摘要
本文提出的 VaLiK 框架,通过视觉-语言对齐技术,构建了一个无需人工标注的多模态知识图谱,旨在解决大语言模型在多模态推理中常见的知识不完整和幻觉问题。该方案不仅存储高效,而且在性能上表现领先。
一、研究背景:多模态推理的困境
近年来,大语言模型(LLMs)在自然语言推理任务中展现出卓越的性能。为了将 LLMs 的能力拓展到多模态领域,研究人员开发了多模态大语言模型(MLLMs),例如 BLIP-2、GPT-4o 和 Janus-Pro。
然而,这些模型在迈向真正“理解”世界的道路上,却始终面临两个核心难题。
1.1 知识缺陷导致的幻觉现象
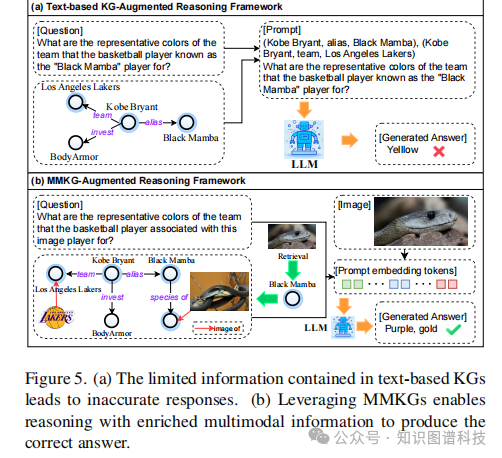
尽管 MLLMs 取得了显著进展,但它们经常会出现令人头疼的“幻觉”问题。这通常源于模型内部知识的不完整或过时。虽然通过微调 LLMs 可以更新知识,但计算成本极高。文本知识图谱(KGs)通过实时高效的信息更新,部分解决了这一问题,但由于其固有的“模态隔离”特性,它们无法有效支持需要结合视觉信息的跨模态推理。
1.2 传统多模态知识图谱构建的局限
多模态知识图谱(MMKGs)作为一种统一的表示框架被提出,旨在弥合不同模态间的语义碎片。但构建高质量 MMKGs 本身,就面临两大主要障碍:
(1)依赖大规模人工标注
如图1(a)所示,训练实体抽取模型需要海量、细粒度的人工标注数据集,这大幅推高了标注成本,严重制约了方案的扩展性。
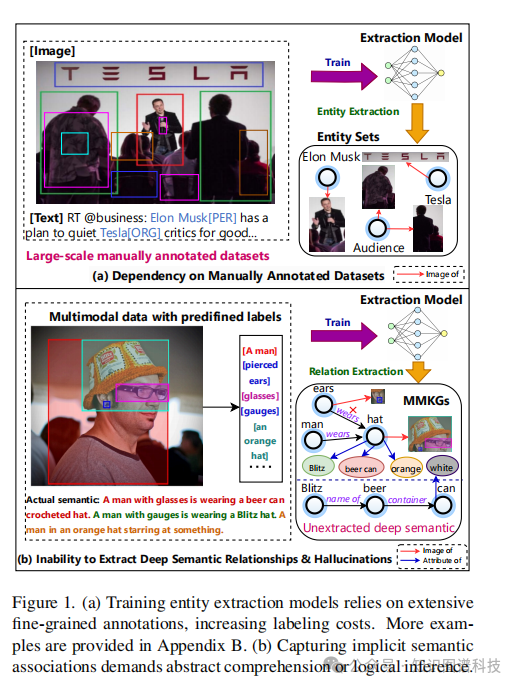
(2)无法提取深层语义关系及产生幻觉
如图1(b)所示,传统的视觉关系检测器主要识别的是表面的空间交互(比如“在...旁边”),而非与知识图谱逻辑一致的语义关系(如“穿戴”、“属于”)。这些方法还经常产生不合理或错误的连接,破坏了图谱的完整性。像“一个戴眼镜的男人戴着啤酒罐钩针帽”这类需要抽象理解的深层语义信息,往往无法被有效提取。
二、VaLiK框架:创新解决方案
为了解决上述挑战,本文提出了 VaLiK(Vision-align-to-Language integrated Knowledge Graph)。这是一个专为增强 LLMs 多模态推理能力而设计的新型框架。
2.1 核心设计理念
与依赖文本标注来训练提取模型的传统路径不同,VaLiK 采用了一种无标注方法来构建 MMKGs。该框架的核心思路是,首先使用多个基于专家链(Chain-of-Experts, CoE)原则设计的预训练视觉-语言模型(VLMs),通过跨模态特征对齐,将视觉输入“翻译”成图像特有的文本描述。
2.2 技术架构
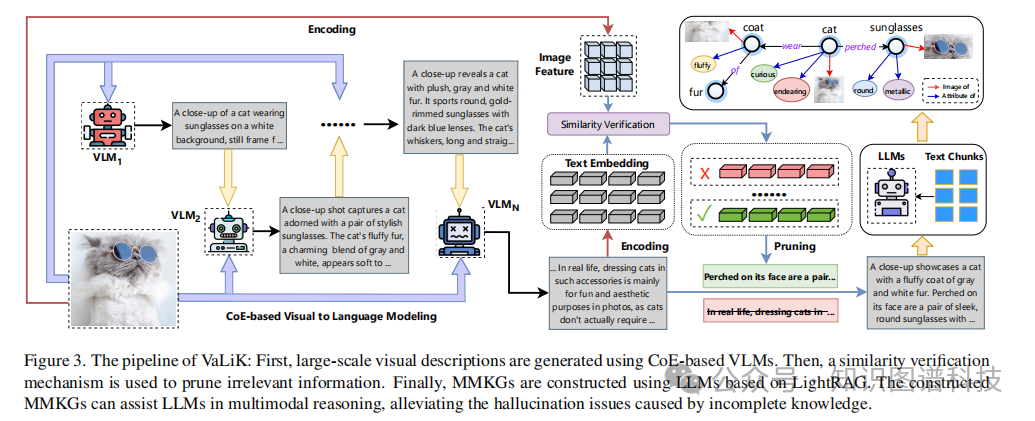
