近期,Yann LeCun 团队连续发表了三篇重要论文,直指非生成式世界模型在迈向高效自主智能系统过程中面临的几大核心挑战,并提供了从表征学习到规划算法的系统性解决方案。

非生成式路线的优势在于通过潜在空间预测避开了像素级生成的高昂计算成本。然而,在具体实践中,该路线仍受限于一些工程与算法短板:例如,现有的稠密特征缺乏类似生物神经系统的稀疏性,难以实现高效的信息解耦;下游规划任务未能充分利用模型的梯度信息,导致长程决策效率低下;同时,复杂的架构设计也限制了其在通用硬件上的复现与改进。
LeCun 团队此次发布的 Rectified LpJEPA、GRASP 和 EB-JEPA,正是分别从正则化目标修正、梯度轨迹优化以及轻量化工程实现三个维度,提供了具有针对性的优化方案,共同推动了 人工智能 世界模型技术栈的进阶。

Rectified LpJEPA:实现可控的稀疏表征

在自监督学习领域,I-JEPA 和 VICReg 等方法虽已证明非生成式架构的有效性,但其正则化策略存在局限——过度依赖高斯分布。现有方法通常强制特征分布接近各向同性高斯分布。这种约束虽能通过最大化熵防止模型坍塌,却会导致学到的特征呈现“稠密”状态,即绝大多数神经元时刻处于激活状态。
这与神经科学的观测相悖。生物大脑皮层采用高度稀疏的编码方式,这对计算能效和语义解耦至关重要。
论文标题:Rectified LpJEPA: Joint-Embedding Predictive Architectures with Sparse and Maximum-Entropy Representations
论文链接:https://arxiv.org/pdf/2602.01456
代码链接:https://github.com/YilunKuang/rectified-lp-jepa
为解决这一问题,研究团队提出了 Rectified LpJEPA。
RDMReg 正则化与 RGG 分布
该架构的核心改进在于引入了 RDMReg 正则化项。不同于 VICReg 试图匹配标准高斯分布,RDMReg 强制特征投影去匹配一种全新的目标分布——整流广义高斯分布。
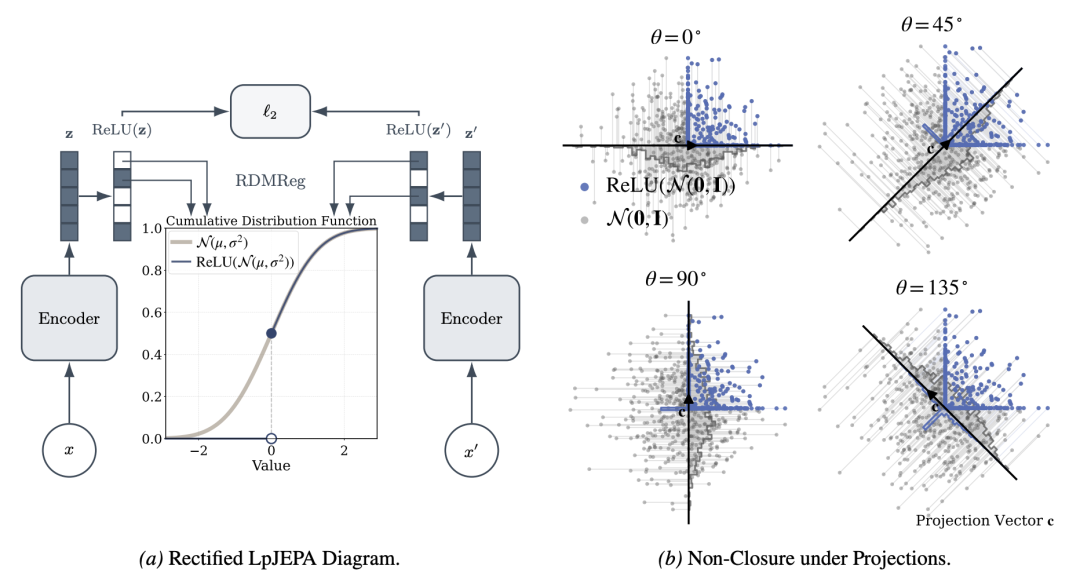
RGG 分布的数学构造包含两个关键部分:
- 狄拉克 δ 函数:位于 z = 0 处,用于显式控制稀疏度(即特征为 0 的比例)。
- 广义高斯分布:用于建模非零值的分布形态。
通过调整形状参数 p 和位置参数 μ,该方法允许精确控制特征稀疏度。μ 的取值决定了分布在整流前的偏移量,直接影响落入零值区域的概率质量。如此一来,研究者既能保持最大信息熵约束,又能强制模型实现特定的神经元静默率。
