计算机视觉(Computer Vision,简称CV)是让机器“看懂”图像和视频的核心技术,也是当前人工智能领域最活跃、最具商业价值的子领域之一。无论是自动驾驶的眼睛,还是工业质检的慧眼,背后都离不开它的支撑。面对海量的学习资料和快速迭代的技术,如何规划一条高效务实的学习路径?本文为你梳理了一份适用于2025-2026年的计算机视觉从入门到精通的五阶段实战路线,特别融入了视觉大模型、3D生成等前沿趋势,并强调了工程落地这一拉开差距的关键环节。
学习路线总览(分5个阶段)
| 阶段 |
时间建议 |
核心目标 |
主要内容 |
推荐资源 |
| 0 |
0-4周 |
打基础 |
数学 + Python + 深度学习前置 |
必备前置知识 |
| 1 |
1-3个月 |
入门经典CV |
传统图像处理 + OpenCV实战 |
古典CV + 手写小项目 |
| 2 |
3-6个月 |
深度学习CV核心 |
CNN → Transformer → 主流检测/分割模型 |
CS231n + 现代模型复现 |
| 3 |
6-12个月 |
进阶与前沿 |
视觉大模型、多模态、3D视觉、视频理解 |
VLM、Diffusion、NeRF、YOLOv12+ |
| 4 |
12个月+ |
工程化 & 产业落地 |
模型部署、MLOps、边缘计算、项目闭环 |
工业级项目 + 比赛/开源 |
阶段0:打基础(强烈建议先补齐)
这一步没走稳,后面的路会变得格外艰难。别跳过,这些是理解一切复杂模型的基石。
- 高等数学 & 线性代数(重点):矩阵运算、特征值/特征向量、梯度、链式法则、PCA/SVD。这些概念是理解模型如何“学习”和“优化”的钥匙。
- 概率统计:常见分布、贝叶斯思想、期望、KL散度、信息论基础。用于处理不确定性,也是很多生成式模型的理论源头。
- Python编程:熟练掌握
numpy(数组操作)、pandas(数据处理)、matplotlib(可视化),以及 PIL/pillow(图像处理库)。良好的调试技巧能极大提升效率。
- 深度学习前置:搞懂神经网络的基本原理、前向/反向传播过程、常见优化器(如SGD, Adam)的工作原理,以及应对过拟合的常用方法(如Dropout, 正则化)。
2025-2026实用资源推荐:
- 数学:3Blue1Brown的《线性代数的本质》系列视频直观易懂,结合《深度学习数学》这类书籍巩固。
- Python:找一份“Python数据分析”速成教程,边学边练。
- 深度学习入门:吴恩达在Coursera的《Deep Learning Specialization》前3门课体系完整;或者直接看李宏毅教授2025年最新的机器学习/深度学习课程(B站有免费资源),更贴近当下发展。
阶段1:古典计算机视觉(1-3个月)
目标很明确:理解图像的底层构成,并学会用OpenCV等工具解决大多数简单的视觉任务。这是培养“视觉直觉”的重要阶段。
核心内容:
- 图像的本质:像素、通道、RGB/HSV等色彩空间。
- 图像滤波:高斯滤波去噪、中值滤波抗椒盐噪声、双边滤波保边。
- 特征提取:边缘检测(Sobel, Canny)、角点检测(Harris)、更稳健的特征描述子(SIFT, ORB)。
- 图像变换与合成:仿射/透视变换、图像配准与拼接。
关键在于动手:
- 官方教程是最好的起点:《OpenCV官方教程》(使用4.10+版本)。
