微软最近在官网正式开源了其最新的多模态视觉模型 Phi-4-Reasoning-Vision-15B(简称 Phi-4-Vision)。
该模型已在 HuggingFace 上开源,地址为:https://huggingface.co/microsoft/Phi-4-reasoning-vision-15B。
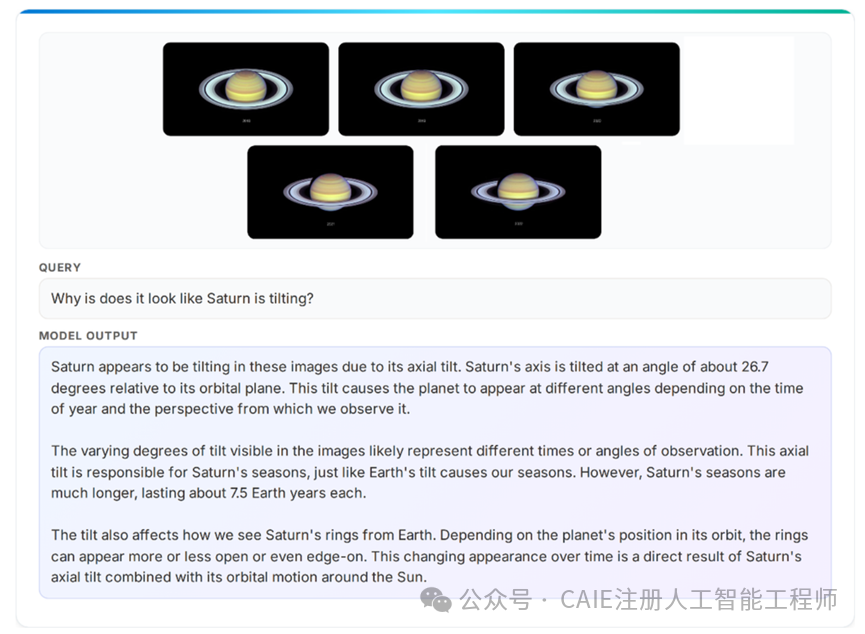
与传统的视觉语言模型不同,Phi-4-Vision 不仅能识别图像中的内容,更核心的是具备了深度的推理能力。传统的模型或许能告诉你图片里“有一只猫”,但 Phi-4-Vision 可以进一步思考“这只猫接下来可能做什么”,或者“如何操作当前的界面来完成一个任务”。这相当于为AI同时配备了“眼睛”和“思考的大脑”,使其从被动感知走向了主动理解与交互。
一个典型的例子是数据处理:过去,AI看到一张Excel表格截图,可能只能读出单元格里的数字。而 Phi-4-Vision 可以理解表格的结构,并根据指令(如“计算A产品的月度增长率”)定位数据、执行计算步骤,并输出结果和推理过程。这种“看得懂、想得通、算得出”的能力,是其最大的亮点。

从实用角度看,Phi-4-Vision 有两个设计非常友好:
- 推理功能可开关:用户可以根据任务需求,像调节音量一样开启或关闭深度推理模式。需要精准答案时开启,追求响应速度时关闭,实现了效率与精度的平衡。
- 专为视觉推理优化:其在图表数学题解答、PDF表格解析、屏幕界面理解等场景表现突出。无论是给一张图片提问,还是让AI看懂电脑屏幕并执行操作,它都能给出精准回应,避免了某些模型只能处理单一类型视觉内容的局限性。
在应用场景上,它尤其擅长两个方向:
- 科学与数学推理:面对复杂的几何图形或科学图表,它不仅能识别元素,还能一步步推导出解题过程或分析结论,是科研分析和教育辅导的潜在利器。
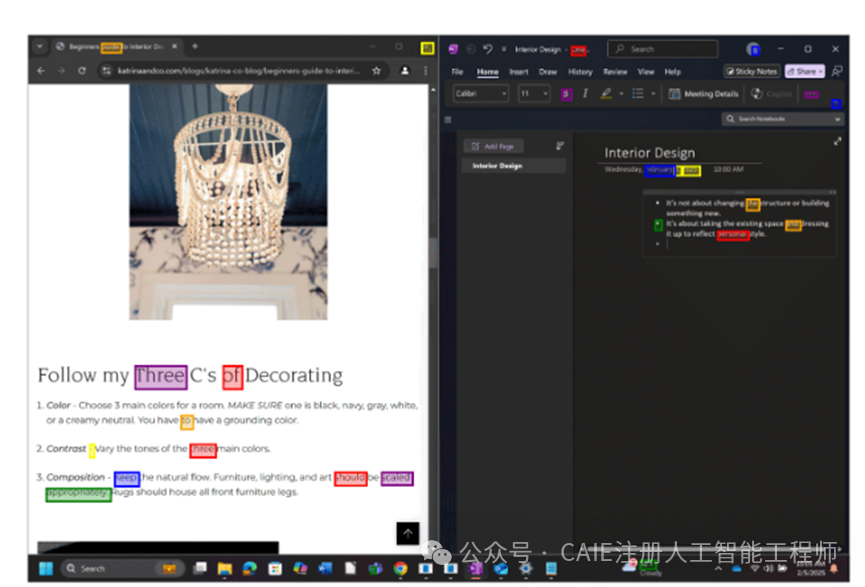
