在高并发的秒杀或电商活动中,账户余额的扣减是最核心也是最容易出错的环节之一。想象一下,用户A和用户B同时抢购同一件商品,他们的账户都有100元,商品价格是50元。理论上,两个订单都该成功,用户余额应归零。但如果没有正确的并发控制,最终结果很可能是账户里还剩50元,钱无声无息地“消失”了。这就是典型的竞态条件(Race Condition) 问题,具体表现为丢失更新(Lost Update)。
为了应对这个挑战,我们需要深入理解不同的并发控制机制,并在复杂的秒杀架构中恰当地应用它们。本文将系统性地分析三种主流解决方案:悲观锁、乐观锁和Redis分布式锁,并结合秒杀系统的整体架构,为你提供从理论到实践的完整指南。
一、什么是竞态条件?
1.1 定义与问题场景
竞态条件是指:在多线程或分布式环境下,多个操作(如读取和修改)并发地访问和操作同一份共享数据(比如账户余额),最终结果的正确性依赖于这些操作执行的相对时序。如果时序控制不当,就会产生非预期的错误结果。
1.2 一个直观的例子
场景重现:
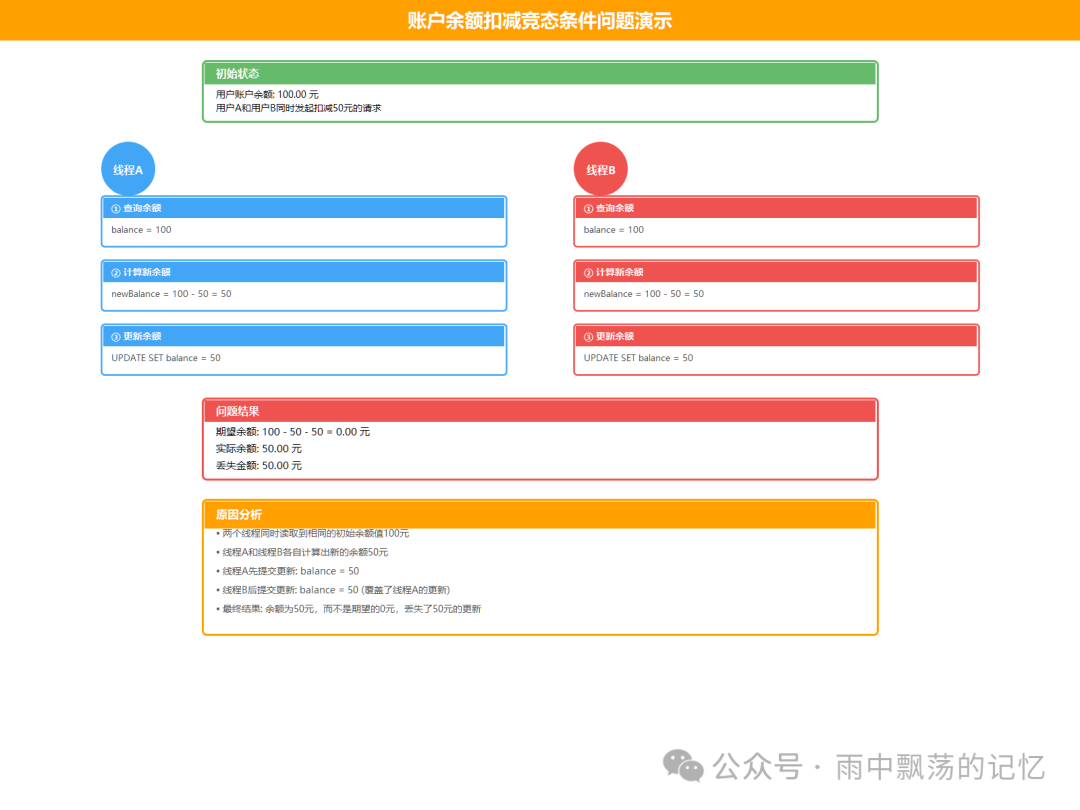
- 初始状态:用户账户余额 = 100元。
- 并发操作:线程A和线程B同时发起扣减50元的请求。
- 期望结果:100 - 50 - 50 = 0元。
- 可怕的实际结果:账户余额还剩50元,系统“丢失”了50元的扣减!
