纵观人工智能的发展历程,其核心驱动力的演进史,本质上是数据如何被策略性利用的变革史。
每一次范式的跃迁,不仅拓展了前一阶段的数据驱动方式,更演化出新的数据利用方法,从而推动模型能力实现质的飞跃。
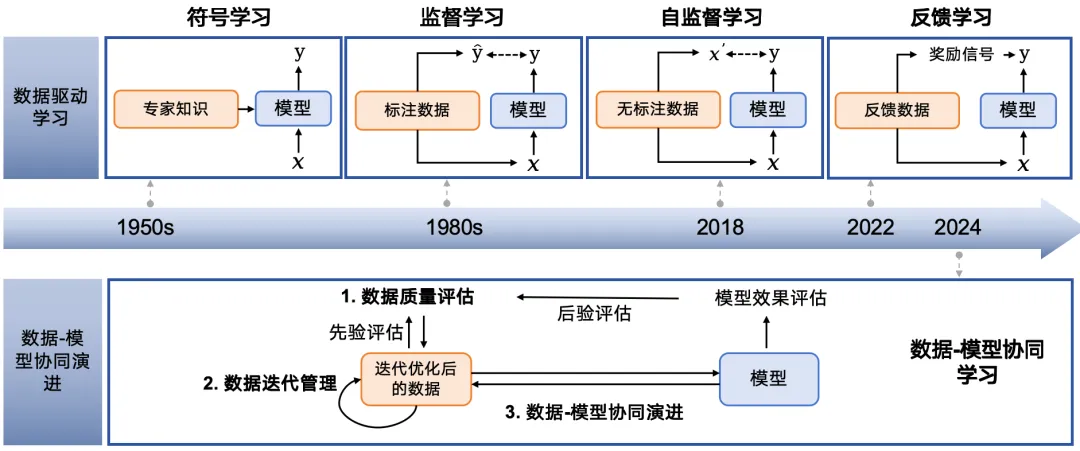
数据驱动策略与利用方式演进示意图
目前,通用人工智能的发展经历了从符号学习、有监督学习、无监督学习到反馈学习的四个阶段。回顾这些阶段,现有的主流范式是“数据驱动学习”,即通过不断扩张数据规模来单向驱动模型性能提升。
但随着模型自身能力的增强,我们认为人工智能的发展正迈入一个崭新的阶段——“数据-模型协同演进”。这个阶段将形成一个良性的闭环:模型能力可以反过来指导数据治理,而高质量的数据又能进一步优化模型性能。
为适应这一范式转变,清华大学自然语言处理实验室、面壁智能与OpenBMB联合发布了模型驱动的 L0-L4 数据分级治理体系,旨在为迈向通用人工智能提供系统化的数据科学支撑。
为了验证这套分级治理体系的有效性,研究团队在英文网页、中文网页、数学、代码四个核心领域进行了系统性实验。实验结果清晰地表明:模型性能随着数据质量从L1向L3的逐级提升而持续增强。
在实验过程中,团队系统性地构建了 UltraData-Math——一个面向数学领域的大规模、高质量预训练数据集。该数据集包含了当前开源范围内规模最大的高质量L3数学合成数据,并在多个评测基准上表现优异,为数学垂直领域的数据治理提供了前沿范式。
为了构建更开放的数据治理社区生态,团队推出了 UltraData 开放社区网站。该网站系统地整理了如UltraChat、UltraFeedback等前期的高质量数据工作,并开源了实验过程中产生的总计 2.4T Tokens 的数据以及 4项 核心数据治理工具。
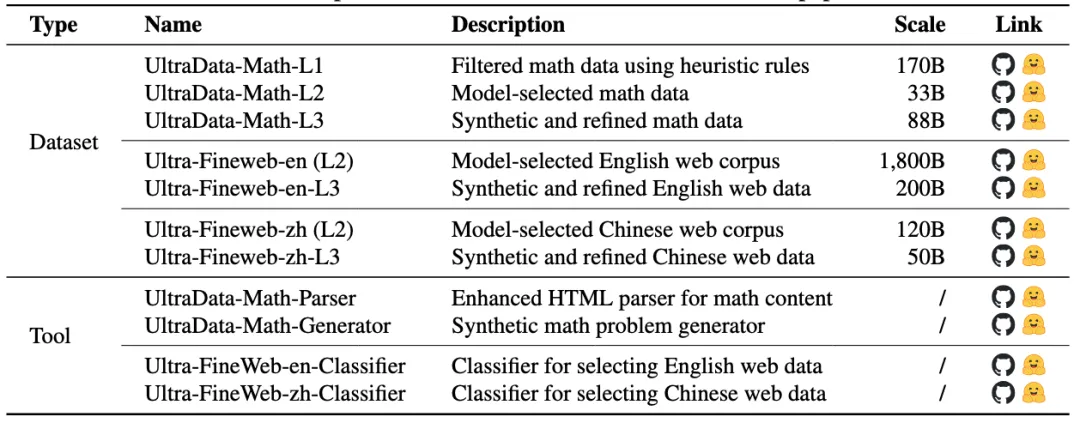
开源数据与工具清单
项目地址
UltraData 数据分级治理体系
现有的数据治理方法往往只关注特定的处理任务,例如数据过滤、筛选或编辑。然而,这些孤立的方法难以满足大语言模型在全生命周期训练中的系统性需求。
