在强化学习领域,尤其是近期的PPO(Proximal Policy Optimization)及其变体GRPO(Group Relative Policy Optimization)算法中,Clip机制扮演着确保模型稳定训练的“定海神针”角色。很多人在学习时容易被复杂的数学公式劝退,本文将试图绕过繁琐的推导,从最直观的逻辑层面帮你理解:Clip到底在限制什么,以及它为何如此重要。
核心结论先行:Clip机制的设计本质是一种非对称的约束。它限制模型向“好”方向(即回报更高的动作)更新得过快、过猛,但并不限制模型从“错误”方向拉回来的力度。这种设计巧妙地平衡了探索与利用,防止策略更新步幅过大导致训练崩溃。
在深入分析前,我们先回顾一下GRPO算法的核心目标函数,其中就包含了关键的裁剪(Clip)项:
ℒ_GRPO(θ) = -1/G ∑_i=1^G 1/|o_i| ∑_t=1^|o_i| [min(π_θ(o_{i,t}|q,o_{i,<t}) / π_θ_old(o_{i,t}|q,o_{i,<t}) Â_{i,t}, clip(π_θ(o_{i,t}|q,o_{i,<t}) / π_θ_old(o_{i,t}|q,o_{i,<t}), 1-ε, 1+ε) Â_{i,t}) - βD_KL[π_θ||π_ref]]
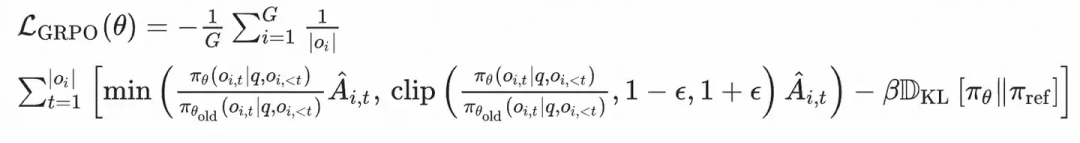
公式中,最需要关注的是这个比值 r_t(θ),它被称为重要性采样权重,数学上表示新策略与旧策略在生成某个特定token(或执行某个动作)时概率的比值:
r_t(θ) = π_θ(o_i,t|q,o_i,<t) / π_old(o_i,t|q,o_i,<t)
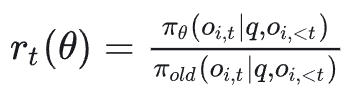
而Clip操作,即 clip(r_t(θ), 1-ε, 1+ε),会将 r_t 限制在区间 [1-ε, 1+ε] 内。这里的关键在于,整个损失函数使用了 min(r_t * A, clip(...) * A) 的结构,其中 A 是优势函数(Advantage),表示当前动作相对于平均水平的“好坏”程度(A>0 为好,A<0 为坏)。
下面,我们分三种情况来拆解Clip是如何具体起作用的。
情况一:r_t 在安全区内 [1-ε, 1+ε]
此时,新策略相对于旧策略的变化幅度被控制在预设的“安全区”内。无论 A 是正是负,min 函数都会选择原始的 r_t * A,因为 clip(...) * A 的值与之相同或更“不利”(在 min 函数看来)。Clip机制在此情况下不生效,模型按照标准的重要性采样梯度进行正常、平缓的更新。
情况二:r_t > 1+ε(新策略概率显著增加)
这是模型试图“大幅度跨步”的场景。我们需要结合优势函数 A 的正负来分析。
-
如果 A > 0 (好Token):模型认为自己找到了一个明显更好的生成方式(概率大增),并且优势函数也确认这是好的。按常理,应该给予大幅奖励和更新。但此时,clip(r_t, 1-ε, 1+ε) 会将这个过大的 r_t 截断为上限 1+ε。由于 A>0,min 函数会选取值较小的那一项,即被截断后的 (1+ε) * A。
结果:对应Token的梯度被限制在了一个固定的、较小的值上,甚至在某些情况下梯度贡献趋近于被忽略。这阻止了模型在“好方向”上走得太快、太急,防止因单步更新过大而偏离有效的策略分布,导致后续训练不稳定或崩溃。
-
如果 A < 0 (坏Token):情况变得有趣。模型执迷不悟,生成一个坏Token的概率反而大幅增加(r_t 很大)。虽然Clip项会将 r_t 截断为 1+ε,但由于 A 是负数,clip(...)*A 会得到一个负值。而原始的 r_t*A 因为 r_t 很大且 A 为负,会得到一个更负的值。对于 min 函数,它会选择更小的那个,也就是原始的、更负的 r_t*A。