- 系统课程:Coursera上的《Computer Vision Basics》或Udemy的《Modern Computer Vision with OpenCV》(找2025年更新版)。
- 实战博客:PyImageSearch,里面有大量即学即用的代码示例和项目思路。
- 小项目驱动学习:尝试完成一个人脸检测程序、一个自定义的美颜滤镜、一个文档扫描矫正工具,或者一个车牌识别Demo。这些都会让你对OpenCV的能力边界有清晰认识。
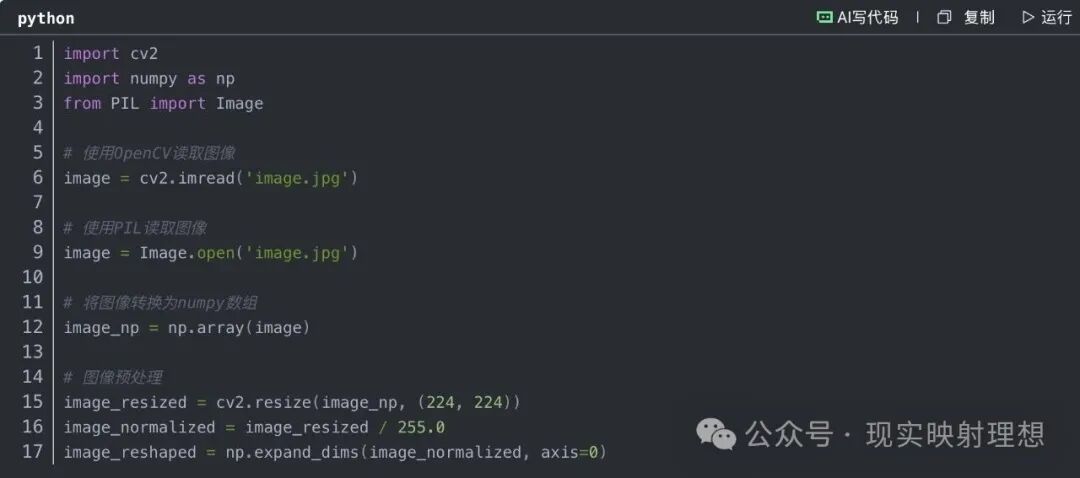
上图展示了一个典型的图像预处理流程,涉及OpenCV和PIL库的读取、NumPy数组转换以及 resize、normalize 等操作。
阶段2:深度学习驱动的计算机视觉(核心阶段,3-6个月)
从这里开始,正式进入现代计算机视觉的核心腹地。掌握本阶段的内容,意味着你具备了解决复杂视觉问题的能力。
必须掌握的模型与任务路线:
- 图像分类:理解从AlexNet、VGG到ResNet、EfficientNet的演进,重点掌握ResNet的残差思想,并跟进ConvNeXt和Vision Transformer(ViT)。
- 目标检测:弄清两阶段(Faster R-CNN)和单阶段(YOLO系列)的差异。紧跟YOLO家族最新进展(v8, v10, v11, v12),同时了解基于Transformer的检测器如RT-DETR。
- 图像分割:从FCN、U-Net到DeepLab系列,掌握语义分割和实例分割(Mask R-CNN)。务必动手体验一下Meta的Segment Anything Model(SAM/SAM2),感受提示式分割的强大。
- 关键点与姿态估计:了解HRNet、MoveNet等主流架构。
- 视觉Transformer:深入理解ViT如何将图像分块处理,以及Swin Transformer提出的层级化窗口注意力机制。
2025-2026必修课:
- 斯坦福CS231n:经典中的经典,务必找到2025年春季的最新版本课程视频、笔记和作业(B站/YouTube有中英字幕资源)。这是构建完整知识体系的不二之选。
- DeepLearning.AI专项课程:Coursera上由吴恩达团队推出的《Deep Learning for Computer Vision》专项课程,结构清晰,适合系统学习。
- PyImageSearch University:如果你偏爱极度实战、代码驱动的学习方式,这个付费平台是非常好的投资。
- 终极检验:使用PyTorch框架,亲自复现一个简化版的YOLOv8或RT-DETR,这会让你对模型细节的理解远超单纯调库。
阶段3:2025-2026前沿方向(进阶必看)
在打好核心基础后,你可以根据兴趣和职业方向,选择以下一个或多个前沿领域进行深入。这些方向代表了当前的研究热点和产业需求。
- 视觉大模型:探索CLIP(图文对齐)、BLIP-2、LLaVA、Qwen-VL等模型,理解如何让大语言模型“拥有”视觉能力。
- 多模态生成:不局限于理解,还要能创造。学习Stable Diffusion、Flux、SD3等文生图模型的原理与应用。
- 3D视觉重建与生成:NeRF及其后续变体(如Gaussian Splatting)彻底改变了3D重建。同时关注TripoSR、InstantMesh等3D生成模型。
