一、技术背景与核心概念
1.1 什么是分段卸载技术
Linux分段卸载技术(Segmentation Offload)是一种网络性能优化机制,它允许网络接口卡(NIC)在硬件层面处理大数据包的分段和重组工作,从而显著减轻CPU的负载。我们可以通过一个简单的类比来理解:
传统方式(无卸载):大型家具 → 拆分成小块(CPU) → 多辆小货车运输 → 目的地重新组装(CPU)
卸载方式:大型家具 → 整件交给专业物流公司(NIC) → 自动分拆运输 → 自动重组
1.2 核心技术分类
| 技术类型 |
缩写 |
方向 |
工作层面 |
类比 |
| 大段发送卸载 |
TSO |
发送 |
传输层→网络层 |
快递公司自动拆分大包裹 |
| 通用段发送卸载 |
GSO |
发送 |
通用分层 |
智能分拣系统 |
| 大段接收卸载 |
LRO |
接收 |
网络层→传输层 |
物流中心自动合并小包裹 |
| 通用段接收卸载 |
GRO |
接收 |
通用合并 |
智能合并系统 |
二、工作原理深度分析
2.1 核心问题:MTU限制与性能矛盾
网络传输中存在MTU(最大传输单元)的限制,以太网默认通常为1500字节。但应用层可能产生数MB甚至更大的数据块,这就产生了根本性的矛盾。对于开发者而言,深入理解Linux及TCP/IP协议栈的原理,有助于更好地定位和解决此类性能瓶颈。
应用层数据(10MB)
↓
TCP层(需要保证可靠传输)
↓
IP层(MTU=1500字节限制)
↓
需要拆分成约6667个数据包!
2.2 分段卸载的核心思想
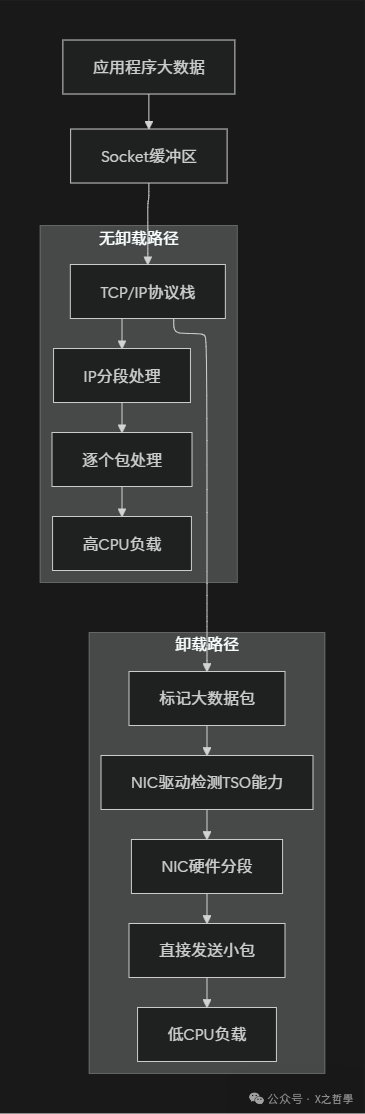
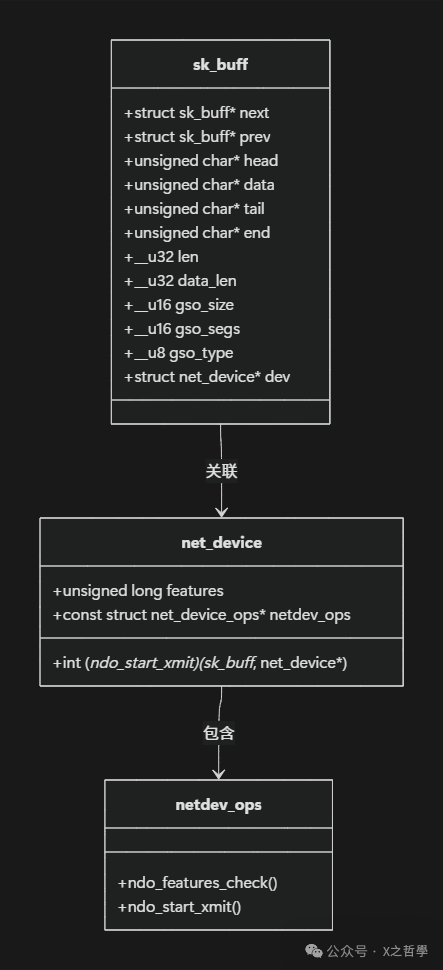
2.3 sk_buff:Linux网络数据包的核心结构
sk_buff(socket buffer)是内核网络子系统的基石,理解其结构是掌握卸载技术的关键。
/* 简化版sk_buff结构 - 实际有200+字段 */
struct sk_buff {
/* 链表管理 */
struct sk_buff *next;
struct sk_buff *prev;
/* 数据区指针 */
unsigned char *head; // 分配的内存起始
unsigned char *data; // 当前数据起始
unsigned char *tail; // 当前数据结束
unsigned char *end; // 分配的内存结束
/* 网络层信息 */
__u32 len; // 数据总长度
__u32 data_len; // 分段数据长度
__u16 mac_len; // MAC头长度
__u16 hdr_len; // 头部长度
/* 卸载相关标志 */
__u8 cloned:1;
__u8 nohdr:1;
__u8 pfmemalloc:1;
__u16 gso_size; // GSO分段大小
__u16 gso_segs; // GSO分段数量
__u8 gso_type; // GSO类型
/* 校验和 */
__wsum csum;
__u32 csum_start;
__u32 csum_offset;
/* 设备信息 */
struct net_device *dev;
};
三、实现机制详析
3.1 TSO(TCP Segmentation Offload)实现机制
3.1.1 TSO工作流程
当协议栈准备发送一个大TCP数据包时,会先检查网卡是否支持TSO。
/* 简化的TSO发送流程 */
int tcp_transmit_skb(struct sock *sk, struct sk_buff *skb, int clone_it)
{
struct tcp_sock *tp = tcp_sk(sk);
/* 检查TSO支持 */
if (skb->len > tp->mss_cache &&
sk->sk_route_caps & NETIF_F_TSO) {