结果:Clip在这种情况下没有起到约束作用!更新完全由原始的、放大后的 r_t*A 决定。这意味着,当模型试图强化一个坏行为时,算法不会限制对这种错误进行严厉的惩罚。这是一种“纠错从严”的逻辑。
情况三:r_t < 1-ε(新策略概率显著降低)
这是模型试图“大幅度躲避”某个Token的场景。
-
如果 A > 0 (好Token):模型不小心把“好东西”丢了,生成正确答案的概率在急剧下降。此时,clip(...) 的下限 1-ε 不生效(因为 r_t 更小)。由于 A>0,min 函数会选择值更小的那一项,即原始的 r_t*A(因为 r_t 很小且为正,r_t*A 的值小于被截断的下限值 (1-ε)*A)。
结果:更新遵循标准的重要性采样梯度,且更新幅度会随着 r_t 的缩小而自然缩小。从直觉上看,这意味着模型虽然知道这是一个好Token(A>0),但它自身选择该Token的置信度(概率)已经变得很低,因此其更新行为本身就更加保守和微弱。
-
如果 A < 0 (坏Token):这是模型“知错就改”的理想场景!它生成烂Token的概率显著变小了。此时,clip(r_t, 1-ε, 1+ε) 会将过小的 r_t 提升到下限 1-ε。由于 A<0,min 函数会选取值更小的项(即更负的项)。是原始的 r_t*A 更负,还是被截断后的 (1-ε)*A 更负?因为 r_t < 1-ε 且均为正数,乘以同一个负数 A 后,原始的 r_t*A 实际上负得更多(绝对值更大)*。所以,min 函数会选择原始的 `r_tA`。
等等,这岂不是没限制? 注意看,当 r_t 小到一定程度,继续变小并不会让 r_t*A 的绝对值变得更大(因为 A 固定),但 (1-ε)*A 是一个固定值。实际上,在 r_t 小于 1-ε 的整个区间,clip(...)*A 这个固定值((1-ε)*A)就是 min 函数的输出。
结果:对于那些已经“躲得足够远”(r_t 远小于 1-ε)的坏Token样本,它们的梯度被固定在一个恒定的、相对温和的负值上,而不再随着 r_t 的减小而无限加大惩罚力度。宏观意义在于**:从整个Batch的平均来看,既然这部分坏Token已经被新策略有效规避(概率变得极低),我们就适可而止,停止施加过度的惩罚。这种“见好就收”的策略,有效保护了模型已经习得的、正确的行为模式,避免了因过度惩罚而“矫枉过正”。
总结
通过以上分析,我们可以清晰地看到PPO/GRPO中Clip机制的智慧:
- 限制冒进:当模型发现一个好方法并想大力推广时(
r_t 很大且 A>0),Clip会踩刹车,防止更新步幅过大,保障训练稳定性。
- 鼓励纠错:当模型强化一个坏行为时(
r_t 很大且 A<0),Clip不会限制惩罚,允许算法大力纠正错误。
- 保护成果:当模型成功规避一个坏行为时(
r_t 很小且 A<0),Clip会设定一个惩罚上限,防止对已经改得很好的行为进行无休止的“鞭打”,保护已学习到的策略。
这正印证了开头的结论:Clip是一种定向的、非对称的稳定器。它不是简单粗暴地限制所有大幅更新,而是精心地区分更新方向,在鼓励改进、纠正错误的同时,最大限度地避免训练发散。理解这一点,对于在实际模型训练中调参(如设置 ε 值)和Debug至关重要。
希望这篇从直观逻辑入手的解析,能帮你拨开公式的迷雾,真正理解PPO/GRPO算法设计的精妙之处。如果你对强化学习或大模型训练的其他技术细节感兴趣,欢迎在云栈社区继续交流与探讨。
 发表于 2026-2-9 07:50:13
|
查看: 257|
回复: 0
发表于 2026-2-9 07:50:13
|
查看: 257|
回复: 0