- 视频理解与生成:从TimeSformer、VideoMAE等视频理解模型,到Sora引发的视频生成革命,视频是比图像更富挑战性的领域。
- 高效部署与边缘计算:研究YOLO-World、MobileNetV4、EfficientViT等为部署设计的模型,以及NCNN、TensorRT、ONNX等推理加速工具链。
阶段4:工程化 & 产业落地(真正拉开差距)
模型效果好只是第一步,能让模型在真实场景中稳定、高效地运行,才是产生商业价值的关键。这一步是区分研究型人才和工程型人才的分水岭。
- 模型优化:掌握模型量化(INT8/INT4)、剪枝、知识蒸馏等压缩加速技术。
- 部署流水线:熟悉ONNX作为中间格式,并实践TensorRT、OpenVINO、NCNN等在不同硬件(CPU, GPU, NPU)上的部署流程。
- 边缘设备:了解NVIDIA Jetson、瑞芯微RK3588、华为昇腾等边缘计算平台。
- MLOps实践:引入数据集版本管理(如Roboflow, DVC)、模型监控和持续训练的理念,构建健壮的AI pipeline。
- 工业场景:深入一个垂直领域,如表面缺陷检测、仪表读数识别(OCR)、人员行为分析等,理解业务痛点与数据特性。
高价值项目实战推荐:
- 收集并标注一个自定义数据集,用YOLOv12训练一个目标检测模型,并部署到树莓派或Jetson上。
- 利用SAM2的交互式分割能力,开发一个简易的图像标注或编辑工具。
- 基于LLaVA等视觉大模型,搭建一个可进行图文问答的演示应用。
- 尝试用Gaussian Splatting重建一个室内场景的3D模型。
- 最具含金量:复现或参与一个完整的工业质检项目,从数据采集、标注、训练、优化到部署上线,走完整个闭环。
2025-2026 CV学习资源速查表
| 类型 |
推荐资源 |
适合阶段 |
| 经典教材 |
《Computer Vision: Algorithms and Applications》 (Szeliski) |
0-2 |
| 顶尖课程 |
Stanford CS231n 2025最新版、课程笔记及作业 |
2-3 |
| 实战平台 |
Roboflow Learn、PyImageSearch University |
全阶段 |
| 中文优质 |
B站:李宏毅机器学习、3Blue1Brown数学、UP主“3D视觉工坊” |
全阶段 |
| 最新论文 |
arXiv + CVPR 2025/2026、ICCV 2025论文集 |
3-4 |
| 模型与代码 |
Ultralytics YOLO、OpenMMLab、HuggingFace Hub |
2-4 |
路线总结:先夯实数学与Python基础 → 通过OpenCV掌握古典视觉方法 → 深入吃透CNN与Transformer两大核心架构 → 追踪视觉大模型、多模态与3D等前沿方向 → 最终攻克模型工程化部署,完成真实项目闭环。
这条路线为你提供了一个清晰的框架,但每个人的背景和目标不同,可以根据自身情况进行调整和侧重。无论你目前处于哪个阶段,持续动手实践、保持对新技术的好奇心,并积极参与像云栈社区这样的开发者社区交流,都是快速成长的不二法门。你现在处于哪个阶段?最想先从哪个方向入手呢? |  发表于 2026-2-11 06:48:17
|
查看: 304|
回复: 0
发表于 2026-2-11 06:48:17
|
查看: 304|
回复: 0
