想象一下,你只需要给计算机一段文字或一张图片,它就能在几分钟内为你生成一段电影质感的短片。这不再是科幻场景,而是AI视频生成技术正在带来的现实变革。过去,视频制作依赖于昂贵的设备和复杂的后期;而现在,AI正通过理解海量的物理规律,学习如何模拟光影、动作与时间的流动。阿里巴巴通义实验室推出的通义万相Wan系列,特别是其开源版本,正在成为这一领域的重要标杆。
本文将通过解析Wan系列的核心技术,带你了解让画面“动起来”背后的四大支柱:架构支撑、数据压缩、分工效率与精准控制。我们将详细探讨从Wan 2.1到Wan 2.6的关键迭代,以及各子版本如何从不同维度推动视频生成技术的边界。
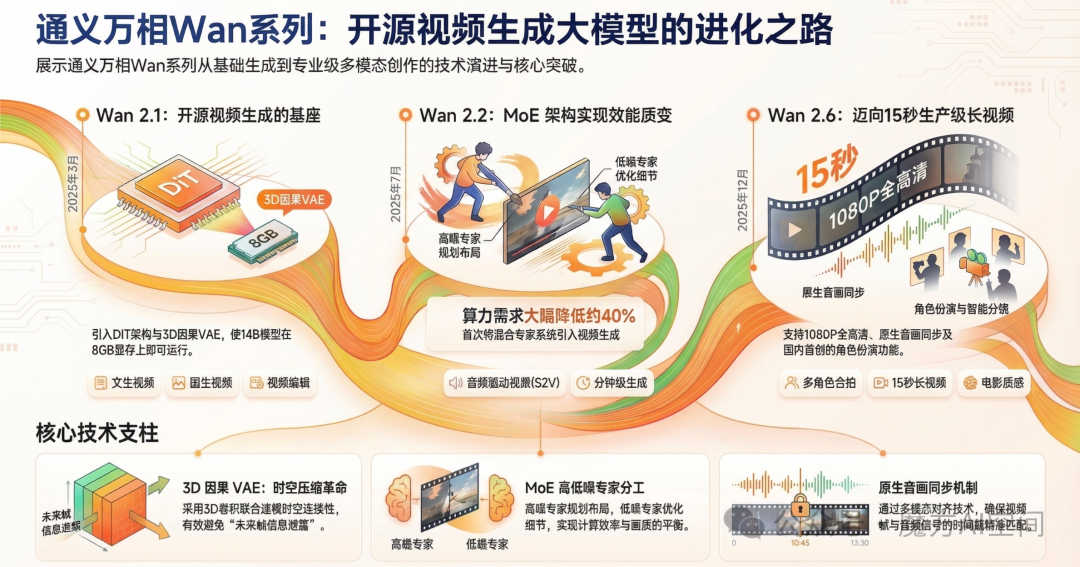
核心洞察:通义万相系列的发展路线存在一个清晰的战略转折。Wan 2.1与2.2作为开源基座,旨在降低技术门槛,构建全球开发者生态;而后续的Wan 2.5与2.6则转向了非开源的生产级应用模型,侧重于提供1080p全高清画质与原生音画同步的一键式解决方案。
一、Wan系列发展脉络:从基础生成到多模态创作
Wan系列自2025年初发布以来,经历了数次重大版本迭代,每次升级都带来了显著的技术突破和功能扩展。从最初的文生视频(T2V)、图生视频(I2V)基础功能,逐步发展为支持多模态输入、音画同步、角色扮演和智能分镜的完整解决方案。
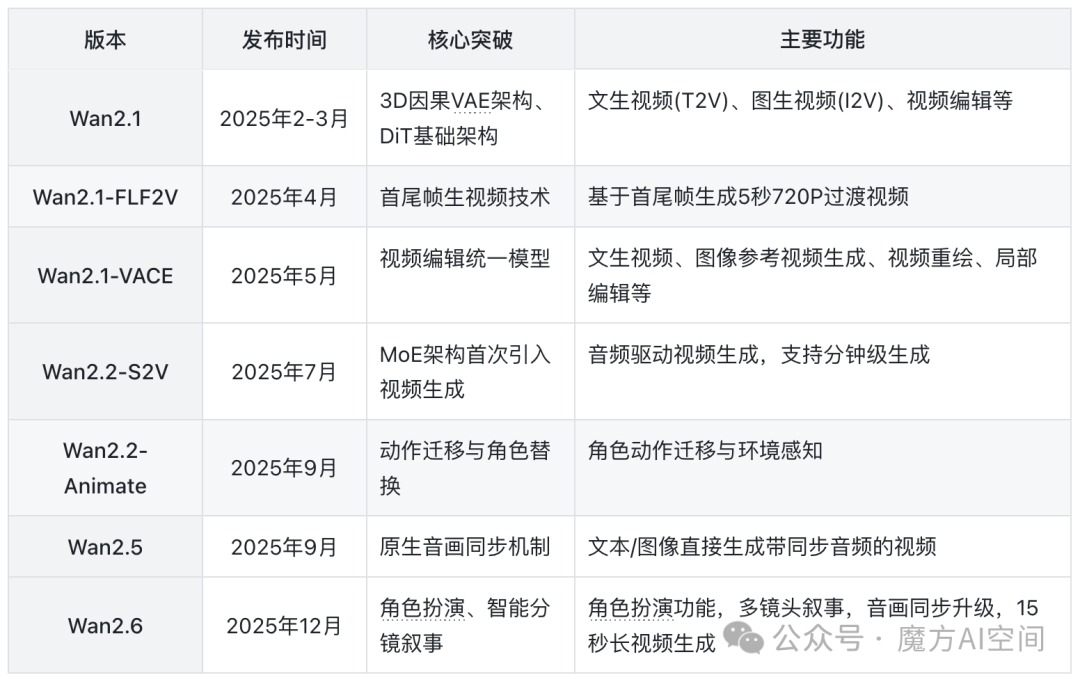
其技术演进遵循了一条清晰的路径:基础生成能力 → 多模态控制 → 音画同步 → 角色扮演与长视频生成。这一系列的开源实践为整个AIGC领域提供了宝贵的参考。
二、关键技术突破与创新分析
2.1 Wan2.1:3D因果VAE——时空压缩的革命性突破
《Wan: Open and Advanced Large-Scale Video Generative Models》[1]