构建一套系统性的数据治理体系,主要基于三大动机:
- 高质量公开数据资源趋于枯竭:未来模型的演进无法再单纯依赖数据规模的野蛮增长,数据科学必须从粗放式扩张转向精细化治理,以挖掘存量数据的深层价值。
- 模型训练阶段的差异化需求:模型在不同训练阶段(如预训练知识注入、微调指令对齐)对数据的质量、数量和分布特征要求不同,需要针对性地构建训练数据。
- 成本与收益的动态平衡:数据治理需要在投入成本与模型收益之间寻求最优解。前期使用轻量低成本方法(如规则过滤),后期在关键训练节点投入高价值数据,以最大化数据的边际效应。
基于上述动机,研究团队构建了L0-L4五级数据分级体系,让数据处理更具靶向性。
从原始数据(L0)开始,经过基础过滤(L1)、模型精筛(L2)、合成与增强(L3),最终成为可直接用于编排的数据(L4)。每一级都对应明确的处理标准和应用场景,避免了“一刀切”的粗放加工,旨在最大化每单位数据的训练价值。
各层级的核心定义与应用如下:
- L0 - 原始数据:未经实质性处理的初始数据(PB级),包含大量噪声与重复内容,经采集解析后作为底层储备,不直接用于训练。代表:Common Crawl网页、PDF文档。
- L1 - 过滤数据:经过启发式规则过滤、去重等基础清洗的数据,格式规范但语义质量不均,为后续处理提供基础资源。代表:FineWeb、DCAD。
- L2 - 精筛数据:通过模型打分、标签标注等方式筛选出的高信息密度数据,领域明确、逻辑连贯,对模型能力提升贡献显著。代表:Ultra-FineWeb、FineWeb-edu。
- L3 - 合成与增强数据:经过改写、合成或人工标注的结构化数据,语义清晰、质量优异,适配Mid-Training、SFT、RL等高阶训练阶段。代表:UltraChat、UltraFeedback。
- L4 - 编排数据:经过整理、可信校验、统一编排的有序数据,结构清晰、可检索,可直接支持RAG等应用。代表:Wikidata、UltraData-Arxiv。
