在关系型数据库,特别是 Oracle 中,B树索引是一种通用且默认的索引类型。无论是单列(简单)索引,还是组合了多列的复合索引,其底层通常都采用B树结构,这种索引最多可支持32个列。
我们以一个建立在employee表last_name列上的B树索引为例。假设这个索引的二元高度为3,这意味着Oracle需要经过两级分支块的导航,才能最终到达存储实际数据位置(ROWID)的树叶块。在每个分支块内部,都包含了一个指向下一级块(可能是另一个分支块或树叶块)的ID号,从而构成了树的枝干。
树叶块是索引结构的末端,它包含了三个核心部分:索引列的值、对应数据行的ROWID,以及指向前一个和后一个树叶块的指针。这种双向指针的设计,使得Oracle能够高效地向前或向后遍历所有索引条目。需要明确的是,B树索引只会对索引列上具有非空(NOT NULL)值的行建立索引条目。如果某一行在索引列上的值为NULL,那么它不会被纳入索引。对于复合索引,如果其中某列包含NULL值,该行仍然会被索引,只是NULL值在索引中被视为空值处理。
下图清晰地展示了B树索引的这种分层逻辑结构:
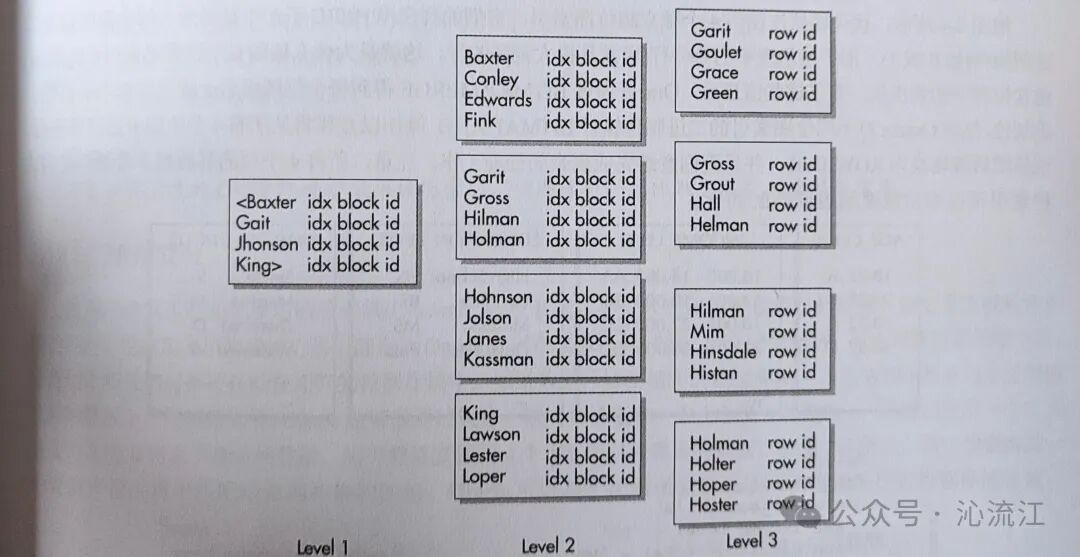
B树索引的优势与要点在于其存储了索引列的实际值。这一特性带来一个重要的性能优化手段:当查询仅涉及索引中包含的列时(例如一个SELECT last_name FROM employee WHERE last_name = 'King'的查询,或者一个精心设计的覆盖索引查询),数据库可以完全通过读取索引来获取所需数据,而无需再去访问原始的数据表。这被称为“索引覆盖扫描”,它能显著减少磁盘I/O操作,从而提升查询速度。
因此,在设计数据库索引,尤其是在处理类似MySQL等数据库的高频查询时,考虑创建合适的复合索引来覆盖查询字段,是优化性能的一个关键思路。当然,索引并非越多越好,需要权衡查询加速与维护成本(如插入、更新、删除操作变慢)。在实际开发中,理解B树索引的工作原理,是进行高效数据库设计和SQL优化的基础。 |  发表于 2026-2-11 07:14:52
|
查看: 155|
回复: 0
发表于 2026-2-11 07:14:52
|
查看: 155|
回复: 0