论文地址:https://arxiv.org/abs/2503.20314
GitHub:https://github.com/Wan-Video/Wan2.1.git
3D因果VAE是Wan系列的基础架构创新,它解决了传统视频生成模型在显存占用和长视频生成方面的核心瓶颈。该架构采用3D卷积网络替代传统2D卷积,实现了对视频时空连续性的联合建模。
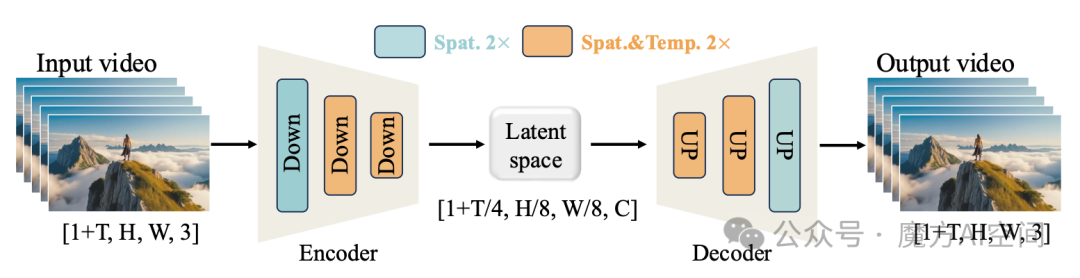
Wan-VAE框架。通过4×8×8倍压缩视频的时空维度。橙色矩形表示2×时空压缩,绿色矩形表示2×空间压缩。
在具体实现上,Wan2.1的3D因果VAE包含三个关键设计:
- 因果掩码机制:通过限制3D卷积的感受野,确保生成过程仅依赖于当前帧和之前帧的信息,避免了“未来帧信息泄露”问题,从而保证了生成视频的时序一致性。
- 多尺度特征融合:编码器采用金字塔结构,从不同空间尺度提取特征,并通过跨层连接整合多尺度信息,增强了模型对细节和全局结构的理解。
- 特征缓存优化:针对长视频生成,实现了特征缓存机制,将中间特征表示存储在磁盘而非显存中,从而支持更长的1080P视频处理。这一技术使14B参数的模型在480P分辨率下仅需约8.2GB显存即可运行。
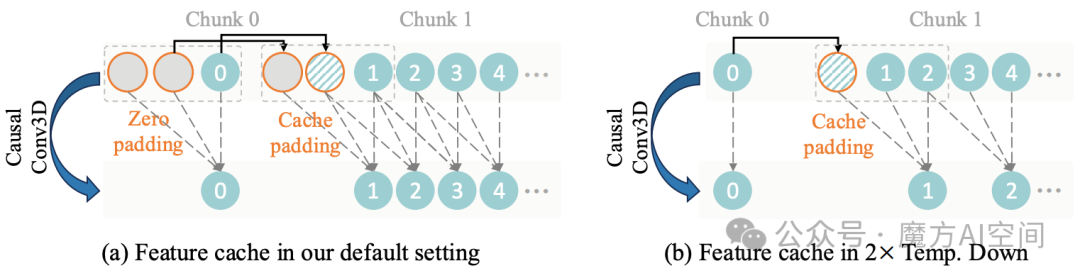
实验数据显示,3D因果VAE相比传统视频VAE架构,减少了约60%的显存占用,同时保持了相近的生成质量,为后续更大规模模型的开发铺平了道路。
2.2 Wan2.2:MoE混合专家系统——计算效率的质变提升
技术报告:https://tongyi.aliyun.com/wan/blog/wan2.2
Github:https://github.com/Wan-Video/Wan2.2.git
