在众多关于RAG的讨论中,评论区总绕不开一个经典问题:chunk大小到底该怎么选?为什么非得是某个特定尺寸?
选小了,细节丰富但上下文断裂;选大了,全局语义完整可关键事实又容易丢失。这就像走钢丝,平衡点难找。
近期,被英伟达开出20~30亿美元收购意向的以色列AI公司AI21 Labs,发布了一篇重磅研究《Chunk size is query-dependent: a simple multi-scale approach to RAG retrieval》。文章直接指出:chunk大小根本没有通用最优解,它高度依赖于你的查询内容。更妙的是,他们提出了一套多尺寸chunk方案,无需重新训练模型,就能让RAG检索性能提升1%~37%,在一些数据集上甚至能触及20%~40%的性能天花板。
今天,我们就来深入拆解这份研究,看看这套“简单却有效”的方案究竟如何运作。
01 不存在标准chunk大小,准确率与提问强相关
过去,业界普遍认为chunk的最优区间在500-800个token左右,因为这大致对应一段话的长度,能在细节和语义之间取得平衡。
这个结论本身没错,但它引出了一个更深层的问题:真的存在一个能完美适配所有查询的单一chunk大小吗?
AI21 Labs用实验给出了否定的答案。他们使用多个数据集和不同的chunk尺寸进行检索性能测试,发现了一个关键规律:即使是查询同一个语料库,不同提问所对应的最优chunk大小也天差地别。
例如,对于事实型查询(比如“某产品的发布日期”),可能只有100个token的小chunk才能精准命中关键信息;而对于需要理解上下文的理解型查询(比如“分析某个会议的讨论焦点”),则可能需要500个token以上的大chunk才能匹配到足够的背景信息。
这在实际应用中也有体现:沃尔沃构建企业知识库时,由于理解型内容居多,倾向于使用较大的chunk;而OpenAI在处理更通用的任务时,则可能采用一刀切的500 token策略。
当然,经验之谈需要数据支撑。为了确保结论的普适性,AI21选取了三个在文本形式和查询类型上差异巨大的数据集:
- QMSum:会议转录文本,文档平均长度超过5000个token,信息分散在不同发言者和主题中,查询多是具体的讨论点。
- NarrativeQA:基于长篇故事和书籍章节的问答,查询需要理解叙事中不同粒度的关联情节,考验系统的上下文理解能力。
- Seinfeld(宋飞正传):一个自定义的趣味数据集,基于电视剧转录文本进行问答,同时测试对具体事实和全局上下文的检索能力。