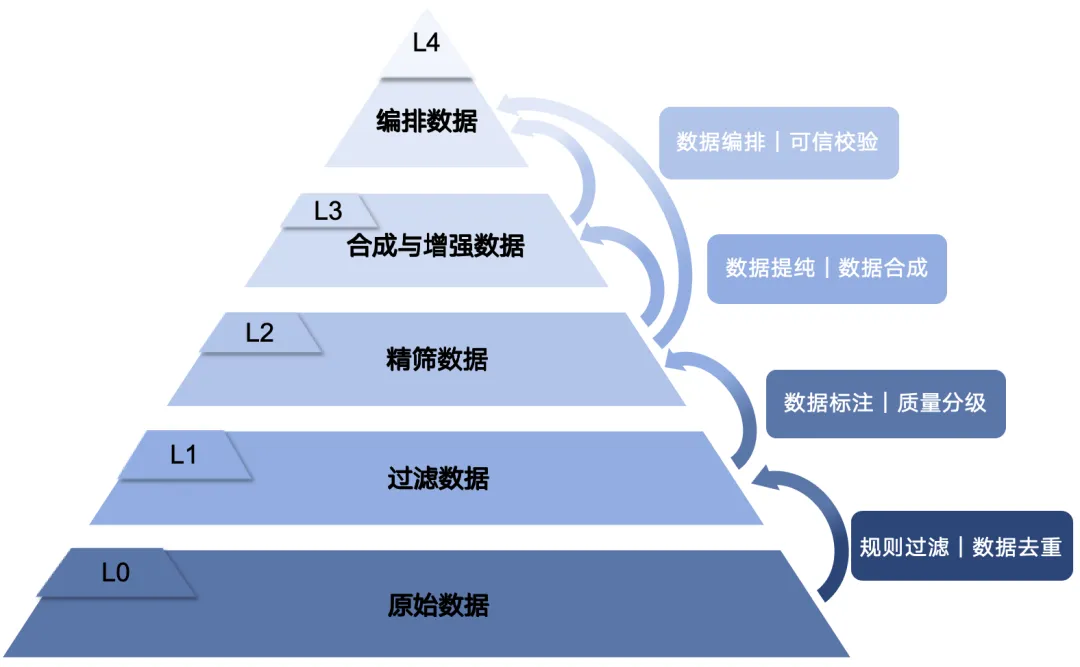
分级治理体系示意图
分级体系有效性验证
研究团队设计了充分的实验来验证该分级体系的有效性。实验选取了英文网页、中文网页、数学、代码四个领域中L1至L3的代表性数据,在 MiniCPM-1.2B 模型上,对每个单一数据源采样 10B Tokens 进行快速质量验证。
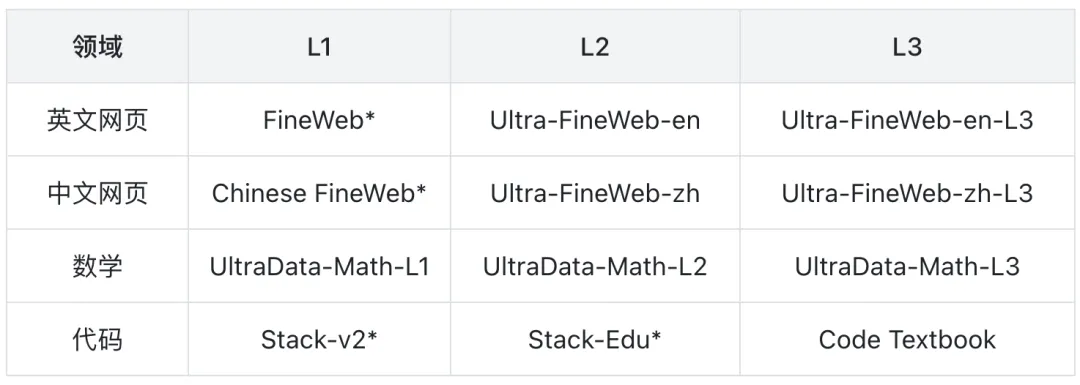
L1-L3 实验数据选择(标为开源数据)*
实验结果如下表所示。在不同领域中,模型性能从L1到L3呈现出清晰且一致的提升趋势。这验证了所提出的分级数据治理体系能够有效刻画具有实际意义的数据质量分层。
L3 > L2 > L1 的严格性能层级关系在所有实验中均成立。这些结果证明了即使在训练预算受限的验证设置下,分级治理体系依然能产生清晰稳定的性能提升信号。
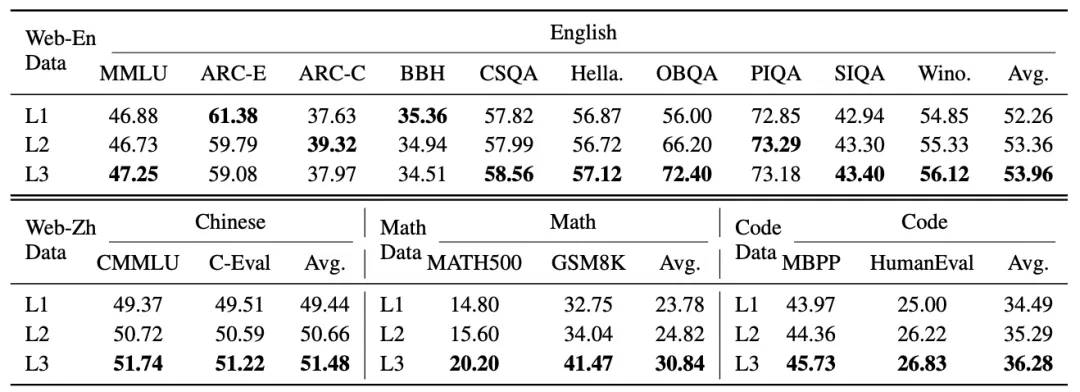
L1-L3 数据分别在英语网页、中文网页、数学和代码领域训练结果
基于分级治理体系的多阶段模型训练
为了验证分级治理体系对完整训练过程的动态影响,团队设计了一组对比实验,评估 混合训练 与 分级训练 两种策略的性能差异。
实验混合了四个领域的数据,并固定配比(50%英文网页,25%中文网页,7%数学,18%代码),在 MiniCPM-1.2B 模型上从头训练总计 120B Tokens。
- 混合训练策略:采用单阶段训练,将L1、L2、L3数据按1:1:1比例混合为一个统一的数据池进行训练。
- 分级训练策略:将训练划分为三个连续的阶段,每阶段训练40B Tokens,依次使用L1、L2、L3数据进行训练。
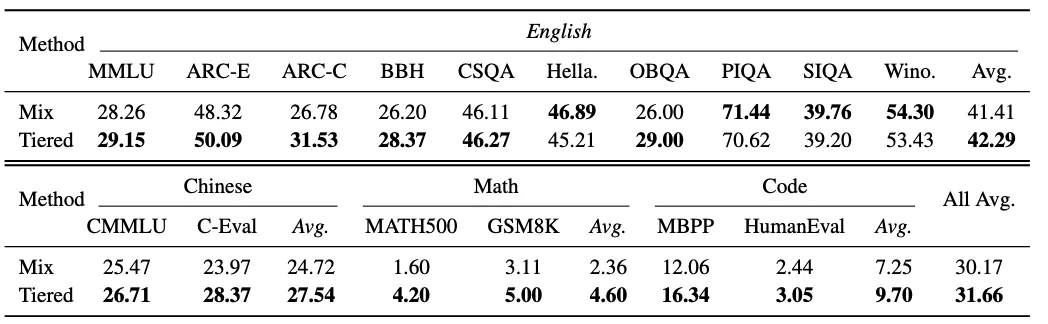
混合训练与分级训练结果对比
上表展示了两种策略在各评测基准上的详细结果。与混合训练相比,分级训练在整体平均性能上提升了 1.49个百分点,并且在英文、中文、数学和代码四个主要评测领域均取得了显著提升。
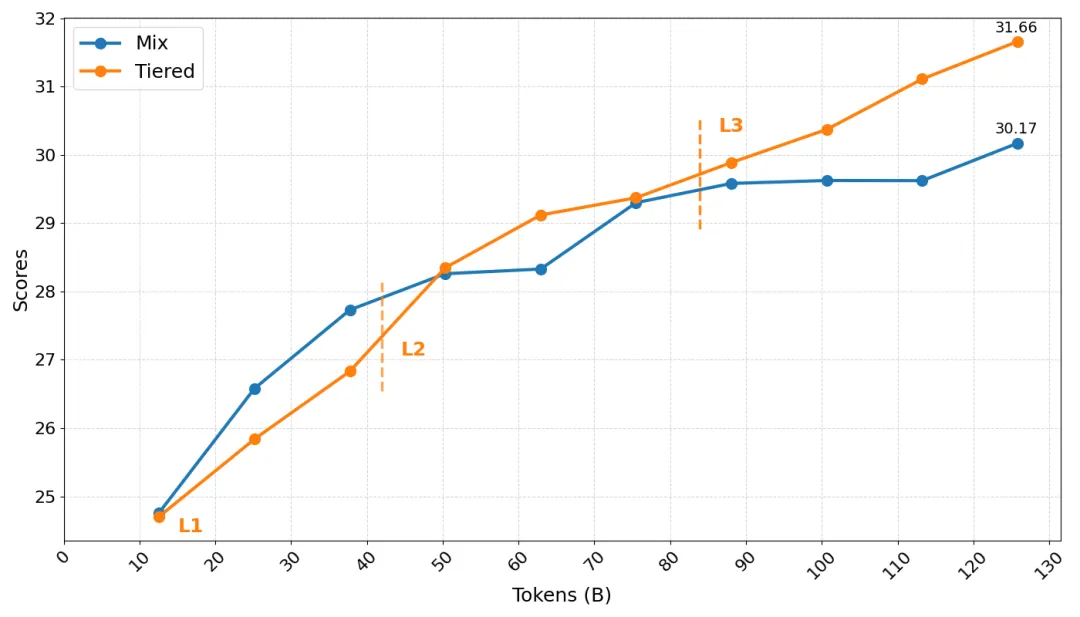
