当你听到“用 Rust 重写那个老旧的 C 服务”时,是否心头一紧?
你正在维护一个用 C 语言编写的核心服务,它每天处理数百万请求,已经稳定运行了数年。突然,技术决策者要求在保持服务不间断的前提下,逐步迁移到更安全的 Rust。你脑海中浮现的第一个念头,是不是“从 main 函数开始彻底重写”?先冷静一下。
这好比为一栋仍在住人的老房子做现代化改造。与其一次性推倒重建,更稳妥的做法是逐一更换门窗和管线,确保生活不受影响。生产环境的 C 代码也是如此——它可能存在内存泄漏、段错误等潜在风险,但它在持续创造价值。直接停服重写的代价,往往是业务无法承受的。
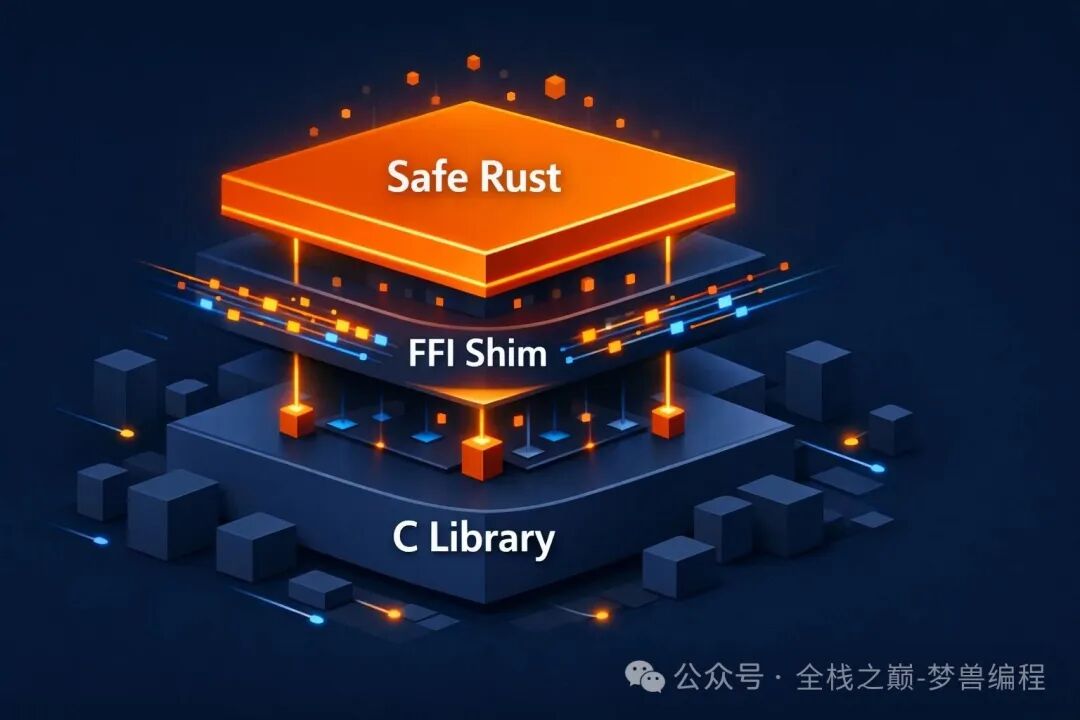
本文将介绍一种在 Rust 生态中备受推崇的稳健方案:FFI 三明治(FFI Sandwich)。这是一种渐进式迁移模式,能够让你在保持 C 代码持续运行的同时,为其逐步包裹上 Rust 的安全层。
FFI Sandwich 是什么?