针对每个语料库,研究团队分别按照50、100、200、500、1000、2000个token的尺寸进行切块并检索top K结果。最终的实验结果清晰地表明:最优的chunk大小随着查询内容的变化而显著变化。
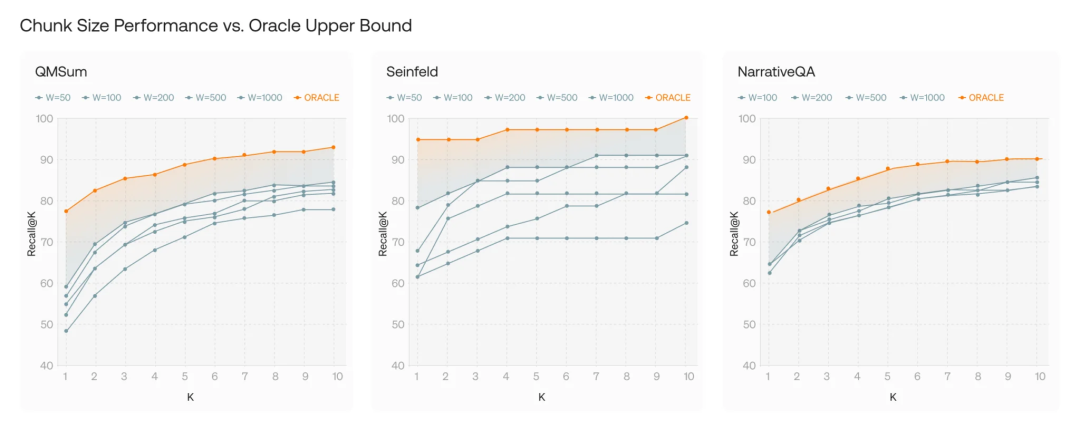
从图中可以得出两个核心结论:
- 不存在一个在绝对意义上占优的chunk尺寸。适用于某个查询的“最佳”尺寸,往往在另一个查询中表现平平。
- 理论上最优的性能(图中ORACLE线)相比任何固定尺寸的chunk,都有20%~30%的准确率优势,部分数据集甚至超过40%。这个结论在不同类型的文本中均成立。
因此,放弃寻找“万能”的固定尺寸chunk,转而为不同的查询动态匹配最合适的chunk,成为了提升RAG性能的一个关键方向。
当然,行业内的研究者们早就意识到了固定尺寸chunk的局限性,并提出过多种优化方案,例如:
- Anthropic的上下文检索,会为chunk补充文档级的上下文信息。
- Jina AI的Late Chunking采用先embedding后切块的方式。
- RAPTOR算法在固定尺寸chunk基础上构建分层摘要。
但这些方法要么仍未完全脱离固定尺寸的框架,要么增加了模型复杂度,甚至需要重新训练embedding模型或引入LLM生成新内容,可能带来额外噪声。
相比之下,AI21的这条研究路径显得更加“工程友好”:它不改变chunk的基础逻辑,仅仅在数据处理阶段引入多尺寸策略。
02 如何构建多尺寸chunk并对索引结果排序
这套方案的核心思路异常简洁:
- 索引阶段:预处理时,用多个不同的尺寸对文档进行切块,并为每一组尺寸的chunk分别建立向量索引。
- 推理阶段:收到查询时,并行查询所有这些不同尺寸的索引。
- 结果融合:使用倒数排名融合(Reciprocal Rank Fusion, RRF)算法整合所有查询结果,得到最终的文档排名。
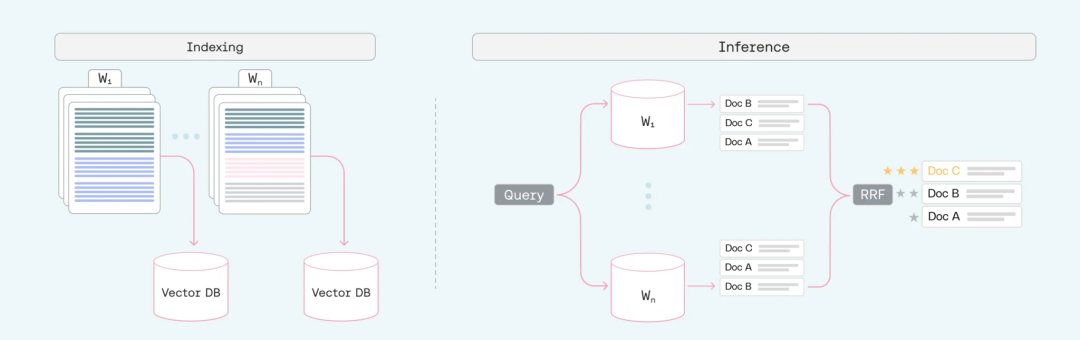
这个流程中有几个细节值得深究。
首先,为什么用RRF,而不是直接对比或加总相似度分数?
因为不同尺寸chunk计算出的相似度分数不具备直接可比性。小chunk的embedding更聚焦、更具体,其相似度分数可能普遍偏高;而大chunk的embedding更泛化、更抽象,分数可能相对偏低。直接进行数值比较或加总毫无意义。