1.3 问题根源分析
为什么钱会“丢”?我们来拆解一下两个线程的执行时序:
- 线程A 读取余额:拿到100元。
- 线程B “同时”读取余额:也拿到了100元(此时线程A的计算结果还未写回数据库)。
- 线程A 计算新余额(100-50=50),并将50写回数据库。
- 线程B 计算新余额(100-50=50),也将50写回数据库。
- 结果:线程B的更新覆盖了线程A的更新,导致一次扣减完全失效。
这清晰地展示了在并发编程和分布式系统中,缺乏同步机制会导致数据一致性被破坏。
二、解决方案一:悲观锁
2.1 核心思想
悲观锁如其名,持一种“悲观”态度,它假设并发冲突一定会发生。因此,在访问目标数据(如某行账户记录)之前,会先将其“锁”住,阻止其他线程访问,直到当前操作完成。
核心口诀:先加锁,再操作。
2.2 数据库层面的实现
在关系型数据库如MySQL中,通常使用 SELECT ... FOR UPDATE 语句来获取行级排他锁。
-- 1. 开启事务后,查询并锁定这条用户账户记录
SELECT * FROM account WHERE user_id = 1 FOR UPDATE;
-- 2. 在锁的保护下,安全地更新余额
UPDATE account SET balance = balance - 50 WHERE user_id = 1;
-- 3. 提交事务,锁自动释放
COMMIT;
2.3 Java代码示例
在Spring框架中,可以结合 @Transactional 注解方便地实现。
@Transactional(rollbackFor = Exception.class)
public boolean deductBalancePessimistic(Long userId, Long amount) {
// 1. 查询并加锁(MyBatis-Plus示例,需确保Mapper方法支持加锁)
Account account = accountMapper.selectByIdForUpdate(userId);
// 2. 检查余额是否充足
if (account.getBalance().compareTo(amount) < 0) {
return false;
}
// 3. 扣减余额
account.setBalance(account.getBalance().subtract(amount));
return accountMapper.updateById(account) > 0;
}
2.4 优缺点与适用场景
优点:
- 简单直观:逻辑清晰,易于理解和实现。
- 强一致性:能彻底杜绝丢失更新问题。
- 高冲突场景有效:在数据争用严重时,能保证顺序执行。
缺点:
- 性能瓶颈:串行化操作导致并发性能低下,线程需要排队等待锁。
- 数据库压力大:大量的锁请求和等待会增加数据库连接和CPU开销。
- 死锁风险:不当的事务设计可能导致多个线程相互等待,形成死锁。
适用场景:
- 并发量相对不高,但业务逻辑复杂,需要严格保证数据正确的场景。
- 数据冲突概率非常高的写操作。
2.5 生产环境最佳实践
- 缩小锁粒度:尽量只锁定需要修改的那行数据,避免锁表。
- 控制事务时长:事务内只进行必要的数据库操作,将RPC调用、复杂计算等挪到事务之外。
- 使用批量操作:合并多个单行更新为批量更新,可以有效减少锁的竞争次数。
三、解决方案二:乐观锁
2.1 核心思想
乐观锁则持“乐观”态度,它假设并发冲突不常发生。因此,它允许多个线程同时读取数据,但在提交更新时,会检查在此期间数据是否被其他线程修改过。如果被修改过,则更新失败,通常需要重试。
核心口诀:先操作,提交时校验版本。
2.2 版本号机制实现
最常见的实现方式是在数据表中增加一个版本号字段(version)。
表结构设计:
CREATE TABLE account (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
balance DECIMAL(20,2) NOT NULL,
version INT NOT NULL DEFAULT 0, -- 乐观锁版本号
update_time DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
);
更新操作:
-- 基于版本号的CAS更新。只有当查询时的版本号与当前版本号一致时,更新才会成功。
UPDATE account
SET balance = balance - 50, version = version + 1
WHERE user_id = 1 AND version = 0; -- 假设我们读取时 version=0
如果这条SQL语句执行后返回的影响行数(affected rows)为0,说明在我们读取之后、更新之前,已经有其他线程成功更新了该记录(版本号变了),本次更新失败。
2.3 Java代码实现(带指数退避重试)
public boolean deductBalanceOptimistic(Long userId, Long amount) {
int maxRetries = 5;
int retryCount = 0;
while (retryCount < maxRetries) {
// 1. 查询账户(获取当前余额和版本号)
Account account = accountMapper.selectById(userId);
if (account.getBalance().compareTo(amount) < 0) {
return false; // 余额不足,直接返回
}
// 2. 准备更新对象,使用CAS(Compare And Set)思想
Account updateAccount = new Account();
updateAccount.setId(account.getId());
updateAccount.setBalance(account.getBalance().subtract(amount));
updateAccount.setVersion(account.getVersion()); // 设置期望的旧版本号
// 3. 尝试更新(MyBatis-Plus的updateById会基于id和version进行CAS更新)
int rows = accountMapper.updateById(updateAccount);
if (rows > 0) {
return true; // 更新成功!
}
// 4. 更新失败,说明版本号已变(发生冲突),进行重试
retryCount++;
try {
// 指数退避:等待时间随重试次数指数增长,避免活锁
Thread.sleep(Math.min(100L * (1L << retryCount), 1000L));
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
}
}
// 重试多次仍失败
return false;
}
2.4 优缺点与适用场景
优点:
- 高并发性能:读操作不上锁,极大提升了系统的吞吐量。
- 避免死锁:没有锁的获取和等待,从根本上杜绝了死锁。
- 数据库压力小:减少了锁竞争带来的数据库资源消耗。
缺点:
- 高冲突下性能差:如果冲突频繁,大量线程会陷入“读取-冲突-重试”的循环,CPU消耗在自旋上,性能反而下降。
- ABA问题:需要关注(可通过增加版本号或时间戳解决)。
- 实现复杂度:需要处理重试逻辑和失败回滚。
适用场景:
- 读多写少:这是乐观锁的理想场景。
- 并发量高,但实际的数据写入冲突率较低的场景。
- 业务系统能够接受一定概率的更新失败和重试。
2.5 生产环境最佳实践
- 动态重试策略:根据监控的历史冲突率,动态调整最大重试次数(如3-10次)。
- 快速失败与降级:在第一次冲突后,可以根据业务需求选择快速失败(返回“请重试”给用户),或将请求放入队列异步处理。
- 指数退避:重试间隔时间应采用指数增长策略,防止所有失败请求同时重试,引发雪崩。
四、解决方案三:Redis分布式锁
2.1 为什么需要分布式锁?
