近年来,以大型语言模型(LLM)为核心的生成式AI发展迅猛。然而,我们常常面临一个痛点:LLM的训练数据是固定的,无法获取训练后产生的新知识或企业内部的私有文档。直接向其提问内部信息,它可能会“幻觉”(即一本正经地胡说八道)。检索增强生成(RAG)技术正是为解决这一问题而生,而 Spring AI 则为Java开发者提供了便捷的实现路径。
本文将深入探讨RAG的核心原理,并手把手带你在Spring Boot项目中,基于PGVector向量数据库,构建一个能够利用自有文档进行问答的智能应用。
RAG是什么?为何需要它?
想象一下,你想向LLM咨询公司内部某份技术手册的内容。如果把整本手册(可能数百页)都作为上下文喂给它,不仅成本高昂(按Token计费),LLM也容易“迷失”在信息海洋中,抓不住重点。
RAG(Retrieval Augmented Generation)即检索增强生成,其核心思想是:在LLM生成答案前,先从一个外部知识库中检索出与问题最相关的片段,然后将这些片段与原始问题一同提交给LLM。这样,LLM的答案就有了精准、可靠的依据,极大减少了幻觉。
整个过程分为离线和在线两条主线:
- 离线流程(知识入库):将你的文档(TXT、PDF、HTML等)进行分割、转化为向量,并存储到专门的向量数据库中。
- 在线流程(智能问答):当用户提问时,将问题也转化为向量,从向量库中快速找到最相似的文本块,将其作为“证据”与问题一起交给LLM生成最终答案。
核心技术拆解:从文档到答案的旅程
要理解RAG,需要掌握几个关键概念。
1. 文档分块 (Chunking)
文档不能整篇存入,需要切分成有意义的片段。常见的策略有:
- 固定大小拆分:简单快速,但可能割裂完整语义。
- 语义/递归拆分:根据段落、句子或标记符(如
\n\n)分割,能更好保持语义完整性,是更推荐的方式。
2. 嵌入与向量化 (Embedding)
这是实现语义检索的魔法。Embedding模型可以将一段文本(无论长短)转换为一个固定长度的浮点数数组(即向量)。语义相近的文本,其对应的向量在数学空间中的“距离”也更近。
3. 向量数据库 (Vector Database)
传统数据库擅长精确匹配,而向量数据库专为高效“找相似”而设计。它存储向量,并能根据一个查询向量,快速找出库中最相似的Top K个向量。常见的如Chroma、Pinecone,以及本文使用的 PGVector(PostgreSQL的扩展)。
4. 相似性搜索 (Similarity Search)
如何衡量两个向量的“相似度”?常用方法有:
- 余弦相似度:最常用,衡量向量方向的差异,结果在[-1,1]之间,越接近1越相似。它不受向量长度影响,非常适合文本语义匹配。
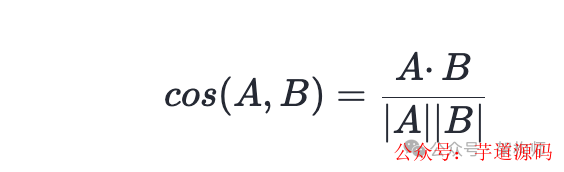
- 欧氏距离:衡量空间中的直线距离,距离越小越相似。
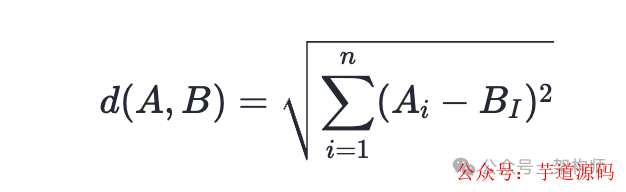
- 点积:计算简单,但结果受向量长度影响。
5. 提示词模板 (Prompt Template)
这是连接检索结果与LLM的桥梁。一个典型的RAG提示词模板如下,它明确指令LLM基于给定的上下文进行回答:
基于以下上下文信息回答问题。如果你无法从中找到答案,请说“我不知道”,不要编造信息。
上下文:
{检索到的文档片段}
问题:
{用户的问题}
答案:
实战:用Spring AI快速搭建RAG应用
下面,我们以构建一个“员工信息问答”应用为例,展示具体步骤。完整环境:JDK 17, Spring Boot 3.5.0, Spring AI 1.0.0。
第1步:项目依赖与配置
首先,在 pom.xml 中引入必要的起步依赖:
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!-- Spring AI 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!-- PGVector 向量存储 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pgvector</artifactId>
</dependency>
<!-- RAG 功能支持 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-rag</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- Web支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
接下来是核心的 application.yml 配置。这里我们配置了:
- LLM模型:使用 Qwen2.5-72B-Instruct
- Embedding模型:使用 OpenAI 的 text-embedding-ada-002 (需配置API Key和Base URL)
- 向量存储:使用 PGVector,并自动初始化表结构。
spring:
ai:
openai:
base-url: ${OPENAI_BASE_URL} # 你的LLM服务地址
api-key: ${OPENAI_API_KEY}
chat:
options:
model: Qwen/Qwen2.5-72B-Instruct
embedding:
options:
model: text-embedding-ada-002
vectorstore:
pgvector:
initialize-schema: true # 自动建表
index-type: HNSW # 索引算法
distance-type: COSINE_DISTANCE # 相似度计算方式
dimensions: 1536 # 向量维度,需与Embedding模型匹配
datasource:
url: jdbc:postgresql://localhost:5432/rag_demo # 你的PG数据库
username: ${DB_USER}
password: ${DB_PASSWORD}
第2步:知识入库(离线流程)
我们准备一个 file.txt 放在 src/main/resources 下,内容是关于员工“小璐”的描述。然后通过一个ETL(提取、转换、加载)流程将其存入向量库。