VaLiK 的完整流程如图2所示,包含三个关键阶段:
阶段一:基于CoE的视觉到语言建模
系统级联使用多个 VLMs(例如 VLM1、VLM2...VLMn),为同一张图像生成多样化的描述。这就像让多位专家从不同角度观察同一幅画,并各自给出描述。例如,对于一张戴太阳镜的猫的图片,不同 VLMs 可能生成:
- “白色背景上一只戴太阳镜的猫的特写...”
- “特写展示了一只有着蓬松灰白毛皮的猫,戴着金色边框、深蓝色镜片的圆形太阳镜...”
- “现实生活中,给猫穿戴这类配饰主要是为了拍照时的趣味和美感...”
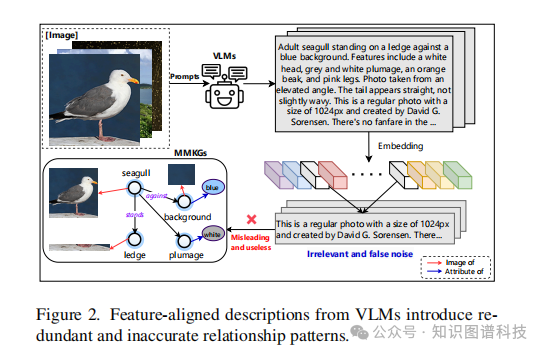
阶段二:相似度验证机制
为了应对单一 VLM 可能产生的冗余或不准确描述(如图2所示),VaLiK 开发了一套跨模态相似度验证机制。该机制通过编码、相似度计算和剪枝操作,量化不同描述之间的语义一致性,从而有效过滤掉在特征对齐过程中引入的噪声,保留高质量的文本片段。
阶段三:知识图谱构建
利用 LLMs,并基于类似 LightRAG 的技术,将经过验证和精炼的文本描述构建成结构化的 MMKG。最终生成的图谱将包含实体(如 “cat”、“sunglasses”、“fur”)及其之间的语义关系(如 “wear”、“attribute of”、“image of”)。
2.3 核心优势
最关键的是,即使没有任何人工标注的图像描述,仅凭这些经过精炼的文本描述,就足以构建出可用的 MMKG。相比传统的 MMKGs 构建范式,VaLiK 在保持直接“实体到图像”链接能力的同时,实现了显著的存储效率提升。
三、关键技术创新
3.1 端到端无标注框架
据研究者所知,VaLiK 是首个用于提升 LLMs 多模态推理能力的端到端无标注 MMKGs 构建框架。它有效消除了对昂贵人工标注文本材料的依赖,实现了完全自主的多模态知识生成过程。
3.2 零样本深层语义捕获
VaLiK 提供了一种创新的零样本方法来构建 MMKG,能够超越传统基于预定义标签的方法,捕获更深层的语义连接。同时,配备的有效验证系统确保了这些抽取关系的准确性。这种知识蒸馏范式在保持语义完整性的同时,大幅减少了存储需求。
3.3 高度模块化的可扩展架构
VaLiK 采用了高度模块化和可扩展的架构设计。这意味着可以轻松整合新的 VLMs 或调整工作流程,以应对不同专业领域的任务。这种设计促进了框架的快速适应性,无需进行昂贵的系统性重构。
3.4 模型选择策略