在单体应用中,使用JVM级别的锁(如synchronized或ReentrantLock)即可。但在微服务或分布式架构下,服务部署在多台机器上,JVM锁只能锁住当前进程,无法跨JVM、跨服务节点实现互斥。此时,就需要一个所有服务节点都能访问的外部协调系统来提供锁服务,Redis因其高性能和丰富的数据结构成为首选。
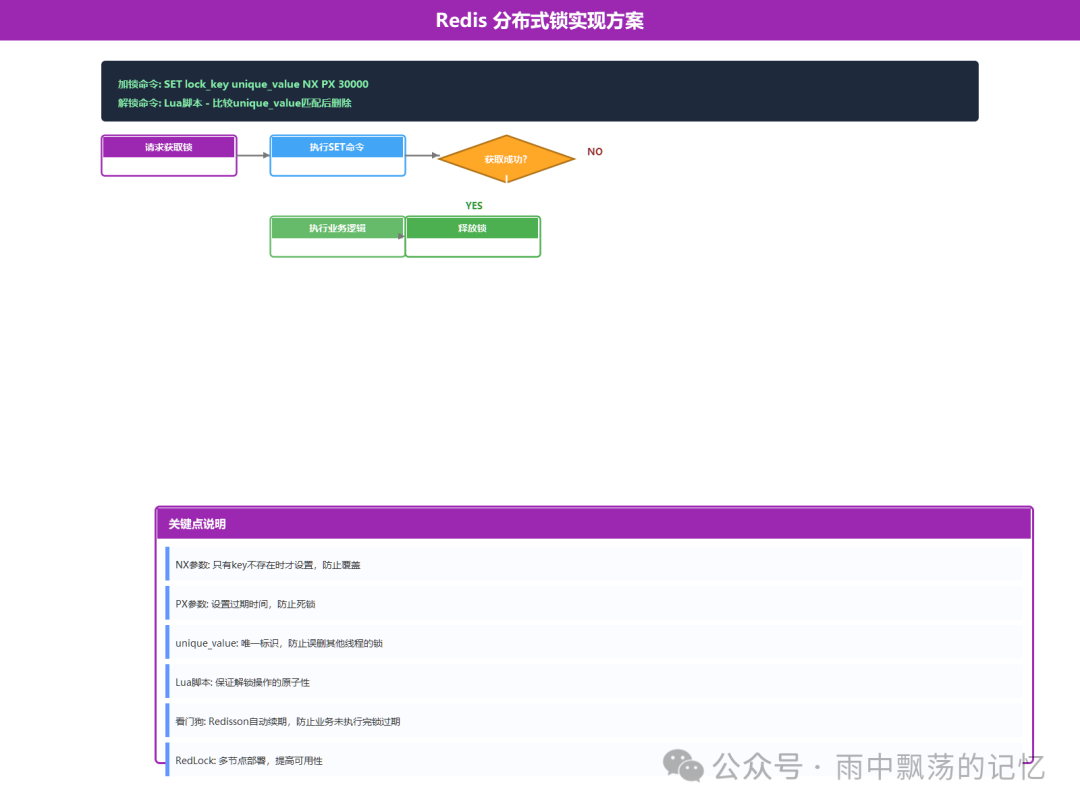
2.2 基于SET命令的实现
Redis从2.6.12版本开始,SET命令支持NX和PX参数,使得实现一个简单的分布式锁变得非常容易。
# 加锁命令:设置一个键值对,仅在键不存在时设置成功,并设置30秒的过期时间。
SET lock_key unique_value NX PX 30000
- NX:
Not eXists,只有lock_key不存在时才设置成功,确保互斥性。
- PX 30000:设置键的过期时间为30000毫秒,即使持有锁的客户端崩溃,锁也会自动释放,防止死锁。
- unique_value:必须是全局唯一的值(如UUID),用于标识加锁的客户端,避免误删其他客户端的锁。
2.3 解锁Lua脚本(保证原子性)
解锁操作必须是原子的:它需要检查锁的值是否属于自己,然后再删除锁。分两步(先GET再DEL)不是原子操作,中间可能发生锁过期并被其他客户端获取的情况,导致误删。必须使用Lua脚本。
-- KEYS[1] 是锁的key,ARGV[1] 是自己持有的 unique_value
if redis.call("get", KEYS[1]) == ARGV[1] then
return redis.call("del", KEYS[1])
else
return 0
end
2.4 Java代码实现(使用Redisson框架)
手动实现分布式锁需要考虑很多细节(如锁续期、可重入性等)。推荐使用成熟的客户端库,如Redisson。
@Autowired
private RedissonClient redissonClient;
public boolean deductBalanceWithDistributedLock(Long userId, Long amount) {
String lockKey = "account:lock:" + userId; // 锁粒度:按用户ID
RLock lock = redissonClient.getLock(lockKey);
boolean acquired = false;
try {
// 尝试获取锁:最多等待10秒,锁持有时间30秒(Redisson有看门狗自动续期)
acquired = lock.tryLock(10, 30, TimeUnit.SECONDS);
