
摘要
检索增强生成(RAG)通过从外部知识库获取信息来增强大语言模型的生成能力,这已是当前AI应用的一个主流范式。但传统RAG有个明显的短板:它主要处理文本,对于文档中常见的图像、图表等多模态信息往往“视而不见”。
多模态RAG(MRAG)试图解决这个问题,常见做法是将图像和文本映射到同一个向量空间进行相似度检索。但这带来了新问题:首先,这种方法抓不住知识内在的结构和不同模态间的逻辑链条;其次,它通常需要针对特定任务进行大量训练,泛化能力有限,容易导致模型“自信地”生成错误答案。
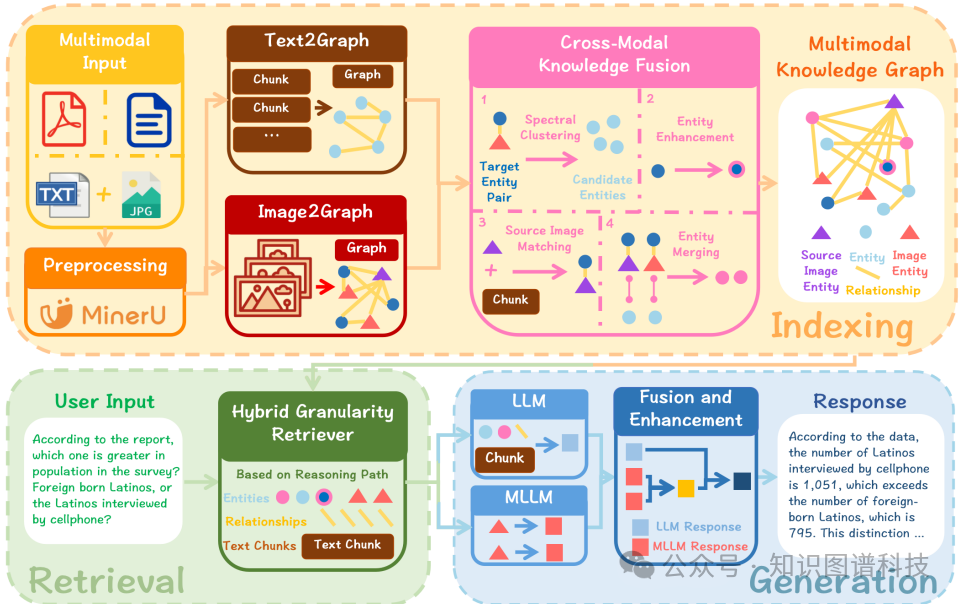
为此,研究者提出了 MMGraphRAG。这个框架的思路很巧妙:它先利用场景图技术对视觉内容进行精细化解析,再将其与基于文本构建的知识图谱(KG)融合,形成一个统一的多模态知识图谱(MMKG)。其中,它采用谱聚类算法实现跨模态的实体链接,并沿着知识图谱中的推理路径进行检索,从而引导生成过程。实验表明,MMGraphRAG在DocBench和MMLongBench等多个基准测试上都达到了先进水平,不仅表现出强大的领域适应性,还能提供清晰的推理路径,大大提升了结果的可解释性。
这项工作的主要贡献可以总结为三点:
- 提出了首个多模态GraphRAG框架:MMGraphRAG创新地将图像细化为场景图,并与文本知识图谱结合,构建出统一的多模态知识图谱,专门用于支撑复杂的跨模态推理任务。
- 发布了中英文实体对齐数据集(CMEL):为了解决该领域缺乏基准测试的问题,研究团队构建并开源了CMEL数据集,专门用于评估视觉与文本实体之间的对齐效果。
- 设计了基于谱聚类的CMEL方法:该方法通过整合实体的语义和结构信息,高效生成高质量的候选实体对,显著提升了跨模态实体链接任务的准确性。
核心速览
研究背景
-
研究问题:这篇文章要解决的核心问题是传统RAG方法在处理多模态信息时的先天不足。现有的多模态RAG方法虽然能把图文映射到同一空间,但无法捕捉模态间的结构化知识和深层逻辑关系,并且严重依赖特定领域的大规模训练,导致其泛化能力成为瓶颈。
-
研究难点:该问题的难点突出体现在几个方面:如何深度融合图文信息以捕捉其间的结构和逻辑链?如何在不进行海量任务定制训练的前提下提升模型泛化能力?以及,如何在多模态推理过程中提供令人信服的可解释路径?