混合训练与分级训练在各训练节点的平均得分对比
上图从训练过程的动态视角进一步揭示了分级数据治理的优势。
在训练早期,两种策略增长趋势相似。此阶段分级训练主要使用L1数据。
在训练后期,分级训练策略逐步引入经过L2筛选及L3合成的高质量数据,性能曲线呈现持续稳定的上升趋势,最终达到31.66分,相比中期增长 3.31。相比之下,混合训练的增长明显放缓,最终仅达到30.17分,增幅约为 1.91。
实验结果表明,将训练数据按L1、L2、L3分级组织并进行阶段式训练,能更有效地提升模型在知识、推理及领域能力等多维度的综合性能。
UltraData-Math 高质量数学预训练数据
基于UltraData数据分级治理体系,研究团队在数学数据上进行了深入治理与严格实验,构建了当前最大规模的L3数学合成数据。相关实验结果证明了该方法的有效性,全量数据与分级治理工具已在OpenBMB、HuggingFace 等社区开源。
具体的治理方法如下:
- L0 层:基于 magic-html 开发了数学专用解析器 UltraData-Math-Parser,结合 w3m 布局保留渲染和多级回退策略,能将 MathML、KaTeX 和 AsciiMath 等格式标准化为 LaTeX 格式。
- L1 层:通过启发式规则清洗噪声数据,并进行文档级去重处理。
- L2 层:使用闭源大模型对种子数据进行标注,并蒸馏成轻量级 Embedding 分类器,实现对全语料库的高效质量分级。
- L3 层:构建 UltraData-Math-Generator,通过多种形式的数据改写、合成和精修(如问答、多人对话、多风格重写及知识支撑教材)生成结构化内容。

UltraData-Math Parser 解析效果对比
经过全链路清洗与重构,数据实现了从“广度覆盖”到“深度聚焦”的转变。最终得到了总计 290B Tokens 的数学分级数据:
- UltraData-Math-L1:包含 170.5B Tokens 的网页数学语料。
- UltraData-Math-L2:包含 33.7B Tokens 的经质量模型筛选的高质量数学数据。