if (!acquired) {
return false; // 获取锁失败,可能系统繁忙
}
// 成功获取锁,执行业务逻辑
Account account = accountMapper.selectById(userId);
if (account.getBalance().compareTo(amount) < 0) {
return false;
}
account.setBalance(account.getBalance().subtract(amount));
return accountMapper.updateById(account) > 0;
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
return false;
} finally {
// 确保只有持有锁的当前线程才释放锁
if (acquired && lock.isHeldByCurrentThread()) {
lock.unlock();
}
}
}
2.5 Redis分布式锁关键要点
- 互斥性与NX:确保同一时刻只有一个客户端能持有锁。
- 防死锁与PX:必须设置过期时间。
- 防误删与唯一值:解锁时必须验证锁的持有者。
- 原子性操作:加锁(SET)和解锁(GET+DEL)都必须是原子的。
- 锁续期(看门狗):Redisson等框架提供的机制,防止业务执行时间超过锁过期时间。
- 高可用与RedLock:在Redis集群模式下,为了更高的可靠性,可以考虑使用RedLock算法(存在争议,需谨慎评估)。
2.6 生产环境最佳实践
- 合理设置超时:锁的持有时间应略大于业务平均执行时间的3-5倍,并配合看门狗。
- 锁粒度要细:例如按
用户ID加锁,比按整个“账户服务”加锁并发度高得多。
- 完备的监控:监控锁的等待时间、持有时间、获取失败率等指标,设置告警。
五、三种方案的详细对比
该如何选择?没有银弹,只有最适合的场景。下面的对比图和数据表可以帮你做出决策。
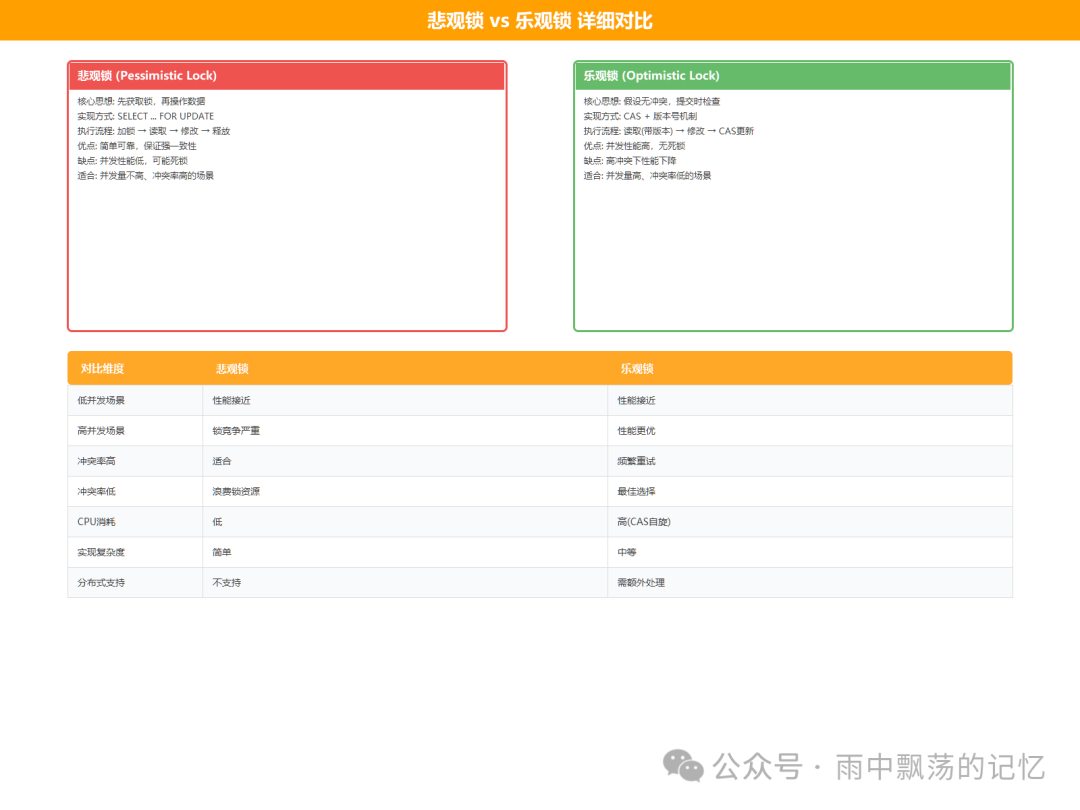
| 对比维度 |
悲观锁 |
乐观锁 |
Redis分布式锁 |
| 核心思想 |
先加锁,后操作 |
先操作,提交时校验 |
借助外部存储实现跨进程互斥 |
| 实现复杂度 |
简单 |
中等(需处理重试) |
中等(推荐使用成熟客户端) |
| 并发性能 |
差(串行) |
优(无锁读) |
中(有网络开销) |
| 冲突率高时 |
适合(顺序执行) |
差(频繁重试) |
适合(排队等待) |
| 冲突率低时 |
浪费资源(锁竞争) |
最佳选择 |
性能尚可 |
| 死锁风险 |
有 |
无 |
无(有过期时间) |