Wan2.2引入的混合专家(MoE)架构是视频生成领域的重大突破,它实现了模型容量与计算成本的有效平衡。MoE架构将视频生成任务分解,由不同的专家模型并行处理,显著提升了计算效率。
Wan2.2的MoE系统主要包含以下创新点:
- 高噪与低噪专家分工:模型将视频生成分为两个阶段:高噪专家负责早期阶段的整体布局规划和大尺度运动控制;低噪专家负责后期阶段的细节优化和精确特征还原。
- 动态路由机制:根据输入视频的上下文信息(如场景类型、运动复杂度)自动选择最合适的专家组合。
- 多尺度特征融合:高噪专家在低分辨率下快速生成粗略画面,低噪专家在高分辨率下精细化处理,避免了直接生成高分辨率视频时的计算负担。

这一架构创新带来了显著的效率提升:Wan2.2在生成1080P视频时,算力需求比传统单一模型降低约40%。5B参数的版本可在RTX 4090等消费级显卡上流畅运行,大大降低了视频生成的硬件门槛。
2.3 Wan2.5:原生音画同步机制——多模态融合的里程碑
项目主页:https://wan2-5.com/
Wan2.5的原生音画同步机制实现了视频生成从单一视觉模态到多模态协同的跨越,是技术演进中的重要里程碑。
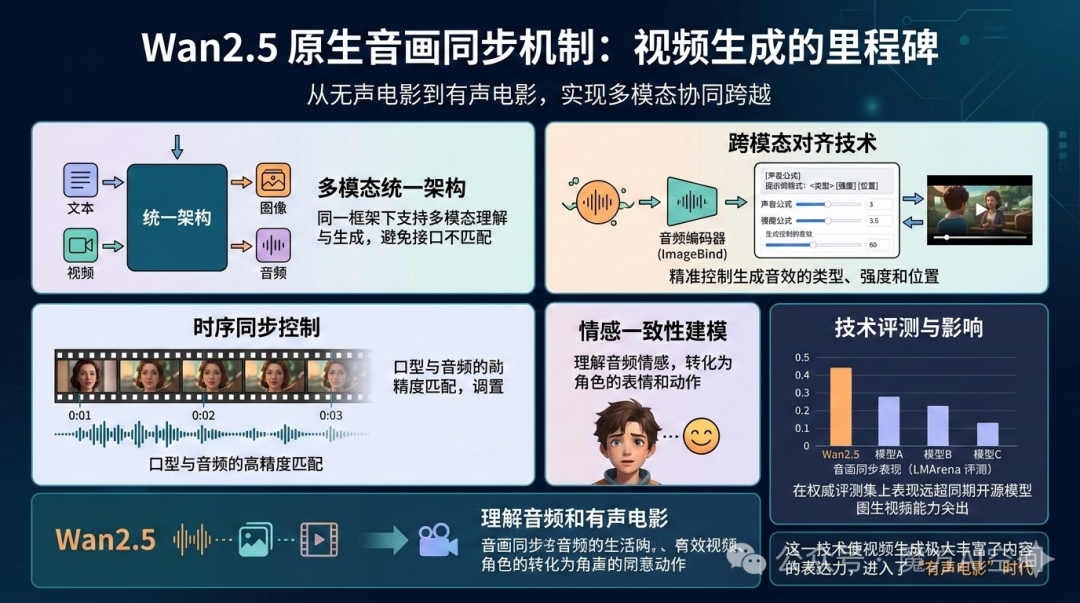
其核心技术包括:
- 多模态统一架构:在同一框架下支持文本、图像、视频和音频的理解与生成,避免了传统多模态系统间的接口不匹配问题。
- 跨模态对齐技术:通过冻结的音频编码器提取分段音频特征,并与视频生成器联合优化,实现音画内容的精确对齐。
- 时序同步控制:引入时序同步控制模块,精确对齐音频信号时间戳与视频帧的生成,确保口型与音频的高精度匹配。
- 情感一致性建模:模型能够理解音频中的情感信息,并将其转化为视频中角色的表情和动作。
技术评测表明,Wan2.5在权威评测集上的音画同步表现远超同期其他开源模型,使视频生成从“无声电影”迈入了“有声电影”时代。
2.4 Wan2.6:角色扮演与智能分镜的突破性创新