- UltraData-Math-L3:包含 88B Tokens 的多格式高质量合成数学数据(如问答、多轮对话、知识教材等)。
实验验证与结果分析
为验证数据质量,团队基于 MiniCPM-1.2B 模型设计了一系列控制变量实验。所有实验模型均在 100B Tokens 的训练量下进行。
实验数据显示,在L0层使用UltraData-Math解析器,对下游任务表现产生了显著影响。该解析方案在 MATH 数据集上达到 28.72 分,优于 trafilatura (28.08) 和 magic-html (26.58)。这证明了数据解析的完整性对于模型理解复杂数学逻辑至关重要。
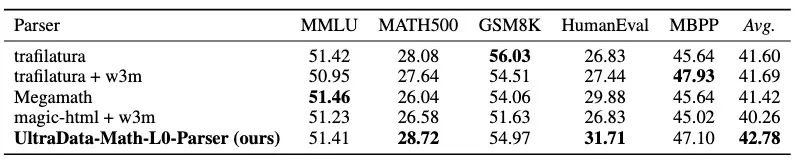
L0 解析器实验结果对比
团队将最终数据 UltraData-Math-L3 与当前先进的开源数学数据集(Nemotron-CC、MegaMath、FineMath)进行了独立训练对比。结果表明,UltraData-Math 在多个核心基准上刷新了同规模模型的性能纪录。
得益于L0-L3的分级治理,模型不仅在 MATH 基准上大幅领先 Nemotron-CC 4plus (领先+3.62分),更在 GSM8K、Math-Bench 以及 R-Bench-T 等多维数学评测中展现了卓越的推理性能,有力验证了L3合成数据对复杂数学思维链的显著增益。
同时,模型在 MBPP 代码生成任务上收益显著 (49.27分),并保持了稳健的通用知识水平(MMLU),实现了数学深度与逻辑广度的双重突破。

数学 L3 数据实验结果对比
UltraData 开放社区网站
研究团队正式推出UltraData开放社区与官方网站,将及时发布最新的治理工具、数据集与研究动态。
全链路治理工具
平台聚合了每一层级的数据治理工具,完整覆盖从原始数据到规范化有序数据的全流程:
- L0 - UltraData-Parser:支持网页、PDF等异构内容解析。
- L1 - UltraData-Cleaner:动态组合启发式规则过滤、去重等算子。