| 分布式支持 |
不支持(单DB) |
需额外设计(如全局版本号) |
原生支持 |
| 一致性强度 |
强一致性 |
最终一致性(需重试) |
强一致性 |
| 典型应用层 |
数据库层 |
数据库层/应用层 |
应用层/服务层 |
六、在秒杀系统架构中的综合应用
在真实的秒杀系统中,我们不会只使用一种锁,而是根据不同的子业务特点,组合多种技术,形成一套分层、异步、柔性的高性能架构。
6.1 秒杀系统核心架构
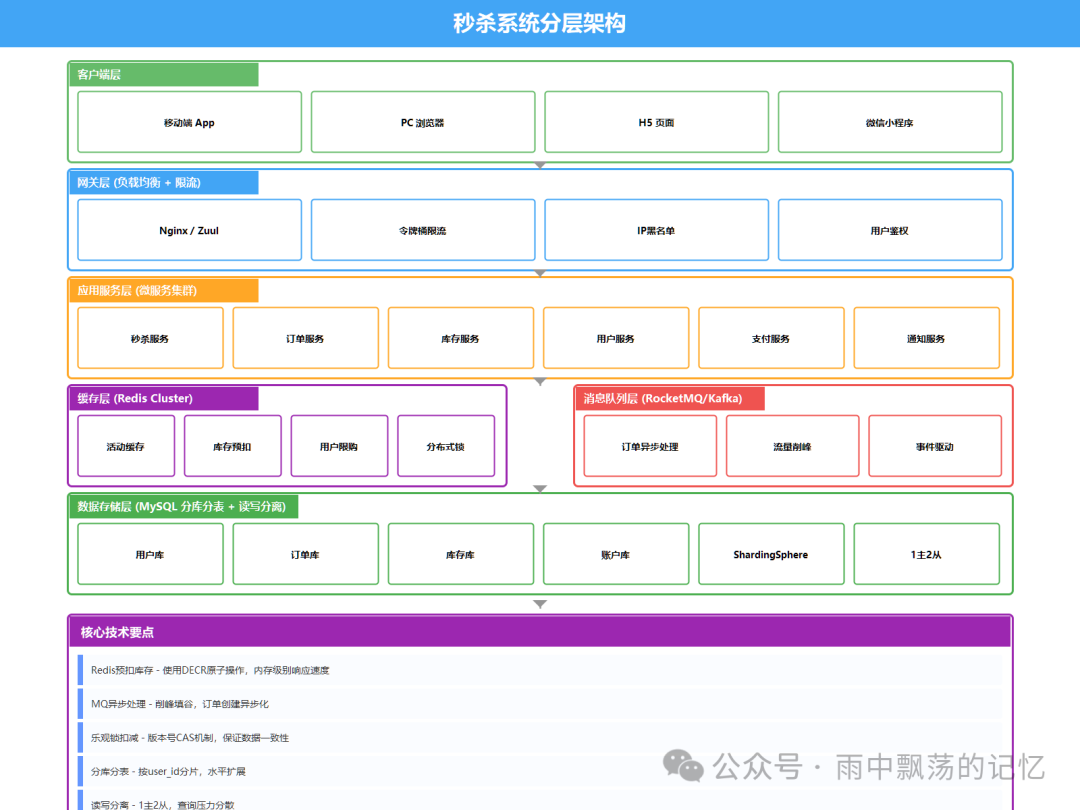
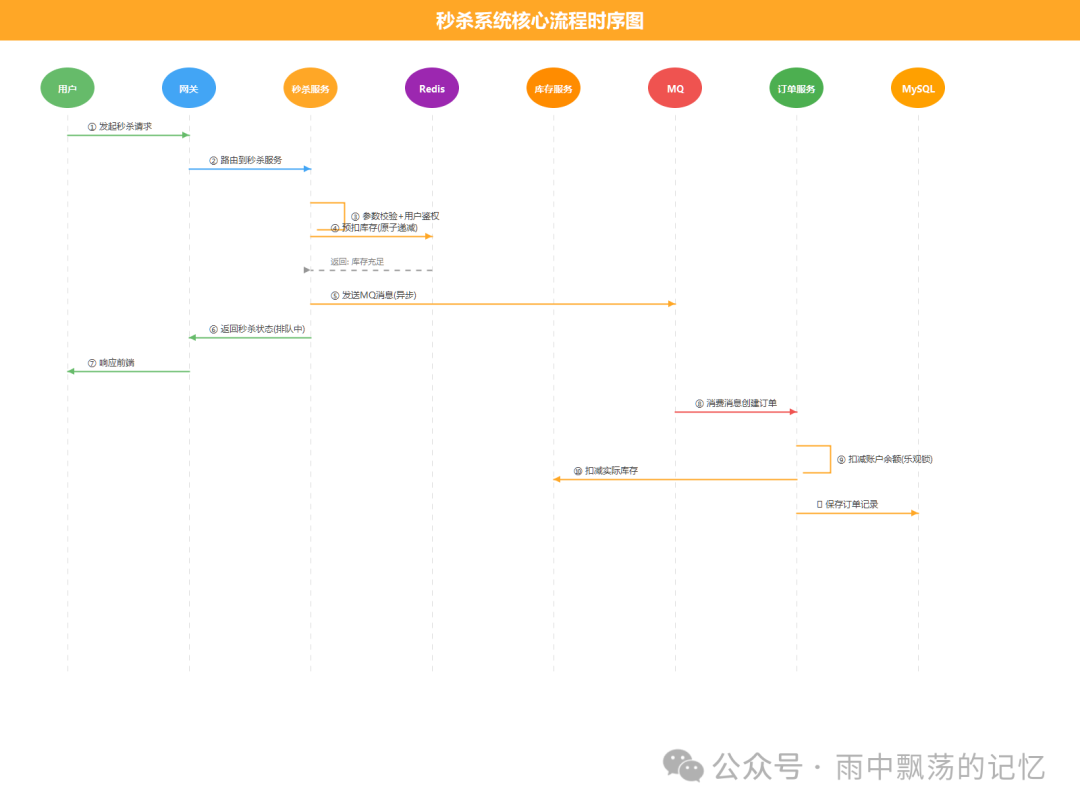
核心设计思路是“前端限流、中间异步、后端批量”:
- Redis预扣库存:使用
DECR 原子操作,在内存中完成秒杀资格的校验,响应极快。
- MQ异步处理:将订单创建、数据库扣减等耗时操作异步化,削峰填谷。
- 乐观锁扣减:在异步处理环节进行最终的账户余额、实际库存扣减,保证数据一致性。
- 分库分表 & 读写分离:解决数据存储层的瓶颈。
6.2 秒杀核心流程伪代码
public SeckillResult doSeckill(Long userId, Long activityId, Integer quantity) {
// 1. 校验活动状态、用户限购等(从Redis缓存读取)
// 2. **关键步骤:Redis原子预扣库存**
String stockKey = "seckill:stock:" + activityId;
Long remainingStock = redisTemplate.opsForValue().decrement(stockKey, quantity);
if (remainingStock == null || remainingStock < 0) {
// 库存不足,回滚预扣
redisTemplate.opsForValue().increment(stockKey, quantity);
return SeckillResult.fail("库存不足");
}
// 3. 记录用户已购买(防超卖)
// 4. **关键步骤:发送MQ消息,将订单创建请求异步化**
sendOrderMessage(userId, activityId, quantity);
// 5. 立即返回“秒杀排队中”结果给前端
return SeckillResult.success("秒杀请求已接受,正在创建订单...");
}
// MQ消费者:处理订单创建
@RabbitListener(queues = "order.queue")
public void processOrderMessage(OrderMessage message) {