项目介绍:https://wan2-5.com/wan-2-6
参考:https://baike.baidu.com/item/%E4%B8%87%E7%9B%B82.6/67189452
作为国内首个支持角色扮演功能的视频模型,Wan2.6在2025年12月发布,实现了多项技术突破。
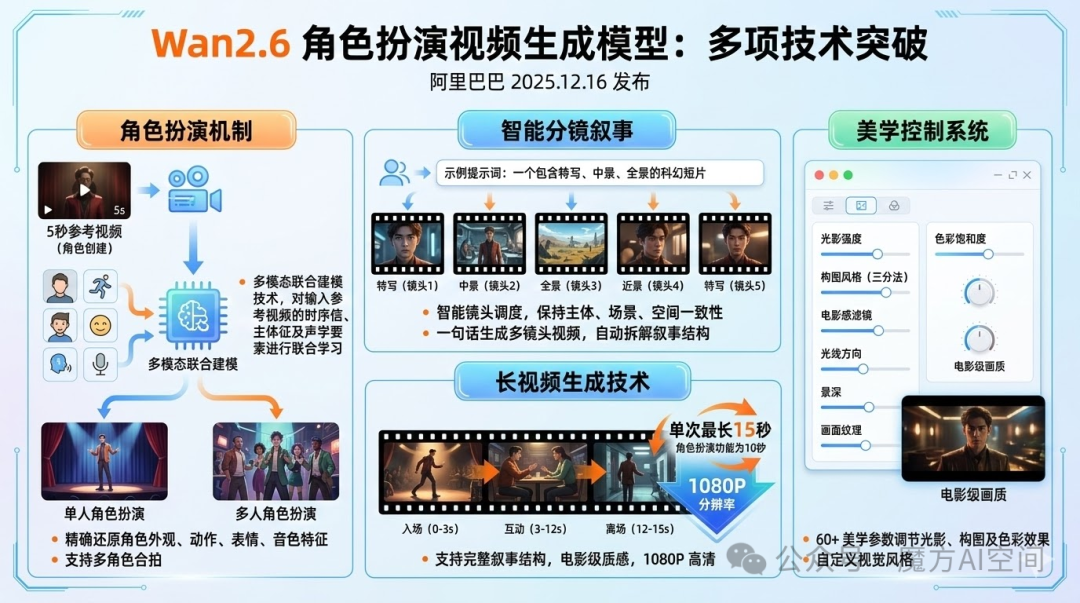
其核心能力包括:
- 角色扮演机制:通过多模态联合建模技术,对输入参考视频的时序信息、主体特征及声学要素进行联合学习,实现从外观、动作、表情到音色的高精度还原,支持单人或多人合拍。
- 智能分镜叙事:支持通过自然语言指令实现智能镜头调度,可自动将一句话拆解为包含特写、中景、全景等多镜头的连贯叙事,并保持主体、场景的一致性。
- 长视频生成技术:单次生成视频时长提升至15秒,分辨率可达1080P,支持更完整的叙事结构。
- 美学控制系统:提供60余项参数调节光影、构图及色彩效果,赋予生成视频电影级质感。
三、子版本功能详解:从基础生成到专业创作
Wan系列通过多个专业子版本,实现了对不同应用场景的精准覆盖,形成了完整的产品矩阵。这些开源实战项目为开发者提供了丰富的选择。
3.1 Wan2.1-FLF2V:首尾帧生成的创新应用
项目介绍:https://tongyi.aliyun.com/wan/blog/wan2.1-flf2v
Wan2.1-FLF2V是全球首个开源的百亿级首尾帧生视频模型。它基于DiT架构,通过首尾帧图像作为控制条件,自动生成时长5秒、分辨率720P的自然过渡视频。
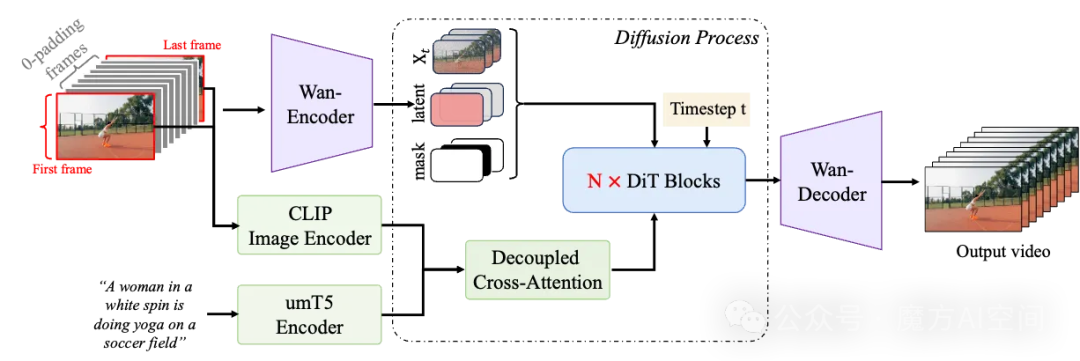
其关键技术包括:
- 条件控制分支:将首尾帧与零填充中间帧拼接为控制序列,结合噪声和掩码作为DiT输入。
- 交叉注意力机制:提取首尾帧CLIP特征并通过交叉注意力注入生成过程,保持语义一致性。