/* 设置GSO信息,通知下层这是一个需要硬件分段的大包 */
skb_shinfo(skb)->gso_size = tp->mss_cache;
skb_shinfo(skb)->gso_type = SKB_GSO_TCPV4;
/* 计算需要分成多少段 */
skb_shinfo(skb)->gso_segs = DIV_ROUND_UP(skb->len, tp->mss_cache);
/* 将“大包”信息传递给网卡驱动,而非实际分段 */
return ip_queue_xmit(skb);
}
/* 如果网卡不支持,则走传统的软件分段路径 */
return tcp_fragment(sk, skb, tp->mss_cache, skb->len);
}
3.1.2 网卡驱动中的TSO处理
驱动程序接收到带有GSO信息的skb后,会利用DMA和硬件描述符来指导网卡进行分段。
/* Intel ixgbe驱动TSO处理示例 */
static netdev_tx_t ixgbe_xmit_frame(struct sk_buff *skb,
struct net_device *netdev)
{
struct ixgbe_adapter *adapter = netdev_priv(netdev);
/* 检查是否为TSO数据包 */
if (skb_is_gso(skb)) {
/* 准备TSO上下文描述符 */
union ixgbe_adv_tx_desc *tx_desc;
/* 设置TCP头部信息 */
if (skb_shinfo(skb)->gso_type & SKB_GSO_TCPV4) {
tx_desc->read.cmd_type_len |=
IXGBE_ADVTXD_DCMD_DEXT | // 扩展描述符
IXGBE_ADVTXD_DTYP_CTXT | // 上下文描述符
IXGBE_ADVTXD_DCMD_TSE; // TSO使能
/* 设置MSS值,告诉网卡每个分段的大小 */
tx_desc->read.olinfo_status |=
skb_shinfo(skb)->gso_size << IXGBE_ADVTXD_MSS_SHIFT;
}
/* 设置数据总长度和分段数量信息 */
tx_desc->read.olinfo_status |=
(skb_shinfo(skb)->gso_segs << IXGBE_ADVTXD_PAYLEN_SHIFT);
}
/* 启动DMA传输,将大数据缓冲区的地址交给网卡 */
dma_sync_single_for_device(&pdev->dev,
mapping,
skb_headlen(skb),
DMA_TO_DEVICE);
}
3.2 GRO(Generic Receive Offload)实现机制
3.2.1 GRO工作原理类比
GRO可以看作是一个智能的网络数据包“合并”中心。传统方式需要单独处理每个到达的小数据包,而GRO则尝试将属于同一个TCP流、序列号连续的小包在底层合并成一个大的数据包,再提交给上层协议栈处理,从而大幅减少协议栈的处理次数。
3.2.2 GRO核心数据结构
内核通过以下结构来跟踪和管理可能合并的数据包流。
/* GRO控制结构,附加在skb上 */
struct napi_gro_cb {
/* 数据偏移 */
int data_offset;
/* 分段信息 */
int frag0_len;
int frag0_valid;
/* 匹配标识 */
u32 flush;
u32 flush_id;
/* 协议特定信息 */
union {
struct {
u16 flags;
u16 num_frags;
} tcp;
struct {
u16 mac_len;
} eth;
} proto;
};
/* GRO流表项 - 用于标识和合并相同流的数据包 */
struct gro_remotelist_entry {
struct list_head list;