在 VLMs 的选择上,研究发现 BLIP-2 在生成描述性文本和识别图像中关键实体关系方面表现出色,因此被选为主要模型,而 LLaVA 或 Qwen2-VL 等可作为辅助组件。实验还发现,添加更多 VLMs 带来的收益会递减,这归因于单张图像中实体数量的有限性。但研究者假设,在面对语义内容更丰富的复杂视觉场景时,使用更多专家的益处将会增加。
四、实验验证与性能表现
4.1 性能优势
在多模态推理任务的实验结果表明,使用 VaLiK 增强的 LLMs 在性能上超越了先前的最先进模型。
所构建的 MMKGs 让 LLMs 实现了卓越的多模态推理性能,同时所需的存储空间远少于传统方法。更重要的是,即使采用了压缩的图结构,该方法依然保留了直接的实体到图像链接能力。
4.2 计算成本分析
在成本效益方面,VaLiK 的方法显著优于人工标注或对 LLM 进行全参数微调。由于篇幅限制,详细的计算成本分析可参见原论文附录。
五、研究意义与未来展望
5.1 理论贡献
VaLiK 实现了首个端到端、无标注、零样本且存储高效的多模态知识构建框架,并具有高度的适应性和可扩展性。
通过将视觉和语言对齐,VaLiK 不仅消除了对人工标注的依赖,还同时解决了视觉-文本语义不一致的固有问题。通过整合级联的预训练 VLMs 和跨模态验证机制,VaLiK 成功地将图像转换为了结构化知识,并过滤了噪声。
5.2 实践价值
所构建的知识图谱能够以极小的存储开销,显著增强 LLMs 的推理能力。VaLiK 的模块化设计支持其跨领域的快速适配,为自主知识综合提供了一个可扩展的解决方案。
5.3 未来方向
这项工作通过实现视觉和文本数据的高效集成,推进了多模态 AI 系统的发展。未来的研究可以探索在更复杂的视觉场景(如视频、3D环境)中应用 VaLiK,以及将其扩展到医疗、工业等特定领域的专业任务中。
六、研究团队与开源贡献
本研究由同济大学、上海人工智能实验室、华东师范大学、斯坦福大学和纽约大学的联合团队完成。研究代码已在 GitHub 上开源发布:https://github.com/Wings-Of-Disaster/VaLiK
结语
多模态推理在 LLMs 中一直受到知识不完整和幻觉问题的限制,而传统的文本知识图谱又因模态隔离而无法弥合视觉-文本语义鸿沟。VaLiK 框架通过创新的视觉-语言对齐方法构建 MMKGs,在无需人工标注的情况下成功应对了这一挑战。其在多模态推理基准测试中达到的最先进性能表明,这为构建高效、可扩展的多模态 AI 系统提供了一种切实可行的知识整合解决方案。
对多模态AI、知识图谱与大模型融合等前沿技术感兴趣的开发者,欢迎在云栈社区交流探讨,共同追踪技术演进与落地实践。
 发表于 2026-3-12 06:03:09
|
查看: 228|
回复: 0
发表于 2026-3-12 06:03:09
|
查看: 228|
回复: 0