- 三阶段训练策略:从基础视觉认知构建,到专项动态过渡能力优化,再到高清精细化调优。
3.2 Wan2.1-VACE:全能视频编辑的统一模型
Github地址:https://github.com/ali-vilab/VACE
论文地址:https://arxiv.org/abs/2503.07598
Wan2.1-VACE是业界功能较全的视频生成与编辑统一模型,通过单一框架实现了文生视频、图像参考视频生成、视频重绘、局部编辑等八大能力。
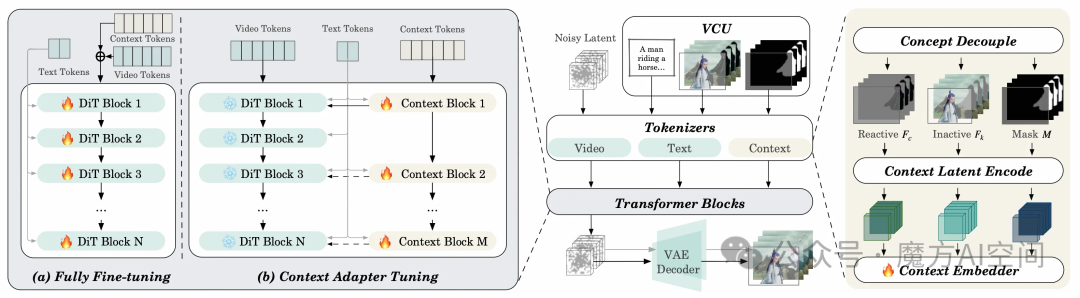
其核心模块视频条件单元(VCU)负责处理视频输入的时空依赖关系。模型支持多模态输入融合,并采用FFGo多对象融合技术,支持最多5个参考实体的组合生成。
3.3 Wan2.2-S2V:音频驱动视频生成的专业解决方案
论文地址:https://arxiv.org/abs/2508.18621
项目介绍:https://tongyi.aliyun.com/wan/blog/wan2.2-S2V
Wan2.2-S2V是一个多模态视频生成模型,通过单张静态图片结合音频输入,可生成具有自然面部表情、精准口型同步及流畅肢体动作的数字人视频。
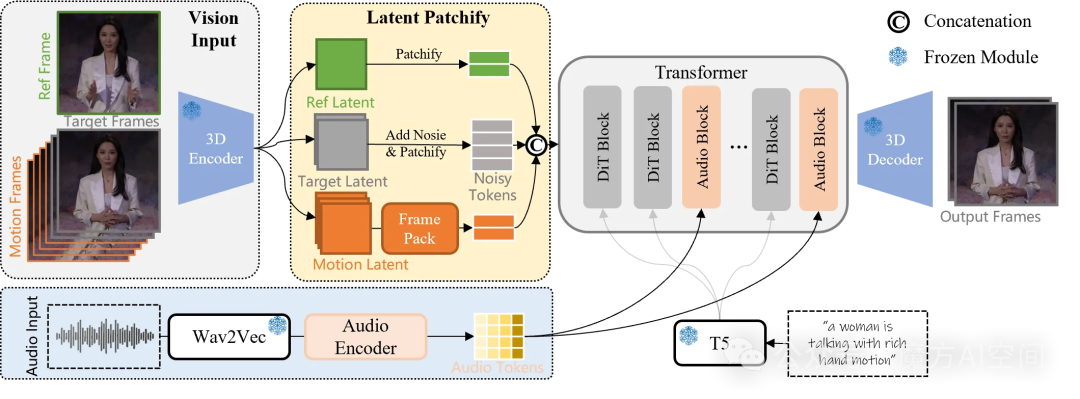
其创新点在于引入了AdaIN与CrossAttention控制机制,并采用层次化帧压缩技术,将历史参考帧长度大幅拓展,从而支持更稳定的分钟级长视频生成效果。
3.4 Wan2.2-Animate:角色动作迁移的精准控制
论文地址:https://arxiv.org/abs/2509.14055
项目介绍:https://tongyi.aliyun.com/wan/blog/wan2.2-animate
Wan2.2-Animate是一个动作生成模型,支持动作模仿和角色替换。它能基于表演者的视频,精确复制其面部表情和动作,生成高度逼真的角色动画视频。