__be32 remote_ip;
__be32 local_ip;
__be16 remote_port;
__be16 local_port;
__be16 protocol;
};
3.2.3 GRO处理流程
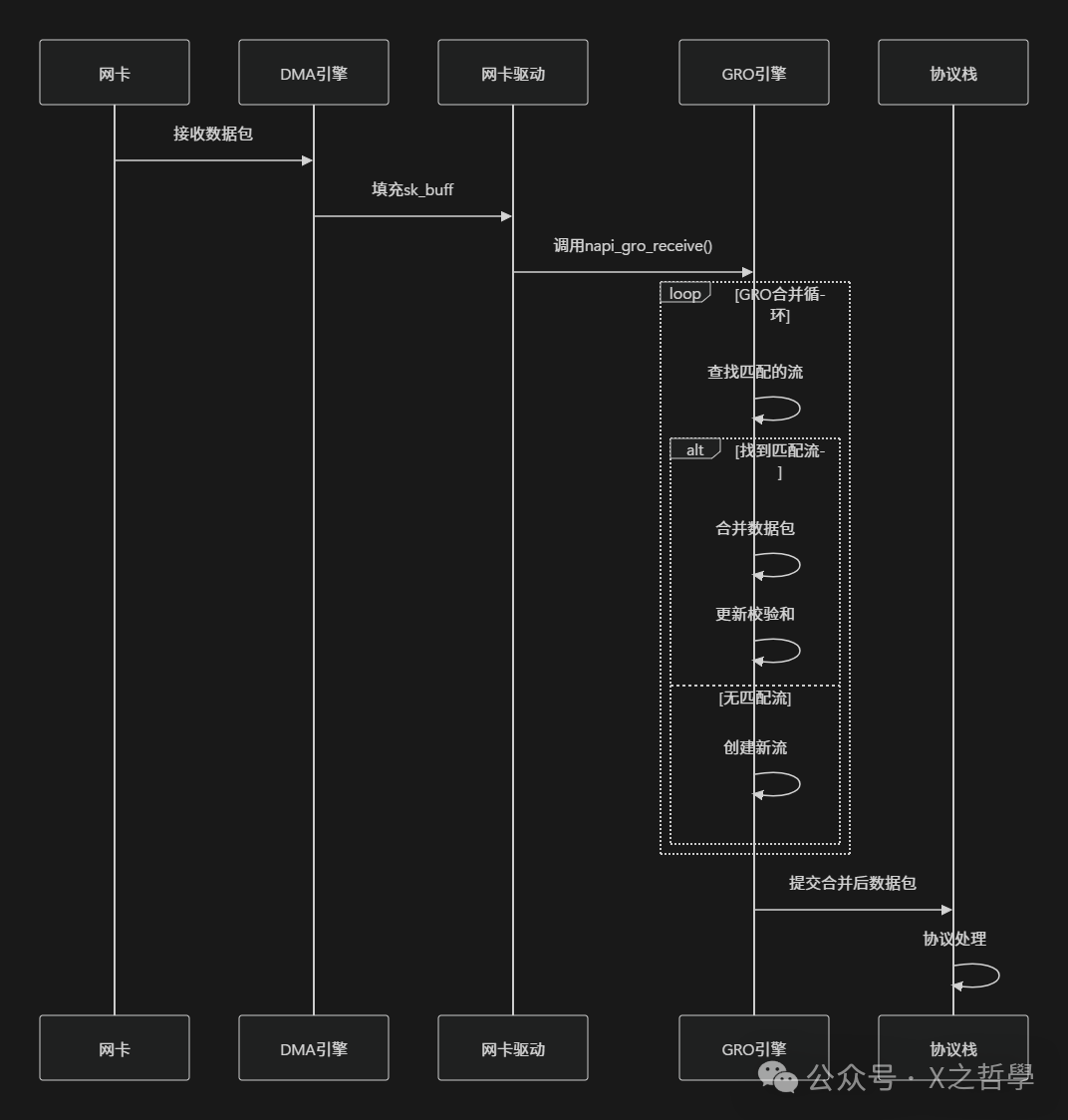
/* GRO接收处理的入口函数 */
gro_result_t napi_gro_receive(struct napi_struct *napi,
struct sk_buff *skb)
{
/* 调整skb内部指针,准备进行GRO处理 */
skb_gro_reset_offset(skb);
/* 根据网络层协议调用特定的GRO接收函数 */
switch (skb->protocol) {
case htons(ETH_P_IP):
return napi_gro_receive_iph(napi, skb);
case htons(ETH_P_IPV6):
return napi_gro_receive_ipv6(napi, skb);
default:
return dev_gro_receive(napi, skb);
}
}
/* TCP GRO合并的核心逻辑 */
static struct sk_buff *tcp_gro_receive(struct list_head *head,
struct sk_buff *skb)
{
struct sk_buff *pp = NULL;
struct sk_buff *p;
struct tcphdr *th;
struct tcphdr *th2;
/* 遍历现有的GRO列表,寻找可以合并的数据包 */
list_for_each_entry(p, head, list) {
if (!NAPI_GRO_CB(p)->same_flow)
continue;
th = tcp_hdr(p);
th2 = tcp_hdr(skb);
/* 核心检查:必须是同一个TCP连接,且序列号严格连续 */
if (*(u32 *)&th->source != *(u32 *)&th2->source ||
th->dest != th2->dest ||
th->seq + p->len != th2->seq) {
NAPI_GRO_CB(p)->same_flow = 0;
continue;
}
pp = p;
break;
}
if (pp) {
/* 找到匹配项,执行合并操作 */
return skb_gro_receive(head, skb);
}
/* 无匹配项,将此skb作为新流的起始添加到列表中 */
return skb;
}
四、代码框架与架构剖析
4.1 Linux网络协议栈中的卸载框架
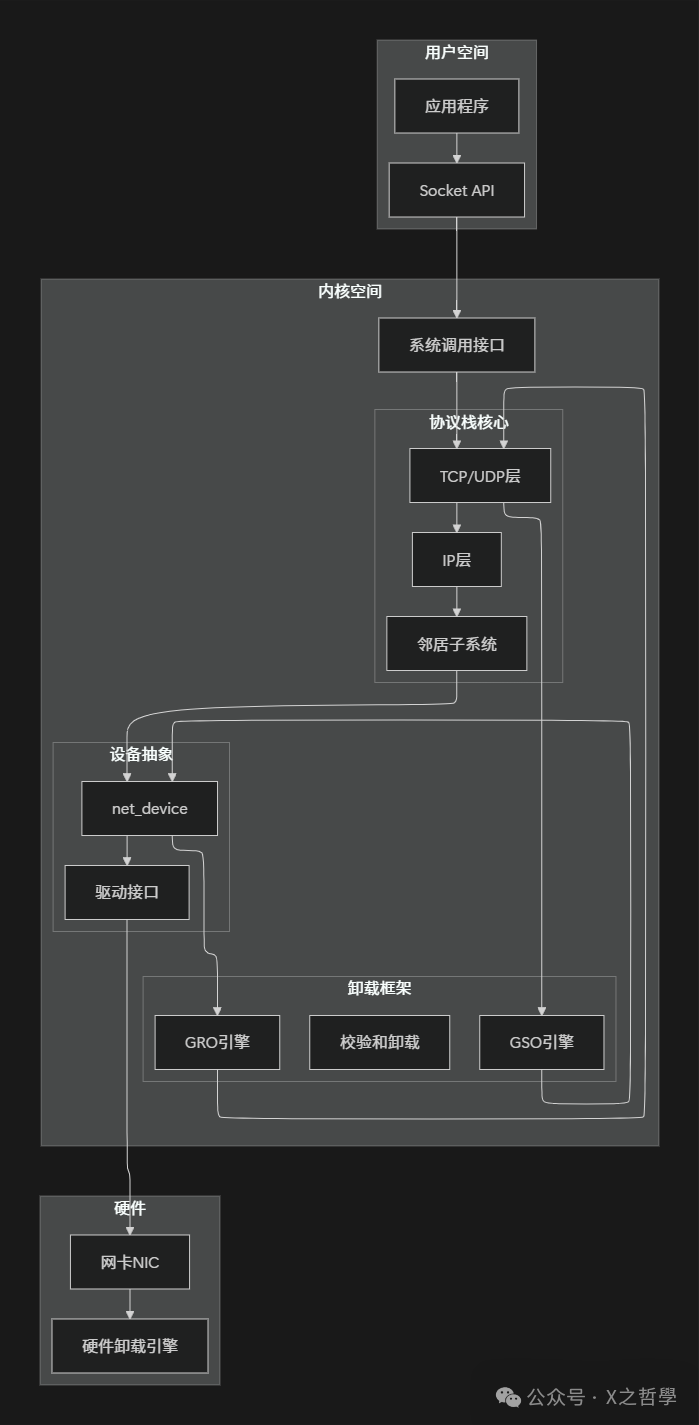
4.2 核心数据结构关系
网络设备的卸载能力通过一个位图特征字段来定义和协商。
/* 网络设备能力标志 - 64位位图 */
typedef u64 netdev_features_t;
/* 关键的卸载能力标志位定义 */
#define NETIF_F_TSO (1ULL << 18) /* 支持TCP分段卸载 */
#define NETIF_F_GSO (1ULL << 19) /* 支持通用分段卸载 */
#define NETIF_F_GRO (1ULL << 20) /* 支持通用接收卸载 */
#define NETIF_F_LRO (1ULL << 21) /* 支持大接收卸载 */
#define NETIF_F_HW_CSUM (1ULL << 24) /* 支持硬件校验和计算 */
#define NETIF_F_SG (1ULL << 26) /* 支持分散/聚集IO (Scatter/Gather) */
/* 网络设备结构体中相关的特性字段 */
struct net_device {
/* ... 其他字段 ... */