稀疏性与性能的权衡
传统观点认为,增加稀疏性约束会导致信息损失,进而降低模型性能。Rectified LpJEPA 的实验打破了这一成见:稀疏性与性能完全可以共存。
在 ImageNet-100 的线性评估实验中,该模型展示了显著的去冗余能力:
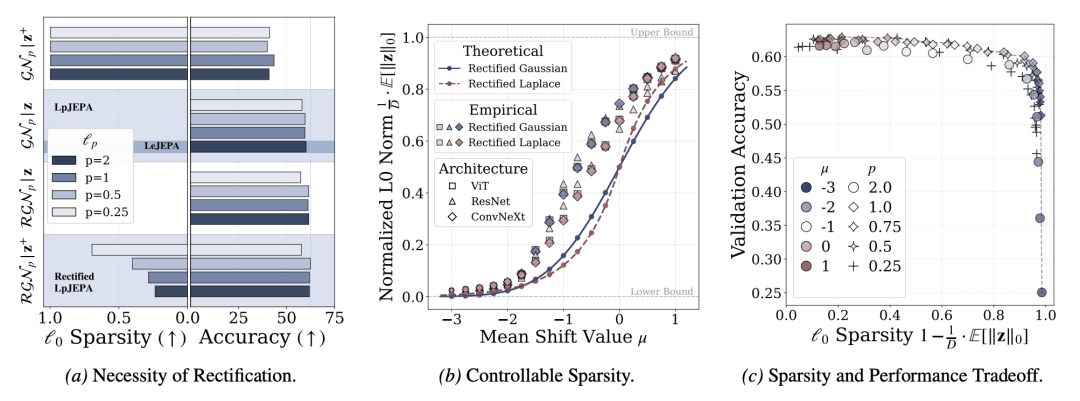
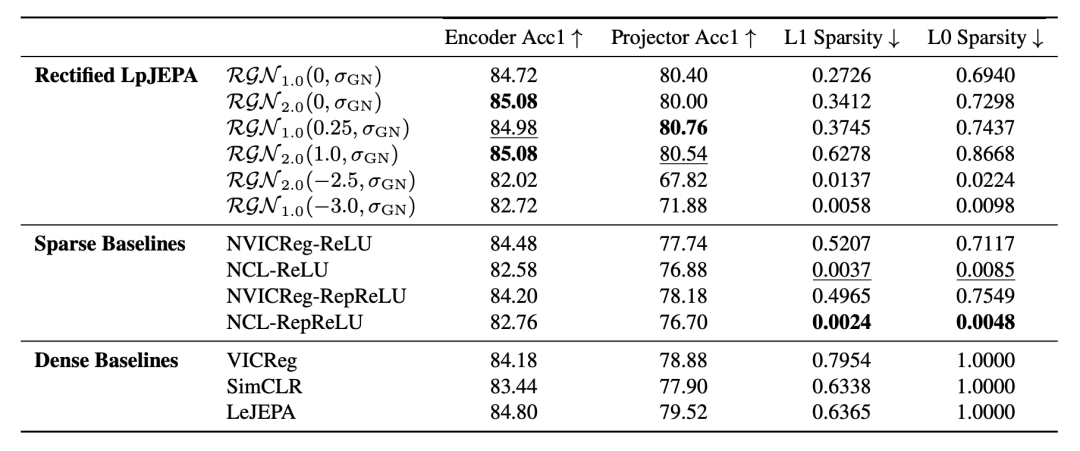
实验数据表明,通过切片 Wasserstein 距离匹配分布,RDMReg 有效迫使模型学习统计上更独立、解耦的特征表示。这种稀疏表征降低了特征间干扰,为后续规划任务提供了更优的状态空间结构。
GRASP:基于梯度的随机规划器

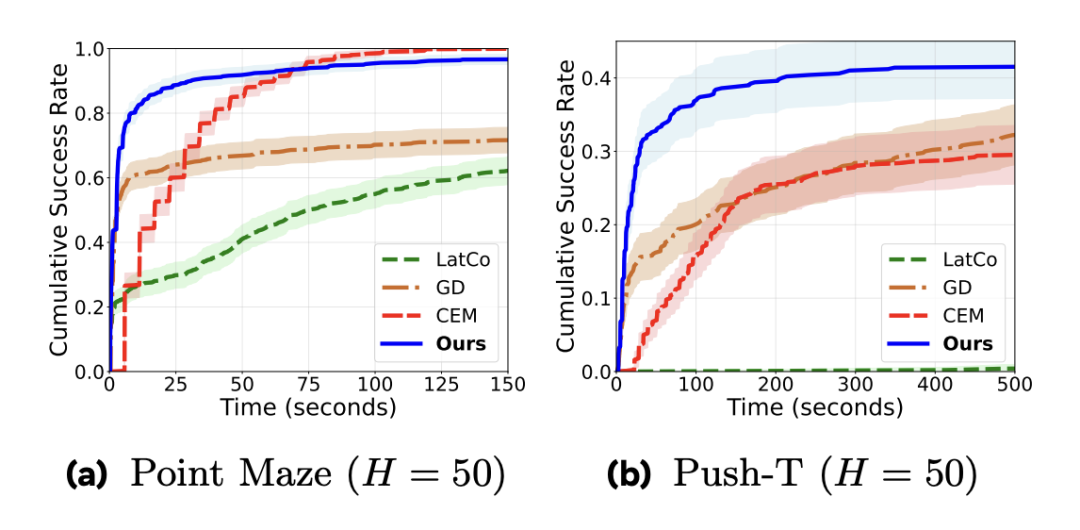
搞定高效的世界模型表征后,核心难题来到决策环节。目前的模型预测控制主要依赖零阶优化方法,如交叉熵法(CEM)或 MPPI。这类方法通过在动作空间随机采样大量序列并评估回报来寻找最优解。尽管鲁棒性较强,但在高维空间或长程任务中,其搜索效率极低。
理论上,由于世界模型是可微神经网络,直接使用梯度下降反向优化动作序列更高效;但实操中,通过长序列进行反向传播往往面临梯度消失/爆炸,且极易陷入局部最优。
论文标题:Parallel Stochastic Gradient-Based Planning for World Models
论文链接:https://arxiv.org/pdf/2602.00475
项目主页:https://www.michaelpsenka.io/grasp/
针对这些挑战,论文提出了 GRASP,通过两项关键技术创新,实现了稳定的梯度规划。
从“串行推导”到“并行配置”
传统规划通常采用串行方式,GRASP 则采用了配置点范式,将整个时间窗口内的所有状态和动作视为独立的优化变量。这种方法将序列推理转化为一个约束优化问题,其核心目标函数如下:
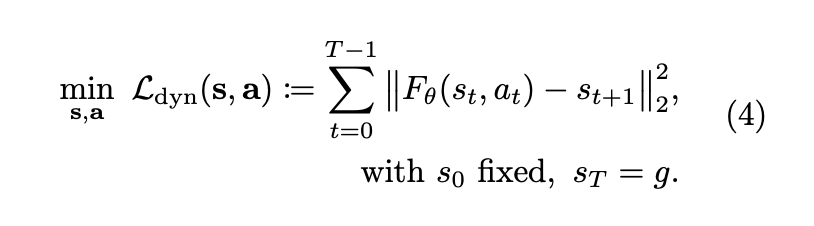
通过最小化这一动力学违反误差,GRASP 实现了计算并行化,并大幅缩短了梯度传播路径。
梯度截断与随机探索机制
这是 GRASP 解决梯度病态问题的核心设计。优化过程中,如果不加约束,优化器倾向于通过修改输入状态来“欺骗”损失函数,而非真正优化动作。GRASP 引入了一种特殊的梯度结构:在计算动力学误差的梯度时,切断了通过世界模型输入状态的反向传播。
在此过程中,模型仅利用对动作的梯度和对下一时刻目标状态的直接梯度进行更新,而忽略了模型状态输入端的梯度。这一约束倒逼优化器必须调整动作以符合物理规律。