RRF是一种模型无关的排名聚合方法。它不关心绝对的相似度分数,只关注每个chunk在不同尺寸索引中的排名位置。排名越靠前,其“投票”权重就越高。这种方法无需在不同索引间进行复杂的分数校准,简单且高效。
RRF的得分计算公式如下:
score_d = Σ_{s∈S} Σ_{c∈C_{d,s}} 1 / (k + rank_{s}(c))
其中:
S 是chunk大小的集合(例如 {50, 100, 200, 500, 1000});C_{d,s} 是在chunk大小为 s 时,文档 d 被检索到的所有chunk的集合;rank_{s}(c) 是chunk c 在尺寸为 s 的索引中的排名(排名从1开始,越靠前权重越高);k 是一个常数(通常设为60),用于平滑排名权重。
简单来说,这个公式会更倾向于那些被多次检索到的文档:要么它在某个尺寸下多个相关chunk排名靠前,要么它在多个不同尺寸的索引中都能被找到。通过这种加权投票机制,最终综合出一个更鲁棒的文档排序。
03 结果测评
为了验证这套方案的实际效果,AI21在多个基准数据集上进行了测试。他们选用了 intfloat-multilingual-e5-small 和 nomic-ai-nomic-embed-text-v1 两款常用的开源embedding模型,对比了传统的固定尺寸chunk索引与多尺寸索引+RRF的效果。
在MTEB检索任务的一个子集上,结果显示在8种模型配置中,有7种情况下的多尺寸方案都优于传统的固定chunk方案。虽然平均提升幅度在1%~3%之间,但在成熟的检索基准测试中,顶尖模型之间的差距往往也只有百分之零点几,这个提升已经相当显著。
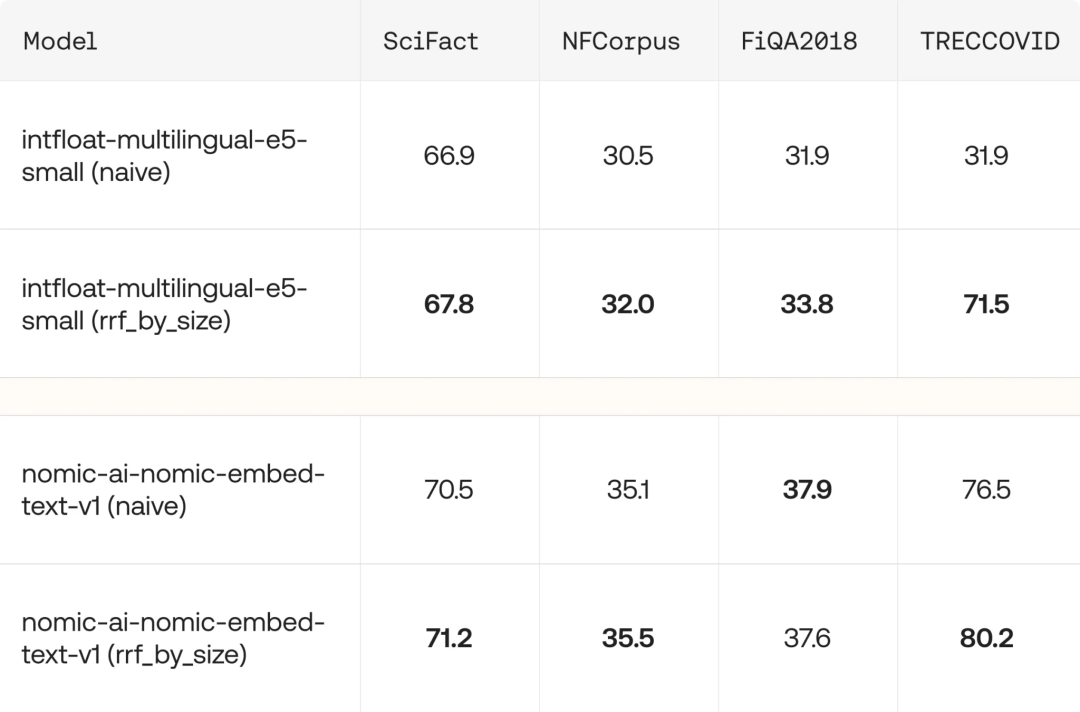
而在TREC-COVID数据集上,多尺寸方案更是实现了36.7% 的显著效果提升。这充分说明,对于查询类型多样、文档结构复杂的数据集,从多尺寸chunk中获得的收益越大。
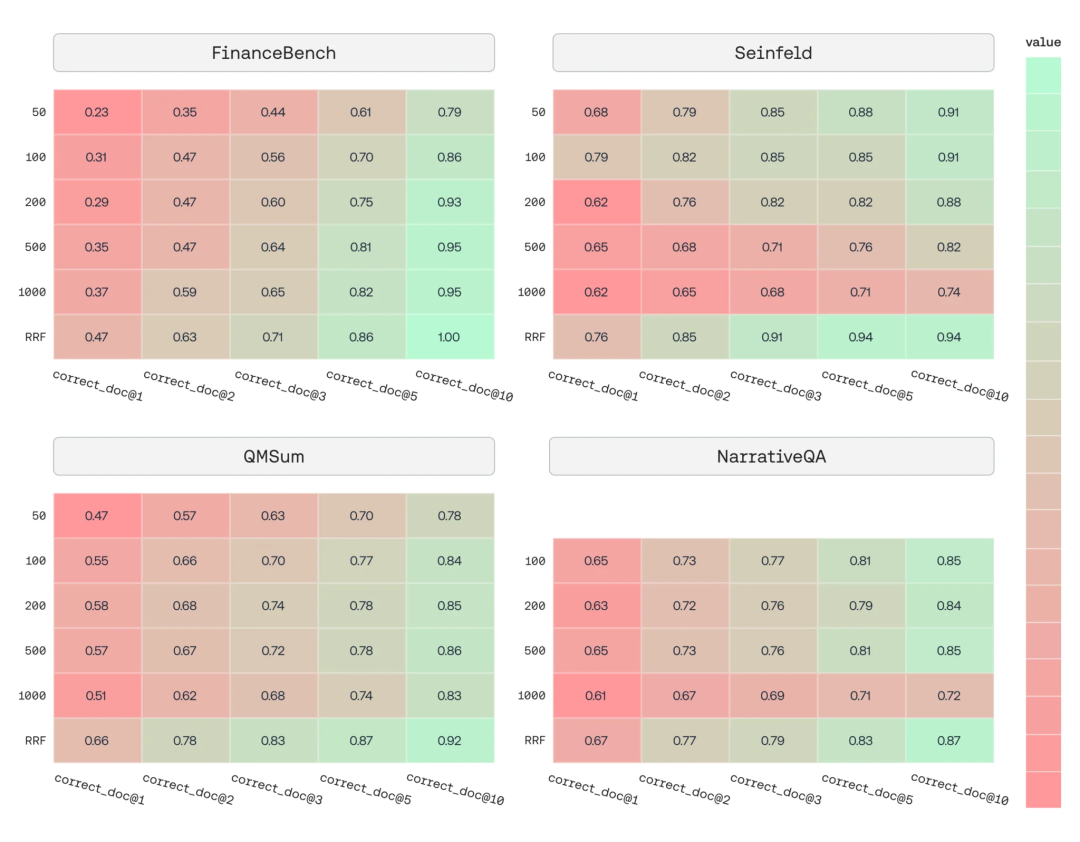
在FinanceBench、NarrativeQA、QMSum和《宋飞正传》数据集上的测试结果也呈现出一致的趋势:多尺寸chunk方案的性能稳定优于任何单一固定尺寸,并且无限接近理论上的性能上限(SOTA)。
04 延伸解读
这套方案的核心价值,不在于其模型设计有多复杂,而在于它重新思考了文本表示和检索结果的聚合方式。它不需要更换模型、不需要重新训练embedding、不需要添加复杂规则,仅仅通过“多存几份不同尺寸的索引”和“一个简单的排名融合算法”,就能实现与更换更强embedding模型相当的性能提升。这对于广大正在进行RAG工程落地的开发者而言,具有极高的参考价值和实操性。