netdev_features_t features; /* 当前生效的特性 */
netdev_features_t hw_features; /* 硬件原生支持的特性 */
netdev_features_t wanted_features; /* 用户空间期望启用的特性 */
netdev_features_t vlan_features; /* VLAN接口继承的特性 */
/* ... */
};
4.3 卸载能力协商机制
内核会在驱动注册、用户配置等时机,检查并修正特性之间的依赖关系。
/* 特性自动修正与协商流程 */
static netdev_features_t netdev_fix_features(
struct net_device *dev,
netdev_features_t features)
{
/* 检查特性间的依赖关系 */
/* TSO需要硬件校验和卸载的支持 */
if (features & NETIF_F_TSO) {
if (!(features & NETIF_F_HW_CSUM)) {
features &= ~NETIF_F_TSO;
features &= ~NETIF_F_TSO6;
}
}
/* GSO是更通用的框架,需要Scatter/Gather IO支持 */
if (features & NETIF_F_GSO) {
if (!(features & NETIF_F_SG)) {
features &= ~NETIF_F_GSO;
}
}
/* 最终能力不能超过硬件实际支持的范围 */
features &= dev->hw_features;
return features;
}
五、实例实现:自定义简易卸载驱动
5.1 需求分析
我们通过一个简化的虚拟网卡驱动示例,来演示TSO/GRO的基本实现框架,这有助于理解内核与硬件协作的接口。
5.2 核心数据结构定义
/* 虚拟网卡驱动私有数据结构 */
struct virtnic_priv {
struct net_device *netdev;
/* 卸载能力标志 */
netdev_features_t supported_features;
/* 统计信息 */
u64 tso_packets;
u64 tso_segments;
/* DMA缓冲区 */
dma_addr_t dma_addr;
void *dma_buffer;
/* 发送队列 */
struct sk_buff_head tx_queue;
/* 延迟发送的工作队列 */
struct work_struct tx_work;
};
/* 驱动内部使用的TSO上下文描述符 */
struct virtnic_tso_ctx {
u32 ip_id; /* IP标识符,用于生成分片ID */
u32 tcp_seq; /* TCP序列号基值 */
u16 mss; /* 最大段大小 */
u8 total_segs; /* 总分段数 */
u8 curr_seg; /* 当前正在处理的分段索引 */
};
5.3 驱动初始化与特性声明
在驱动探测阶段,需要声明设备支持的各种卸载能力。
static int virtnic_probe(struct platform_device *pdev)
{
struct net_device *netdev;
struct virtnic_priv *priv;
/* 分配net_device结构体 */
netdev = alloc_netdev(sizeof(struct virtnic_priv),
"virtnic%d", NET_NAME_UNKNOWN,
ether_setup);
if (!netdev)
return -ENOMEM;
priv = netdev_priv(netdev);
/* 设置硬件支持的功能特性 */
netdev->hw_features = NETIF_F_SG | /* 分散聚集IO,是GSO的基础 */