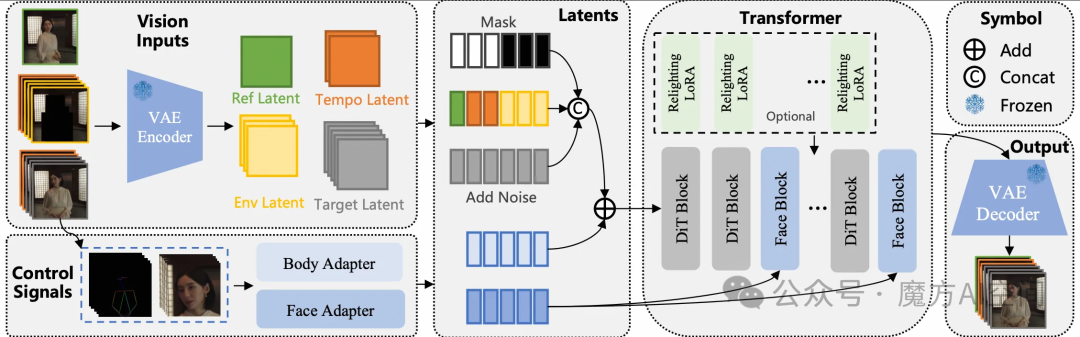
模型通过修改输入范式来适应动画任务,并采用两种控制信号:
- 骨骼信号控制:使用空间对齐的骨骼信号精确控制角色的肢体运动。
- 隐式面部特征控制:从源图像中提取隐式特征来重现细微的表情变化。
此外,还开发了Relighting LoRA模块,实现角色与新环境的光照和色调无缝融合。
四、性能优化与部署策略
Wan系列不仅在架构上创新,在模型优化和部署上也做了大量工作,实现了从专业级到消费级的跨越。
4.1 模型压缩与轻量化技术
通过多种技术,Wan系列在保持质量的前提下大幅降低了计算需求:
- 参数共享机制:在MoE架构中,同一专家可被多个任务共享,避免冗余。
- 知识蒸馏:从大模型向小模型蒸馏关键知识,减少参数规模。
- 量化技术:采用混合精度训练和量化,减少内存占用和计算量。
这使得1.3B参数模型可在RTX 3060等消费级显卡运行,而14B/27B参数模型则为专业创作提供支持。
4.2 推理优化与加速技术
推理优化显著提升了生成速度并降低了硬件要求:
- 时空注意力优化:通过稀疏注意力、局部窗口注意力等技术降低计算复杂度。
- 并行生成技术:支持视频帧并行生成,摆脱逐帧限制。
- 硬件适配优化:针对不同GPU架构进行专门优化。
- 推理框架集成:提供了与ComfyUI等流行框架的集成。
例如,Wan2.2-T2V-A5B模型在RTX 4090上可在5-8秒内生成一段3秒左右的视频。
4.3 开源生态与开发者支持
繁荣的开源生态是Wan系列成功的关键:
- 全平台开源:代码与权重在GitHub、Hugging Face等平台采用Apache 2.0协议开源。
- 文档与教程:提供了详细的技术文档、使用教程和示例代码,降低上手门槛。
- 社区建设:与开发者社区合作举办活动,促进交流。