当然,AI21的方案也并非完美无缺。其主要局限性在于:
- 存储与计算成本增加:引入多尺寸chunk,需要embedding和存储的chunk数量会成倍增加(通常是2~5倍),这对于成本敏感型场景是一个挑战。
- 推理延迟增加:相比查询单一索引,并行查询多个索引必然会增加推理耗时,对低延迟有严格要求的实时场景不太友好。
- 语义割裂问题依旧存在:这套方案本质上还是基于不同固定尺寸的滑动窗口进行硬切分,无法避免将一个完整的语义单元(如段落)切分到两个chunk中的情况,这可能影响最终检索效果。
当前,行业内的研究和实践正朝着更智能的方向演进,主要包括以下几个趋势:
- 语义自适应chunk:摒弃固定窗口,基于文本的语义边界(如段落、句子、主题)进行切分,利用LLM或embedding模型判断语义连贯性,从根本上避免硬切分带来的语义割裂。
- 分层chunk检索:在RAPTOR思想上升级,将文本切分为细粒度块和包含其摘要的粗粒度块。检索时先通过粗粒度块快速定位文档范围,再用细粒度块精准定位信息,在上下文和细节之间取得平衡,也部分降低了多尺度索引的成本。
- 基于查询判断的动态chunk:结合AI21的多尺度思想,在推理时先通过轻量级分类器判断查询类型(事实型/理解型/推理型),再有选择性地查询部分最相关尺度的索引,在保留多尺度匹配优势的同时,大幅减少无效查询,降低延迟。
- 混合chunk策略:将语义chunk和多尺寸chunk结合。先进行语义chunk保证文本完整性,再对每个语义块进行小尺度的细切分。这种方式兼顾了语义完整性和多尺度的查询匹配性,是当前工程落地中颇具前景的方案之一。
- 工程化优化:在既定chunk方式上,通过添加元数据(如位置、主题、来源)、利用向量数据库的分区或混合索引功能,来优化存储和检索效率,从而控制多尺度索引带来的成本压力。
技术的优化永无止境,但AI21的这项研究为我们指明了一条清晰且低成本的改进路径。在实际应用中,开发者可以根据自身场景在效果、成本和延迟之间做出权衡,选择最适合的chunk策略组合。
想要深入探讨更多AI与检索技术细节?欢迎来云栈社区与大家一起交流学习。
 发表于 2026-2-11 07:19:14
|
查看: 207|
回复: 0
发表于 2026-2-11 07:19:14
|
查看: 207|
回复: 0