NETIF_F_IP_CSUM | /* IPv4校验和卸载 */
NETIF_F_TSO | /* TCP分段卸载 */
NETIF_F_GSO; /* 通用分段卸载 */
/* 默认启用所有硬件支持的特性 */
netdev->features = netdev->hw_features;
/* 设置网络设备操作函数集 */
netdev->netdev_ops = &virtnic_netdev_ops;
/* 注册网络设备到内核 */
register_netdev(netdev);
return 0;
}
5.4 TSO发送处理实现
/* 驱动的数据包发送入口函数 */
static netdev_tx_t virtnic_start_xmit(struct sk_buff *skb,
struct net_device *dev)
{
struct virtnic_priv *priv = netdev_priv(dev);
/* 判断是否为需要TSO处理的大数据包 */
if (skb_is_gso(skb)) {
/* 进入TSO处理路径 */
return virtnic_transmit_tso(skb, dev);
} else {
/* 进入普通数据包发送路径 */
return virtnic_transmit_normal(skb, dev);
}
}
/* TSO分段处理核心函数 */
static netdev_tx_t virtnic_transmit_tso(struct sk_buff *skb,
struct net_device *dev)
{
struct virtnic_priv *priv = netdev_priv(dev);
struct virtnic_tso_ctx tso_ctx;
int seg_count, i;
/* 从skb中获取GSO信息 */
seg_count = skb_shinfo(skb)->gso_segs;
tso_ctx.mss = skb_shinfo(skb)->gso_size;
/* 根据原始数据包初始化TSO上下文(如获取初始序列号) */
virtnic_init_tso_ctx(skb, &tso_ctx);
/* 更新驱动统计信息 */
priv->tso_packets++;
priv->tso_segments += seg_count;
/* 循环处理每个分段 */
for (i = 0; i < seg_count; i++) {
struct sk_buff *seg_skb;
if (i == seg_count - 1) {
/* 最后一个分段可以直接使用原始skb */
seg_skb = skb;
} else {
/* 前面的分段需要克隆skb,共享数据区 */
seg_skb = skb_copy(skb, GFP_ATOMIC);
if (!seg_skb) {
/* 克隆失败,错误处理 */
break;
}
}
/* 更新TCP头中的序列号 */
tcp_hdr(seg_skb)->seq = htonl(ntohl(tcp_hdr(seg_skb)->seq) +
i * tso_ctx.mss);
/* 对于IPv4,更新IP头中的标识符和分片偏移量 */
if (ip_hdr(seg_skb)->version == 4) {
ip_hdr(seg_skb)->id = htons(ntohs(ip_hdr(seg_skb)->id) + i);
ip_hdr(seg_skb)->frag_off = htons(i * tso_ctx.mss >> 3);
}
/* 将处理好的分段提交给硬件发送函数 */
virtnic_transmit_segment(seg_skb, dev, &tso_ctx, i);
}
return NETDEV_TX_OK;
}
/* 从原始skb提取信息初始化TSO上下文 */