// 1. 创建订单记录(Order表)
// 2. **关键步骤:使用乐观锁扣减账户余额(如本章第三节所示)**
boolean deductSuccess = deductBalanceOptimistic(message.getUserId(), message.getAmount());
if (!deductSuccess) {
// 扣减失败,需要触发订单取消、库存回滚等补偿事务
handleCompensation(message);
return;
}
// 3. 扣减实际库存(同样可用乐观锁)
// 4. 更新订单状态为“待支付”
}
6.3 秒杀流程时序图
七、高性能高可用架构深化
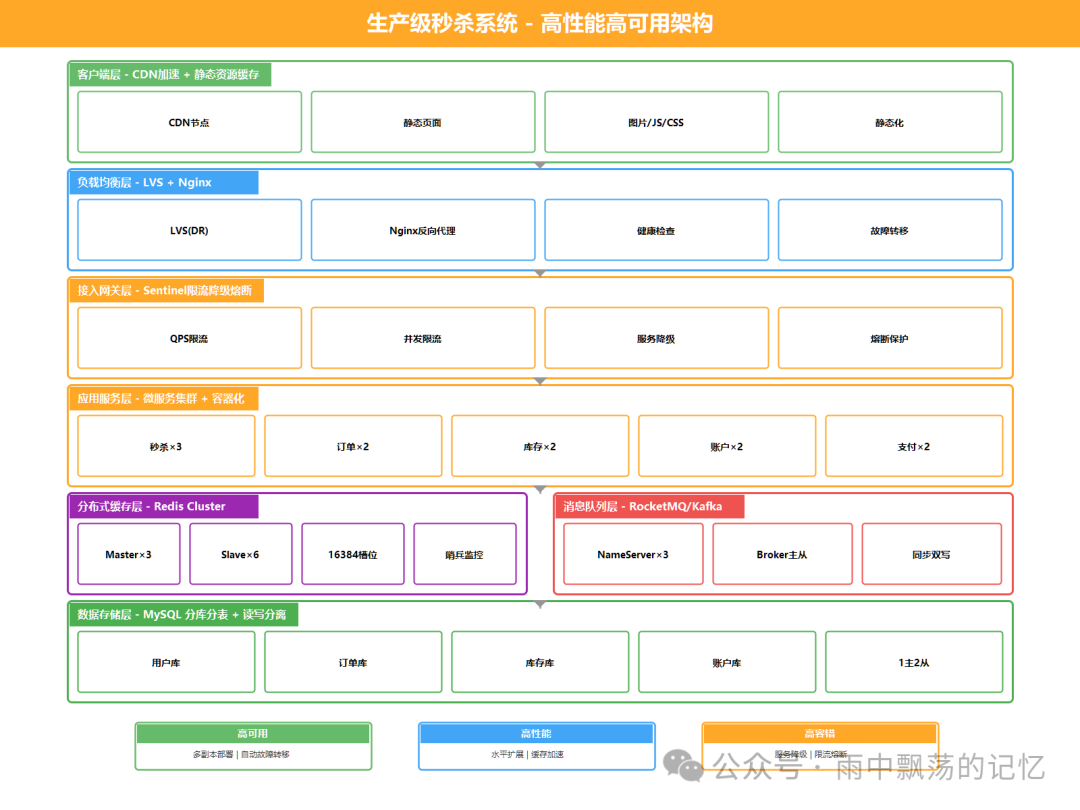
7.1 多级缓存与库存分桶
为了应对极致并发,可以进一步优化:
- 多级缓存:本地缓存(Caffeine/Ehcache) + 分布式缓存(Redis) + 数据库。
- 库存分桶:将10000件商品库存分成10个桶(每个桶1000件),用户秒杀时随机扣减某个桶。这可以将一个热点Key的竞争压力分散到10个Key上,显著提升并发能力。
// 库存预热:分桶
for (int i = 0; i < 10; i++) {
String bucketKey = "seckill:stock:" + activityId + ":bucket:" + i;
redisTemplate.opsForValue().set(bucketKey, totalStock / 10);
}
// 秒杀时:随机选桶扣减
int bucketIndex = ThreadLocalRandom.current().nextInt(10);
String bucketKey = "seckill:stock:" + activityId + ":bucket:" + bucketIndex;
redisTemplate.opsForValue().decrement(bucketKey, quantity);
7.2 生产级部署架构
八、监控、熔断与降级最佳实践
任何系统都不能保证100%可用,必须有自我保护机制。当余额扣减服务因数据库慢查询、网络抖动等原因变得不稳定时,熔断器应快速介入,防止故障蔓延导致系统雪崩。
8.1 熔断降级策略
使用如Resilience4j或Sentinel实现熔断器,核心配置包括:
- 失败率阈值:例如50%,过去N次调用中失败率达到此值则触发熔断。
- 慢调用阈值:例如3秒,超过此时间的调用计为慢调用。
- 半开状态试探:熔断一段时间后,进入半开状态,允许少量请求通过,试探后端是否恢复。
8.2 带熔断保护的余额扣减服务