此外,为防止梯度法陷入局部最优,GRASP 在状态更新中引入了朗之万动力学噪声:
s_t^{k+1} ← s_t^k - η_s ∇_{s_t} ℒ_dyn(s^k, a^k) + σ_state ξ_t^k,
a_t^{k+1} ← a_t^k - η_a ∇_{a_t} ℒ_dyn(s^k, a^k),
这种受控的随机性允许规划器在状态空间进行探索,有效避免了陷入次优解。
在 PointMaze 迷宫导航和 Push-T 等长程任务中,GRASP 展现了显著优于 CEM 等传统采样方法的性能。
EB-JEPA:轻量化的工程实现库

如果说前两项工作攻克了算法理论高地,EB-JEPA 则意在降低准入门槛。复现 I-JEPA 或 V-JEPA 等前沿模型通常耗费昂贵算力,且代码库深度绑定特定基础设施。为扫除这一障碍,作者团队开源了 EB-JEPA 库。
论文标题:A Lightweight Library for Energy-Based Joint-Embedding Predictive Architectures
论文链接:https://arxiv.org/abs/2602.03604
项目链接:https://github.com/facebookresearch/eb_jepa
模块化设计与单卡训练
EB-JEPA 的设计原则是轻量级和模块化。它将 JEPA 的核心组件——编码器、预测器和代价函数(如 VICReg)——完全解耦,支持研究者灵活替换。
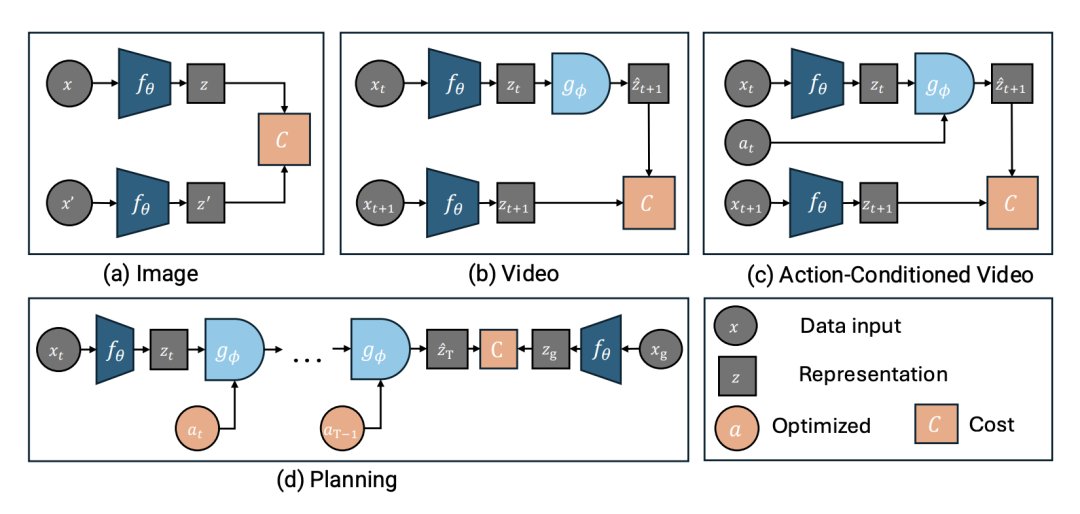
该库对所有示例进行了计算优化,仅需数小时即可在单张 GPU(如 V100 16GB)上完成训练。这一设计使得基于能量的自监督学习能够被更广泛的研究群体所访问。
核心:动作条件视频预测
EB-JEPA 不仅仅是图像表征库,它还提供了 Action-Conditioned Video-JEPA 的完整实现。这是构建世界模型的基石:模型需要根据当前状态和控制输入,预测未来的潜在状态。
下面是其训练循环中规划部分(MPPI算法)的伪代码示例:
Algorithm 1 Model Predictive Path Integral (MPPI)
1: Input: Initial observation x0, goal observation xg, initial mean μ ∈ ℝ^H×A, noise scale σ, temperature τ, number of samples N, number of iterations J, number of elites K, max steps per episode M