static void virtnic_init_tso_ctx(struct sk_buff *skb,
struct virtnic_tso_ctx *ctx)
{
struct iphdr *iph;
struct tcphdr *tcph;
if (skb_shinfo(skb)->gso_type & SKB_GSO_TCPV4) {
iph = ip_hdr(skb);
tcph = tcp_hdr(skb);
ctx->ip_id = ntohs(iph->id);
ctx->tcp_seq = ntohl(tcph->seq);
ctx->mss = skb_shinfo(skb)->gso_size;
ctx->total_segs = skb_shinfo(skb)->gso_segs;
ctx->curr_seg = 0;
}
}
5.5 GRO接收处理实现
/* 简化的GRO接收处理函数 */
static gro_result_t virtnic_gro_receive(struct napi_struct *napi,
struct sk_buff *skb)
{
struct virtnic_priv *priv = netdev_priv(napi->dev);
struct sk_buff *head = napi->gro_list;
/* 遍历现有的GRO列表,尝试合并 */
while (head) {
if (virtnic_can_gro_merge(head, skb)) {
/* 可以合并,执行合并操作 */
return virtnic_do_gro_merge(napi, head, skb);
}
head = head->next;
}
/* 无法与现有流合并,作为新流的头节点加入列表 */
skb->next = napi->gro_list;
napi->gro_list = skb;
skb->len = 0;
skb->data_len = 0;
return GRO_MERGED;
}
/* 判断两个skb是否属于同一个流且可以合并 */
static bool virtnic_can_gro_merge(struct sk_buff *skb1,
struct sk_buff *skb2)
{
struct iphdr *iph1, *iph2;
struct tcphdr *th1, *th2;
/* 检查IP层五元组是否匹配 */
iph1 = ip_hdr(skb1);
iph2 = ip_hdr(skb2);
if (iph1->saddr != iph2->saddr ||
iph1->daddr != iph2->daddr ||
iph1->protocol != iph2->protocol)
return false;
/* 如果是TCP,还需要检查端口号和序列号的连续性 */
if (iph1->protocol == IPPROTO_TCP) {
th1 = tcp_hdr(skb1);
th2 = tcp_hdr(skb2);
if (th1->source != th2->source ||
th1->dest != th2->dest ||
ntohl(th1->seq) + skb1->len != ntohl(th2->seq))
return false;
}
return true;
}
六、核心模型框架剖析
6.1 卸载技术决策树
内核根据数据包大小、网卡能力、系统配置等因素动态选择处理路径。
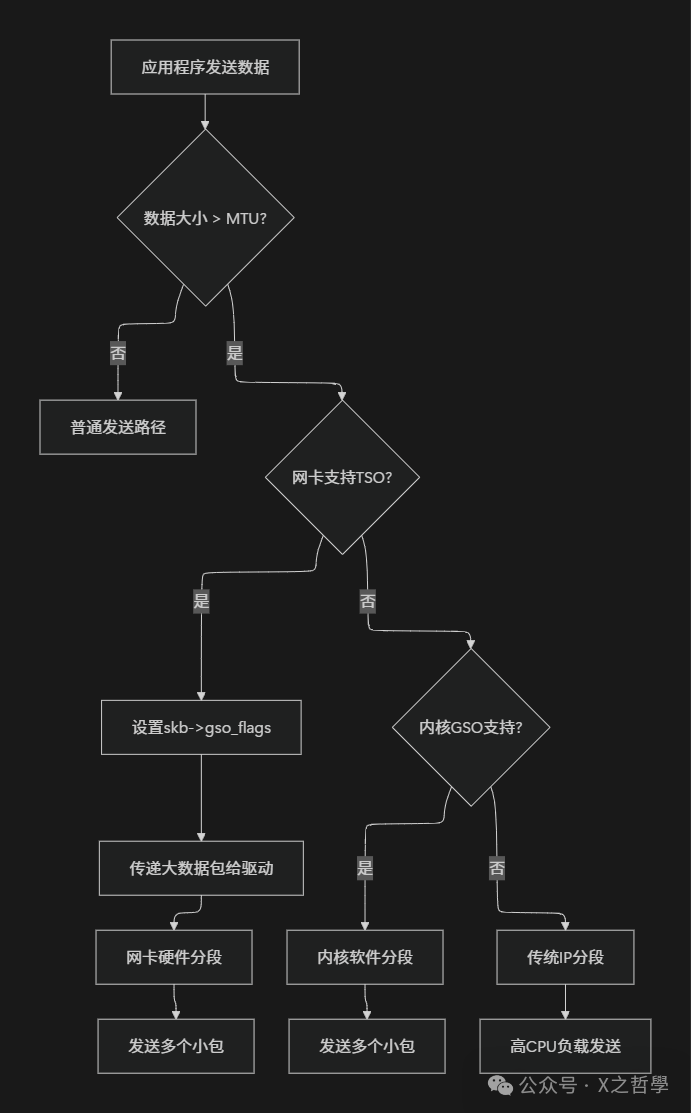
6.2 性能影响分析
| 场景 |
CPU使用率 |
吞吐量 |
延迟 |
适用场景 |
| 无卸载 |
高 |
低 |
高 |
小包、低带宽环境 |
| 硬件TSO |
低 |
高 |
低 |
大文件传输、视频流 |
| 软件GSO |
中 |
中 |
中 |
通用场景,或硬件不支持时 |
| 硬件GRO |
低 |
高 |
低 |
高负载接收、服务器 |