顾名思义,FFI 三明治由三层结构组成,像两片面包夹着一层馅料:
你的应用(安全的 Rust 代码)
↓
FFI 中间层(unsafe 但很薄)
↓
C 语言库(久经考验的老代码)
- 上层“面包”:安全的 Rust 应用代码,享受 Rust 所有权系统和借用检查器带来的安全保障。
- 中间“馅料”:FFI 垫片(Shim),使用
#[no_mangle] extern “C” 进行桥接,主要职责是处理类型转换,将 Rust 世界的安全类型转化为 C 世界能理解的原始类型,反之亦然。
- 下层“面包”:现有的、稳定运行的 C 库。
这个模式追求的是“无趣”和“可预测”。它不依赖复杂的宏魔法或泛型技巧,因为生产环境最需要的是稳定,而非惊喜。你可以把它想象成一位专业的翻译:你(Rust)说一种语言,老师傅(C)说另一种,翻译(FFI 层)确保信息准确传递,而老师傅的工作流程完全不受干扰。
先决决策:调用方向
动手之前,必须明确一个核心方向:是 Rust 调用 C,还是 C 调用 Rust?这决定了整个互操作架构的走向。
Rust 调 C
这是最常见且推荐的起步方式。你的 C 库中包含了经过千锤百炼的算法或逻辑,运行高效且稳定。你希望在不改动其内部实现的前提下,为它加装一个安全的“外壳”或“入口”。这就像为老房子安装一套新的智能门锁,内部陈设不变,但进出变得更安全、可控。
C 调 Rust
当你需要编写一个全新的、用 Rust 实现的核心模块,并希望现有的 C 程序能够调用它时,采用此方向。这如同在老厨房里安装一台新的高效炉灶,烹饪方式(调用接口)保持不变,但核心性能得到了提升。
重要原则:对于一个给定的子系统,尽量只选择一个方向进行互操作,避免双向复杂调用。虽然技术上可行,但双向互调会显著增加架构的复杂度和心智负担。
跨越边界的类型:持“证”通行

FFI 边界如同海关,并非所有数据类型都能自由通行。Rust 的安全模型在此处需要你格外谨慎。以下类型持有“通行证”:
- 原始指针:
*const T、*mut T
- 基本整数类型:
i32、u64、usize 等具有确定位宽的类型。
#[repr(C)] 结构体:其内存布局与 C 语言的结构体完全一致。- 缓冲区:通常以
(指针, 长度) 对的形式传递,明确数据的位置和大小。
- 错误码:使用整数返回错误(例如,0 表示成功,负数表示错误)。这是
extern “C” 函数的惯例,避免使用 Rust 的 Result 类型。
以下类型则被“禁止通行”:
- Rust 的高级抽象类型:如
String、Vec、Option,它们的内存布局对 C 来说是未定义的。
panic:绝不能让 panic 跨越 FFI 边界传播,这会导致未定义行为。- Rust 的 Drop 语义:C 语言不理解 Rust 的自动析构机制。
互操作的核心就在于严格遵守这条边界规则。两边各自管理自己的复杂类型,边界上只传递最原始、双方都能理解的数据。
核心范式:一个出参,一个状态码
理论讲完,来看一个体现 Rust FFI 安全性的核心代码范式。这十几行代码是构建稳健 FFI 接口的基石:
use std::os::raw::c_int;
#[repr(C)]
pub struct FfiResult {
pub code: c_int, // 0 = 成功, <0 = 错误
}
#[no_mangle]
pub extern "C" fn rs_sum_u32(
input: *const u32,
len: usize,
out: *mut u64,
) -> FfiResult {
// 1. 严格校验输入:空指针立即拒绝
if input.is_null() || out.is_null() {
return FfiResult { code: -1 };
}
// Safety: 调用方必须保证 input 指向连续的 len 个 u32,且 out 有效
let slice = unsafe { std::slice::from_raw_parts(input, len) };
let sum: u64 = slice.iter().map(|&x| x as u64).sum();
unsafe { *out = sum; }
// 2. 返回简单明了的错误码结构
FfiResult { code: 0 }
}
这个模式清晰可靠:
- 入口校验:像餐厅服务员核对预约一样,先检查指针是否有效、长度是否合理。