import org.springframework.ai.document.Document;
import org.springframework.ai.reader.TextReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.core.io.Resource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class KnowledgeIngestionController {
@Autowired
private VectorStore vectorStore;
@Value("classpath:/file.txt")
private Resource resource;
@GetMapping("/ingest")
public String ingestDocument() {
// 1. Extract: 读取文本文件
TextReader textReader = new TextReader(this.resource);
List<Document> rawDocuments = textReader.read();
// 2. Transform: 将文档按语义切分成块
TokenTextSplitter splitter = new TokenTextSplitter(500, 100, 10, 1000, true);
List<Document> documentChunks = splitter.apply(rawDocuments);
// 3. Load: 将块存入向量数据库(内部会自动调用Embedding模型生成向量)
vectorStore.add(documentChunks);
return "文档已成功入库,共切分为 " + documentChunks.size() + " 个片段。";
}
}
访问 /ingest 接口,你的知识库就准备好了。Spring AI 的 TokenTextSplitter 会智能地分割文档,而 vectorStore.add() 方法背后会自动调用你配置的Embedding模型为每个文本块生成向量。
第3步:智能问答(在线流程)
这是最精彩的部分,只需几行代码即可实现完整的RAG问答链。
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.api.Advisor;
import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;
import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;
import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class RagQaController {
@Autowired
private ChatClient chatClient;
@Autowired
private VectorStore vectorStore;
@GetMapping("/ask")
public String ask(@RequestParam String question) {
// 1. 构建检索增强顾问(Retrieval Augmentation Advisor)
Advisor ragAdvisor = RetrievalAugmentationAdvisor.builder()
.documentRetriever(
VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore) // 指定知识库来源
.similarityThreshold(0.6) // 相似度阈值,过滤低质量结果
.topK(4) // 检索最相似的4个片段
.build()
)
.queryAugmenter(
ContextualQueryAugmenter.builder()
.allowEmptyContext(true) // 允许无检索结果
.build()
)
.build();
// 2. 发起对话,并应用RAG顾问
return chatClient.prompt()
.advisors(ragAdvisor) // 挂载RAG能力
.user(question)
.call()
.content();
}
}
现在,访问 /ask?question=小璐是做什么工作的?。Spring AI 将自动执行以下操作:
- 将你的问题转化为向量。
- 在PGVector库中检索出最相关的几个关于“小璐”的文本片段。
- 将这些片段作为上下文,连同你的问题和内置的优化指令,一起发送给LLM。
- 将LLM生成的、基于上下文的专业回答返回给你。
效果对比:
- 无RAG:直接问LLM“小璐是谁?”,它可能回答不知道或胡编乱造。
- 有RAG:LLM的回答将是:“小璐是一名专注于Java开发的计算机从业者...”,答案精准且源自你的文档。
总结与展望
通过本文,我们不仅理解了RAG如何通过“检索-增强”的机制攻克LLM的幻觉与知识滞后难题,还亲身体验了利用 Spring Boot 和Spring AI框架快速实现这一技术的便利性。从文档分块、向量化到检索与生成,Spring AI 提供了高度封装的组件,让Java开发者能专注于业务逻辑。
本文的实战示例基于文件系统和一个简单的员工档案。在实际生产环境中,你可以轻松扩展:
- 知识源:支持PDF、Word、PPT、网页乃至数据库表。
- 向量库:根据数据规模和要求,选用 PostgreSQL(PGVector)、Redis(RediSearch)或专业向量库。
- 流程优化:引入更精细的重排序模型、多路检索、对话历史管理等高级特性。
RAG已成为构建企业级可信AI应用(如智能客服、知识库助手、代码分析工具)的基石技术。希望这篇从原理到实战的指南,能帮助你顺利上手,在 Spring AI 的助力下,将强大的大模型能力安全、可控地引入你的项目之中。
 发表于 2026-2-11 09:48:07
|
查看: 258|
回复: 0
发表于 2026-2-11 09:48:07
|
查看: 258|
回复: 0