6.3 卸载与虚拟化
在虚拟化与云原生环境中,分段卸载技术变得更加复杂且关键。数据包需要穿越物理机、宿主机、虚拟机或容器多层网络栈。现代方案如SR-IOV、virtio-net with packed ring等,都在努力将卸载能力穿透到虚拟机内部,这对提升云原生/IaaS平台的整体网络性能至关重要。
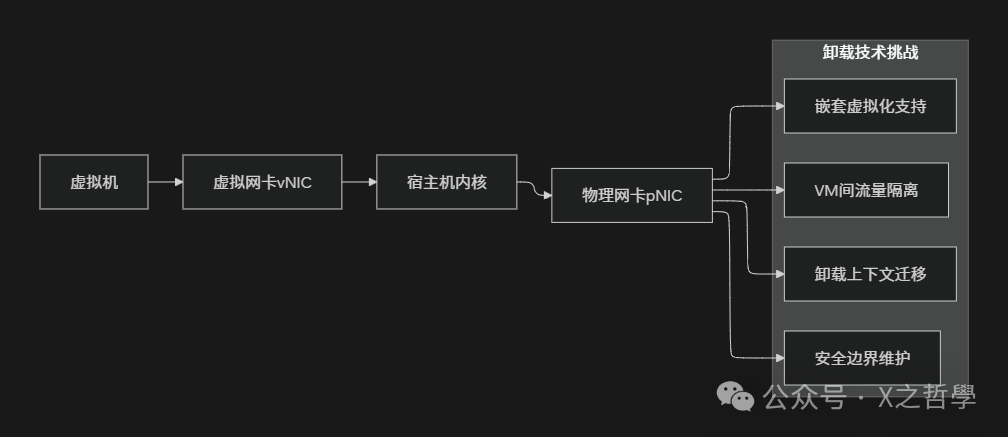
七、调试与监控工具
7.1 系统状态查看命令
# 查看指定网卡支持的卸载能力
ethtool -k eth0
# 输出示例:
# tcp-segmentation-offload: on
# tx-tcp-segmentation: on
# tx-tcp6-segmentation: on
# scatter-gather: on
# tx-scatter-gather: on
# tx-scatter-gather-fraglist: on
# 动态修改卸载设置(需要网卡支持)
ethtool -K eth0 tso on # 开启TSO
ethtool -K eth0 gro on # 开启GRO
ethtool -K eth0 gso off # 关闭GSO(不推荐)
# 查看网络接口统计信息,可观察包数量、错误等
cat /proc/net/dev
# 或使用ip命令
ip -s link show eth0
# 查看与GSO/GRO相关的内核参数
sysctl -a | grep -E "(gso|gro|tcp.*seg)"
7.2 性能测试工具
# 使用iperf3测试TSO效果
# 在服务器端启动
iperf3 -s
# 在客户端测试,使用大窗口和多线程模拟大流量
iperf3 -c server_ip -t 60 -P 4 -w 2M
# 使用netperf进行更详细的网络性能测试
# 启动netserver
netperf -H server_ip -t TCP_STREAM -l 30 -- -m 64K # 测试64KB大消息
# 使用perf工具分析CPU使用情况,观察协议栈开销是否降低
perf record -g -p $(pidof iperf3) -o perf.data
perf report -i perf.data
7.3 内核调试技巧
/* 在驱动代码中添加调试信息 */
#define VIRTNIC_DEBUG 1
#ifdef VIRTNIC_DEBUG
#define virtnic_dbg(fmt, ...) \
pr_debug("virtnic: %s: " fmt, __func__, ##__VA_ARGS__)
#else
#define virtnic_dbg(fmt, ...) do {} while (0)
#endif
/* 在关键函数中打印skb的GSO信息 */
static netdev_tx_t virtnic_start_xmit(struct sk_buff *skb,
struct net_device *dev)
{
virtnic_dbg("skb len=%u, gso_size=%u, gso_segs=%u\n",
skb->len,
skb_shinfo(skb)->gso_size,
skb_shinfo(skb)->gso_segs);
/* ... 实际处理逻辑 ... */
}
/* 使用内核动态调试功能,灵活控制打印开关 */
echo 'file virtnic.c +p' > /sys/kernel/debug/dynamic_debug/control
7.4 常见问题排查
| 问题现象 |
可能原因 |
排查命令 |
解决方案 |
| TSO不生效,CPU依然高 |
1. 网卡硬件不支持
2. 驱动程序未正确声明能力
3. 中间设备(如交换机)不支持巨帧 |
ethtool -k eth0 |
确认硬件规格,更新驱动,或尝试启用GSO |
| 启用卸载后性能反而下降 |
1. 分段大小(MSS)设置不合理