2: Encode initial and goal: ẑ0 = fθ(x0), zg = fθ(xg)
3: for j = 1 to J do
4: Sample N noise perturbations: εi ∼ 𝒩(0, σ²I) for i = 1, ..., N
5: Compute candidate action sequences: a(i)_0:H-1 = μ + εi
6: Unroll predictor for each trajectory: ŷ(i)_{t+1} = gφ(ẑ(i)_{t-v:t}, u(i)_{t-v:t}) for t = 0, ..., H-1
7: Compute trajectory costs: Si = Σ(t=1 to H) ‖zg - ŷ(i)_t‖₂
8: Select top K elite samples with lowest costs
9: Compute weights over elites: wi = exp(-Si/τ) / Σ(k=1 to K) exp(-Sk/τ)
10: Update mean: μ ← Σ(i=1 to K) wi · a(i)_0:H-1
11: end for
12: Return: Execute first m actions of μ, then replan from new observation until M steps reached
在 CIFAR-10 和 Moving MNIST 上的基准测试表明,即便在轻量级设置下,EB-JEPA 依然能学习到高质量表征。这为学术界提供了标准化的实验平台,低成本验证新正则化方法或规划算法成为可能。
总结
从底层原理到上层应用,这三项工作完成了 JEPA 世界模型技术栈的闭环构建。
Rectified LpJEPA 证明了修正目标分布可显著提升表征的稀疏性与解耦度;GRASP 验证了在长程规划任务中利用梯度信息的优越性;而 EB-JEPA 则通过模块化代码,让这一技术路线在通用计算资源上落地生根。
这些工作将非生成式世界模型的关注点,从架构有效性的初步验证,推进到了对表征效率、控制精度及系统可扩展性的深度优化阶段。这为后续研究提供了具备明确数学原理和工程参考价值的技术基线,也标志着构建高效自主智能系统的路径又向前迈进了一步。对于想深入探索相关领域的研究者和开发者,可以关注 云栈社区 中关于智能与数据云计算的讨论板块,获取更多前沿动态和技术资源。
 发表于 2026-2-11 19:26:58
|
查看: 190|
回复: 0
发表于 2026-2-11 19:26:58
|
查看: 190|
回复: 0