- 计算机使用AI智能体:这是当前非常热门的方向。
Phi-4-Vision 可以看作一个聪明的“数字员工”。例如,你让它“在电商网站上找到性价比最高的某商品”,它能理解屏幕上的价格信息、筛选按钮、促销标签,并自主决定点击哪些按钮来完成比价和购买操作。这种基于理解的自动化,才是真正智能体的模样。
在基准测试中,Phi-4-Vision 的成绩也相当亮眼。下面的对比表格清晰地展示了其与同类别其他模型在不同测试集上的表现:
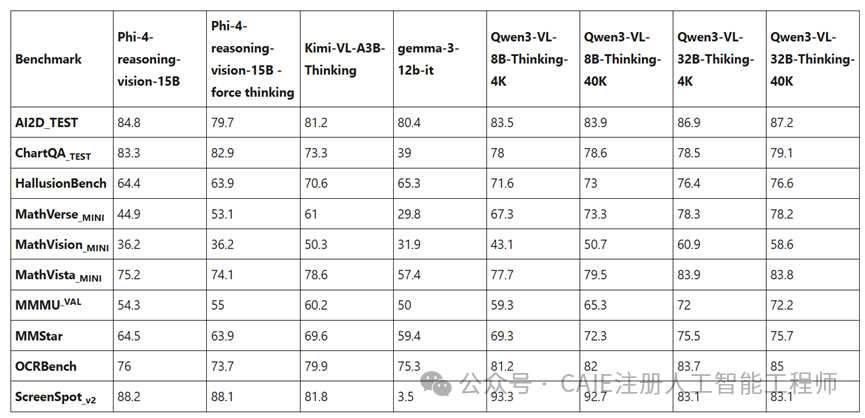
具体来看几个关键数据:
- 在测试科学图表理解的
AI2D_TEST 上,它获得了 84.8 分。作为对比,参数量大得多的 Qwen3-VL-32B 模型得分是87.2分,两者差距极小。
- 在专门测试模型理解手机或电脑屏幕界面能力的
ScreenSpot_v2 基准上,Phi-4-Vision 拿到了 88.2 的高分。这个能力直接决定了其能否成为一个合格的计算机操作智能体。相比之下,Gemma-3-12b 在该项仅得3.5分,差距悬殊。
- 在图表问答测试
ChartQA_TEST 上,它保持了 83.3 的高分,而开启了思考模式的 Kimi-VL-A3B-Thinking 得分为73.3分。这表明,Phi-4-Vision 在复杂图表逻辑推理上,并未因参数规模较小而性能打折。
综合来看,Phi-4-Vision 在同等参数规模的模型中表现突出,其“小身材、大能量”的特点(15B参数,高性能、低能耗)使其在 人工智能 特别是多模态与智能体应用领域极具吸引力。对于开发者而言,通过 开源实战 探索和微调这个模型,有望打造出更实用的自动化数字助手。
你对这种具备深度视觉推理能力的AI智能体有什么想象?欢迎到 云栈社区 的开发者板块分享你的看法和创意应用场景。 |  发表于 2026-3-8 07:02:45
|
查看: 144|
回复: 0
发表于 2026-3-8 07:02:45
|
查看: 144|
回复: 0