- L2 - UltraData-Selector:通过模型打标筛选高价值样本。
- L3 - UltraData-Generator:实现多样化数据改写与合成。
- L4 - UltraData-Organizer:构建结构化知识库并进行可信校验。
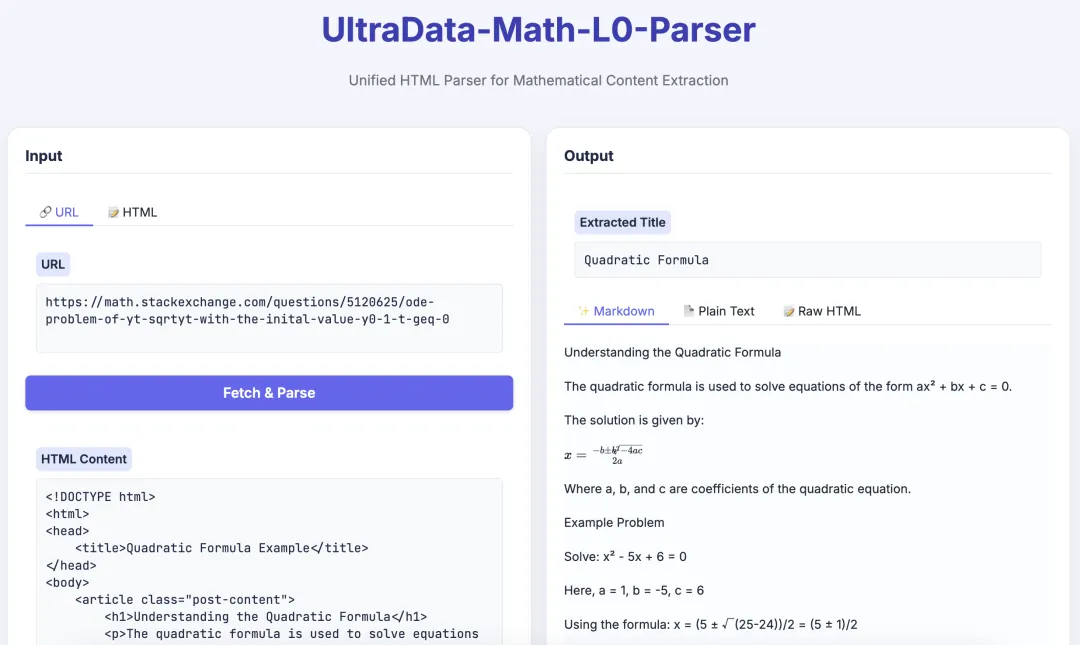
UltraData-Math-L0-Parser 在线试用 Demo
这些治理工具已部署在 HuggingFace Spaces 等平台,开发者无需自行部署即可快速体验效果。对于热衷于动手实践的开发者,也欢迎到 云栈社区 的相关板块交流更多开源实战心得。
全层级数据集
网站整合了OpenBMB社区数据治理的往期成果与最新实践,所有数据集均经过开源社区验证并广受好评:
- DCAD-2000 (L1):累计下载222k,覆盖2282种语言、159种文字系统。
- Ultra-FineWeb (L2):累计下载406k,曾连续2周登顶 HuggingFace Datasets Trending 第一名。
- UltraChat (L3):据HuggingFace统计,全球有500+模型使用,位列第7位。
- UltraFeedback (L3):据HuggingFace统计,全球有1000+模型使用,位列第4位。
- UltraData-Math 系列:涵盖L1-L3全级别数学数据。
结语
从论文提出科学方法,到平台落地实用工具,再到开源高质量数据集提供可用资源,UltraData项目构建了“理论→实践→应用”的完整闭环。团队深知,数据科学的未来不在于孤岛式的积累,而在于开放式的协作。
未来,团队希望团结更多学术界与工业界的合作伙伴,诚挚邀请全球开发者共同发展UltraData生态,共享优质数据、共建科学治理体系、共同探索面向AGI实践的新可能。
 发表于 2026-2-11 17:43:37
|
查看: 224|
回复: 0
发表于 2026-2-11 17:43:37
|
查看: 224|
回复: 0