- 统一错误码:使用简单的整数或
repr(C) 结构体返回状态,确保 C 端能够无误解析。
- 通过出参返回结果:避免在 FFI 层进行复杂的内存分配,调用方负责提供存储结果的缓冲区。
- 最小化
unsafe 块:将 unsafe 代码限制在绝对必要的范围内,如同使用手术刀般精准。
遵循此模式,可以大幅降低 FFI 编程的风险。
内存管理:谁分配,谁释放
内存管理是 FFI 中最易出错的部分。黄金法则是:Rust 分配的内存,由 Rust 释放;C 分配的内存,由 C 释放。
这好比合租公寓的规则,自己买的东西自己处理。
如果 Rust 需要为 C 端分配内存,则必须配对提供相应的释放函数:
#[no_mangle]
pub extern "C" fn rs_create_buffer(size: usize) -> *mut u8 {
let mut buf = Vec::with_capacity(size);
let ptr = buf.as_mut_ptr();
std::mem::forget(buf); // 防止 Rust 自动回收
ptr
}
#[no_mangle]
pub extern "C" fn rs_free_buffer(ptr: *mut u8, capacity: usize) {
if !ptr.is_null() {
unsafe {
// 重新构造 Vec,利用其 Drop 实现进行正确释放
let _ = Vec::from_raw_parts(ptr, 0, capacity);
}
}
}
关于线程,一个实用建议是:避免在线程间传递需要通过 FFI 共享的复杂缓冲区。Rust 和 C 的运行时对线程模型的假设可能不同,容易引发问题。
对于回调函数,应遵循 C 的惯例:使用 函数指针 + void* 上下文 这种简单形式,避免尝试传递 Rust 闭包。
构建与集成
构建配置需要细心,但并不可怕。
对于 Rust 调 C 的场景:
- 在
Cargo.toml 中设置 crate-type = [“cdylib”] 或 [“staticlib”]。
- 使用
cbindgen 工具根据你的 Rust 代码(特别是 #[repr(C)] 结构体)自动生成 C 语言头文件。
- 在
build.rs 中链接 C 库:println!(“cargo:rustc-link-lib=your_clib”);。
- 最终产出:一个动态库/静态库(如
libyourlib.so)和对应的 .h 头文件。
对于 C 调 Rust 的场景:
过程基本相反:将 Rust 编译为库,在 C/C++ 项目的构建系统(CMake, Make等)中链接该库并包含生成的头文件。
推荐两个核心工具:
cbindgen:从 Rust 生成 C 头文件。bindgen:从 C 头文件生成 Rust 绑定,通常在 build.rs 中使用。
测试:双向验证,确保一致
迁移是否成功,不能靠感觉,必须靠数据对比。
- 准备测试数据集:涵盖正常值、边界值、大体积数据及各种 corner case。
- 编写 C 测试工具:调用原有 C 接口,处理测试数据并输出结果(或结果哈希)。
- 编写 Rust 测试工具:调用新的 Rust FFI 接口,处理相同数据并输出结果。
- 对比验证:严格比较两个输出的结果。任何差异都意味着潜在的 bug。
# 基本流程示意
./legacy_c_program < test_data.bin > c_output.txt
./new_rust_wrapper < test_data.bin > rust_output.txt
diff c_output.txt rust_output.txt
将 cargo fuzz 之类的模糊测试工具集成到夜间 CI 中,让随机生成的输入不断轰炸新旧两套接口,是发现隐藏分歧的绝佳方法。
注意浮点数比较:应预先约定精度容差(epsilon),使用类似 assert!((a - b).abs() < 1e-9) 的方式进行判断。
性能考量
许多人担心 FFI 调用会带来性能开销。实际上,Rust 和 C 本身的执行效率在伯仲之间,真正的瓶颈往往在于跨边界调用的次数。
想象搬家:瓶颈不是你从五楼跑到一楼的速度,而是你上上下下跑了多少趟。因此,优化策略在于:
- 批处理:通过
(指针, 长度) 一次传递大量数据,在一边集中处理,而非逐条调用 FFI 函数。