-
相关工作:围绕这一问题,业界已有一些探索。例如,GraphRAG系列方法通过构建实体知识图和社区摘要来提升RAG的推理能力;HM-RAG提出了一个分层多代理框架,但仍主要依赖将多模态内容转为文本;传统实体链接(EL)方法尝试引入视觉信息作为辅助属性;而CMEL方法则更进一步,将视觉内容本身视为实体,与文本实体进行对齐,从而构建多模态知识图(MMKG)。
研究方法
这篇论文提出的MMGraphRAG,其设计目标直指上述多模态RAG的痛点。整个框架的运作可以分解为以下几个关键步骤:
-
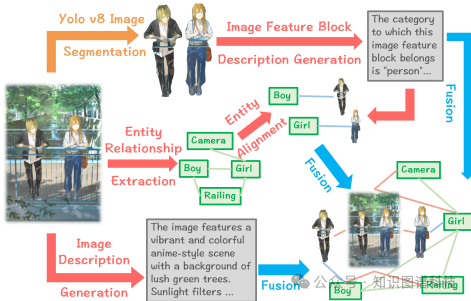
图像到图的转换:首先,系统需要对图像进行深度理解。它利用YOLO等模型对输入图像进行语义分割,将其划分成多个语义独立的“图像特征块”。随后,调用大语言模型(LLM)为每个特征块生成详细的文本描述。紧接着,从图像中提取实体及其关系,并将分割出的特征块与提取的实体进行精准对齐。最后,构建一个能描述整张图像的“全局实体”,并将其与各个“局部实体”连接起来,形成一个初步的图像场景图。
-
跨模态融合:这是MMGraphRAG的核心。系统需要将上一步得到的图像场景图与从文本中构建的知识图谱融合。为此,它设计了一个基于谱聚类的跨模态实体链接(CMEL)流程:
- 算法重新设计了加权邻接矩阵A和度矩阵D,以同时捕捉实体间的语义相似性和图结构信息。
- 通过标准的谱聚类流程(构建拉普拉斯矩阵、特征分解等)形成特征矩阵,并使用DBSCAN进行聚类。
- 对于每个图像实体,选择与其嵌入向量最相关的簇作为候选实体集。
- 最终,利用LLM的推理能力对候选实体进行对齐,确保它们在最终的多模态知识图谱(MMKG)中具有统一的表示。
-
增强与对齐:对于未能在CMEL过程中对齐的剩余图像实体,系统会通过整合原始文本中的相关信息来增强其描述,以提升知识图谱的完整性。同时,每个图像的“全局实体”也会与相关的文本实体进行对齐,如果找不到直接匹配,则在文本知识图谱中创建一个新节点来表示图像的整体语义。
-
实体融合:最后,对所有已经对齐的实体进行语义层面的融合,确保它们在MMKG中有一致、连贯的表示,从而为下游的推理和检索任务打下坚实基础。
实验设计
为了验证MMGraphRAG的有效性,研究团队进行了严谨的实验设计:
-
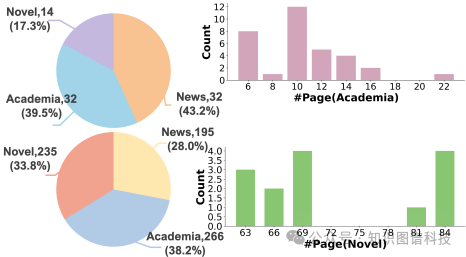
数据集:他们专门构建了CMEL数据集,包含新闻、学术和小说三个领域的文档,确保了领域的多样性。该数据集共包含1114个对齐实例,为评估跨模态实体链接提供了可靠的基准。
-
实验设置:在多模态文档问答(DocQA)任务上,选用了DocBench和MMLongBench两个权威基准。DocBench包含229个PDF,涵盖学术、金融等五个领域;MMLongBench则包含135个长文档,来自研究、教程等七个不同领域,对模型处理长上下文和多模态信息的能力提出了更高要求。
-
评估指标:采用了微观准确率(按实体计算)和宏观准确率(按文档计算)双指标进行评估。宏观准确率能有效减轻因文档间实体分布不均带来的评估偏差。
结果与分析
实验数据有力地支撑了MMGraphRAG的设计:
-
CMEL实验结果:MMGraphRAG采用的谱聚类方法在CMEL任务上显著优于传统的基于嵌入或纯LLM的方法,微观准确率提升约15%,宏观准确率提升约30%。
-
多模态文档问答结果:在DocBench数据集上,MMGraphRAG在文本和多模态问题上的表现均全面超越GraphRAG。在更复杂的MMLongBench数据集上,MMGraphRAG在准确率和F1分数上也显著领先,尤其在涉及图表、图形的查询中优势明显。
-
跨领域适应性:与所有纯文本RAG方法相比,MMGraphRAG在视觉结构复杂度高的领域(如学术、金融)表现出了显著的性能增益,这说明它不仅能处理通用问题,在专业领域也具备强大的适应能力。
-