@Service
public class SeckillServiceWithCircuitBreaker {
@Autowired
private CircuitBreakerRegistry circuitBreakerRegistry;
private final ConcurrentHashMap<Long, AtomicInteger> pendingQueue = new ConcurrentHashMap<>();
public boolean deductBalanceWithCircuitBreaker(Long userId, Long amount) {
CircuitBreaker circuitBreaker = circuitBreakerRegistry.circuitBreaker("balanceDeduct");
return Try.of(() -> {
// 如果熔断器已打开,直接执行降级逻辑
if (circuitBreaker.getState() == CircuitBreaker.State.OPEN) {
log.warn("熔断器开启,转入降级策略");
return fallbackToQueue(userId, amount);
}
// 正常调用业务方法
return doDeductBalance(userId, amount);
}).recover(throwable -> {
// 调用发生异常,执行降级
log.error("扣减服务调用异常,降级处理", throwable);
return fallbackToQueue(userId, amount);
}).get();
}
// 降级策略:将扣减请求存入待处理队列,后续异步补偿
private boolean fallbackToQueue(Long userId, Long amount) {
log.info("请求进入降级队列, userId:{}, amount:{}", userId, amount);
pendingQueue.computeIfAbsent(userId, k -> new AtomicInteger(0)).addAndGet(amount.intValue());
return true; // 先告诉用户“已接受请求”
}
// 后台定时任务,处理队列中的补偿请求
@Scheduled(fixedDelay = 60000)
public void processPendingQueue() {
pendingQueue.forEach((userId, amountAtomic) -> {
try {
