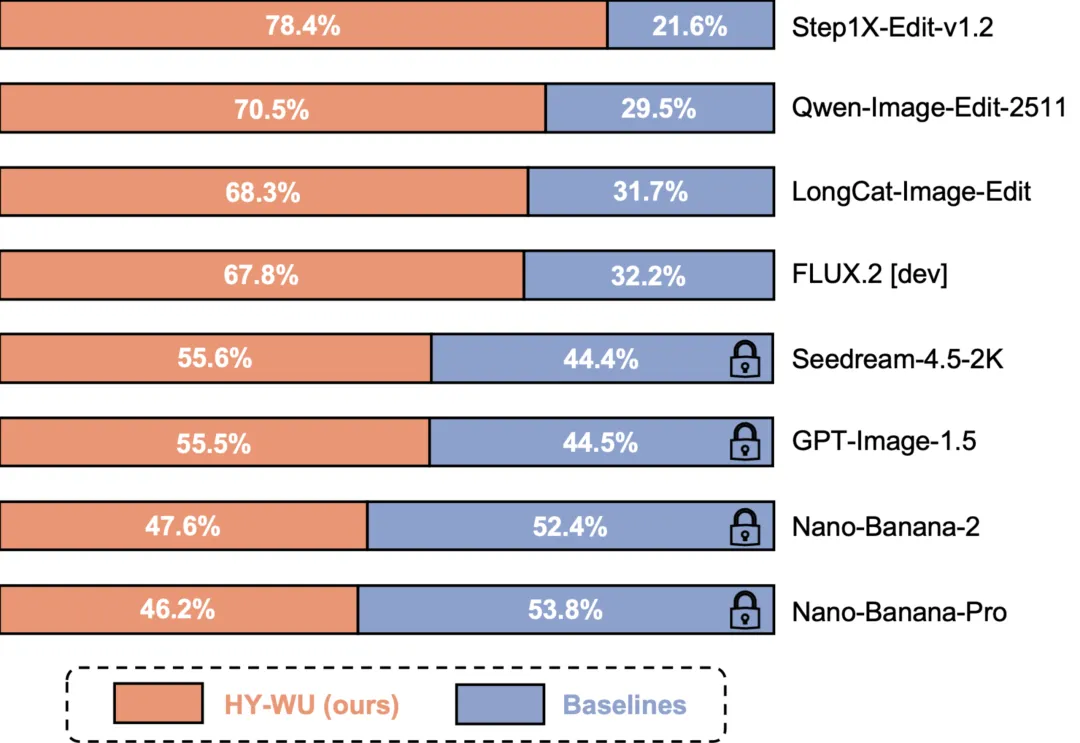
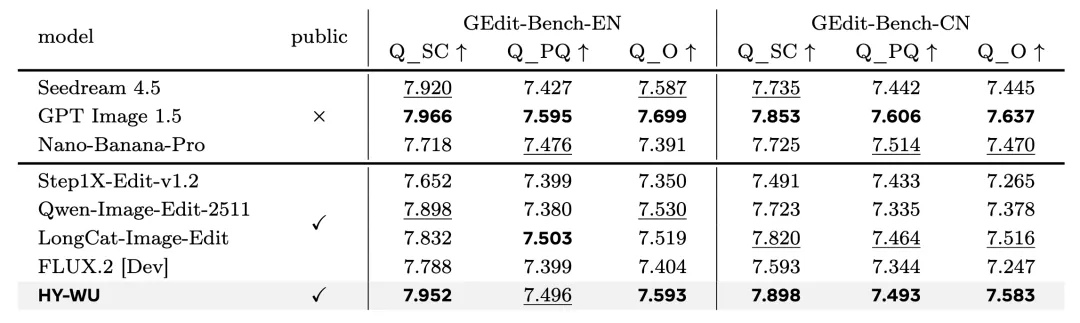
在代表用户真实感知的人类评价中,HY-WU显著优于所有主流开源模型。在自动化评测榜单GEdit-Bench上,其多项核心指标在开源模型中排名第一,甚至部分超越了闭源模型。
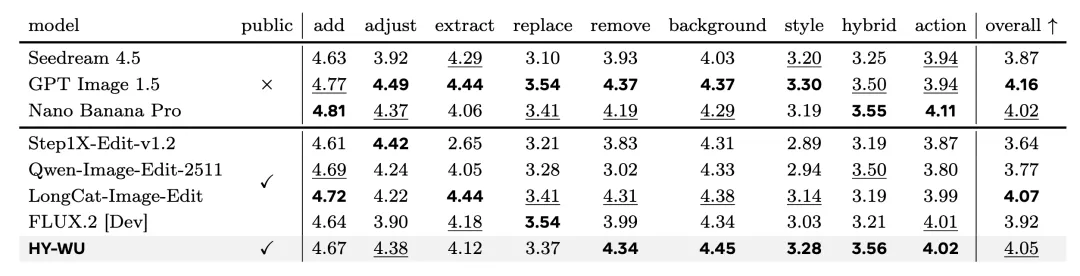
在ImgEdit-Bench的9项细分编辑任务中,HY-WU在开源模型中夺得了5项第一,总分在所有公开模型中排名第二,与闭源标杆GPT Image 1.5的差距微乎其微。
智能架构走向功能模块化
腾讯混元的这项探索,其意义远超图像编辑领域本身。它描绘了一幅以功能性神经记忆为核心的未来AI架构蓝图:检索记忆负责存储事实知识,功能记忆负责存储变换逻辑与算子,两者形成完美互补。
长远来看,功能记忆有望彻底解决在线持续学习的难题。新技能可以被安全地写入“更新族”的空白区域,而不会破坏旧有能力。这种将主干模型与功能记忆模块联合扩展的路径,比单纯堆砌单体模型参数更具计算与数据效率。
这种范式在跨模态领域潜力广阔:视频模型可为特定动作序列生成动态时序注意力算子;多模态交互任务可根据输入比例实时调节融合层权重;在长序列生成中,可专门生成“身份算子”来杜绝角色特征漂移。
当然,将计算压力从静态权重转移到动态参数生成,也对硬件推理侧提出了新挑战,例如动态权重导致的显存访问碎片化问题。开发定制化的算子融合技术、与高性能推理引擎深度结合,是推动该技术广泛落地的关键。当“千人千面”的实时个性化适配能在端侧设备流畅运行时,智能计算才真正融入日常。
把模型参数从静态束缚中完全释放,或许是通往更强、更灵活人工智能的必经之路。对这类前沿模型训练与推理技术感兴趣的开发者,可以持续关注云栈社区的相关讨论。
参考资料:
 发表于 2026-3-9 07:13:46
|
查看: 216|
回复: 0
发表于 2026-3-9 07:13:46
|
查看: 216|
回复: 0