与先进MRAG方法的对比:与同期优秀的MRAG方法M3DOCRAG相比,MMGraphRAG在多模态信息理解上优势突出。在涉及图表等视觉内容的查询中,MMGraphRAG准确率达到48.2,远超M3DOCRAG的39.0。
总体结论
总而言之,MMGraphRAG作为一个基于知识图谱的多模态RAG框架,通过构建细粒度的图像场景图并实现深度的跨模态融合,有效地解决了传统方法的痛点。实验证明,它在多项任务中显著优于现有方法,不仅在性能上领先,还兼具强大的领域适应性和可解释的推理路径。这项研究为知识图谱与多模态大模型的结合指明了新的方向,即通过结构化的知识来引导和增强多模态理解与推理。
论文评价
优点与创新
- 框架首创性:首次提出了将GraphRAG思想系统性地扩展到多模态领域,构建统一的MMKG,为跨模态推理提供了新范式。
- 基准贡献:构建并开源CMEL数据集,填补了该领域基准测试的空白,对后续研究极具价值。
- 方法有效性:基于谱聚类的CMEL方法巧妙地融合了语义与结构信息,显著提升了对齐精度。
- 性能卓越:在多个数据集上达到SOTA,特别是在处理视觉密集型查询时表现远超同类方法。
- 可解释性强:基于知识图谱的检索提供了清晰的推理路径,增强了结果的可信度。
- 泛化能力好:无需大规模任务特定训练,即在多个领域展现出良好的适应性和鲁棒性。
不足与反思
当然,论文也提到了当前方案的局限性。例如,在处理超大规模数据集或某些极端特定的任务时,可能仍需进一步的优化。未来的工作可以沿着几个方向深入:探索更高效的跨模态实体链接算法,尝试将框架扩展到视频、3D模型等其他模态,以及研究如何动态更新和维护多模态知识图谱。
关键问题及回答
问题一:MMGraphRAG在图像到图的转换中,具体如何利用LLM?
这个过程是精细化的流水线:
- 语义分割:使用YOLO模型将输入图像切割成多个独立的“图像特征块”。
- 文本描述生成:针对每个特征块,调用LLM生成一段文字描述,这为后续的跨模态对齐建立了语义桥梁。
- 实体关系提取:从图像整体及描述中,提取出实体以及它们之间的关系。
- 特征块与实体对齐:将第一步分割出的每个区域,与第三步提取出的实体进行匹配和关联。
- 全局实体构建:创建一个能代表整张图像核心语义的“全局实体”,并将其与各个“局部实体”连接起来,形成完整的图像场景图。
通过这五步,图像从像素矩阵转化为了富含语义和结构信息的图表示。
问题二:MMGraphRAG的谱聚类算法如何工作以生成候选实体对?
这是跨模态融合的关键技术:
- 矩阵设计:算法首先构建一个加权邻接矩阵A,其中的权重同时反映实体间的语义相似度和在图结构中的关系紧密度。同时计算度矩阵D。
- 聚类过程:基于A和D构建拉普拉斯矩阵,进行特征值分解,得到降维后的特征表示,然后使用DBSCAN算法对这些特征进行聚类。DBSCAN能很好地发现任意形状的簇并处理噪声。
- 候选集生成:对于每一个图像实体,计算其向量表示与各个聚类中心的相似度,选择最相关的那个簇,该簇内的所有文本实体就构成了它的候选实体集。
- 精炼对齐:最后,再利用LLM对候选集进行精挑细选和最终对齐,确保融合的准确性。
问题三:MMGraphRAG在实验中表现优异的核心原因是什么?
其成功可归结为以下几个设计优势:
- 结构化知识表示:通过构建细粒度的图像场景图和MMKG,系统能进行基于关系的精确检索,而非简单的向量相似度匹配,这对理解复杂视觉查询至关重要。
- 深度跨模态推理:MMKG天然支持沿着实体和关系的路径进行推理,使得模型能综合图文信息进行深层逻辑判断。
- 领域鲁棒性:基于图谱的方法对领域特定词汇和结构有更好的包容性,因此在学术、金融等专业领域表现更稳定。
- 路径可解释性:整个检索和推理过程基于图谱路径,这使得答案的生成过程变得透明、可追溯,极大地增强了可信度。
- 针对性的优化:相比传统MRAG,MMGraphRAG专门优化了对图表、图形等结构化视觉内容的处理能力,因此在相关任务上优势显著。
|  发表于 2026-3-12 06:05:57
|
查看: 162|
回复: 0
发表于 2026-3-12 06:05:57
|
查看: 162|
回复: 0