2. 应用本身发送的就是小包 |
ethtool -g eth0
抓包分析 |
调整TCP MSS,或仅在传输大块数据时启用 |
| 数据包丢失或重传增加 |
1. 网卡Ring Buffer不足
2. 中断合并过于激进 |
ethtool -g eth0
cat /proc/interrupts |
增大环缓冲区大小,调整中断合并参数 |
| 校验和错误 |
1. 软件和硬件校验和卸载配置冲突
2. 硬件Bug |
ethtool -k eth0 |
确保校验和卸载设置统一(全开或全关) |
八、高级主题与未来演进
8.1 智能网卡与DPU的卸载演进
现代智能网卡(SmartNIC)和数据处理单元(DPU)正将网络协议栈的更多功能卸载到硬件,包括隧道封装(VxLAN, Geneve)、加密、负载均衡甚至分布式拒绝服务攻击(DDoS)防护。在复杂的运维/DevOps场景下,合理利用这些高级卸载功能可以极大简化主机侧的网络配置与管理负担。
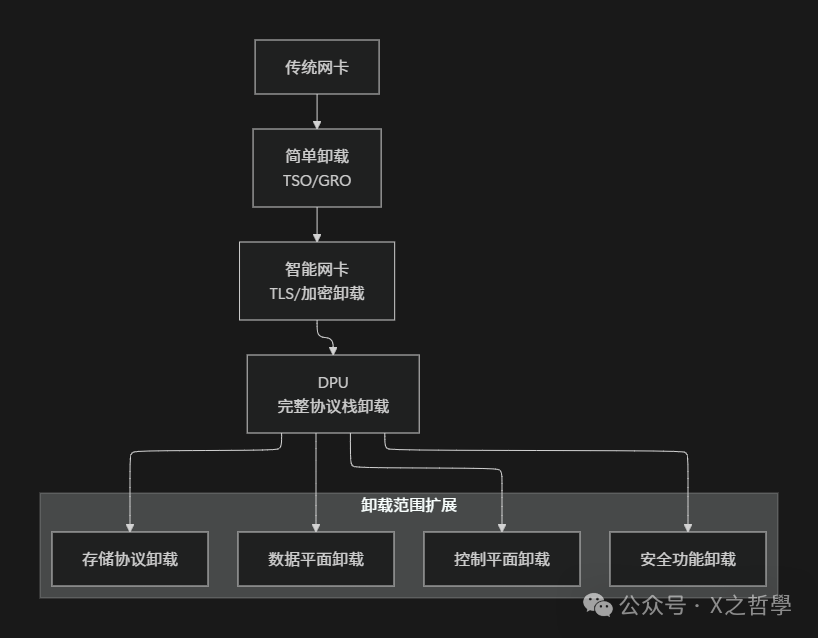
8.2 云原生环境中的卸载挑战
在Kubernetes等云原生环境中,分段卸载技术的应用需要考虑更多维度:
- 容器网络接口(CNI)兼容性:不同CNI插件对虚拟设备特性的支持程度不同。
- 服务网格的影响:Sidecar代理(如Envoy)会增加一跳,可能破坏端到端的TSO/GRO。
- 多租户隔离需求:需要确保卸载功能不会成为租户间安全或性能干扰的通道。
- 弹性伸缩:Pod的频繁创建销毁要求卸载状态能快速、正确地迁移和重建。
8.3 性能优化最佳实践
以下是一个简单的系统优化配置脚本示例,可用于高吞吐量服务器场景。
#!/bin/bash
# 网络性能优化脚本示例
# 1. 启用网卡卸载特性
ethtool -K eth0 tso on gro on gso on
# 增大环缓冲区以减少丢包
ethtool -G eth0 rx 4096 tx 4096
# 2. 优化内核TCP缓冲区参数
sysctl -w net.core.rmem_max=16777216
sysctl -w net.core.wmem_max=16777216
sysctl -w net.ipv4.tcp_rmem="4096 87380 16777216"
sysctl -w net.ipv4.tcp_wmem="4096 65536 16777216"
# 启用MTU路径发现,动态调整MSS
sysctl -w net.ipv4.tcp_mtu_probing=1
# 3. 其他TCP优化
sysctl -w net.ipv4.tcp_slow_start_after_idle=0 # 避免空闲后吞吐量下降
sysctl -w net.ipv4.tcp_notsent_lowat=16384 # 减少写缓冲区延迟
九、总结
9.1 技术价值回顾
Linux分段卸载技术通过硬件与软件的精妙协同,将原本由CPU负责的繁重数据包分段与重组工作,下放到更专业的网络硬件中执行。其核心价值体现在:
- 显著降低CPU负载:释放CPU周期用于处理业务逻辑。
- 大幅提升网络吞吐量:减少协议栈的逐包处理开销。
- 优化端到端延迟:减少内存拷贝和上下文切换次数。
- 改善系统整体能效:以更低的功耗获得更高的网络性能。
9.2 关键要点总结
| 技术维度 |
核心要点 |
实现机制 |
性能影响 |
| TSO |
发送端大包分段 |
硬件IP/TCP分段 |
显著降低发送CPU使用 |
| GSO |
通用分段框架 |
软件辅助硬件卸载 |
提供向后兼容与灵活性 |
| GRO |
接收端包合并 |
协议感知的包重组 |
大幅提升接收处理效率 |
| 实现核心 |
sk_buff结构扩展 |
特性协商框架 |
动态适配异构硬件能力 |
 发表于 2025-12-5 12:29:27
|
查看: 173|
回复: 0
发表于 2025-12-5 12:29:27
|
查看: 173|
回复: 0