- API与云服务:在阿里云百炼平台提供企业级API服务,同时保持开源社区活力。
写在最后
通义万相Wan系列代表了AI视频生成技术的前沿水平。通过持续的技术创新和开放的开源策略,该系列已从基础生成功能,发展成为支持多模态输入、音画同步、角色扮演等全方位创作能力的解决方案。
从Wan2.1到Wan2.6,该系列不断突破边界,实现了从专业级到消费级的跨越,为内容创作、影视制作、广告营销等多个领域带来了变革。对于开发者和技术爱好者而言,深入研究其开源实战代码与架构设计,无疑是理解当前视频生成技术脉络的绝佳途径。想了解更多AIGC前沿技术解读与实战分享,欢迎访问云栈社区,与广大开发者一同交流成长。
参考
[1] Wan: Open and Advanced Large-Scale Video Generative Models: https://arxiv.org/abs/2503.20314
[2] Wan2.2: https://tongyi.aliyun.com/wan/blog/wan2.2
[3] Wan2.5: https://wan2-5.com/
[4] Wan2.6: https://wan2-5.com/wan-2-6
[5] Wan2.1-FLF2V: https://tongyi.aliyun.com/wan/blog/wan2.1-flf2v
[6] Wan2.1-VACE: https://arxiv.org/abs/2503.07598
[7] Wan2.2-S2V: https://arxiv.org/abs/2508.18621
[8] Wan2.2-Animate: https://arxiv.org/abs/2509.14055
 发表于 2026-3-12 06:08:42
|
查看: 196|
回复: 0
发表于 2026-3-12 06:08:42
|
查看: 196|
回复: 0