- 保持热循环完整性:如果某个计算密集型循环原本在 C 中,尽量一次 FFI 调用就让 C 完成整个循环,避免在 Rust 和 C 之间频繁切换。
- 避免跨界分配:内存分配和释放应在同一语言运行时内完成。
合理的性能目标是:关键路径(p95延迟)在引入 FFI 层之后,变化幅度控制在 ±3% 以内。如果性能下降显著,首先检查是否发生了不必要的频繁 FFI 调用。
使用 perf 或 VTune 等工具进行分析时,应重点关注 FFI 调用次数和上下文切换开销。
安全收益
即使底层实现仍是 C 代码,外层的 Rust 安全壳也能立即带来可观的安全提升:
- 输入验证:在 Rust 层对输入的
(指针, 长度) 进行配对和合理性校验,可以消除一大类因 C 直接信任输入而导致的缓冲区溢出漏洞。
- 资源限制:在 Rust API 入口处限制递归深度、循环次数等,防止恶意输入导致的服务拒绝(DoS)。
- 字符串安全:将不可信数据先作为
&[u8] 处理,在 Rust 侧显式验证 UTF-8 有效性后再传递给 C。
- 空指针拦截:所有空指针和非法枚举值在进入 C 代码之前就被阻挡在外。
Rust 层不是万能的防火墙,它无法修复 C 代码内部的逻辑错误。但它能有效隔离外部输入,将许多由外部触发的常见安全问题扼杀在入口处。
四步渐进式迁移法
理论最终要落地。以下是可操作的四个步骤:
第一步:包裹最危险的接口
从你的 C 代码库中,找出那个历史崩溃记录最多、或最可能受外部输入攻击的函数。用上文所述的 FFI 模式为其编写一个 Rust 安全包装层。可以先对少量流量(如1%)启用此新路径。
第二步:双路运行,对比验证
让旧有的 C 直接调用和新设的 Rust 包装路径并行运行一段时间。持续对比两者的输出结果,确保完全一致。任何差异都是需要修复的 bug。
第三步:内部替换一块逻辑
在“三明治”的中间层或底层,选择一小块独立的 C 逻辑,用 Rust 重新实现。保留原有的 C 实现作为快速回退的备选方案。
第四步:重复迭代
选择下一个目标接口或模块,重复上述步骤。不追求速度,追求稳定。每个迭代周期都应带来可量化的稳定性提升。
记住,这是按 接口和功能 迁移,而不是按代码行数迁移。优先处理风险最高的边界,而非体积最大的模块。
如何衡量迁移成效?
用数据说话,而非感觉。关注以下四个指标:
- 崩溃/异常率:统计每百万请求中发生的段错误、Panic 等次数。目标是将由 FFI 边界或已迁移模块引发的问题降至零。
- 关键路径延迟(如 p95):对比迁移前后,目标是将性能波动控制在 ±3% 以内。
- 消灭的漏洞类别:跟踪“因输入校验缺失导致的漏洞”、“因内存管理不当导致的漏洞”等类别是否随着迁移而减少。
- 迁移进度:设定节奏,例如每个开发周期(Sprint)完成一个接口的封装或一个模块的重写。
这些数据是与项目管理者、利益相关者沟通的最佳语言。“我们将模块 X 迁移到 Rust 后,相关崩溃减少了 90%”远比单纯说“Rust 更安全”更有说服力。
立即行动:本周就能开始的三件事
别只停留在阅读。打开你的编辑器,现在就可以开始:
1. 封装一个简单函数
从你的 C 代码库中找一个最简单的、无状态、仅做计算的函数。使用本文的“出参+状态码”模式,为其编写 Rust FFI 包装。如果涉及内存,记得配上释放函数。
2. 建立对比测试套件
创建一个小型测试工具,生成或准备一组(比如100个)测试输入。分别用原 C 函数和新的 Rust 包装函数运行,并自动比对输出。将这个测试加入你的 CI 流程。
3. 分析调用模式
对你打算迁移的模块进行 profiling,了解关键 FFI 函数每秒被调用的频率、平均每次处理的数据量。如果发现“高频次、小数据量”的调用模式,那么“批处理优化”应该是你迁移前的首要重构任务。
核心原则:不要试图立即替换那些正在创造价值的代码,而是先安全地包裹住它。
你的 C 代码库中,哪个函数或模块最让你夜不能寐?是那个复杂的字符串解析器,还是无人敢碰的加密解密模块?在 云栈社区 的技术论坛中分享你的故事,或许你遇到的坑,早已有人填平。
在后续的分享中,我们可以探讨如何为这个“FFI 三明治”添加可观测性(Observability),让每一次跨界调用都有迹可循、有数可查,使整个迁移过程变得更加透明和可控。
 发表于 2026-2-12 00:17:51
|
查看: 177|
回复: 0
发表于 2026-2-12 00:17:51
|
查看: 177|
回复: 0