if (doDeductBalance(userId, amountAtomic.longValue())) {
pendingQueue.remove(userId);
log.info("补偿扣减成功, userId:{}", userId);
}
} catch (Exception e) {
log.error("补偿扣减失败, userId:{}", userId, e);
}
});
}
}
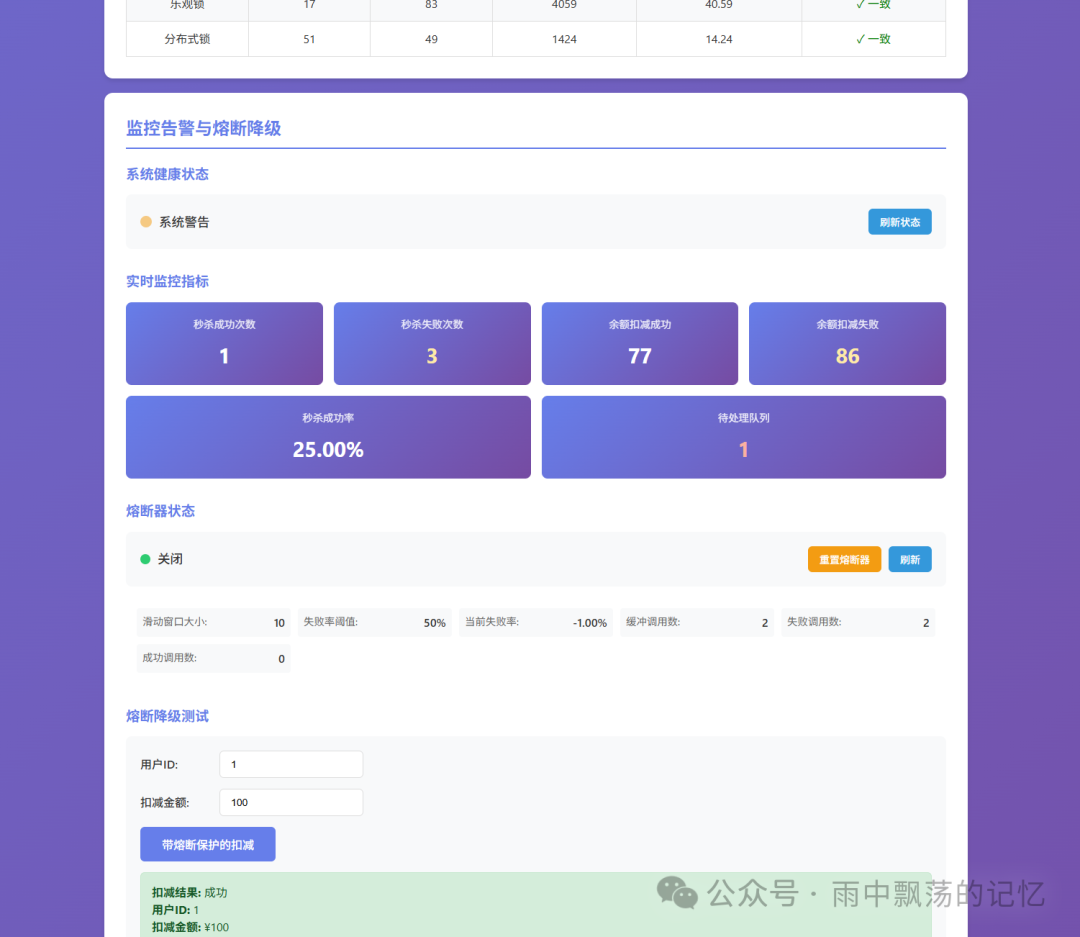
8.3 监控面板
一个直观的监控面板对于运维至关重要,它应能实时展示:
- 系统健康状态(开启/关闭/半开)。
- 核心指标:秒杀成功/失败次数、余额扣减成功率、当前QPS。
- 熔断器详细状态(滑动窗口失败率、调用次数等)。
九、总结与选型建议
经过以上分析,我们可以得出清晰的选型指南:
| 应用场景 |
推荐方案 |
核心理由 |
| 单机低并发,强一致业务 |
悲观锁 (SELECT FOR UPDATE) |
实现简单,保证绝对强一致,适合后台管理、银行转账等。 |
| 单机高并发,读多写少 |
乐观锁 (版本号/CAS) |
最大化读性能,无锁竞争,适合商品库存、账户余额(非秒杀热点)扣减。 |
| 分布式系统,跨服务互斥 |
Redis分布式锁 |
解决JVM锁无法跨进程的问题,适合分布式定时任务、全局配置更新。 |
| 极致并发秒杀场景 |
组合方案:Redis原子操作 + MQ异步 + 乐观锁 |
利用Redis扛住瞬时读并发,MQ异步化写操作,数据库层用乐观锁保证最终一致。这是经过验证的高性能方案。 |
| 性能数据参考(模拟测试环境): |
锁类型 |
平均耗时 |
吞吐量 (QPS) |
适用场景 |
| 悲观锁 |
~250 ms |
约 400 |
低并发强一致 |
| 乐观锁 |
~80 ms |
约 1200+ |
高并发低冲突 |
| Redis分布式锁 |
~150 ms |
约 600-800 |
分布式协调 |
最终建议
设计系统时,不要拘泥于一种方案。分层和折衷是架构的艺术。在秒杀这样的复杂场景中:
- 入口层:用Redis原子操作做最快速的资格校验。
- 服务层:用消息队列解耦,实现异步化和削峰。
- 数据层:根据业务特性(冲突概率、一致性要求)为不同的数据(商品库存、账户余额、订单状态)选择合适的锁机制。
希望本文提供的从问题剖析到解决方案,再到架构集成的完整视角,能帮助你在云栈社区的交流与实践中,设计出更稳健、高性能的并发系统。记住,理解原理,结合实际,灵活运用,才是应对高并发挑战的不二法门。
 发表于 2026-2-11 10:48:36
|
查看: 276|
回复: 0
发表于 2026-2-11 10:48:36
|
查看: 276|
回复: 0
